大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
感谢作者陈煮酒的投稿。
前言
无论是纯前端业务还是服务端业务,线上质量的保障都是我们的底线要求,也是我们日常需要花费很多精力关注的环节。
今天在这里就跟大家分享一下,如何从零到一建设一个能够对线上业务进行精准监控、及时告警的系统。希望能对大家有所帮助和启发。
架构图
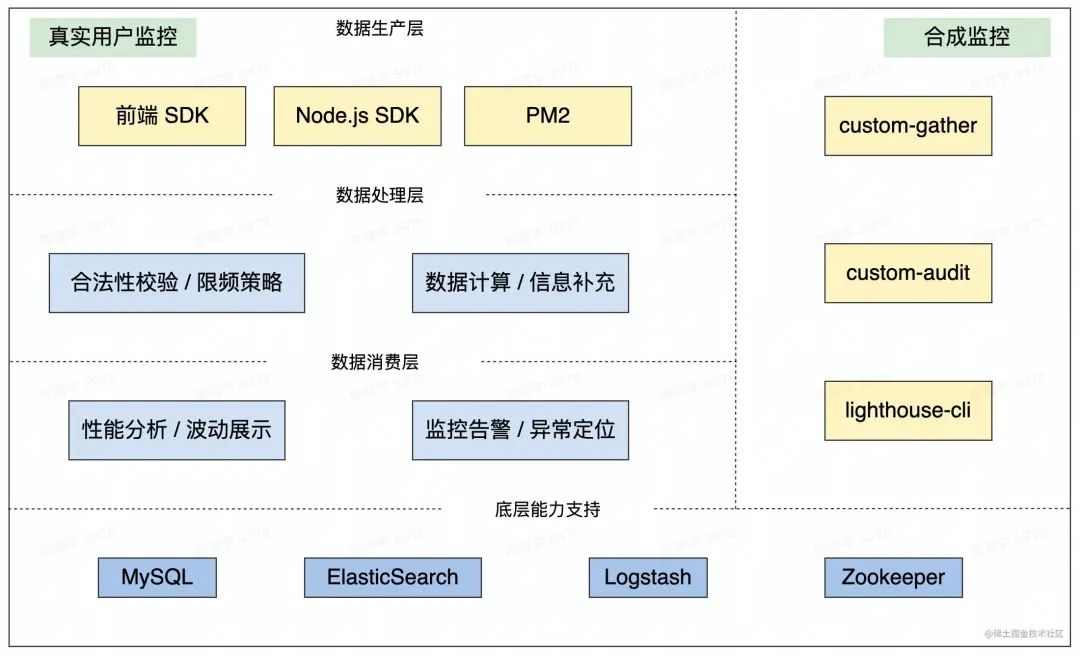
技术方案详述
数据采集(SDK部分)
Web 端 SDK
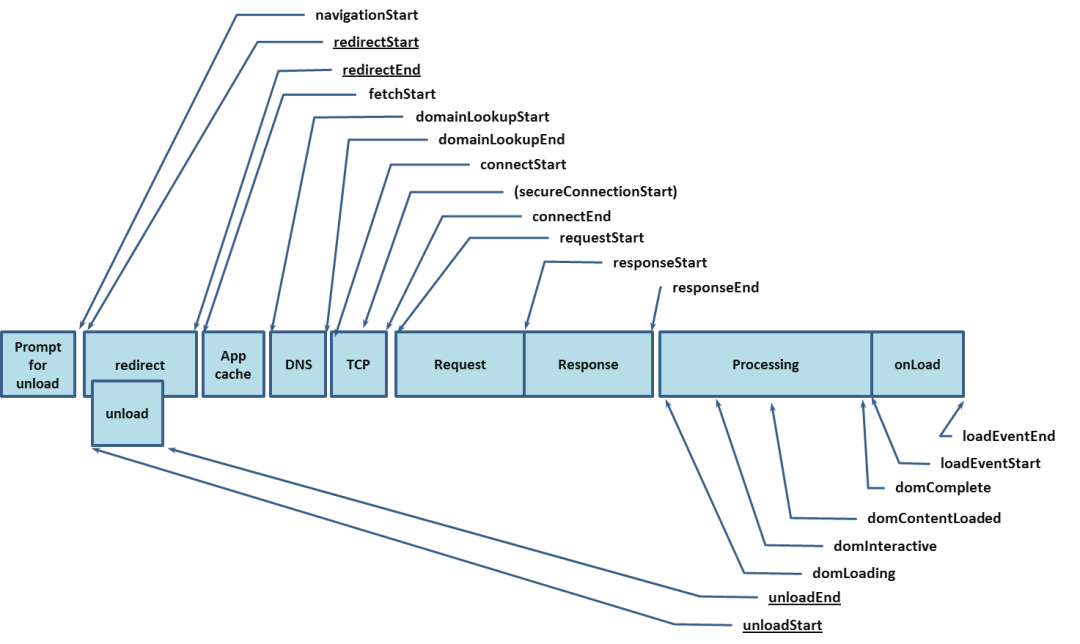
性能上报
Performance Timing
Performance.timing - Web APIs | MDN
普及 兼容
语义更关注技术侧体验,跟不上新时代要求
已经 deprecated
Web Vitals
- Web Vitals

更关注用户侧体验,更有业务价值
未标准化,有些指标需要根据场景具体实现
幸运的是 Google 已经开源了,可以直接用 https://github.com/GoogleChrome/web-vitals
浏览器支持量 < Performance Timing
Largest Contentful Paint
特定需求
SSR 业务首屏
性能打点集中在页面进入和离开,没有请求压力的问题
异常上报
全局
Window errorWindow unhandledrejection
加载
资源加载型(https 下加载 http 资源,加载异常...)
接口异常(拦截公共请求库)
自定义
提供业务方自定义上报
API白屏:页面加载后检查关键
DOM节点(例如 SSR 业务在 JS 执行时页面一定会有东西,更多的是结合业务实际逻辑做的考虑)
boundary
ReactVue
异常限频 防止异常无限循环上报
SDK 比较粗暴的策略:**
Counter超过 100 直接关闭**从异常感知的角度,当前页面上报了超过 100 个异常,那之前 100 个已经够感知及分析了
Node.js 端 SDK
Node.js 端主要通过 服务基础中间件 / PM2 插件进行信息采集
基础中间件
基于中间件机制,支持
Koa / Express
