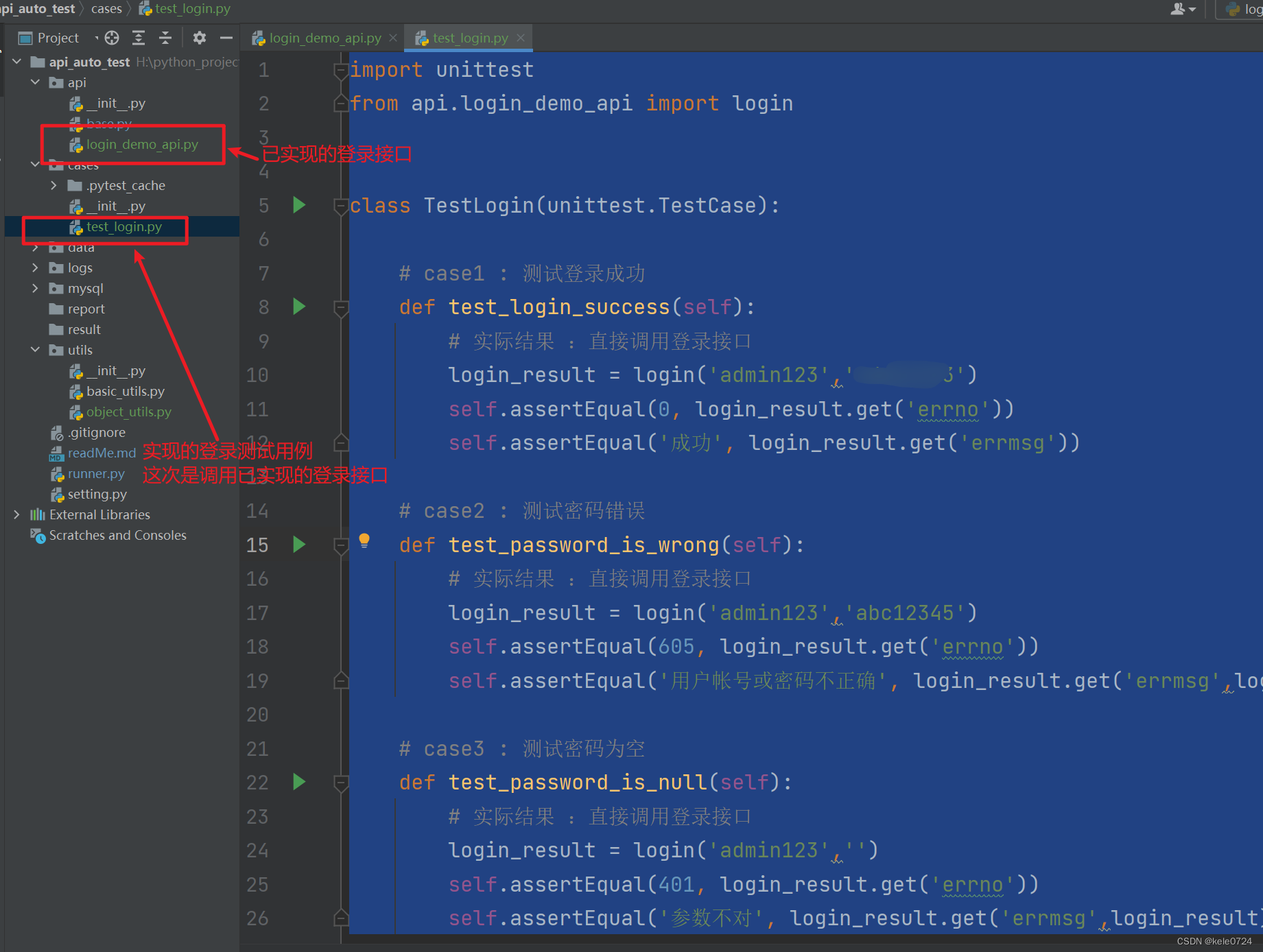
BERT适合分类任务(整段分类后者词分类),对生成任务不友好
使用BERT的方法:只需要在预训练好的BERT基础上新增一个输出层,然后用标记好的数据进行有监督微调
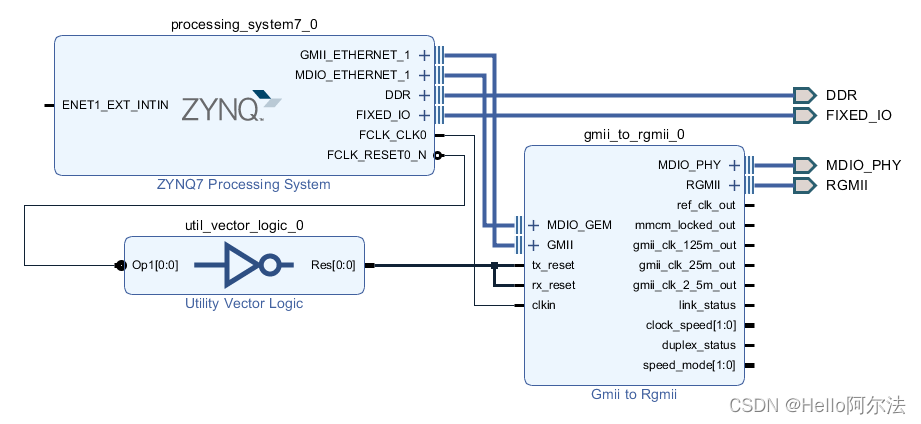
Bidirectional Encoder双向Encoder实质上就是指Transformer中的encoder,双向是指在self-attention的每个位置能看到左/右两侧的上下文信息
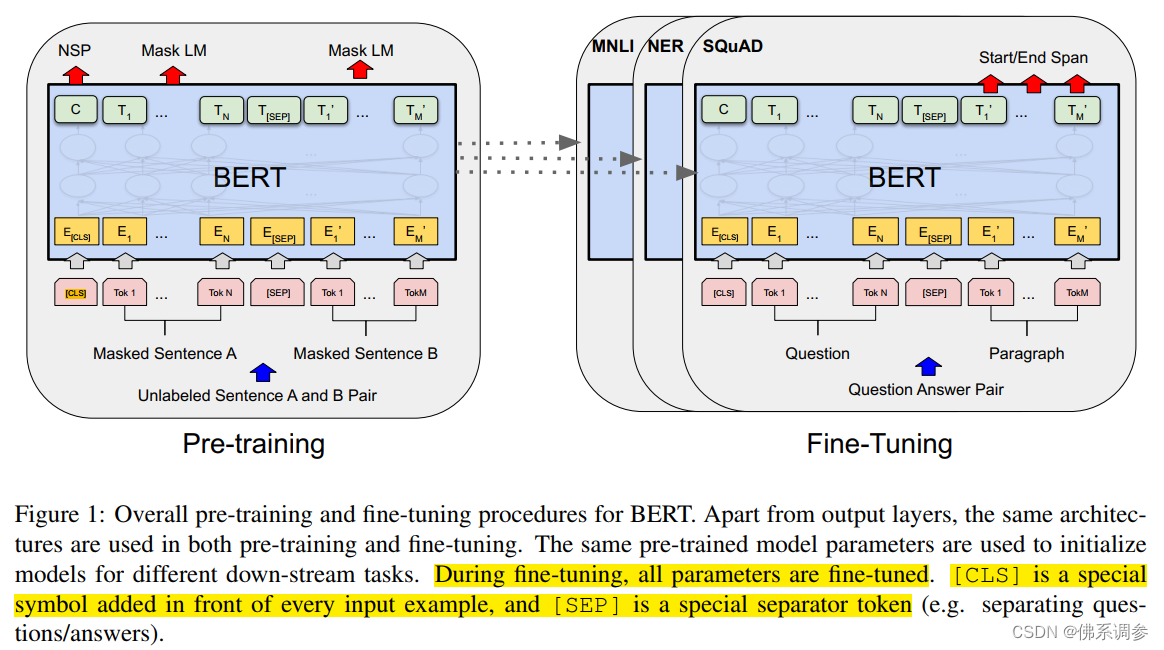
BERT由两大部分组成
1.预训练
有两种预训练任务
(1)Masked LM

