redis 是多线程还是单线程
redis单线程的操作
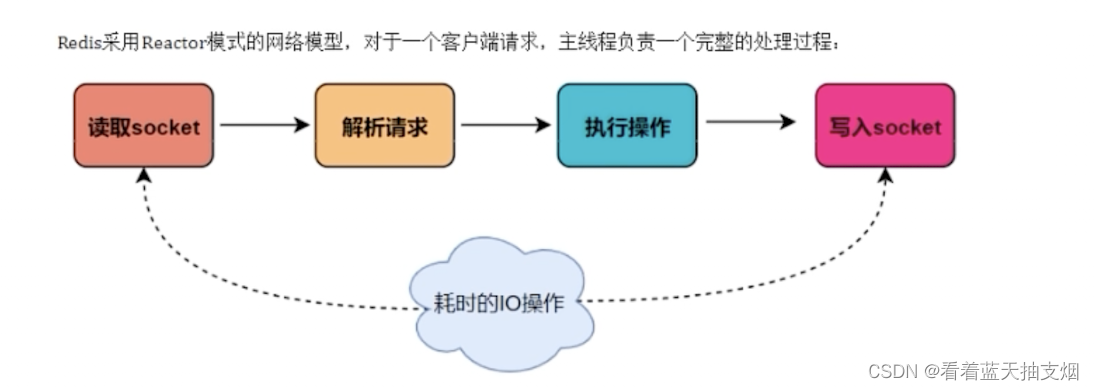
主要是指redis的网路IO和键值对的读写是由一个线程来完成的,Redis在处理客户端的请求时,包括获取(socket 读),解析,执行,内容返回(socket 写)等,这些按顺序串行的命令由一个线程执行,这就是所谓的单线程。这也是redis对外提供键值存储的主要流程。
比如redis-cli -a 11111 --raw 对应 创建socket 解析请求
set k1 v1 对应 执行操作 返回的结果对应 写入socket
redis 多线程的操作
但是redis其他功能,比如持久化RDB,AOF,异步删除,集群数据同步等等,其实是由额外的线程执行的。
所以redis命令工作线程是单线程的,但是对整个redis来说,是多线程的。
redis 3.0之前或者工资线程为什么要选择单线程
- 使用单线程模型使Redis开发维护更简单,因为单线程模型方便开发与调试。
- 即使使用单线程模型也可以并发的处理多客户端请求,主要是IO多路复用和非阻塞IO。
- redis是基于内存操作,因此他的瓶颈可能是机器的内存或者网络带宽,并非CPU。那么自然而然就采用单线程比较合适。但是在4.0以后支持多线程,例如RDB,AOF,后台删除等。
redis多路复用
背景
比如redis需要删除一个很大的数据使(几十万个k的hash),因为是单线程原子操作,这回导致Redis服务卡顿。于是在redis4.0中就新增了多线程模块,当然此版本是为了解决删除数据效率较低的问题。这就是lazy-free的体现
lazy-free的本质就是把某些耗时较高的操作,从主线程剥离让子线程处理极大的减少了主线程阻塞时间,从而增加稳定性。
抛开内存不谈,影响redis性能那就是网络IO。
redis6/7中,非常受关注的第一个新特性就是多线程。