请求耗时上报
QPS 计算
请求级 - 致命异常上报
框架实例异常上报
Process异常上报uncaughtExceptionunhandledRejection
自定义 - 非致命异常上报
基于
Got封装统一请求库下游接口调用异常上报
链路信息透传,traceID 带到 header 中
基于
zookeeper的配置中心常用的 Header(CSP,CORS等)下发
黑白名单下发
离线监控
生产环境:
基于 inspector-api 通过开关采集线上
CPU Profile / Memory Snapshot文件,回传回内网静态资源服务,超时就在本地。导入devtool进行分析查看进程级别心跳检测,5分钟 上报一次状态
开发环境:
autocannon(压测工具) + clinic(分析工具)
PM2 插件
监听
pm2 Eventbus消息,对PM2进程状态进行实时响应
SDK 更新机制
Web 端
前端基础 SDK 最怕更新不及时
用 hash 来硬编码每次更新成本很高
解决方案一:
代码中用 JS 动态生成小时级时间戳,与 CDN约定映射规则,实现小时级更新
解决方案二:
方案一实时性有保证,但存在大量的缓存浪费
SDK 构建时保留小时级时间戳,写入 zookeeper,服务连接 zookeeper 进行实时下发
服务端
与服务发布流程耦合,当基础库有版本升级时,自动更新最新版本
数据处理(中央日志服务部分)
性能日志规则
上报上来的原始性能数据会经历一些处理最终产出为标准化的日志

异常日志规则
第三方厂商注入的 JS 报错、业务已知无需处理的 JS 报错 / 资源错误 / 接口错误 可以进行过滤,精简日志量,降低信噪比
异常过滤特征实时下发到服务
默认按照
error message解析,支持业务方自定义异常解析规则

自身稳定性
限流机制,一段时间内某个
key(domain + path + ip 定时清除)上报超过阈值进程状态监控
CPU / 内存状态监控
数据消费(平台部分)
性能消费
实时趋势 / 天级趋势
多指标:DOMContentLoaded、TTFB、LCP、FP
多维度:地域、机型、网络类型、运营商...
多渠道:主流浏览器、特定APP
基于 多维度信息补充 环节
机型分布、地域分布、浏览器版本分布...