每个sentence随机masked掉15%的token。因为在微调时候是没有[MASK]这个特殊token的,为了弥补预训练和微调时的这个mismatch,作者采用如下策略:
1.80%的概率为[MASK]
2.10%的概率是随机的token
3.10%的概率不改变,仍是原来的token

(2)NSP, Next Sentence Prediction
输入两个句子A和B,B有50%的概率是A的下一句,50%的概率不是。采用[CLS]对应的输出向量进行二分类训练
2.微调
预训练好的模型参数也全部参与训练
额外增加一个输出层进行训练。
本质是分类模型:[CLS]对应输出向量用于整个分类,其余token对应的输出向量用于token-level的分类。用softmax函数实现多分类
网络结构
BERT-BASE, L=12, H=768, A=12,110M即1.1亿参数(和GPT-1具有相近参数)
BERT-LARGE, L=24, H=1024, A=24,340M即3.4亿参数
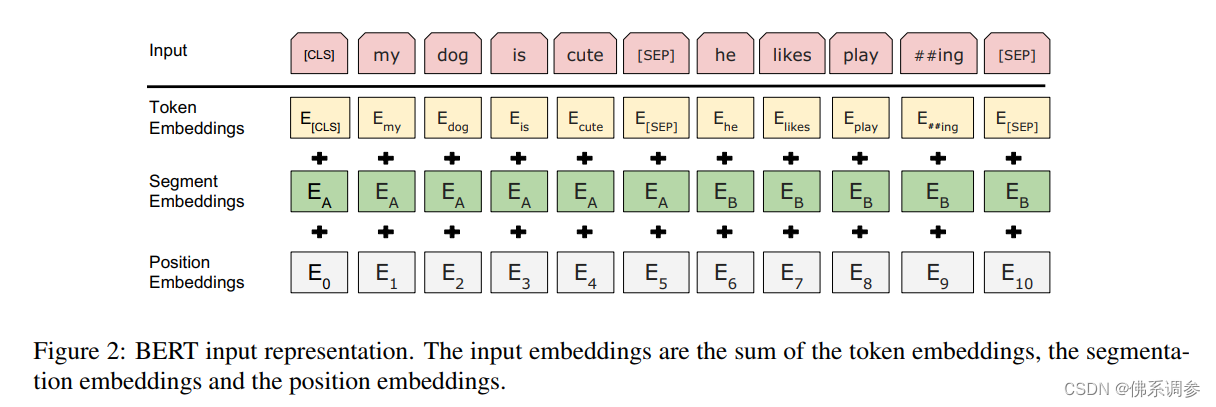
输入输出表示
为了兼容多种下游任务,BERT输入可以是一个句子或者两个句子,统称为一个Sequence
采用WordPiece embeddings,这样输入字典为3w个token(以空格区分,每个单词作为token的话,字典会非常大)
输入的第一个token永远是[CLS],[CLS]的BERT输出向量(维度也为H)可用于整个句子的分类
每个输入句子后面都跟一个分隔符[SEP],因此输入句子对pair的话会有两个[SEP]
每个输入token的embedding由三部分组成,三个embedding都是通过网络学习得到的


![在vite或者vue-cli中使用.env[mode]环境变量](https://img-blog.csdnimg.cn/0a01356b41a242baaffeafa7ba5c53a6.png)