作者 | 小戏、Python
大模型在其巨大体量背后蕴藏着一个直观的问题:“大模型应该怎么更新?”
在大模型极其巨大的计算开销下,大模型知识的更新并不是一件简单的“学习任务”,理想情况下,随着世界各种形势的纷繁复杂的变换,大模型也应该随时随地跟上时代的脚步,但是训练全新大模型的计算负担却不允许大模型实现即时的更新,因此,一个全新的概念“Model Editing(模型编辑)”应运而生,以实现在特定领域内对模型数据进行有效的变更,同时不会对其他输入的结果造成不利影响。

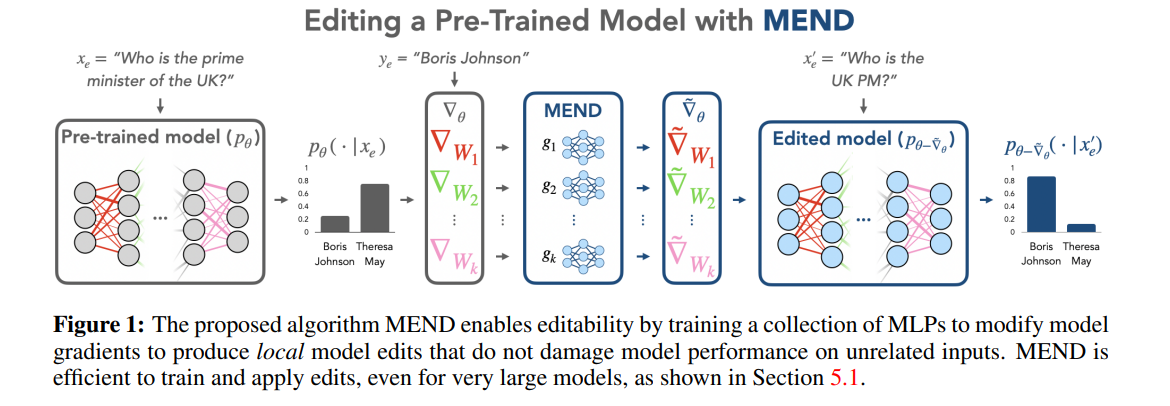
模型编辑这个概念由 Mitchell 等人于 2022 年提出,如上图所示,整个 Model Editing 的过程旨在使用编辑描述符 ( x e , y e ) (x_e,y_e) (xe,ye),即上图中关于信息 “谁是美国总统?-拜登” 的问题答案对,去调整基础模型 f θ f_{\theta} fθ,最终得到一个编辑后的模型 f θ e f_{\theta_e} fθe ,并且使得 f θ e ( x e ) = y e f_{\theta_e}(x_e)= y_e fθe(xe)=ye。
另一方面,模型编辑还要求对当前领域内的“编辑”不会影响到其他领域内输入的正常输出结果,形式化的表述即需要:
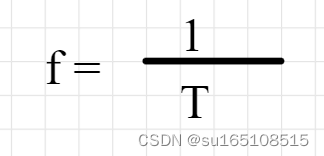
f θ e ( x ) = { y e if x ∈ I ( x e , y e ) f θ ( x ) if x ∈ O ( x e , y e ) f_{\theta_e}(x)= \begin{cases}y_e & \text { if } x \in I\left(x_e, y_e\right) \\ f_\theta(x) & \text { if } x \in O\left(x_e, y_e\right)\end{cases} fθe(x)={yefθ(x) if x∈I(xe,ye) if x∈O(xe,ye)
