文章目录
- 开始之前
- 下载依赖
- 数据集下载
- 新建配置文件
- 执行训练
- 模型选择
- 训练完成
- 测试模型进行预测
- 自定义模型下载
- 数据集下载地址分享
- 问题
开始之前
你应当先克隆这个仓库
git clone https://github.com/ultralytics/yolov5 # clone
下载完毕后,进入克隆的仓库目录
cd yolov5
下载依赖
pip install -r requirements.txt # install
数据集下载
这里我准备了一份数据集,为了方便下载,数据集数据并不是很多,末尾我会共享几个数据集下载地址:
垃圾分类数据集下载
提取码:nr5i
解压后,你会看到这几个文件夹:

随机查看部分内容

我这里解压到了一个 mydata 目录。这不是必须的,但一会你需要可以找到你的数据集目录。
新建配置文件
其中各个文件的含义大体如下:
0: cardboard #纸板
1: glass #玻璃
2: metal #金属
3: paper #纸
4: plastic #塑料
5: trash #垃圾
执行训练
开始之前,请预先下载 yolov5s-cls.pt 模型,记住这个位置,因为下面开始训练钱你需要用到它。
点击下载yolov5s-cls.pt模型
python classify/train.py --model yolov5s-cls.pt --data mydata --epochs 5 --img 224 --batch 128
模型选择
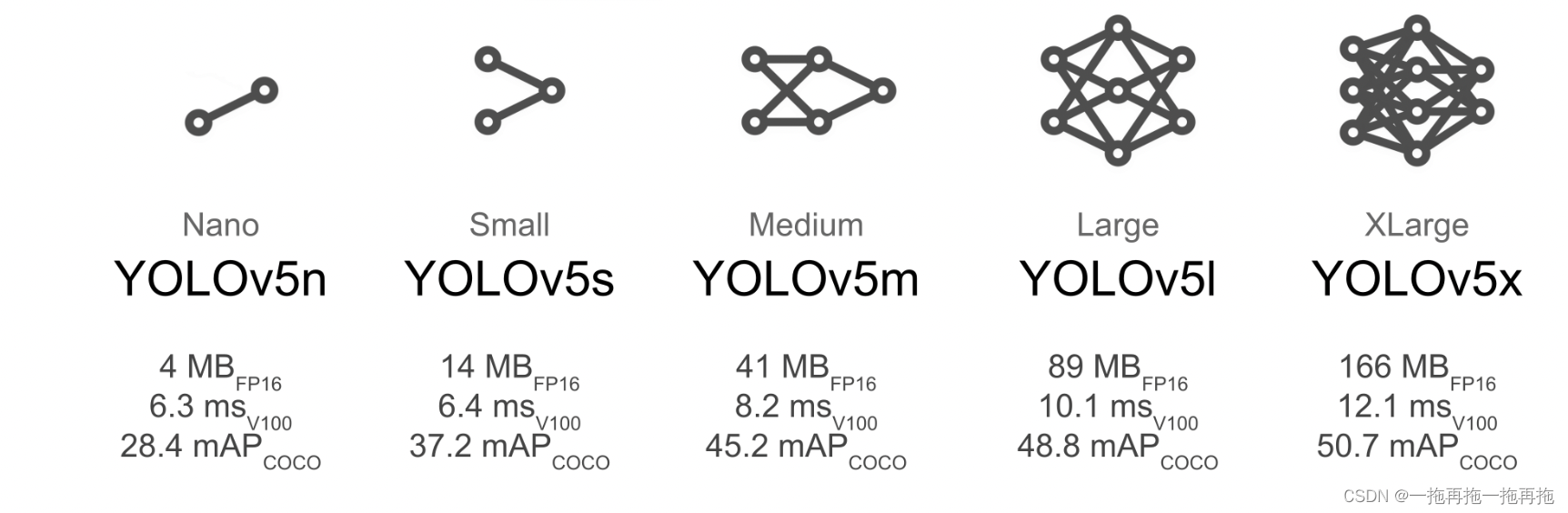
执行训练的时候使用了 --model yolov5s-cls.pt ,这是一种模型,你可以参考下图具体选择,如我们选择 yolov5x ,就可以使用 --model yolov5x-cls.pt ,推荐使用 yolov5s,除非你要求的准确度非常高,不然你需要花费非常长的时间和足够的硬件支持来训练它。
训练完成
那个 best.pt 就是训练好的模型,它在 runs/ 目录下
测试模型进行预测
选择一张图片进行测试:

python classify/predict.py --weights runs/train-cls/exp9/weights/best.pt --source metal4.jpg

恭喜你,成功的训练了一个简单的分类模型。
自定义模型下载
如果你不想进行从头训练模型,可以下载这个已经训练好的模型进行上一步的 测试模型进行预测。
分类模型下载
提取码:jycq
数据集下载地址分享
1:数据集下载地址1
2:数据集下载地址2
问题
如果运行当中出现问题,欢迎咨询。