【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等

专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等
本专栏主要方便入门同学快速掌握相关知识。后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。
声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
专栏订阅:深度学习入门到进阶专栏
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解
1.Transformer-XL: Attentive Language Models Beyonds a Fixed-Length Context
1.1. Transformer-XL简介
在正式讨论 Transformer-XL 之前,我们先来看看经典的 Transformer(后文称 Vanilla Transformer)是如何处理数据和训练评估模型的,如图 1 所示。
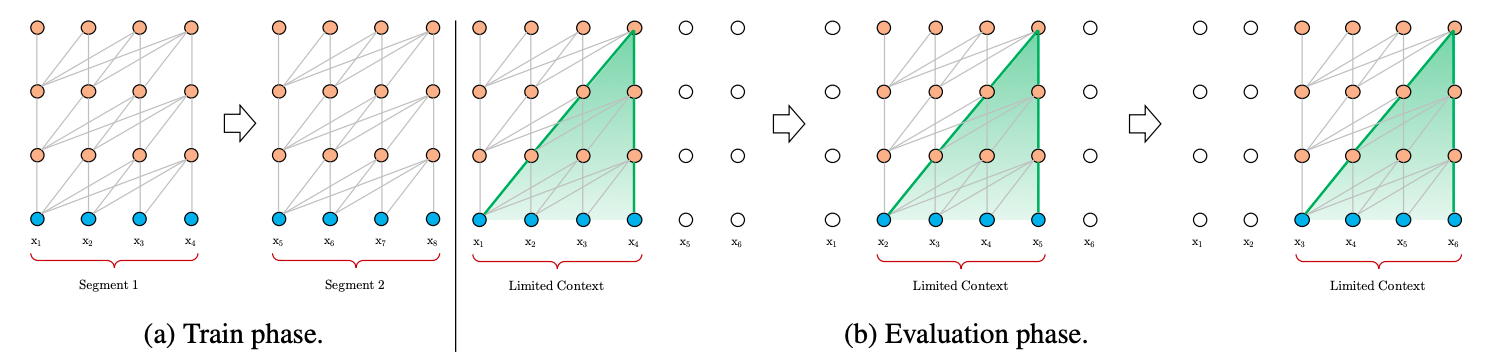
图 1 Vanilla Transformer 训练和评估阶段
在数据处理方面,给定一串较长的文本串,Vanilla Transformer 会按照固定的长度(比如 512),直接将该文本串进行划分成若干 Segment。这个处理方式不会关注文本串中语句本身的边界(比如标点或段落),这样” 粗暴” 的划分通常会将一句完整的话切分到两个 Segment 里面,导致上下文碎片化(context fragmentation)。另外,Transformer 本身能够维持的依赖长度很有可能会超出这个固定的划分长度,从而导致 Transformer 能够捕获的最大依赖长度不超过这个划分长度,Transformer 本身达不到更好的性能。
在模型训练方面,如图 1a 所示,Vanilla Transformer 每次传给模型一个 Segment 进行训练,第 1 个 Segment 训练完成后,传入第 2 个 Segment 进行训练,然而前后的这两个 Segment 是没有任何联系的,也就是前后的训练是独立的。但事实是前后的 Segment 其实是有关联的。
在模型评估方面,如图 1b 所示,Vanilla Transformer 会采用同训练阶段一致的划分长度,但仅仅预测最后一个位置的 token,完成之后,整个序列向后移动一个位置,预测下一个 token。这个处理方式保证了模型每次预测都能使用足够长的上下文信息,也缓解了训练过程中的 context framentation 问题。但是每次的 Segment 都会重新计算,计算代价很大。
基于上边的这些不足,Transformer-XL 被提出来解决这些问题。它主要提出了两个技术:Segment-Level 循环机制和相对位置编码。Transformer-XL 能够建模更长的序列依赖,比 RNN 长 80%,比 Vanilla Transformer 长 450%。同时具有更快的评估速度,比 Vanilla Transformer 快 1800 + 倍。同时在多项任务上也达到了 SoTA 的效果。
1.2. Transformer-XL 建模更长序列
1.2.1 Segment-Level 循环机制
Transformer-XL 通过引入 Segment-Level recurrence mechanism 来建模更长序列,它通过融合前后两个 Segment 的信息来到这个目的。
这里循环机制和 RNN 循环机制类似,在 RNN 中,每个时刻的 RNN 单元会接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。Transformer-XL 同样是接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。但是两者的处理单位并不相同,RNN 的处理单位是一个词,Transformer-XL 的处理单位是一个 Segment。图 2 展示了 Transformer-XL 在训练阶段和评估阶段的 Segment 处理方式。

图 2 Transformer-XL 的训练和评估阶段
在模型训练阶段,如图 2a 所示,Transformer-XL 会缓存前一个 Segment 的输出序列,在计算下一个 Segment 的输出时会使用上一个 Segment 的缓存信息,将前后不同 Segment 的信息进行融合,能够帮助模型看见更远的地方,建模更长的序列依赖能力,同时也避免了 context fragmentation 问题。
在模型评估阶段,如图 2b 所示,Transformer-XL 通过缓存前一个 Segment 的输出序列,当下一个 Segment 需要用这些输出时(前后两个 Segment 具有大部分的重复),不需要重新计算,从而加快了推理速度。