其中, I I I 表示 ( x e , y e ) (x_e,y_e) (xe,ye) 的“有效邻居”, O O O 则表示超出 ( x e , y e ) (x_e,y_e) (xe,ye) 作用范围的领域。一个编辑后的模型应当满足以下三点,分别是可靠性,普适性与局部性,可靠性即编辑后模型应该可以正确的输出编辑前模型错误的例子,可以通过编辑案例的平均准确率来衡量,普适性表示对于 ( x e , y e ) (x_e,y_e) (xe,ye) 的“有效邻居”,模型都应该可以给出正确的输出,这点可以对编辑案例领域数据集进行均匀抽样衡量平均正确率来衡量,最后局部性,即表示编辑后模型在超出编辑范围的例子中仍然应该保持编辑前的正确率,可以通过分别测算编辑前编辑后的平均准确率来对局部性进行刻画,如下图所示,在编辑“特朗普”的位置时,一些其他的公共特征不应受到更改。同时,其他实体,例如“国务卿”,尽管与“总统”具有相似的特征,但也不应受到影响。

而今天介绍的这篇来自浙江大学的论文便站在一个大模型的视角,为我们详细叙述了大模型时代下模型编辑的问题、方法以及未来,并且构建了一个全新的基准数据集与评估指标,帮助更加全面确定的评估现有的技术,并为社区在方法选择上提供有意义的决策建议与见解:
论文题目:
Editing Large Language Models: Problems, Methods, and Opportunities论文链接:
https://arxiv.org/pdf/2305.13172.pdf
大模型研究测试传送门
ChatGPT传送门(免墙,可直接测试):
https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
主流方法
当下针对大规模语言模型(LLMs)的模型编辑方法如下图所示主要可以分为两类范式,分别是如下图(a)所示的保持原模型参数不变下使用额外的参数以及如下图(b)所示的修改模型的内部参数。

首先来看相对简单的增加额外参数的方法,这种方法又称基于记忆或内存的模型编辑方法,代表方法 SERAC 最早出现于 Mitchell 提出“模型编辑”的论文,其核心思想在于保持模型原始参数不变,通过一个独立的参数集重新处理修改后的事实,具体而言,这类方法一般先增加一个“范围分类器”判断新输入是否处于被“重新编辑”过的事实范围内,如果属于,则使用独立参数集对该输入进行处理,对缓存中的“正确答案”赋予更高的选择概率。