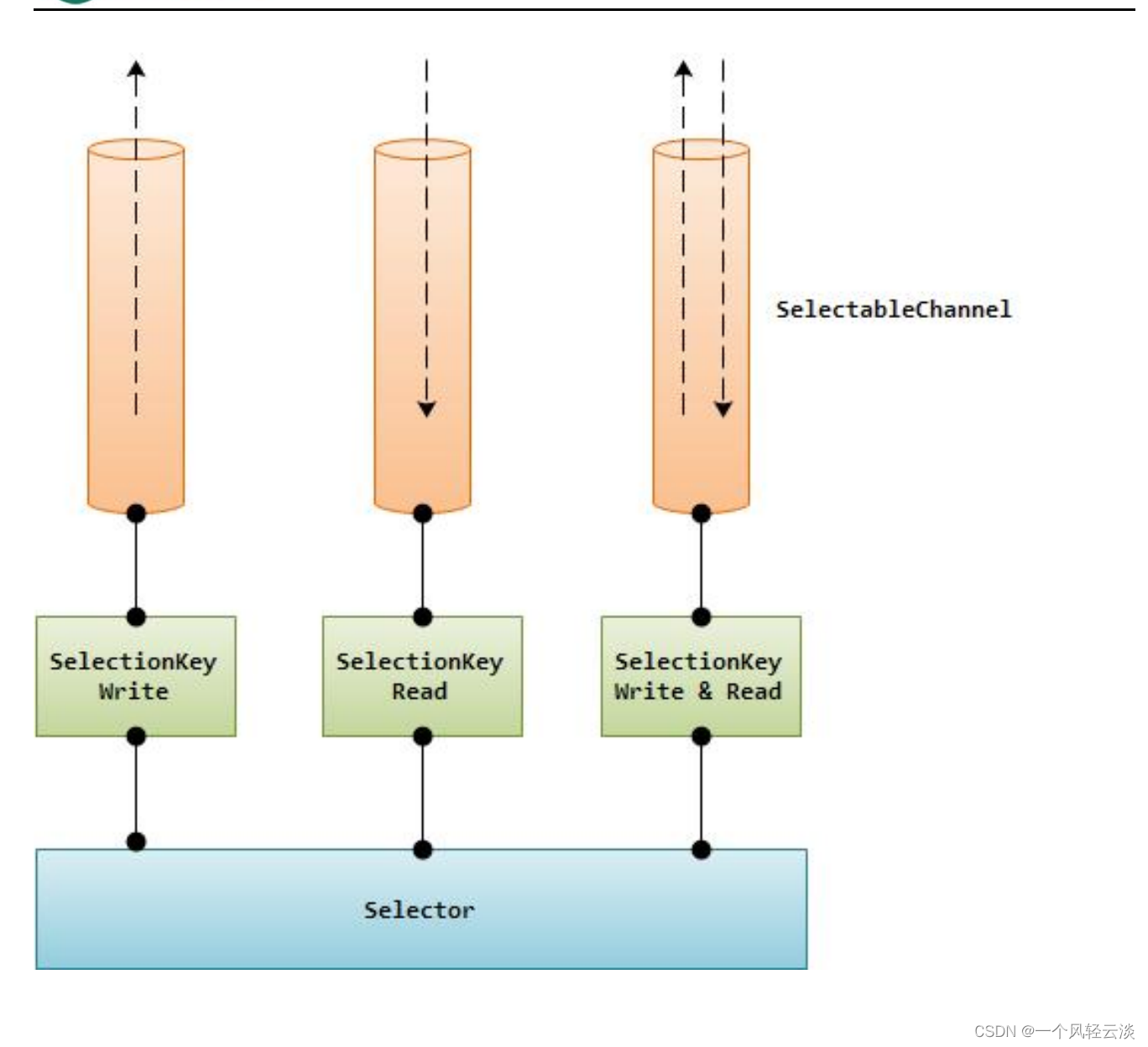
目录
前言
AI唱"基尼太美"是什么感觉
使用so-vits-svc打造自己专属歌手
1.声音素材整理
2.训练模型
3.让AI唱歌编辑
AI歌手背后的技术
AI歌手会成为主流吗
写到最后
大家好,我是大侠,AI领域的专业博主
前言
在5月份,孙燕姿再次成为了乐坛的顶流,但这一次她火爆的并不是她本人,而是AI孙燕姿。2023乐坛最佳新人奖非她莫属~
AI唱"基尼太美"是什么感觉
大侠看着也手痒啊,于是训练了一个孙燕姿版的篮球战歌