下边我们来具体聊聊这些事情是怎么做的,假设前后的两个 Segment 分别为: s τ = [ x τ , 1 , x τ , 2 , . . . , x τ , L ] \text{s}_{\tau}=[x_{\tau,1},x_{\tau,2},...,x_{\tau,L}] sτ=[xτ,1,xτ,2,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , x τ + 1 , 2 , . . . , x τ + 1 , L ] \text{s}_{\tau+1}=[x_{\tau+1,1},x_{\tau+1,2},...,x_{\tau+1,L}] sτ+1=[xτ+1,1,xτ+1,2,...,xτ+1,L],其中序列长度为 L L L。另外假定 h τ n ∈ R L × d h_{\tau}^n \in \mathbb{R}^{L \times d} hτn∈RL×d为由 s τ \text{s}_{\tau} sτ计算得出的第 n n n层的状态向量,则下一个 Segment s τ + 1 \text{s}_{\tau+1} sτ+1的第 n n n层可按照如下方式计算:
h ~ τ + 1 n − 1 = [ SG ( h τ n − 1 ) ∘ h τ + 1 n − 1 ] q τ + 1 n , k τ + 1 n , v τ + 1 n = h τ + 1 n − 1 W q T , h ~ τ + 1 n − 1 W k T , h ~ τ + 1 n − 1 W v T h τ + 1 n = Transformer-Layer ( q τ + 1 n , k τ + 1 n , v τ + 1 n ) \begin{split} \begin{align} & \tilde{h}_{\tau+1}^{n-1} = \left[ \text{SG}(h_{\tau}^{n-1}) \; \circ \;h_{\tau+1}^{n-1} \right] \\ & q_{\tau+1}^{n}, \; k_{\tau+1}^n, \; v_{\tau+1}^n = h_{\tau+1}^{n-1}W_{q}^{\mathrm{ T }}, \; \tilde{h}_{\tau+1}^{n-1}W_{k}^{\mathrm{ T }}, \; \tilde{h}_{\tau+1}^{n-1}W_{v}^{\mathrm{ T }} \\ & h_{\tau+1}^n = \text{Transformer-Layer}(q_{\tau+1}^{n}, \; k_{\tau+1}^n, \; v_{\tau+1}^n) \end{align} \end{split} h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1]qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvThτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)
其中, SG ( h τ n − 1 ) \text{SG}(h_{\tau}^{n-1}) SG(hτn−1) 表示不使用梯度, [ SG ( h τ n − 1 ) ∘ h τ + 1 n − 1 ] \left[ \text{SG}(h_{\tau}^{n-1}) \; \circ \;h_{\tau+1}^{n-1} \right] [SG(hτn−1)∘hτ+1n−1]表示将前后两个 Segment 的输出向量在序列维度上进行拼接。中间的公式表示获取 Self-Attention 计算中相应的 q , k , v q,k,v q,k,v矩阵,其中在计算 q q q的时候仅仅使用了当前 Segment 的向量,在计算 k k k和 v v v的时候同时使用前一个 Segment 和当前 Segment 的信息。最后通过 Self-Attention 融合计算,得出当前 Segment 的输出向量序列。
1.2.2 相对位置编码
Segment-Level recurrence mechanism 看起来已经做到了长序列建模,但是这里有个问题需要进一步讨论一下。我们知道,在 Vanilla Transformer 使用了绝对位置编码,我们来看看如果将绝对位置编码应用到 Segment-Level recurrence mechanism 中会怎样。