在 SERAC 的基础上,T-Patcher 与 CaliNET 向 PLMs 的前馈模块中引入额外可训练的参数(而不是额外外挂一个模型),这些参数在修改后的事实数据集中进行训练以达到模型编辑的效果。

而另一大类方法即修改原来模型中参数的方法主要应用一个 ∆ 矩阵去更新模型中的部分参数 θ \theta θ,具体而言,修改参数的方法又可以分为“Locate-Then-Edit”与元学习两类方法,从名字也可以看出,Locate-Then-Edit 方法先通过定位模型中的主要影响参数,再对定位到的模型参数进行修改实现模型编辑,其中主要方法如 Knowledge Neuron 方法(KN)通过识别模型中的“知识神经元”确定主要影响参数,通过更新这些神经元实现对模型的更新,另一种名为 ROME 的方法思想与 KN 类似,通过因果中介分析定位编辑区域,此外还有一种 MEMIT 的方法可以实现对一系列编辑描述的更新。这类方法最大的问题在于普遍依据一个事实知识局部性的假设,但是这一假设并没有得到广泛的验证,对许多参数的编辑有可能导致意想不到的结果。
而元学习方法与 Locate-Then-Edit 方法不同,元学习方法使用 hyper network 方法,使用一个超网络(hyper network)为另一个网络生成权重,具体而言在 Knowledge Editor 方法中,作者使用一个双向的 LSTM 去预测每个数据点为模型权重带来的更新,从而实现对编辑目标知识的带约束的优化。这类知识编辑的方法由于 LLMs 的巨大参数量导致难以应用于 LLMs 中,因此 Mitchell 等又提出了 MEND(Model Editor Networks with Gradient Decomposition)使得单个的编辑描述可以对 LLMs 进行有效的更新,这种更新方法主要使用梯度的低秩分解微调大模型的梯度,从而使得可以对 LLMs 进行最小资源的更新。与 Locate-Then-Edit 方法不同,元学习方法通常花费的时间更长,消耗的内存成本更大。
方法测评