这是因为,redis被大家熟知的就是他的单线程架构,虽然有些命令操作可用子线程执行(比如数据删除,快照生成,AOF重写)。但是,从网络IO处理到实际的读写命令处理,都是由单个线程完成的。
随着网络硬件的性能提升,Redis的性能瓶颈有时会出现在网络IO的处理上。也就是说单线程的处理网络请求的速度跟不上底层网络硬件的速度。
为了应对这个问题:
采用多个IO线程来处理网络请求,提高网路请求处理的并行度,Redis6/7采用的就是这种办法。
但是多个IO线程只是用来处理网络请求,对于读写命令Redis仍然使用单线程来处理。
这是因为,redis在处理请求时,网络处理经常是瓶颈,通过多个IO线程并行处理网络请求,可以提升实例的整体处理性能。而继续使用单线程(主线程)处理命令操作。就不用为了保证事物的原子性额外的开发多线程互斥加锁机制。
处理网络请求(主线线与IO线程是如何协作的)
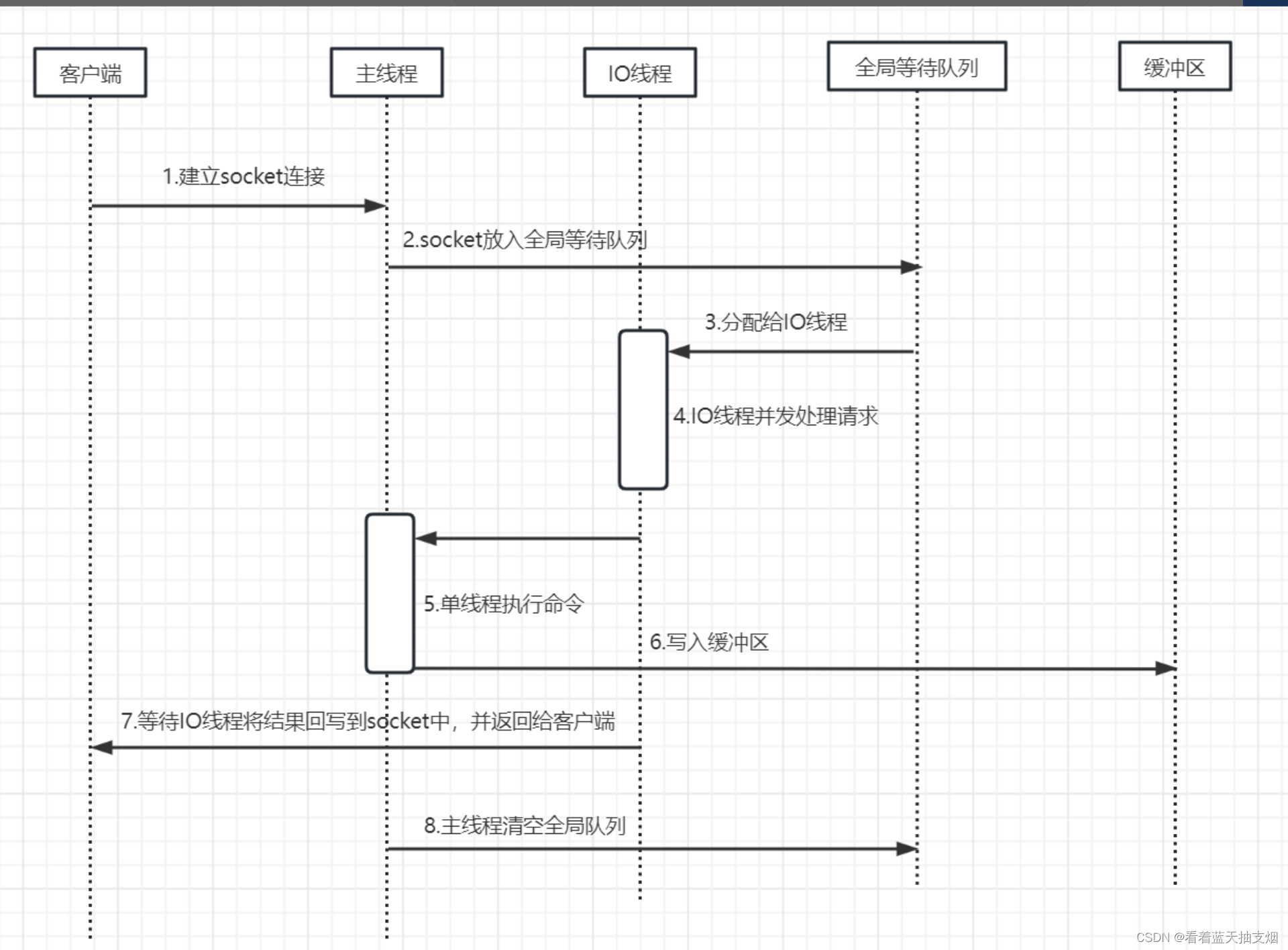
讲到了这里,我们其实接触了两种线程,一种是主线程,一个是IO线程。那这两种线程是如何协作的呢?主要是以下4个步骤。
- 客户端与服务端建立socket链接(redis-cli -a 111111)
主线程负责建立连接,并把socket放入全局等待队列,主线程通过轮询的方法将socket连接分配给IO线程。 - IO线程读取并解析请求(读取命令(set k1 k1),解析命令(set k2 v1))
主线程一旦把socket分配给IO线程,就会进入阻塞状态,等待IO线程完成客户端请求,此时采用多个IO线程并行处理。因为有多个IO并行处理,这个过程可以快速完成。 - 主线程执行解析后的命令(执行解析后的命令set k1 v1,get k1)
IO线程解析完请求,主线程还是会以单线程的方式执行这些命令。 - IO线程会写回socket和主线程清空全局队列