还是假设前后的两个 Segment 分别为: s τ = [ x τ , 1 , x τ , 2 , . . . , x τ , L ] \text{s}_{\tau}=[x_{\tau,1},x_{\tau,2},...,x_{\tau,L}] sτ=[xτ,1,xτ,2,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , x τ + 1 , 2 , . . . , x τ + 1 , L ] \text{s}_{\tau+1}=[x_{\tau+1,1},x_{\tau+1,2},...,x_{\tau+1,L}] sτ+1=[xτ+1,1,xτ+1,2,...,xτ+1,L],其中序列长度为 L L L。每个 Segment 的 Position Embedding 矩阵为 U 1 : L ∈ R L × d U_{1:L} \in \mathbb{R}^{L \times d} U1:L∈RL×d, 每个 Segment s τ \text{s}_{\tau} sτ的词向量矩阵为 E s τ ∈ R L × d E_{\text{s}_{\tau}} \in \mathbb{R}^{L \times d} Esτ∈RL×d,在 Vanilla Transformer 中,两者相加输入模型参与计算,如下式所示:
h τ + 1 = f ( h τ , E s τ + 1 + U 1 : L ) h τ = f ( h τ − 1 , E s τ + U 1 : L ) \begin{split} h_{\tau+1} = f(h_{\tau},\; E_{\text{s}_{\tau+1}}+U_{1:L}) \\ h_{\tau} = f(h_{\tau-1},\; E_{\text{s}_{\tau}}+U_{1:L}) \end{split} hτ+1=f(hτ,Esτ+1+U1:L)hτ=f(hτ−1,Esτ+U1:L)
很明显,如果按照这个方式计算,前后两个段 E s τ E_{\text{s}_{\tau}} Esτ和 E s τ + 1 E_{\text{s}_{\tau+1}} Esτ+1将具有相同的位置编码,这样两者信息融合的时候肯定会造成位置信息混乱。为了避免这份尴尬的操作,Transformer-XL 使用了相对位置编码。
相对位置是通过计算两个 token 之间的距离定义的,例如第 5 个 token 相对第 2 个 token 之间的距离是 3, 那么位置 i i i相对位置 j j j的距离是 i − j i-j i−j,假设序列之中的最大相对距离 L m a x L_{max} Lmax,则我们可以定义这样的一个相对位置矩阵 R ∈ R L m a x × d R \in \mathbb{R}^{L_{max} \times d} R∈RLmax×d,其中 R k R_k Rk表示两个 token 之间距离是 k k k的相对位置编码向量。注意在 Transformer-XL 中,相对位置编码向量不是可训练的参数,以 R k = [ r k , 1 , r k , 2 , . . . , r k , d ] R_k = [r_{k,1}, r_{k,2},...,r_{k,d}] Rk=[rk,1,rk,2,...,rk,d]为例,每个元素通过如下形式生成:
r b , 2 j = sin ( b 1000 0 2 j / d ) , r b , 2 j + 1 = cos ( b 1000 0 ( 2 j ) / d ) r_{b,2j} = \text{sin}(\frac{b}{10000^{2j/d}}), \quad r_{b,2j+1} = \text{cos}(\frac{b}{10000^{(2j)/d}}) rb,2j=sin(100002j/db),rb,2j+1=cos(10000(2j)/db)
Transformer-XL 将相对位置编码向量融入了 Self-Attention 机制的计算过程中,这里可能会有些复杂,我们先来看看 Vanilla Transformer 的 Self-Attention 计算过程,如下:
A i , j abs = ( W q ( E x i + U i ) ) T ( W k ( E x j + U j ) ) ) = E x i T W q T W k E x j ⏟ ( a ) + E x i T W q T W k U j ⏟ ( b ) + U i T W q T W k E x j ⏟ ( c ) + U i T W q T W k U j ⏟ ( d ) \begin{split} \begin{align} A_{i,j}^{\text{abs}} &= (W_q(E_{x_i}+U_i))^{\text{T}}(W_k(E_{x_j}+U_j))) \\ &= \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_k E_{x_j}}_{(a)} + \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_k U_j}_{(b)} + \underbrace {U_{i}^{\text{T}} W_q^{\text{T}} W_k E_{x_j}}_{(c)} + \underbrace {U_{i}^{\text{T}} W_q^{\text{T}} W_k U_{j}}_{(d)} \end{align} \end{split} Ai,jabs=(Wq(Exi+Ui))T(Wk(Exj+Uj)))=(a) ExiTWqTWkExj+(b) ExiTWqTWkUj+(c) UiTWqTWkExj+(d) UiTWqTWkUj