接下来 开始ctrl
原音频
http://image.aidaxia.net/start.mp3
AI唱“鸡你太美”
http://image.aidaxia.net/end.wav

通过音频可以清晰地听出,咯咯的声音已经完全变成了孙燕姿的声音。而令人惊叹的是,这个声音仅经过不到2000次的训练就已经达到了如此高的仿真度。
使用so-vits-svc打造自己专属歌手
大侠使用的是开源项目 <so-vits-svc> 来训练的AI歌手
项目地址 https://github.com/svc-develop-team/so-vits-svc

1.声音素材整理
注意So-VITS-SVC只能识别WAV格式的音频文件。
1.使用UVR来处理音频文件
使用UVR去除背景音、噪音、呼吸声等,只保留纯粹的人声,以保证最佳的语音识别效果。
2.把处理好的音频文件切片
为了避免显卡显存崩溃,建议在使用So-VITS-SVC训练声音素材时,每段音频不要超过30秒。
可以使用<Audio Slicer>来将音频文件切分成合适长度的片段。

在So-VITS-SVC的/dataset_raw目录下创建一个文件夹,并将刚才处理好的音频数据放到里面。
2.训练模型
打开So-VITS-SVC根目录下的【启动webui.bat】文件,启动Web UI界面,并切换到训练Tab选项卡。然后点击“选择数据集”按钮,选择你的数据集文件夹,上方会显示数据集文件夹的名称,这也将成为你训练模型的名称。
然后点击“写入配置文件”准备工作就OK了。
接下来点击下面"从头开始训练"就可以丢到一边训练模型了,是不是很简单
3.让AI唱歌
切换到“推理”选项卡,然后刷新页面选择你训练的模型(以G_开头),然后选择配置文件并加载模型。
在页面下方上传你需要转换的音频文件,然后等待转换完成即可。
如果转换后的声音质量不佳,比如听起来不够清晰,带有电流声等问题,你可以返回到训练界面,点击“继续训练”,直到满意为止。
AI歌手背后的技术
So-VITS-SVC是基于深度神经网络的语音转换模型,它主要使用了以下技术:
-
声码器:使用WaveNet作为声码器,WaveNet是一种基于卷积神经网络的生成式模型,能够生成高质量的音频信号。
-
风格迁移:使用CycleGAN作为风格转换器,CycleGAN是一种基于生成式对抗网络(GAN)的模型,能够将音频的风格转换为目标风格,例如将男性的声音转换为女性的声音。
-
语音识别:使用语音识别模型,例如DeepSpeech,来提取语音特征,以便进行音频转换。
-
深度学习:使用深度学习技术,如循环神经网络(RNN)和卷积神经网络(CNN),来训练模型进行语音转换。
AI歌手会成为主流吗
随着AI歌手的爆火,我们不时会想到AI歌手真的会取代歌手,全面进入AI娱乐时代吗,
我们先来看看AI歌手的优缺点
它的优点很明显:
-
声音非常纯净,几乎听不到换气的声音。
-
拥有无限的歌曲库(AI歌手不需要休息时间,只要有电就能创作)。
-
效率非常高(转换一首歌只需要2分钟,可以在短时间内创作大量的歌曲)。
当然,它的缺点也很明显:
-
情感方面不如人类歌手,AI歌手的声音听起来缺乏感染力。
-
创作性方面也还不够,AI发展还处于初级阶段。
-
道德和安全问题是最致命的问题,AI歌手不仅可以用来唱歌,还可以被不法分子用来模仿人的声音进行诈骗等危险行为,这已经发生了多起事件,涉及金额高达数百万。此外,还涉及到著作权、知识产权等问题。
“AI娱乐”在大侠看来以后肯定会成为主流,但从技术层面和管控方面来看,仍需要进一步提升和加强。我们期待AI娱乐的发展能够更好地保障道德和安全问题,同时也期待这个时代早日到来。
写到最后
AI歌手已经为我们打开了一扇通往音乐世界的新窗口。
未来,还有更多的AI文化创意产业值得我们去探索和期待,例如AI艺术、AI影视等领域。
这些新兴领域不仅将为我们带来全新的艺术体验,也将为创作者和文化产业带来更多的机遇和挑战。
AI是一个充满机遇和挑战的领域,
AI时代已经到来,AI真的会取代我们吗?
你还不主动了解AI?
你还在为跟同事聊AI插不上话吗?
那请关注大侠,带你了解AI行业第一动态。