当主线程执行完请求命令后,会将结果写入缓冲区,主线程进入阻塞状态,等待IO线程将结果会写socket中,并返回客户端。这一步和IO线程读取和解析一样,也是有多个IO线程并行处理。也可以快速完成。
回写socket 完毕后,主线程清空全局队列
UNIX 网络编程中的5种IO模型
1.Blocking IO: 阻塞IO
2. NoBlocking IO :非阻塞IO
3. IO multiplexing: IO多路复用
4. signal drive IO:信号驱动
5. async IO :异步IO
Linux中一切皆文件,文件描述符 FD,句柄。FD实际是一个索引值,当程序打开一个文件或创建一个文件时,内核回返回一个文件描述符。
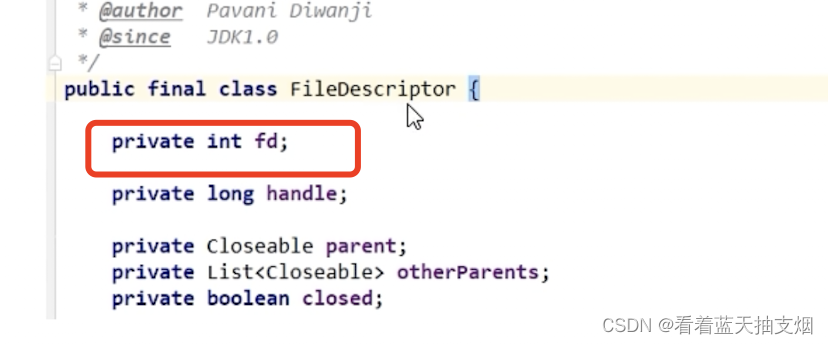
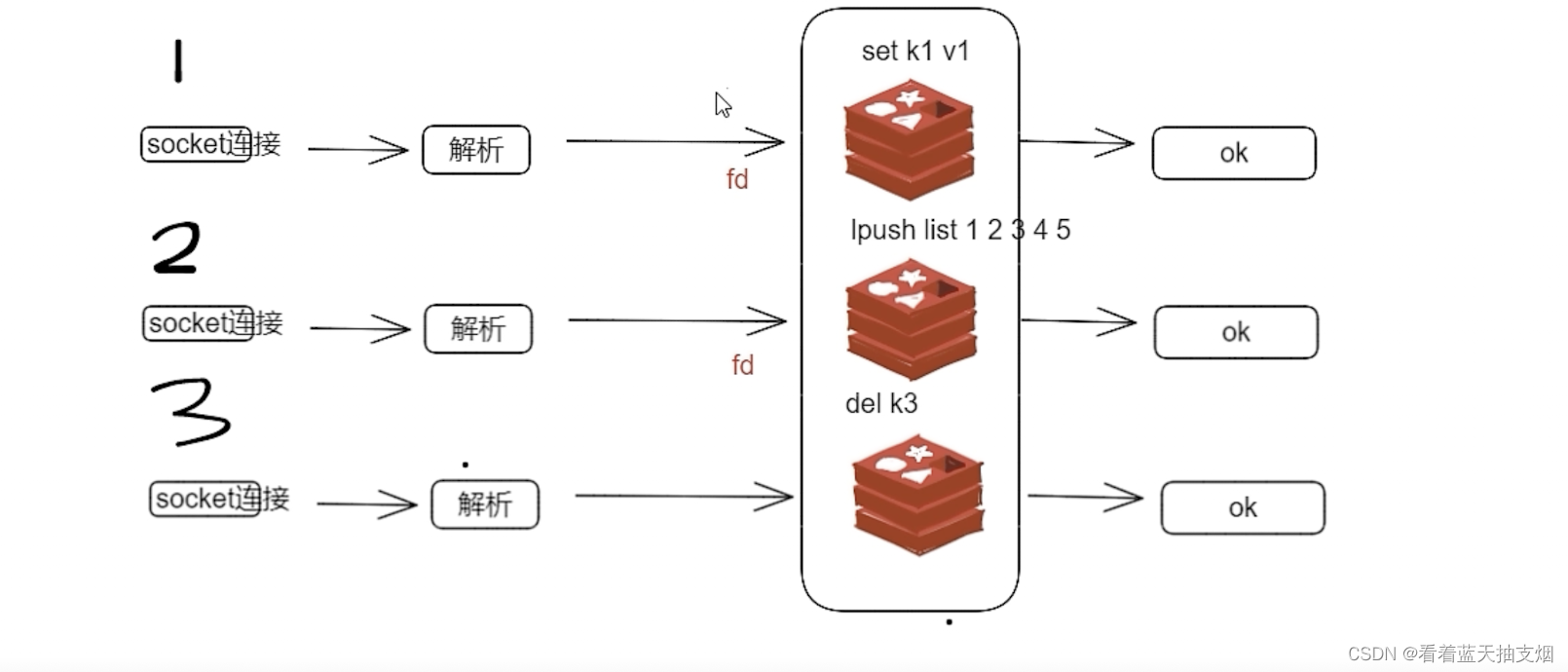
每次socket连接 都会产生一个fd,放入全局队列。
什么时IO多路复用呢
一个同步的IO模型,实现一个线程监视多个文件的句柄,一旦某个文件句柄就绪就能够通知对应的应用程序进行相应的读写操作。没有文件句柄就绪时,就会阻塞应用程序,从而释放CPU资源。
比如 get k1 到返回结果之间的过程,就是一个句柄就绪到读操作的过程。
I/O:网络IO,尤其在操作系统层面,是指数据在内核态和用户态之间的读写操作。
多路:多个客户端连接(连接就是套接字描述符,即socket或则channel)
复用:复用一个或多个线程
IO多路复用:也就是说一个或一组线程处理多个TCP连接,使用单线程就能够实现同时处理多个客户端连接,无需创建或维护过多的线程。
在简单一句话描述:一个服务端端进程可以同时处理多个套接字描述符,
实现多路复用的模型有3种。 select和poll以及epoll.
epoll 场景解释
模拟一个TCP服务器处理30个客户客户端 (1个redisserver,30个 redis-cli)
假设一个监考老师,监管30个学生考试,然后负责收卷。有下面几种选择