总结:基于采集到的性能数据做各种形式的图表展示
异常消费
实时异常列表
按照规则聚合 倒排
前端异常以 domain 为维度,Node.js 异常以 app 为维度
支持堆栈解析(构建侧支持 sourcemap 上传能力)
日志消费
由服务端基础 SDK 统一生成 traceID,透传到页面和下游服务。
通过 traceID 串联页面异步请求 / 服务端请求链条
通过 traceID 定位单一异常的具体信息
数据存储设计
实时查询 ES,读写分离,天级查询 MySQL => 降低 ES 查询压力
标准化日志为 JSON String => 方便 logstash 解析,后期扩展字段更加灵活,基本无新增成本
持久化存储每个字段单独一条数据,定期分表 => 后续指标的接入更加灵活,无新增成本
告警机制
告警过于迟钝会失去意义,告警过于频繁会降低敏感性
告警分级制度
请求级异常 / 前端异常:按照数量进行聚合后触达
实时 / 天级性能趋势波动 超过阈值
请求级异常数量 超过阈值
进程级异常:实时触达
告警确认制度
平台提供异常确认功能,今日已确认的异常数量在计算中将会屏蔽,直到下次再次触达阈值继续告警
阈值调整
整体阈值:按照 domain / app 天级上报量 十万分之五 自动生成,支持业务方自行修改
单一阈值:业务自定,以 异常特征 为维度进行阈值设定
合成监控
上面整体是 RUM(Real User Monitoring)部分,需要采集真实用户数据进行分析。大量的真实用户数据可以非常好的反映整个业务的趋势和实时的业务稳定情况。
对于一个完整的监控中台,还需要一些离线的采集手段做更详细的分析得到更直接的建议,也就是合成监控。
这部分我们选择基于 Lighthouse Node CLI 进行建设
Lighthouse 简介
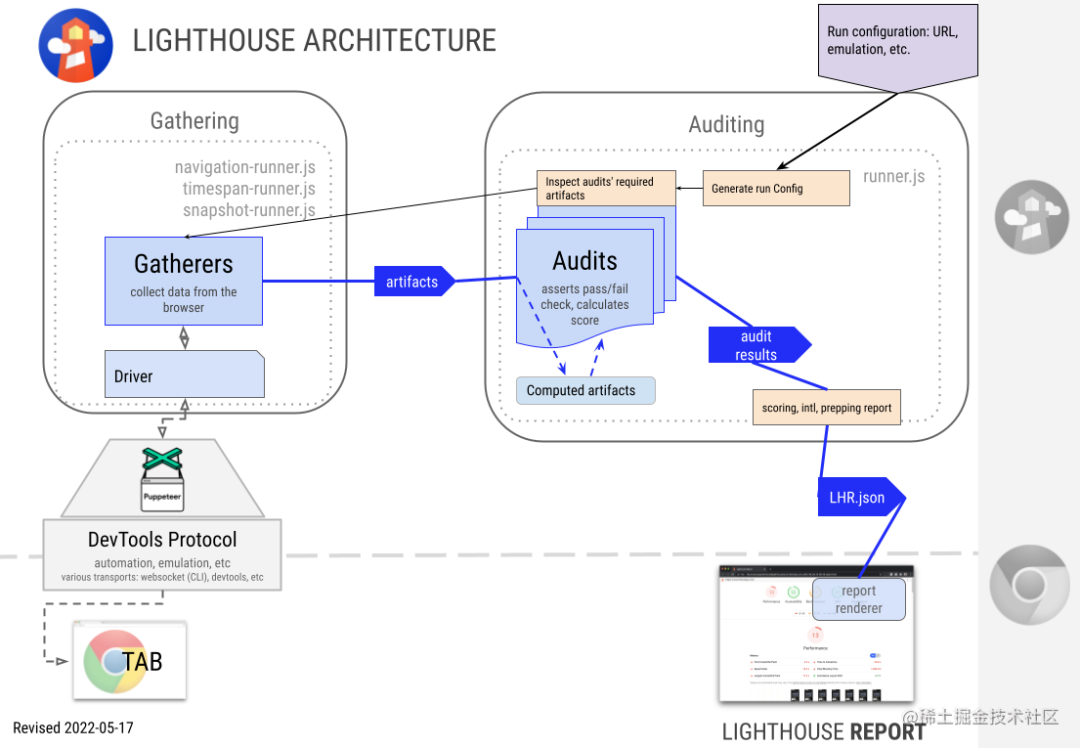
Driver
对 Puppeteer 和 Chrome Devtools Protocol 的接口
Gatherers
收集器:通过 Driver 收集页面的相关信息。Performance、Network 等
Audit
审核器:基于 Gather 收集到的信息,进行解析计算得到分数。
会输出一个 LHR(Lighthouse Result Object) 对象
{
"lighthouseVersion": "5.1.0",
"fetchTime": "2019-05-05T20:50:54.185Z",
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3358.0 Safari/537.36",
"requestedUrl": "http://example.com",
"finalUrl": "https://www.example.com/",
"audits": {...},
"configSettings": {...},
"timing": {...},
"categories": {...},
"categoryGroups": {...},
}Report
基于 LHR 输出报告
常规情况开发同学可以通过 Chrome Devtools 的 lighthouse 选项卡进行手动的操作采集得到 reporter 报告

弊端:
评分不稳定,忽高忽低
有些项可能当前业务并不关注
基于上述两点,我们选择针对业务特点去建设自定义规则
常用配置
module.exports = {
extends: 'lighthouse:default',
settings: {
onlyAudits: ['first-meaningful-paint', 'speed-index', 'interactive',],
maxWaitForFcp: 3000
},
passes: [
{
passName: 'fastPass',
gatherers: ['fast-gatherer'],
},
{
passName: 'slowPass',
recordTrace: true,
useThrottling: true,