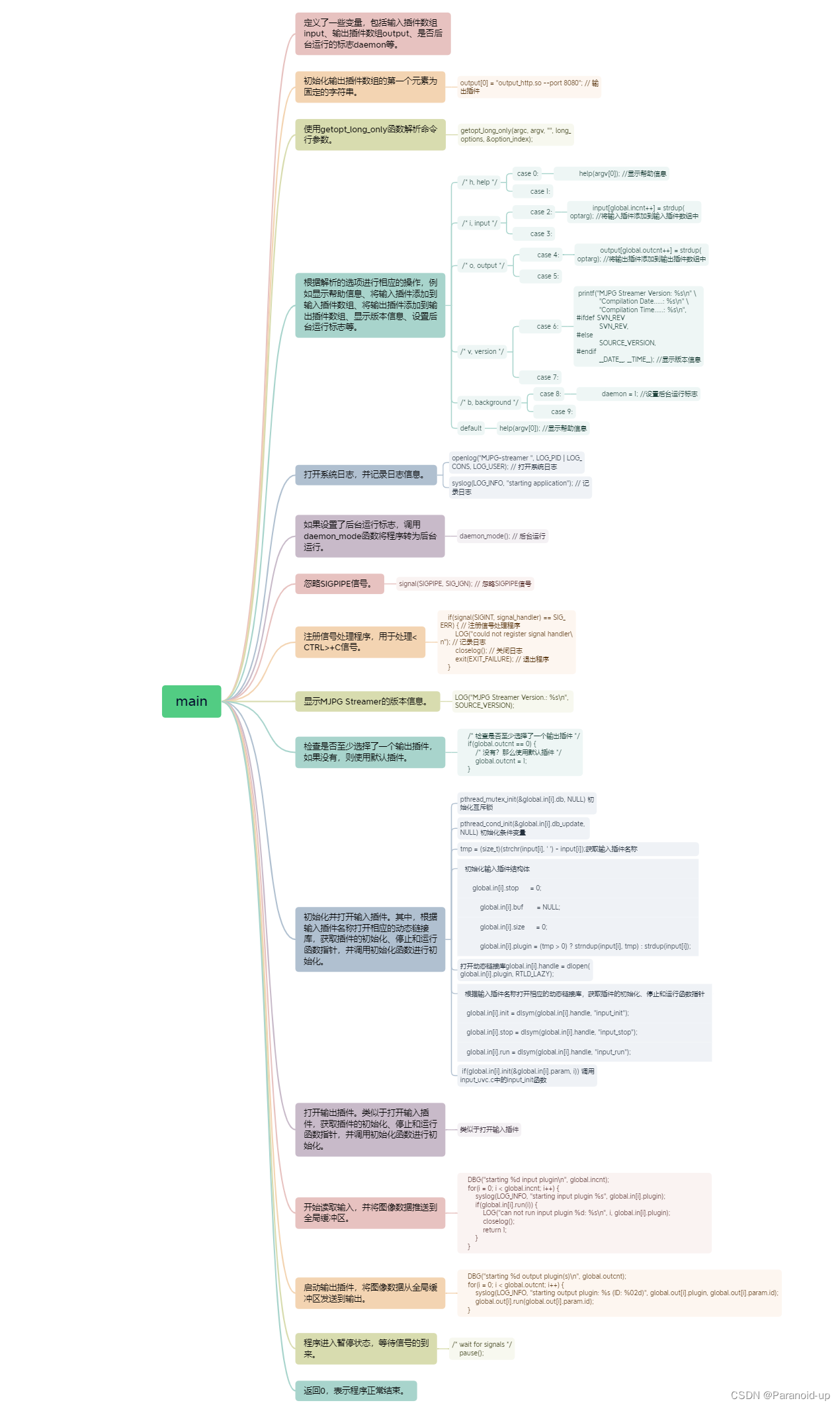
这些不同方法在模型编辑的两个主流数据集 ZsRE(问答数据集,使用反向翻译生成的问题改写作为有效领域) 与 COUNTERFACT(反事实数据集,将主语实体替换为同义实体作为有效领域) 中进行实验如下图所示,实验主要针对两个相对以往研究较大的 LLMs T5-XL(3B)和 GPT-J(6B)作为基础模型,高效的模型编辑器应该在模型性能、推理速度和存储空间之间取得平衡。
对比第一列微调(FT)的结果,可以发现,SERAC 和 ROME 在 ZsRE 和 COUNTERFACT 数据集上表现出色,特别是 SERAC,它在多个评估指标上获得了超过 90% 的结果,虽然 MEMIT 的通用性不如 SERAC 和 ROME,但在可靠性和局部性上表现出色。而 T-Patcher 方法表现极其不稳定,在 COUNTERFACT 数据集中具有不错的可靠性和局部性,但缺乏通用性,在 GPT-J 中,可靠性和通用性表现出色,但在局部性方面表现不佳。值得注意的是,KE、CaliNET 和 KN 的性能表现较差,相对于这些模型在“小模型”中取得的良好表现而言,实验可能证明了这些方法不是非常适配大模型的环境。

而如果从时间来看,一旦训练好网络,KE 和 MEND 则表现相当优秀,而如 T-Patcher 这类方法耗时则过于严重:

再从内存消耗来看,大多数方法消耗内存在同一个量级,但引入额外参数的方法会承担额外的内存开销:

同时,通常对模型编辑的操作还需要考虑批次输入编辑信息以及顺序输入编辑信息,即一次更新多个事实信息与顺序更新多个事实信息,批次输入编辑信息整体模型效果如下图所示,可以看到 MEMIT 可以同时支持编辑超过 10000条信息,并且还能保证两个度量指标的性能都保持稳定,而 MEND 和 SERAC 则表现不佳:
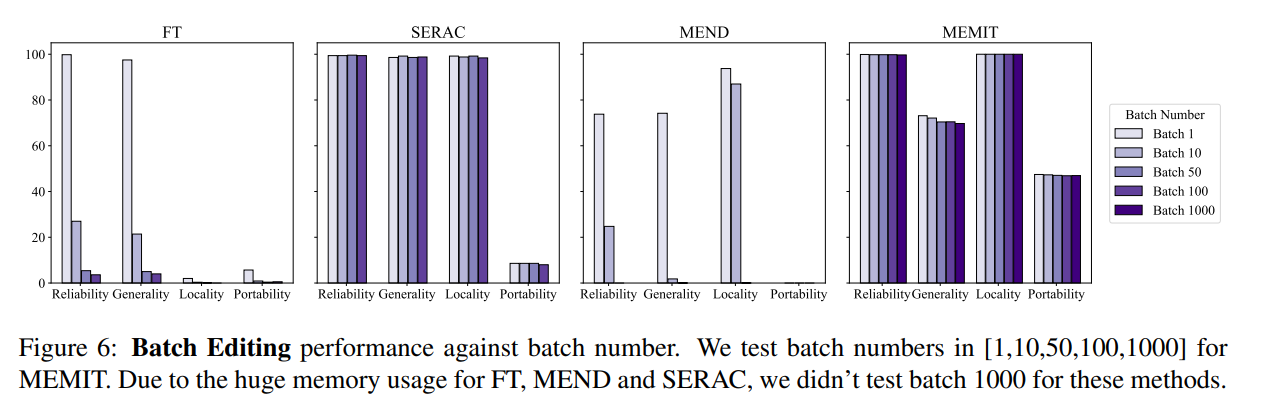
而在顺序输入方面,SERAC 和 T-Patcher 表现出色而稳定,ROME,MEMIT,MEND 都出现了在一定数量的输入后模型性能快速下降的现象:
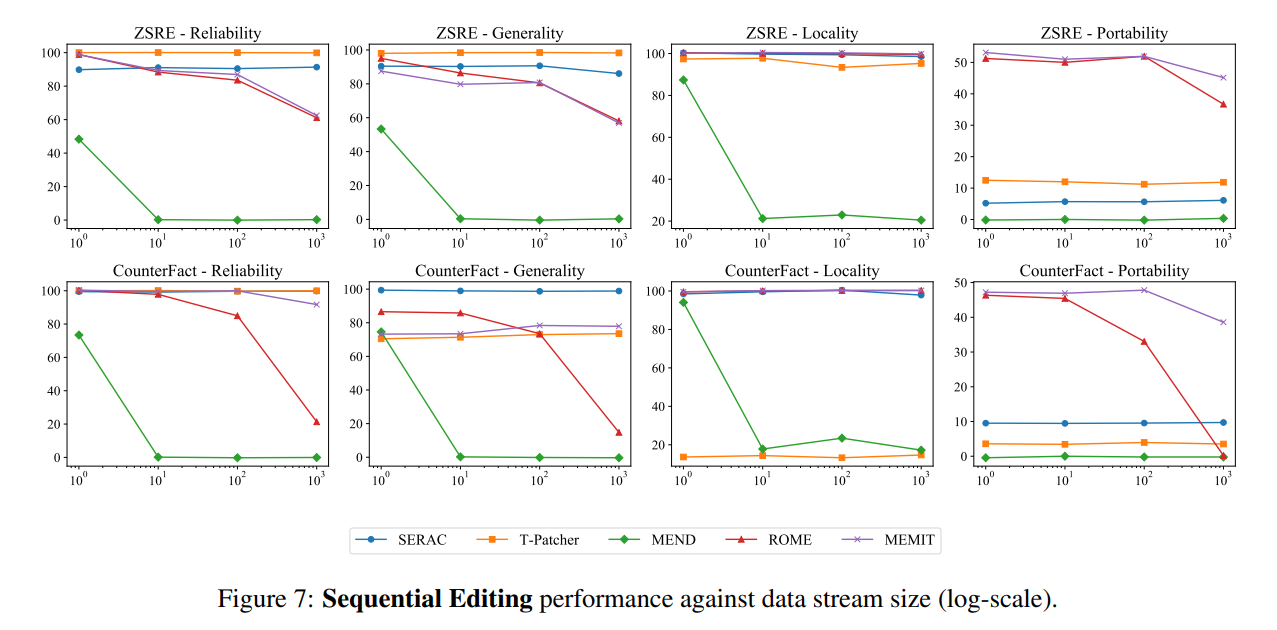