其中 E x i E_{x_i} Exi表示 token x i x_i xi的词向量, U i U_i Ui表示其绝对位置编码,根据这个展开公式,Transformer-XL 将相对位置编码信息融入其中,如下:
A i , j rel = E x i T W q T W k , E E x j ⏟ ( a ) + E x i T W q T W k , R R i − j ⏟ ( b ) + u T W k , E E x j ⏟ ( c ) + v T W k , R R i − j ⏟ ( d ) \begin{align} A_{i,j}^{\text{rel}} = \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_{k,E} E_{x_j}}_{(a)} + \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_{k,R} R_{i-j}}_{(b)} + \underbrace {u^{\text{T}} W_{k,E} E_{x_j}}_{(c)} + \underbrace {v^{\text{T}} W_{k,R} R_{i-j}}_{(d)} \end{align} Ai,jrel=(a) ExiTWqTWk,EExj+(b) ExiTWqTWk,RRi−j+(c) uTWk,EExj+(d) vTWk,RRi−j
这里做了这样几处改变以融入相对位置编码:
-
在分项 ( b ) (b) (b)和 ( d ) (d) (d)中,使用相对位置编码 R i − j R_{i-j} Ri−j取代绝对位置编码 U j U_j Uj。
-
在分项 ( c ) (c) (c)和 ( d ) (d) (d)中,使用可训练参数 u u u和 v v v取代 U i T W q T U_{i}^{\text{T}} W_q^{\text{T}} UiTWqT。因为 U i T W q T U_{i}^{\text{T}} W_q^{\text{T}} UiTWqT表示第 i i i个位置的 query 向量,这个 query 向量对于其他要进行 Attention 的位置来说都是一样的,因此可以直接使用统一的可训练参数进行替换。
-
在所有分项中,使用 W k , E W_{k,E} Wk,E和 W k , R W_{k,R} Wk,R计算基于内容 (词向量) 的 key 向量和基于位置的 key 向量。
式子中的每个分项分别代表的含义如下:
-
( a ) (a) (a)描述了基于内容的 Attention
-
( b ) (b) (b)描述了内容对于每个相对位置的 bias
-
( c ) (c) (c)描述了内容的全局 bias
-
( d ) (d) (d)描述了位置的全局 bias
1.2.3 完整的 Self-Attention 计算过程
上边描述了 Transformer-XL 中的两个核心技术:Segment-Level 循环机制和相对位置编码,引入了这两项技术之后,Transformer-XL 中从第 n − 1 n-1 n−1层到第 n n n层完整的计算过程是这样的:
h ~ τ n − 1 = [ SG ( h τ − 1 n − 1 ) ∘ h τ n − 1 ] q τ n , k τ n , v τ n = h τ n − 1 W q n T , h ~ τ n − 1 W k , E n T , h ~ τ n − 1 W v n T A τ , i , j n = q τ , i n T k τ , j n + q τ , i n T W k , R n R i − j + u T k τ , j + v T W k , R n R i − j α τ n = Masked-Softmax ( A τ n ) v τ n ο τ n = LayerNorm ( Linear ( α τ n ) + h τ n − 1 ) h τ n = Positionwise-Feed-Forward ( ο τ n ) \begin{split} \begin{align} \tilde{h}_{\tau}^{n-1} &= \left[ \text{SG}(h_{\tau-1}^{n-1}) \; \circ \;h_{\tau}^{n-1} \right] \\ q_{\tau}^{n}, \; k_{\tau}^n, \; v_{\tau}^n &= h_{\tau}^{n-1}{W_{q}^n}^{\mathrm{ T }}, \; \tilde{h}_{\tau}^{n-1}{W_{k,E}^n}^{\mathrm{ T }}, \; \tilde{h}_{\tau}^{n-1}{W_{v}^n}^{\mathrm{ T }} \\ A_{\tau,i,j}^{n} &= {q_{\tau, i}^{n}}^{\text{T}}k_{\tau,j}^{n} + {q_{\tau, i}^{n}}^{\text{T}}W_{k,R}^{n}R_{i-j} + u^{\text{T}}k_{\tau,j} + v^{\text{T}}W_{k,R}^{n}R_{i-j} \\ {\alpha}_{\tau}^n &= \text{Masked-Softmax}(A_{\tau}^n)v_{\tau}^n \\ {\omicron}_{\tau}^n & = \text{LayerNorm}(\text{Linear}({\alpha}_{\tau}^n)+h_{\tau}^{n-1}) \\ h_{\tau}^n &= \text{Positionwise-Feed-Forward}({\omicron}_{\tau}^n) \end{align} \end{split} h~τn−1qτn,kτn,vτnAτ,i,jnατnοτnhτn=[SG(hτ−1n−1)∘hτn−1]=hτn−1WqnT,h~τn−1Wk,EnT,h~τn−1WvnT=qτ,inTkτ,jn+qτ,inTWk,RnRi−j+uTkτ,j+vTWk,RnRi−j=Masked-Softmax(Aτn)vτn=LayerNorm(Linear(ατn)+hτn−1)=Positionwise-Feed-Forward(οτn)
- 相关资料:
-
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
-
Transformer-XL Github
2.Longformer: The Long-Document Transformer
2.1. Longformer简介
目前基于Transformer的预训练模型在各项NLP任务纷纷取得更好的效果,这些成功的部分原因在于Self-Attention机制,它运行模型能够快速便捷地从整个文本序列中捕获重要信息。然而传统的Self-Attention机制的时空复杂度与文本的序列长度呈平方的关系,这在很大程度上限制了模型的输入不能太长,因此需要将过长的文档进行截断传入模型进行处理,例如BERT中能够接受的最大序列长度为512。
基于这些考虑,Longformer被提出来拓展模型在长序列建模的能力,它提出了一种时空复杂度同文本序列长度呈线性关系的Self-Attention,用以保证模型使用更低的时空复杂度建模长文档。
这里需要注意的是Longformer是Transformer的Encoder端。
2.2 Longformer提出的Self-Attention
Longformer对长文档建模主要的改进是提出了新的Self-Attention模式,如图1所示,下面我们来详细讨论一下。

图1 经典的Self-Attention和Longformer提出的Self-Attention
图1展示了经典的Self-Attention和Longformer提出的Self-Attention,其中图1a是经典的Self-Attention,它是一种”全看型”的Self-Attention,即每个token都要和序列中的其他所有token进行交互,因此它的时空复杂度均是 O ( n 2 ) O(n^2) O(n2)。右边的三种模式是Longformer提出来的Self-Attention模式,分别是Sliding Window Attention(滑窗机制)、Dilated Sliding Window(空洞滑窗机制)和Global+Sliding Window(融合全局信息的滑窗机制)。
2.2.1 Sliding Window Attention
如图1b所示,对于某个token,经典的Self-Attention能够看到并融合所有其他的token,但Sliding window attention设定了一个窗口 w w w,它规定序列中的每个token只能看到 w w w个token,其左右两侧能看到 1 2 w \frac{1}{2}w 21w个token,因此它的时间复杂度是 O ( n × w ) O(n\times w) O(n×w)。
你不需要担心这种设定无法建立整个序列的语义信息,因为transformer模型结构本身是层层叠加的结构,模型高层相比底层具有更宽广的感受野,自然能够能够看到更多的信息,因此它有能力去建模融合全部序列信息的全局表示,就行CNN那样。一个拥有 m m m层的transformer,它在最上层的感受野尺寸为 m × w m\times w m×w。
通过这种设定Longformer能够在建模质量和效率之间进行一个比较好的折中。
2.2.2 Dilated Sliding Window
