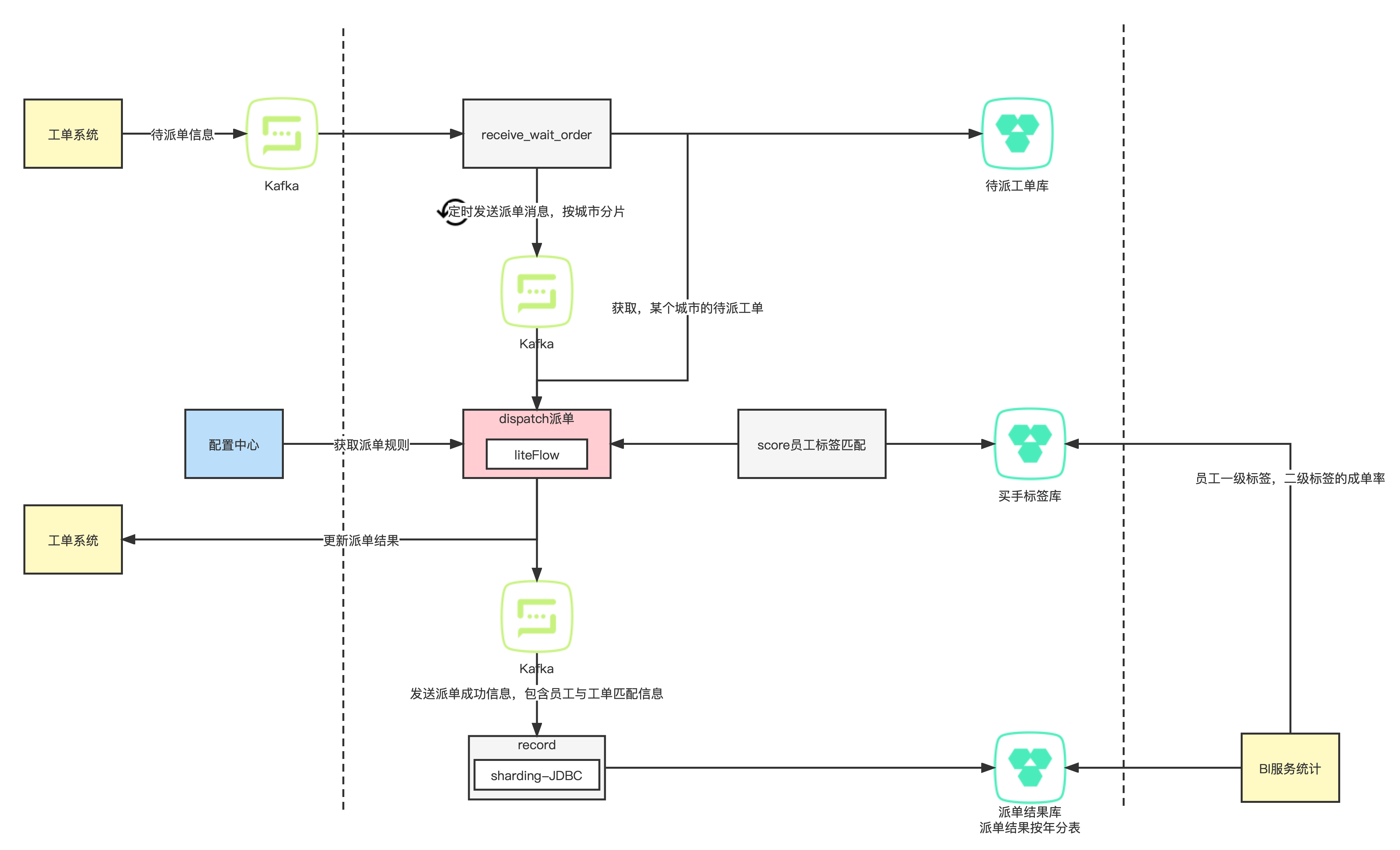
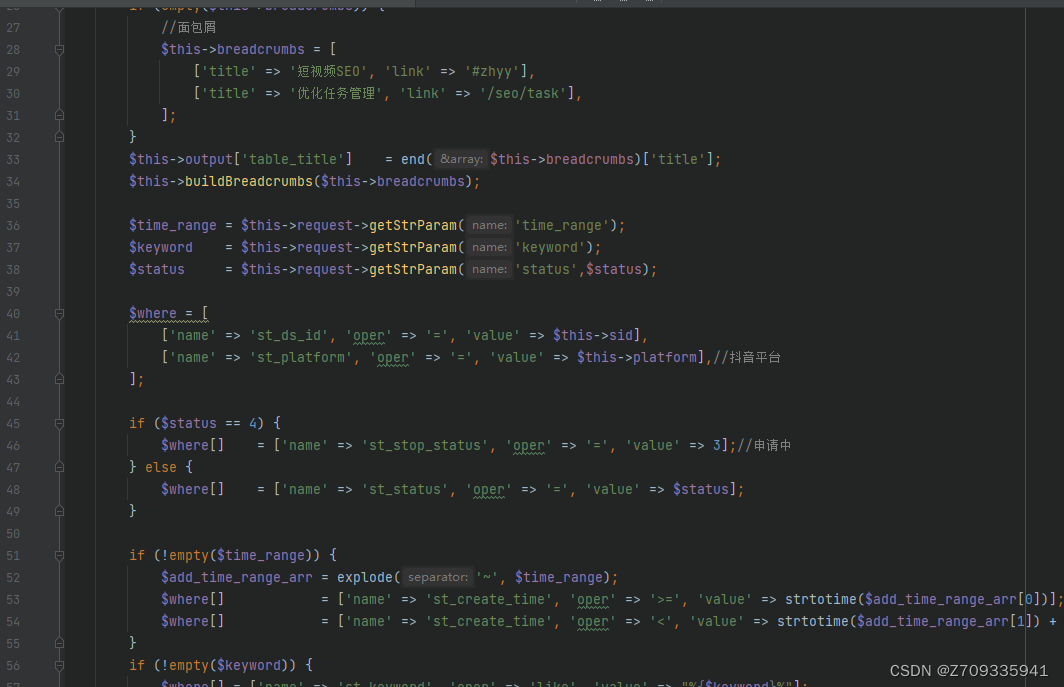
爬虫需要动态IP主要是为了避免被目标网站封禁或限制访问。如果使用固定IP进行爬取,很容易被目标网站识别出来并封禁,导致无法继续爬取数据。而使用动态IP可以让爬虫在不同的IP地址之间切换,降低被封禁的风险。此外,动态IP还可以帮助爬虫绕过一些反爬虫机制,提高爬取效率。

远程桌面VPS可以用来做爬虫,具体步骤如下:
1、购买远程桌面,选择配置较高的VPS,以保证爬虫的速度和稳定性。
2、安装操作系统和必要的软件,如Python、Scrapy等。
3、编写爬虫程序,可以使用Scrapy框架,也可以使用其他Python爬虫库。
4、配置爬虫程序,设置爬取的目标网站、爬取频率、爬取深度等参数。
5、运行爬虫程序,可以使用命令行或者IDE等工具来运行。
6、定期检查爬虫程序的运行情况,及时处理异常情况。
需要注意的是,在进行爬虫时,需要遵守相关法律法规,不得进行非法爬取和侵犯他人隐私等行为。同时,也需要注意网站的反爬虫机制,避免被封禁IP等情况。
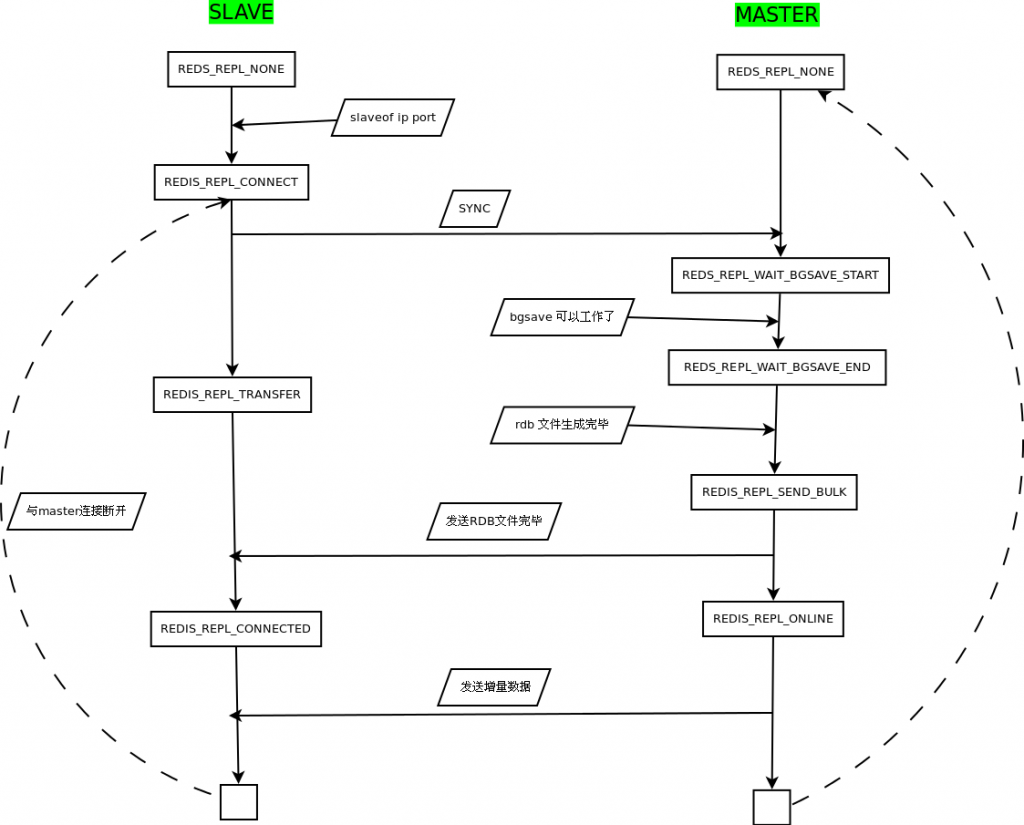
动态远程桌面是指通过远程连接到另一台计算机,进行操作。而爬虫是一种自动化程序,用于从网页中提取数据。因此,可以通过动态远程桌面连接到一台计算机,然后在该计算机上编写爬虫程序。