networkQuietThresholdMs: 5000,
gatherers: ['slow-gatherer'],
}
],
categories: {
performance: {
title: 'Performance',
description: 'This category judges your performance',
auditRefs: [
{ id: 'first-meaningful-paint', weight: 2, group: 'metrics' },
{ id: 'first-contentful-paint', weight: 3, group: 'metrics' },
{ id: 'interactive', weight: 5, group: 'metrics' },
],
}
},
groups: {
'metrics': {
title: 'Metrics',
description: 'These metrics encapsulate your web app's performance across a number of dimensions.'
},
}
};settings
控制整个审计过程。
onlyAudits:只执行哪些审计
maxWaitForFcp:最大等待页面 FCP 时间,超时直接抛错
...
详见:https://github.com/GoogleChrome/lighthouse/blob/575e29b8b6634bfb280bc820efea6795f3dd9017/types/externs.d.ts#L141-L186
passes
控制如何加载请求的****URL
Passes 数组每一项代表着不同情况,都会重新加载一次页面,所以需要控制数量
recordTrace:否启用上个 pass 跟踪记录
networkQuietThresholdMs:距离上个 pass 完成后安静时长,以确保所有请求瀑布流走完,默认5000
gatherers:配置的收集器
...
详见:https://github.com/GoogleChrome/lighthouse/blob/da3c865d698abc9365fa7bb087a08ce8c89b0a05/docs/configuration.md
可以配置自定义收集器
详见:https://github.com/GoogleChrome/lighthouse/tree/main/docs/recipes/custom-audit
audits
控制要运行和包含在最终报告中的 audit
可以配置自定义 audit
categories、groups
对报告中的审计结果进行评分和分类
在分类中对结果进行可视化分组
自定义
Lighthouse 暴露了标准的 Gather、Audit 的接口,我们可以继承实现自己的收集器和审查器
const { Gatherer } = require('lighthouse');
class ResourceSizeGather extends Gatherer {
afterPass(options, loadData) {
return loadData.networkRecords.reduce((arr, record) => {
if (record.resourceType === 'Image') {
arr.push(record)
}
return arr;
}, []);
}
}
module.exports = ResourceSizeGather;afterPass:目标页面加载后调用,在所有gather的pass方法之后loadData:会提供网络请求相关数据
const { Audit } = require('lighthouse');
const INIT_SCORE = 100;
class ResourceSizeAudit extends Audit {
static get meta() {
return {
id: 'resource-size-audit',
