参考:LangChain中文入门教程
LangChain官网
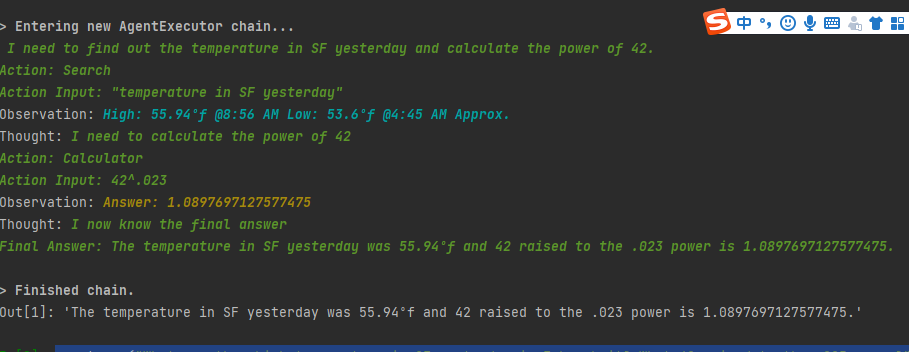
通过 Google 搜索并返回答案
import os
os.environ["OPENAI_API_KEY"] = "xxx"
os.environ['SERPAPI_API_KEY'] = "xxx"
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
# First, let's load the language model we're going to use to control the agent.
llm = OpenAI(temperature=0)
# chroma搜索
# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# Now let's test it out!
agent.run("What was the high temperature in SF yesterday in Fahrenheit? What 42 raised to the .023 power?")
关于agent type 几个选项的含义:
- zero-shot-react-description: 根据工具的描述和请求内容的来决定使用哪个工具(最常用)
- react-docstore: 使用 ReAct 框架和 docstore 交互, 使用Search 和Lookup 工具, 前者用来搜, 后者寻找term, 举例: Wipipedia 工具
- self-ask-with-search 此代理只使用一个工具: Intermediate Answer, 它会为问题寻找事实答案(指的非 gpt 生成的答案, 而是在网络中,文本中已存在的), 如 Google search API 工具
- conversational-react-description: 为会话设置而设计的代理, 它的prompt会被设计的具有会话性, 且还是会使用 ReAct 框架来决定使用来个工具, 并且将过往的会话交互存入内存
Gradio工具
stable fiffusion作图
from gradio_tools.tools import StableDiffusionTool
local_file_path = StableDiffusionTool().langchain.run("Please create a photo of a fox riding a skateboard")

构建本地知识库问答机器人
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI,VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('../source_documents/', glob='*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)
# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch,return_source_documents=True)
# 进行问答
query = "who the little prince meet first"
result = qa({"query": query})
print(result)
# 链式问答
from langchain.chains.question_answering import load_qa_chain
docs = docsearch.similarity_search(query, include_metadata=True)
llm = OpenAI(temperature=0)
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
chain.run(input_documents=docs, question=query)

视频问答
# 加载 youtube 频道
loader = YoutubeLoader.from_youtube_url('https://www.youtube.com/watch?v=9qq6HTr7Ocw')
loader = BiliBiliLoader(['https://www.bilibili.com/video/BV1xt411o7Xu/'])
# loader = BiliBiliLoader(['https://www.bilibili.com/video/BV1Ch411j7Bb']) Return Empty transcript.
# 加载blibili 频道
# 将数据转成 document
documents = loader.load()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=20
)
# 分割 youtube documents
documents = text_splitter.split_documents(documents)
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings()
# 将数据存入向量存储
vector_store = Chroma.from_documents(documents, embeddings)
# 通过向量存储初始化检索器
retriever = vector_store.as_retriever()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{context}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template('{question}')
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate.from_messages(messages)
# 初始化问答链
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.1,max_tokens=2048),retriever,condense_question_prompt=prompt)
chat_history = []
while True:
question = input('问题:')
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa({'question': question, 'chat_history': chat_history})
chat_history.append((question, result['answer']))
print(result['answer'])