jieba.NET是jieba中文分词的C#版本,后者是优秀的Python中文分词组件GitHub中得到超过3万星。jieba.NET支持中文分词、关键词提取、词性标注等功能,本文主要测试其中文分词的功能基本用法。
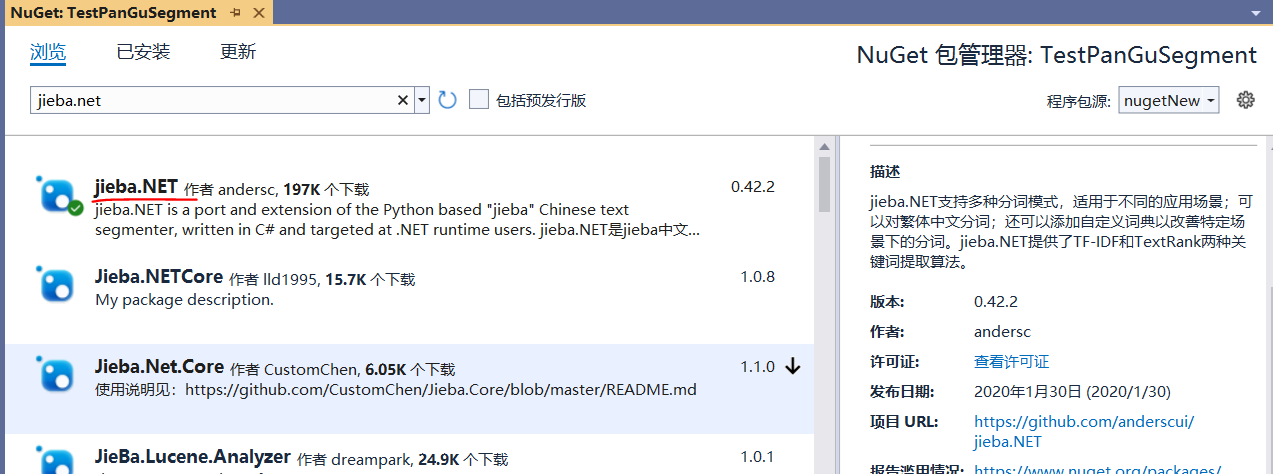
新建测试项目,在NuGet管理器中添加jieba.NET。
jieba.NET程序集中与分词相关的主要是JiebaSegmenter.Cut函数和JiebaSegmenter. CutForSearch函数,这两个函数都以字符串作为分词输入,不像之前盘古分词支持流式输入。
public IEnumerable<string> Cut(string text, bool cutAll = false, bool hmm = true)
public IEnumerable<string> CutForSearch(string text, bool hmm = true)
基于这两个函数,jieba.NET支持多种分词模式(介绍来自参考文献3):全模式(把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义)、精确模式(试图将句子最精确地切开)、搜索引擎模式(在精确模式的基础上,对长词再次切分,提高召回率)。这三种方式的代码其实都比较简单,如下所示:
//精确分词模式
using (TextReader tr = File.OpenText(txtPath.Text))
{
var segmenter = new JiebaSegmenter();
var segments = segmenter.Cut(tr.ReadToEnd());
txtResult.Text=string.Join("/ ", segments);
}
//全模式
using (TextReader tr = File.OpenText(txtPath.Text))
{
var segmenter = new JiebaSegmenter();
var segments = segmenter.Cut(tr.ReadToEnd(),cutAll:true);
txtResult.Text=string.Join("/ ", segments);
}
//搜索引擎模式
using (TextReader tr = File.OpenText(txtPath.Text))
{
var segmenter = new JiebaSegmenter();
var segments = segmenter.CutForSearch(tr.ReadToEnd());
txtResult.Text=string.Join("/ ", segments);
}
精确分词模式的效果如下图所示: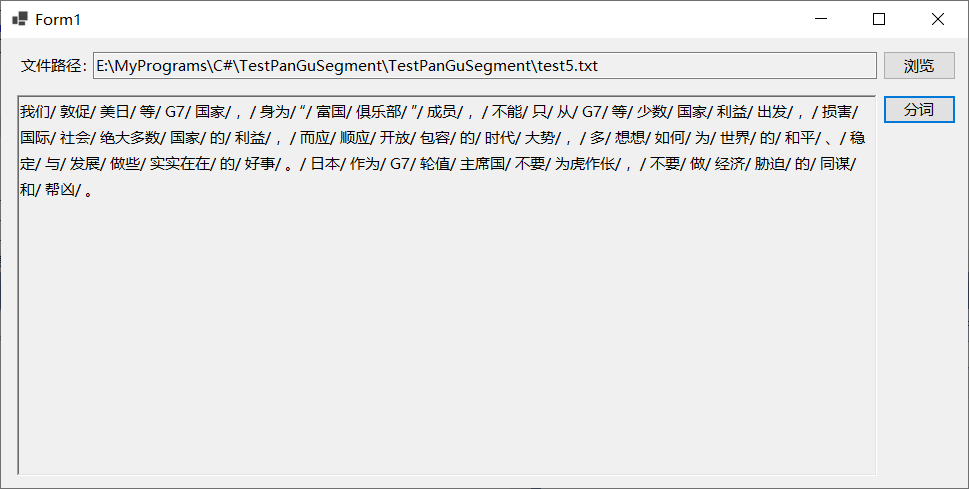
全模式分词的效果如下所示,与精确分词相比,全模式把所有可能的分词都返回了,如“少数国家”一次,静默分词返回的是“少数”和“国家”,而全模式返回的是“少数”、“数国”、“国家”。

搜索引擎模式的分词效果如下图所示,与上面两种方式相比也有不同之处:

测试代码比较简单,值得说明的是jieba.NET的分词速度(全模式:2.5 MB/s
精确模式:1.1 MB/s),测试盘古分词时,导入几十K的文本分词就会卡死,而采用jieba.NET则速度特别快就可以返回分词结果。
jieba.NET还支持并行分词及提取关键词等功能,后续会继续测试这些功能的基本用法。
参考文献:
[1]https://github.com/linezero/jieba.NET
[2]https://www.jianshu.com/p/6f47b670fcb0
[3]https://github.com/anderscui/jieba.NET
[4]https://github.com/JimLiu/Lucene.Net.Analysis.PanGu
[5]https://github.com/apache/lucenenet
[6]https://blog.csdn.net/lijingguang/article/details/127262360
[7]https://blog.51cto.com/u_15834522/5766716
[8]https://www.cnblogs.com/dacc123/p/8431369.html
[9]https://blog.csdn.net/wangkun9999/article/details/1574114