动态远程桌面写一个爬虫
以下是一个简单的Python爬虫示例,用于从网页中提取标题和链接:
import requests
from bs4 import BeautifulSoup
url = 'https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))
print(link.text)
该程序使用requests库发送HTTP请求,然后使用BeautifulSoup库解析HTML响应。它查找所有的链接标签,并打印出链接和文本。
当然,具体的爬虫程序需要根据具体的需求进行编写,例如需要考虑反爬虫机制、数据存储等问题。
以下是使用Python实现动态IP爬虫的示例代码:
import requests
from bs4 import BeautifulSoup
# 定义代理服务器地址和端口
proxy_host = 'proxy.example.com'
proxy_port = '8080'
# 定义代理服务器的认证信息
proxy_auth = {
'username': 'your_username',
'password': 'your_password'
}
# 定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 定义请求URL
url = 'http://www.example.com'
# 定义代理服务器的URL
proxy_url = 'http://{0}:{1}'.format(proxy_host, proxy_port)
# 定义代理服务器的认证信息
proxy_auth = requests.auth.HTTPProxyAuth(proxy_auth['username'], proxy_auth['password'])
# 定义代理服务器的参数
proxy_params = {
'http': proxy_url,
'https': proxy_url
}
# 发送请求
response = requests.get(url, headers=headers, proxies=proxy_params, auth=proxy_auth)
# 解析响应内容
soup = BeautifulSoup(response.text, 'html.parser')
在上面的代码中,我们使用了requests库来发送HTTP请求,并使用BeautifulSoup库来解析响应内容。我们还定义了代理服务器的地址、端口、认证信息和请求头信息,并将它们传递给requests库的get()方法。最后,我们使用代理服务器的URL和认证信息来定义代理服务器的参数,并将它们传递给get()方法的proxies和auth参数。