在对一个token进行Self-Attention操作时,普通的Sliding Window Attention只能考虑到长度为 w w w的上下文,在不增加计算量的情况下,Longformer提出了Dilated Sliding Window,如图1c所示。在进行Self-Attention的两个相邻token之间会存在大小为 d d d的间隙,这样序列中的每个token的感受野范围可扩展到 d × w d\times w d×w。在第 m m m层,感受野的范围将是 m × d × w m\times d \times w m×d×w。
作者在文中提到,在进行Multi-Head Self-Attention时,在某些Head上不设置Dilated Sliding Window以让模型聚焦在局部上下文,在某些Head上设置Dilated Sliding Window以让模型聚焦在更长的上下文序列,这样能够提高模型表现。
2.2.3 Global Attention
以上两种Attention机制还不能完全适应task-specific的任务,因此Global+Sliding Window的Attention机制被提出来,如图1d所示。它设定某些位置的token能够看见全部的token,同时其他的所有token也能看见这些位置的token,相当于是将这些位置的token”暴露”在最外面。
这些位置的确定和具体的任务有关。例如对于分类任务,这个带有全局视角的token是”CLS”;对于QA任务,这些带有全局视角的token是Question对应的这些token。
那么这种融合全局信息的滑窗Attention具体如何实现呢,我们先来回顾一下经典的Self-Attention,公式如下:
Attention ( Q , K , V ) = s o f t m a x ( Q K T d k ) \text{Attention}(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}}) Attention(Q,K,V)=softmax(dkQKT)
即将原始的输入分别映射到了 Q , K , V Q,K,V Q,K,V三个空间后进行Attention计算,Global+Sliding Window这里涉及到两种Attention,Longformer中分别将这两种Attention映射到了两个独立的空间,即使用 Q s , K s , V s Q_s,K_s,V_s Qs,Ks,Vs来计算Sliding Window Attention,使用 Q g , K g , V g Q_g,K_g,V_g Qg,Kg,Vg来计算Global Attention。
2.3. Longformer Attention的实现
上述提出的Attention机制在当前的深度学习框架中尚未实现,比如PyTorch/Tensorflow,因此Longformer作者实现了三种方式并进行了对比,如图2所示。
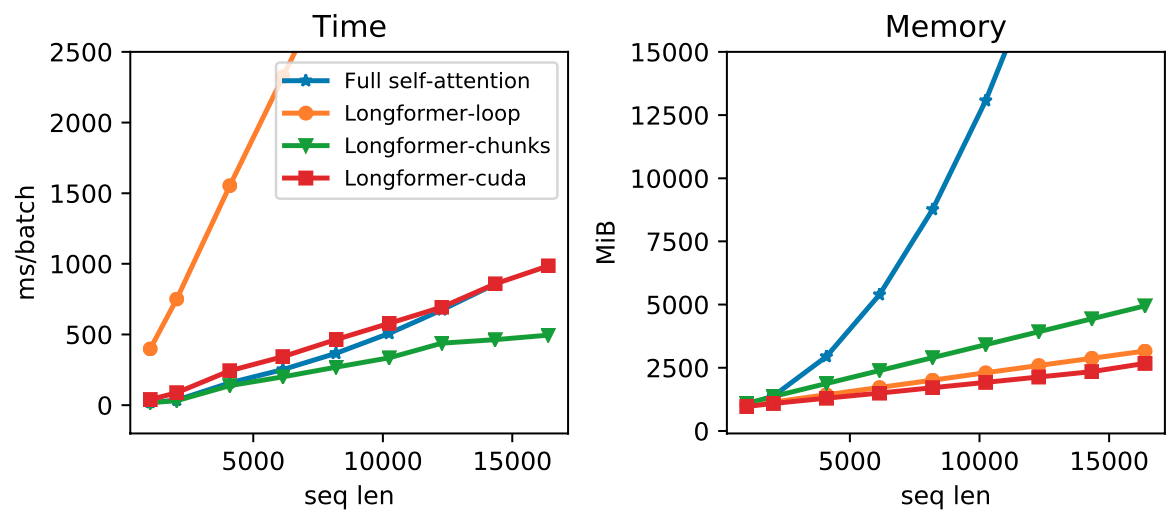
图2 Longformer Attention的不同实现方式
其中Full Self-Attention是经典的自注意力实现;Longformer-loop是一种PyTorch实现,它能够有效节省内存使用并且支持Dilated Sliding Window, 但这种实现方式太慢,因此只能用于测试阶段。Longformer-chunks不支持Dilated Sliding Window,被用于预训练/微调阶段。Longformer-cuda是作者使用TVM实现的CUDA内核方法。可以看到,Longformer能够取得比较好的时空复杂度。
-
相关资料
-
Longformer: The Long-Document Transformer
-
Longformer Github
3.GPT
3.1 简介
2018 年 6 月,OpenAI 发表论文介绍了自己的语言模型 GPT,GPT 是“Generative Pre-Training”的简称,它基于 Transformer 架构,GPT模型先在大规模语料上进行无监督预训练、再在小得多的有监督数据集上为具体任务进行精细调节(fine-tune)的方式。先训练一个通用模型,然后再在各个任务上调节,这种不依赖针对单独任务的模型设计技巧能够一次性在多个任务中取得很好的表现。这中模式也是 2018 年中自然语言处理领域的研究趋势,就像计算机视觉领域流行 ImageNet 预训练模型一样。
NLP 领域中只有小部分标注过的数据,而有大量的数据是未标注,如何只使用标注数据将会大大影响深度学习的性能,所以为了充分利用大量未标注的原始文本数据,需要利用无监督学习来从文本中提取特征,最经典的例子莫过于词嵌入技术。但是词嵌入只能 word-level 级别的任务(同义词等),没法解决句子、句对级别的任务(翻译、推理等)。出现这种问题原因有两个:
-
不清楚下游任务,所以也就没法针对性的进行优化;
-
就算知道了下游任务,如果每次都要大改模型也会得不偿失。
