参考书籍:(找不到资源可以后台私信我)
《深度学习入门:基于Python的理论与实现 (斋藤康毅)》
CNN
概括

其中pooling层有时候会被省略,卷积层的输入输出图像称为特征图(feature map),即输入特征图和输出特征图。
卷积层
全连接层输入时输入的是1维的数据,多维数据需要被拉平,但卷积层可以保持形状不变。
卷积层进行的处理就是卷积运算、滤波器运算。滤波器相当于affine的weights,b可以用一个数值,这个值会加到所有数上。

可以看到,这样的维度是变了,那为了让最终结果仍然是4x4的,就必须要对输入数据进行填充,如下图,填充一圈0。
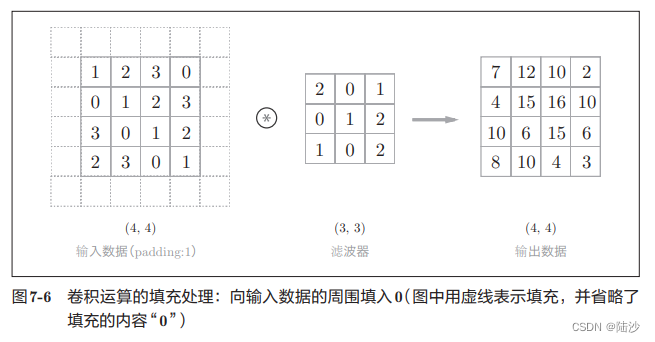
应用滤波器时,步幅(stride)指的是滤波器移动一次的距离。比如上面都是每次往右或者往下移动一格,所以步幅是1。

OH和OW应该是整数,如果是小数的话需要四舍五入或者报错。
如果是多维度的数据(比如三维,输入数据多了几张特征图/矩阵,这个几就是通道数),那么滤波器的通道数应该跟输入数据的通道数一致,而且每个通道的滤波器大小要一致。
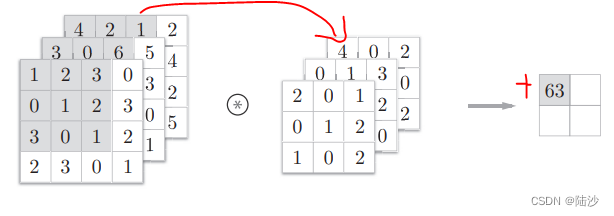
如果希望得到多通道的结果,那么需要加滤波器,几个滤波器几个通道。下图还加了偏置。
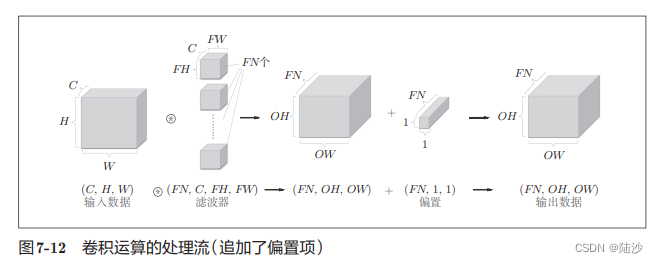
批处理时,需要将数据保存为4维数据,按(batch_num, channel, height, width)的顺序保存。即将N次处理汇总成1次进行。
池化层
池化是缩小高、长方向上的运算。比如下图是max池化(步幅为2),就是选4x4里最大的值放入新矩形。
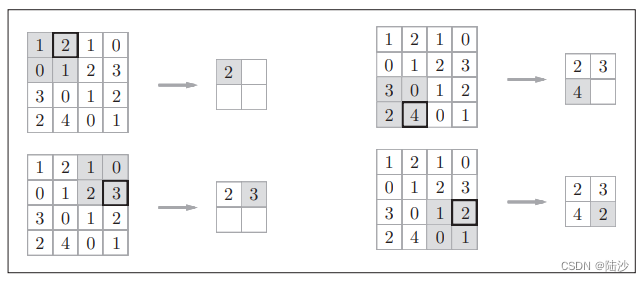
一般池化的窗口大小与步幅一致。图像识别领域经常使用Max池化,但也还有别的池化方式,比如Average(取矩形里平均值填入新矩形)。
池化层的特征:
- 没有要学习的参数
- 通道数不变
- 对微小的偏差有鲁棒性
卷积层和池化层的实现技巧
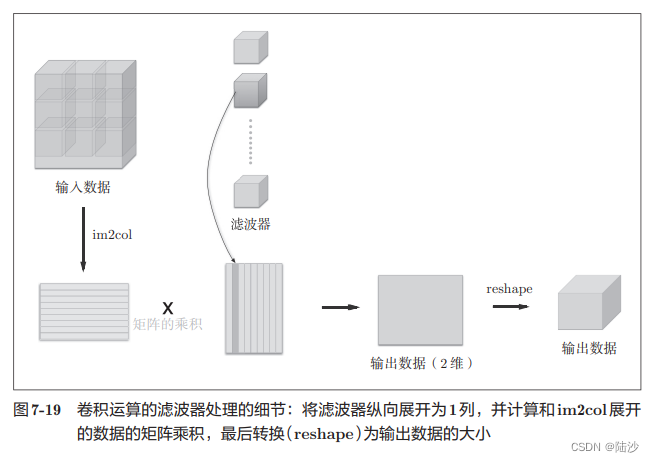
imcol(input_data, filter_h, filter_w, stride=1, pad=0)
卷积层反向传播时,需要进行im2col的逆处理col2im
如果有多个卷积层,最开始的层可能对简单边缘有响应,接下来的层可能对纹理响应,再后面的可能对部件响应。随着层次加深,神经元理解的信息也越来越复杂。
LeNet:1998年提出,用于手写数字识别。AlexNet
深度学习
深度学习是加深了层的深度神经网络。
Data Augmentation 数据扩充:比如mnist数据集,将某些训练图像进行旋转和平移产生新图像以扩充训练集。还可以用裁剪、左右翻转、亮度变化、放缩等。
加深层的好处:
- 可以用更少的参数(小滤波器叠加)达到相近的效果
- 使学习更高效,即可以用更少的学习数据,因为每一层都学习一点点,相当于分解了问题
实践中经常会灵活应用使用ImageNet这个巨大的数据集学习到的权重数据,这称为迁移学习,将学习完的权重(的一部分)复制到其他神经网络,进行再学习(fine tuning)。比如,准备一个和VGG相同
结构的网络,把学习完的权重作为初始值,以新数据集为对象,进行再学习。迁移学习在手头数据集较少时非常有效。
GPU主要由NVIDIA和AMD两家公司提供。虽然两家的GPU都可以用于通用的数值计算,但与深度学习比较“亲近”的是NVIDIA的GPU。这是因为深度学习的框架中使用了NVIDIA提供的CUDA这个面向GPU计算的综合开发环境。cuDNN是在CUDA上运行的库,它里面实现了为深度学习最优化过的函数等。