一、图像采集和标注
- 图像采集
覆盖所有的数据目标,不同场景(视角、光照、可能的干扰)、距离、运动、背景等,用深度和广度摄像头都行。
若兼顾效率和准确率,可以用迁移学习思路训练,则不同场景下采集的图像数据量可以适当降低,但避免场景单一问题。
- 图像标注
可以看LabelImg安装与使用
二、YOLOv5模型训练
1、YOLOv5深度网络下载
下载地址:YOLOv5模型
2、安装环境依赖库
安装命令语句
pip install -r requirements.txt或者
按照requirements.txt文件里依赖库的顺序,分别用pip install安装对应的包
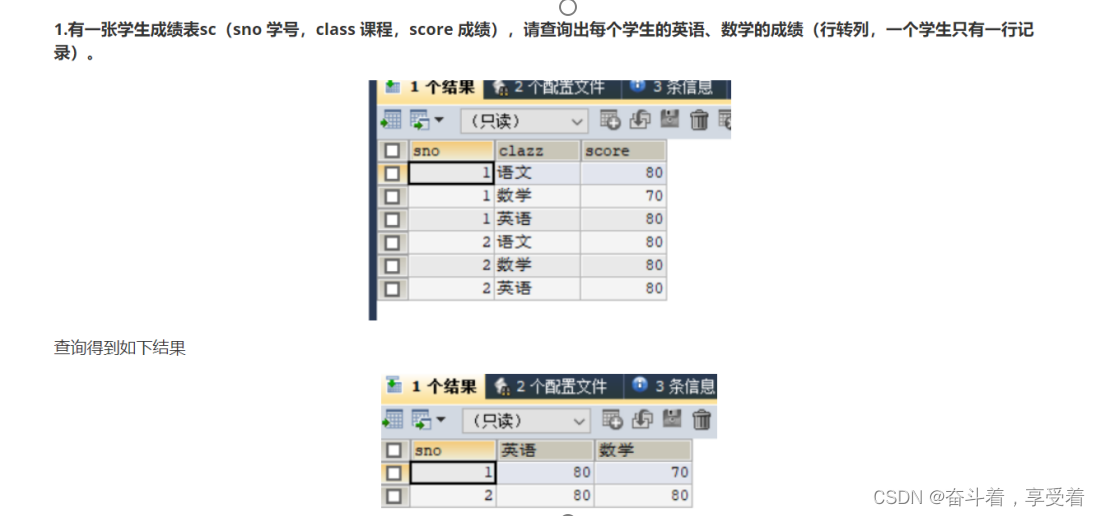
3、准备数据集
把图像数据集和标定数据复制到yolov5/InsectImg/RawInsect文件夹下, 创建一个YOLOLabels文件夹,主要将Pascal VOC标注模式生成的.xml文件转换为.txt格式。

完整代码
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ['aedes', 'aegypti','albiceps','albopictus','americana','australasiae','bazini','cheopis','coquillett', 'culex','cuprina',
'fabricius','fuliginosa','gblattella','melanura', 'musca','pattoni','rhombifolia','sericata','sorbens','wiedemann']
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('InsectImg/RawInsect/Annotations/%s.xml' % image_id)
out_file = open('InsectImg/RawInsect/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "InsectImg/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "RawInsect/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()- 修改class类别标签名
- 修改TRAIN_RATIO,划分训练数据集和验证数据集比例8:2
- 修改文件路径
第一处:
in_file = open('InsectImg/RawInsect/Annotations/%s.xml' % image_id)
out_file = open('InsectImg/RawInsect/YOLOLabels/%s.txt' % image_id, 'w')第二处:
data_base_dir = os.path.join(wd, "InsectImg/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "RawInsect/")4、配置YOLOv5数据环境
在data文件夹下,仿照coco.yaml,创建insect.yaml文件
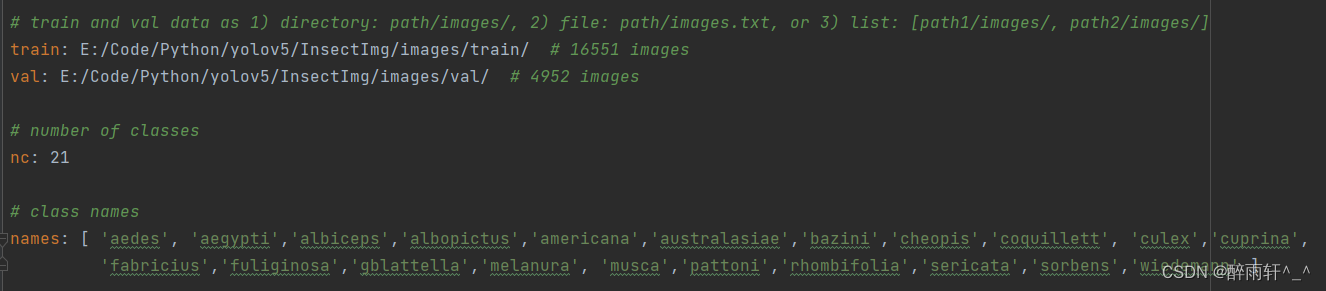
- 修改train训练数据集路径
- 修改val验证数据集路径
- 修改nc类别数
- 修改names列表标签名
在models文件夹下,仿照yolov5l.yaml,创建yolov5l_insect.yaml文件

- 修改nc类别数
在weights文件夹下,存放从GitHub上下载的yolov5l6.pt
注意:如果YOLOv5系列有n、s、m、l、x,models文件夹下创建什么类型的模型,weights文件夹下要存放相应的训练好的模型pt文件。
5、修改train.py参数