最后,作者在研究中发现,当下这些数据集的构造及评估指标很大程度上只关注句子措辞上的变化,但是并没有深入到模型编辑对许多相关逻辑事实的更改,譬如如果将“Watts Humphrey 就读哪所大学”的答案从三一学院改为密歇根大学,显然如果当我们问模型“Watts Humphrey 大学时期居住于哪个城市?”时,理想模型应该回答安娜堡而不是哈特福德,因此,论文作者在前三个评估指标的基础上引入了“可移植性”指标,衡量编辑后的模型在知识转移方面的有效性。
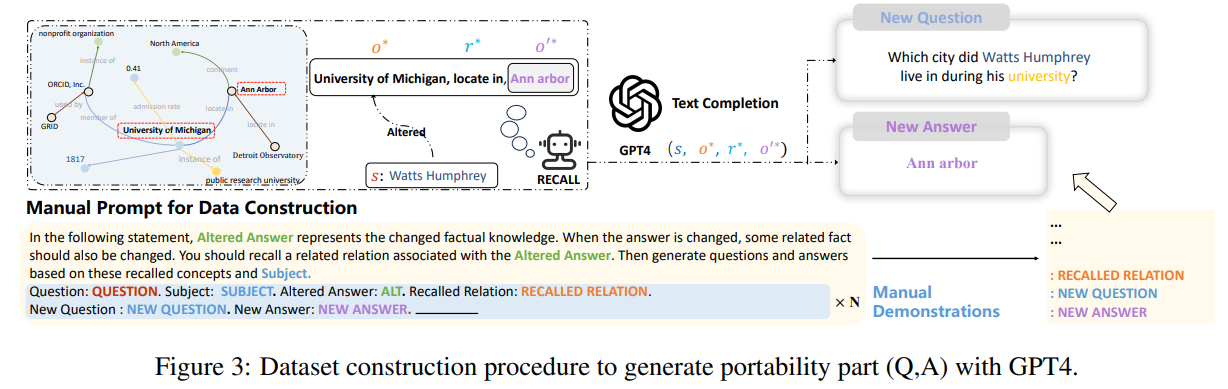
为此,作者使用 GPT-4 构建了一个新的数据集,通过将原始问题 s s s 的答案从 o o o 改为 o ∗ o^{*} o∗,并且构建另一个正确答案为 o ′ ∗ o^{'*} o′∗ 的问题 r ∗ r^* r∗,组成 ( o ∗ , r ∗ , o ′ ∗ ) (o^{*},r^*,o^{'*}) (o∗,r∗,o′∗) 三元组,对编辑后模型输入 ( o ∗ , r ∗ ) (o^{*},r^*) (o∗,r∗),如果模型可以正确输出 o ′ ∗ o^{'*} o′∗ 则证明该编辑后模型具有“可移植性”,而根据这个方法,论文测试了现有几大方法的可移植性得分如下图所示:
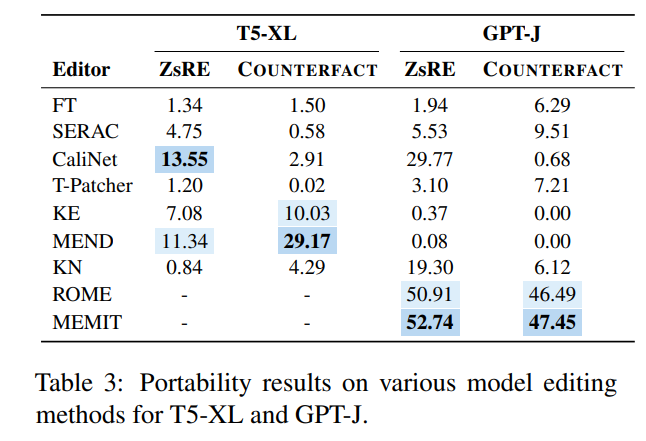
可以看到,几乎绝大多数模型编辑方法在可移植性方面都不太理想,曾经表现优异的 SERAC 可移植性准确率不到 10%,相对最好的 ROME 和 MEMIT 最高也只有 50% 左右,这表明当下的模型编辑方法几乎难以做到编辑后知识的任何扩展和推广,模型编辑尚有很长的路要走。
讨论与未来
不管从何种意义来说,模型编辑预设的问题在未来所谓的“大模型时代”都十分有潜力,模型编辑的问题需要更好的探索如“模型知识究竟存储在哪些参数之中”、“模型编辑操作如何不影响其他模块的输出”等一系列非常难的问题。而另一方面,解决模型“过时”的问题,除了让模型进行“编辑”,还有一条思路在于让模型“终身学习”并且做到“遗忘”敏感知识,不论是模型编辑还是模型终身学习,这类研究都将对 LLMs 的安全与隐私问题做出有意义的贡献。