为了解决以上问题,作者提出了 GPT 框架,用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:无监督Pre-training 和 有监督Fine-tuning。在Pre-training阶段使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,在fine-tuning阶段,根据具体任务对 Transformer 的参数进行微调,目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。
3.2. 模型结构
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
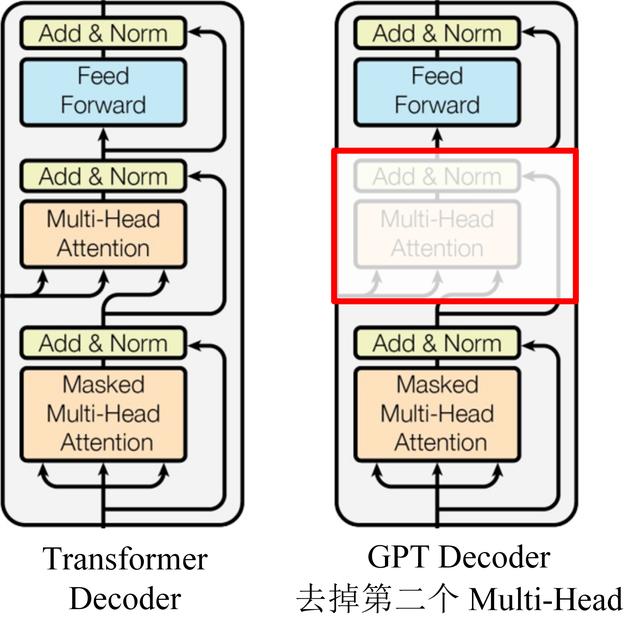
GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。如果利用A 预测B的时候,需要将 [B, C, D] Mask 起来。
Mask 操作是在 Self-Attention 进行 Softmax 之前进行的,具体做法是将要 Mask 的位置用一个无穷小的数替换 -inf,然后再 Softmax,如下图所示。

Softmax 之前需要 Mask

GPT Softmax
可以看到,经过 Mask 和 Softmax 之后,当 GPT 根据单词 A 预测单词 B 时,只能使用单词 A 的信息,根据 [A, B] 预测单词 C 时只能使用单词 A, B 的信息。这样就可以防止信息泄露。
下图是 GPT 整体模型图,其中包含了 12 个 Decoder。
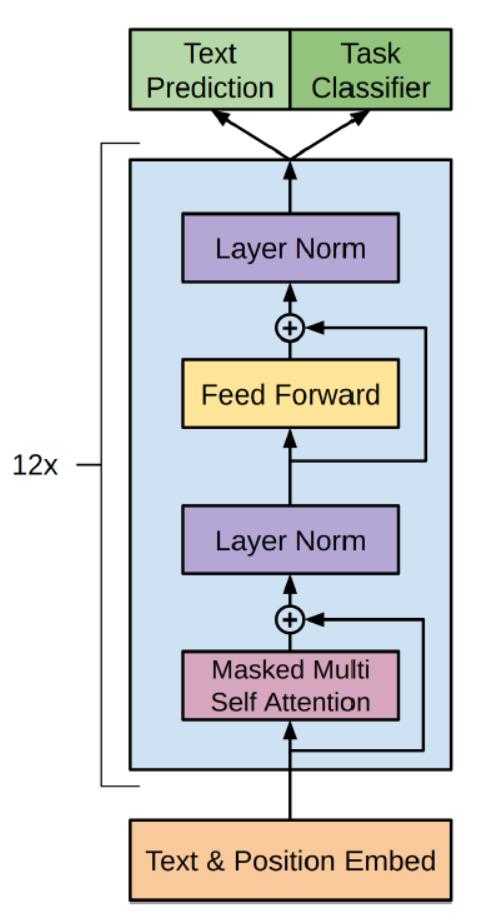
GPT只使用了 Transformer 的 Decoder 部分,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward,共叠加使用了 12 层的 Decoder。
这里简单解释下为什么只用 Decoder 部分:语言模型是利用上文预测下一个单词的,因为 Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,所以也就不需要 encoder-decoder attention 了。
3.3. GPT训练过程
3.3.1 无监督的预训练
无监督的预训练(Pretraining),具体来说,给定一个未标注的预料库 U = { u 1 , u 2 , . . . , u n } U=\{u_{1},u_{2},...,u_{n}\} U={u1,u2,...,un},我们训练一个语言模型,对参数进行最大(对数)似然估计:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u 1 , . . . , u k − 1 ; Θ ) L_{1}(U)=\sum_{i}log P(u_{i}|u_{1},...,u_{k-1};\Theta) L1(U)=i∑logP(ui∣u1,...,uk−1;Θ)
其中,k 是上下文窗口的大小,P 为条件概率, Θ \Theta Θ为条件概率的参数,参数更新采用随机梯度下降(GPT实验实现部分具体用的是Adam优化器,并不是原始的随机梯度下降,Adam 优化器的学习率使用了退火策略)。
训练的过程也非常简单,就是将 n 个词的词嵌入 W e W_{e} We加上位置嵌入 W p W_{p} Wp,然后输入到 Transformer 中,n 个输出分别预测该位置的下一个词
可以看到 GPT 是一个单向的模型,GPT 的输入用 h 0 h_{0} h0 表示,0代表的是输入层, h 0 h_{0} h0的计算公式如下
h 0 = U W e + W p h_{0}=UW_{e}+W_{p} h0=UWe+Wp
W e W_{e} We是token的Embedding矩阵, W p W_{p} Wp是位置编码的 Embedding 矩阵。用 voc 表示词汇表大小,pos 表示最长的句子长度,dim 表示 Embedding 维度,则 W p W_{p} Wp是一个 pos×dim 的矩阵, W e W_{e} We是一个 voc×dim 的矩阵。在GPT中,作者对position embedding矩阵进行随机初始化,并让模型自己学习,而不是采用正弦余弦函数进行计算。
得到输入 h 0 h_{0} h0 之后,需要将 h 0 h_{0} h0 依次传入 GPT 的所有 Transformer Decoder 里,最终得到 h n h_{n} hn。
h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) , ∀ l ∈ [ 1 , n ] h_{l}=transformer\_block(h_{l-1}), \forall l \in [1,n] hl=transformer_block(hl−1),∀l∈[1,n]
n 为神经网络的层数。最后得到 h n h_{n} hn再预测下个单词的概率。