- 逐个验收(select轮询),这时候有一个同学不想交卷,全班都会被耽误,逐个处理不具备并发能力。
- 施展分身(poll一对一),创建30个分身(30个线程)
- 响应式处理(epoll一对多),站在讲台等,谁要交卷,举个手,老师去收卷。比如C,D举手,老师下去依次收卷。然后上台。上台后,E,F又举手,再去处理E,F.这就是IO多路复用模型。
因此epoll能够高效的处理成千上万的并发连接,而且性能不会随着并发量的升高而下降。
select :对socket是线性扫描,即轮询,效率较低。仅仅知道有IO事件发生,去不知道时那几个socket发生的IO事件。只会无差异的轮询所有的socket连接。找出能读写的sokect连接
。同时socket连接越多,轮询的时间越长。
如果我们不用轮询所有socket连接,而是让活跃的socket连接自己去反馈读写的就绪状态呢,是否可以提升效率呢。这就时epoll出现的原因。
redis 为什么这么快
- 基于内存操作:redis的所有数据都存储在内存中,所有的运算都是内存级别的,所以他性能别较高
- 数据结构简单:redis的数据结构是专门设计的,这些数据结构的查找和操作的时间复杂度基本都为O(1),因此性能较高
- I/O多路复用和非阻塞I/O:redis使用I/O多路复用功能来监听多个socket连接客户端,这样可以使用一个线程来处理多个请求,同时也避免了I/O阻塞操作。
- 避免上下文切换:因为单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了上下文切换的时间






![深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解](https://img-blog.csdnimg.cn/img_convert/122d38cf99ad6508cba58116815bbd63.png)