一般情况下,需要修改参数:
- 修改 --weights路径
- 修改--cfg配置模型路径
- 修改--data图像数据路径
- 根据电脑GPU核,设置--batch-size
- 根据n、s、m、l、x,设置--imgsz,YOLOv5l输入图像大小设置为640
- 一般--resume设置为False,如果因电脑重启导致训练中断,可以设置为True,接着上一次的结果继续训练
- epochs一般300,也可以根据训练情况调整
其他参数可以根据情况自动设置
6、运行train.py 进行模型训练
训练模型结果保存在路径
E:\Code\Python\yolov5\runs\train\exp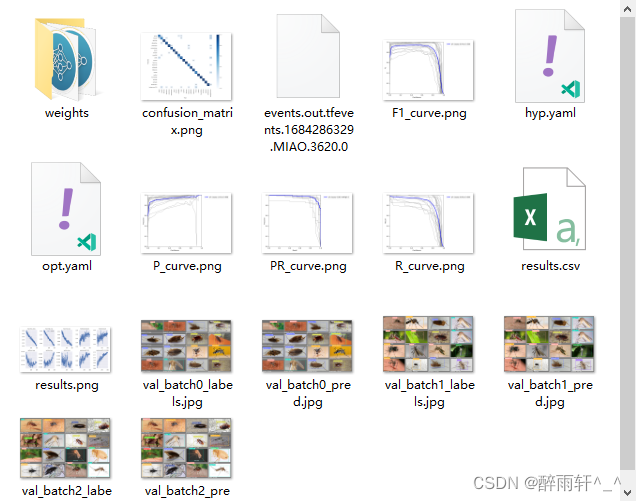
该路径下的weights文件夹生成了last.pt和best.pt两个文件,选择best.pt作为移植模型。
三、YOLOv5模型移植
1、修改export.py文件
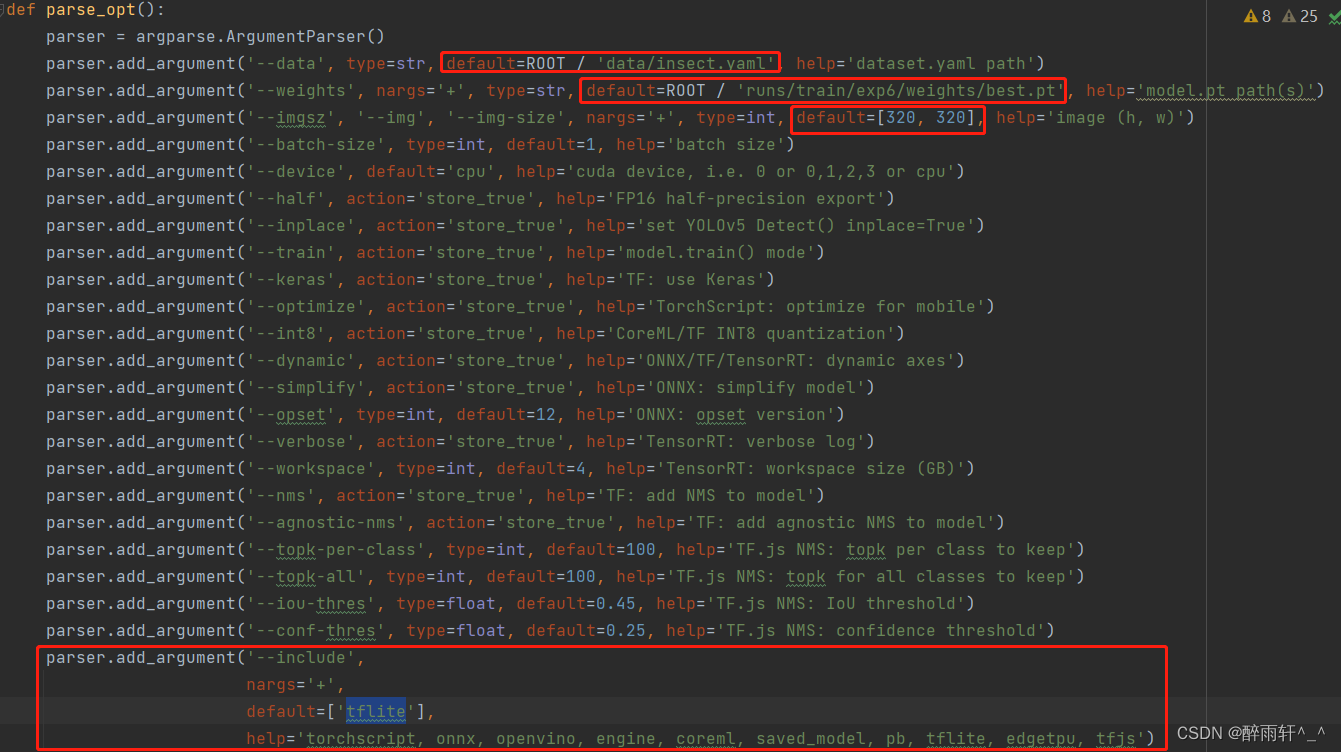
- 修改--data,为自己数据的.yaml文件
- 修改--weights,为上一步YOLOv5l训练得到best.pt最佳路径
- 修改--imgsz,一般设置为320
- 修改--include,根据实际案例,可以选择tflite/onnx/pb等。
运行export.py导出量化后的模型
2、量化后模型移植终端
配置终端环境,调用量化后的模型。