P ( u ) = s o f t m a x ( h n W e T ) P(u)=softmax(h_{n}W_{e}^T) P(u)=softmax(hnWeT)
3.3.2 有监督的Fine-Tuning
预训练之后,我们还需要针对特定任务进行 Fine-Tuning。假设监督数据集合 C C C的输入 X X X是一个序列 x 1 , x 2 , . . . , x m x^1,x^2,...,x^m x1,x2,...,xm,输出是一个分类y的标签 ,比如情感分类任务
我们把 x 1 , . . , x m x^1,..,x^m x1,..,xm输入 Transformer 模型,得到最上层最后一个时刻的输出 h l m h_{l}^m hlm,将其通过我们新增的一个 Softmax 层(参数为 W y W_{y} Wy)进行分类,最后用交叉熵计算损失,从而根据标准数据调整 Transformer 的参数以及 Softmax 的参数 W y W_{y} Wy。这等价于最大似然估计:
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x^1,...,x^m)=softmax(h_{l}^mW_{y}) P(y∣x1,...,xm)=softmax(hlmWy)
W y W_{y} Wy表示预测输出时的参数,微调时候需要最大化以下函数:
L 2 ( C ) = ∑ x , y l o g P ( y ∣ x 1 , . . , x m ) L_{2}(C)=\sum_{x,y}log P(y|x^1,..,x^m) L2(C)=x,y∑logP(y∣x1,..,xm)
正常来说,我们应该调整参数使得 L 2 L_{2} L2最大,但是为了提高训练速度和模型的泛化能力,我们使用 Multi-Task Learning,GPT 在微调的时候也考虑预训练的损失函数,同时让它最大似然 L 1 L_{1} L1和 L 2 L_{2} L2
L 3 ( C ) = L 2 ( C ) + λ × L 1 ( C ) L_{3}(C)=L_{2}(C)+\lambda \times L_{1}(C) L3(C)=L2(C)+λ×L1(C)
这里使用的 L 1 L_{1} L1还是之前语言模型的损失(似然),但是使用的数据不是前面无监督的数据 U U U,而是使用当前任务的数据 C C C,而且只使用其中的 X X X,而不需要标签y。
3.3.3 其它任务
针对不同任务,需要简单修改下输入数据的格式,例如对于相似度计算或问答,输入是两个序列,为了能够使用 GPT,我们需要一些特殊的技巧把两个输入序列变成一个输入序列
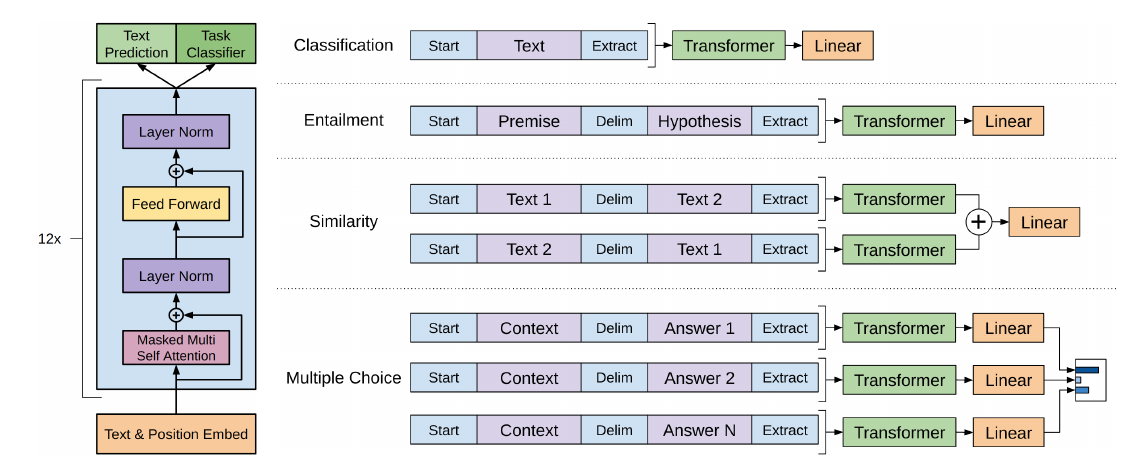
-
Classification:对于分类问题,不需要做什么修改
-
Entailment:对于推理问题,可以将先验与假设使用一个分隔符分开
-
Similarity:对于相似度问题,由于模型是单向的,但相似度与顺序无关,所以要将两个句子顺序颠倒后,把两次输入的结果相加来做最后的推测
-
Multiple-Choice:对于问答问题,则是将上下文、问题放在一起与答案分隔开,然后进行预测
3.4. GPT优缺点
-
优点
-
特征抽取器使用了强大的 Transformer,能够捕捉到更长的记忆信息,且较传统的 RNN 更易于并行化;
-
方便的两阶段式模型,先预训练一个通用的模型,然后在各个子任务上进行微调,减少了传统方法需要针对各个任务定制设计模型的麻烦。
-
-
缺点
- GPT 最大的问题就是传统的语言模型是单向的;我们根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子 The animal didn’t cross the street because it was too tired。我们在编码 it 的语义的时候需要同时利用前后的信息,因为在这个句子中,it 可能指代 animal 也可能指代 street。根据 tired,我们推断它指代的是 animal。但是如果把 tired 改成 wide,那么 it 就是指代 street 了。Transformer 的 Self-Attention 理论上是可以同时关注到这两个词的,但是根据前面的介绍,为了使用 Transformer 学习语言模型,必须用 Mask 来让它看不到未来的信息,所以它也不能解决这个问题。
3.5. GPT 与 ELMo的区别
GPT 与 ELMo 有两个主要的区别:
-
模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 Transformer encoder
-
针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型
参考文献:
Improving Language Understanding by Generative Pre-Training