title: '正常图片',
failureTitle: '过大图片',
description: '过大图片列表',
scoreDisplayMode: Audit.SCORING_MODES.NUMERIC,
requiredArtifacts: ['ResourceSizeGather'],
};
}
static audit(artifacts) {
const imageList = artifacts.ResourceSizeGather;
const overSizeList = imageList.filter((img => img.resourceSize > 50 * 1024));
const finalScore = (INIT_SCORE - overSizeList.length * 0.5) / 100;
const headings = [
{ key: 'url', itemType: 'thumbnail', text: '资源预览' },
{ key: 'url', itemType: 'url', text: '图片资源地址' },
{ key: 'resourceSize', itemType: 'bytes', text: '原始大小' },
{ key: 'transferSize', itemType: 'bytes', text: '传输大小' }, ];
return {
score: finalScore,
displayValue: `${overSizeList.length} / ${imageList.length} Size > 50 KB`,
details: Audit.makeTableDetails(headings, overSizeList),
};
}
}
module.exports = ResourceSizeAudit;meta:返回审查器的元信息requiredArtifacts:当前审查器依赖的采集器,必填
audit:经过计算,返回本次审查结果score:本次审查的分数,必填displayValue:审查结果(字符串值)details:为报告提供的额外信息,支持多种格式
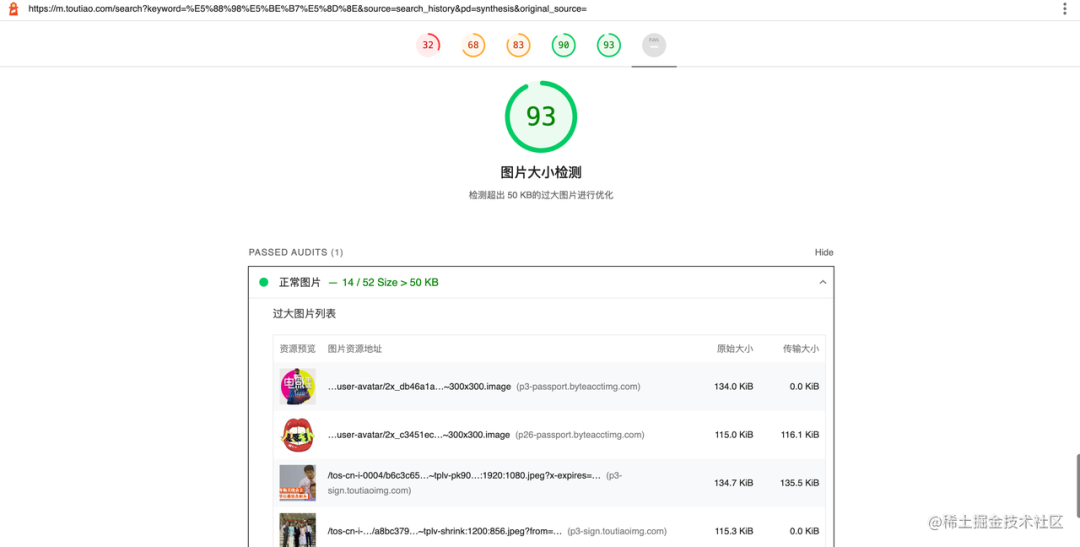
注意事项
cli 的性能评分与 devtool 会有一定差距,甚至相同平台每次跑的性能评分也会有较大差距,以参考为主
更适合做比较稳定的测量,比如资源加载类,DOM节点类
总结与未来展望
上述中台是在支持日常业务之余不断去迭代的,功能上还有很多不完善以及待优化之处。
从业务层面考虑:在建设它的这几年,它比较好的承担了业务对于监控中台的需要,并且为业务解决了大多数的问题。
从技术层面来考虑:未来还有很多能做的东西
底层能力
更完善灵活的日志能力支持
更底层的服务监控能力
归因能力 由经验型归因到智能型归因 => 智能运维
经验型归因:提供尽可能全面的信息帮助定位问题,最后取决于业务同学的经验
智能型归因:通过对历史数据集的最大化利用,利用算法智能推导异常原因,常规问题降低工程师精力占用
大流量场景下的中台稳定性问题
网关负载
限流
云原生能力
更快速稳定的扩缩容
Prometheus云原生监控...
本质上来说,我们做的一切技术工作都是为了业务提效。
在监控运维能力的各个方向都有更多的资源去探索深入的时候,我们可以依托于这些能力去建设更稳定的服务。
工程师就可以有更多的精力去放在业务的迭代和技术的提升中,让我们的技术工作更有价值。
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
如果你觉得这篇内容对你有帮助,我想请你帮我2个小忙:
1. 点个「在看」,让更多人也能看到这篇文章2. 订阅官方博客 www.inode.club 让我们一起成长
点赞和在看就是最大的支持❤️







![[附源码]Python计算机毕业设计Django姜太公渔具销售系统](https://img-blog.csdnimg.cn/cad53fdad5c143dc8a2a6a0110699886.png)