北邮22信通一枚~
跟随课程进度每周更新数据结构与算法的代码和文章
持续关注作者 解锁更多邮苑信通专属代码~
获取更多文章 请访问专栏~
北邮22信通_青山如墨雨如画的博客-CSDN博客
目录
题干描述
解析
1.string库函数
2.使用KMP算法思想
注解1
注解2
注解3
题干描述
设计函数 char *locatesubstr(char *str1,char *str2),查找str2指向的字符串在str1指向的字符串中首次出现的位置,返回指向该位置的指针。若str2指向的字符串不包含在str1指向的字符串中,则返回空指针NULL。
注意这里必须使用指针而不是数组下标来访问字符串。
函数接口定义:\n\nchar *locatesubstr(char *str1,char *str2);
其中 str1 和 str2 都是用户传入的参数,其含义如题面所述 。若查找成功则返回指向该位置的指针,若失败则返回空指针。
裁判测试程序样例:
#include <iostream>
using namespace std;
char* locatesubstr(char* str1, char* str2);
int main()
{
char str1[505], str2[505];
char* p;
gets(str1);
gets(str2);
p = locatesubstr(str1, str2);
if (p == NULL)
printf("NULL!\n");
else puts(p);
return 0;
}输入样例:
didjfsd dabcxxxxxx
abc
输出样例:
abcxxxxxx
解析
1.string库函数
首先如果不用KMP算法,我们可以使用C++string库中自带的库函数,也可以轻松解决这道问题,我们来看一下代码:
#include<iostream>
#include<cstring>
using namespace std;
char* locate(char* s, char* e)
{
string m = s;
int num = m.find(e);
if (num == -1)
throw "non_found";
//cout << "num=" << num << endl;
return (s + num);
}
int main()
{
try
{
char a[] = "hello world";
char b[] = "world";
char d[] = "print";
char* result = locate(a, b);
while (*result != '\0')
cout << *(result++);
}
catch (const char*ss)
{
cout << ss << endl;
}
return 0;
}解释一下:传入两个参数,分别是待查询的字符串和目标子串。然后调用string库中的find函数,寻找子串在主串中的位置,如果没有找到,抛出异常,如果找到了则从这个位置开始,返回剩余全部主串;
2.使用KMP算法思想
char* locatesubstr(char* str1, char* str2)
{
if (*str2 != '\0')
while (*str1 != '\0')
{
for (int i = 0; *(str1 + i) == *(str2 + i); i++)
if (*(str2 + i + 1) == '\0')
return str1;
str1++;
}
return NULL;
}这段代码看着好像难以理解,我们加一些输出作为调试,来看看效果怎么样:
注解1
#include<iostream>
#include<cstring>
using namespace std;
char* locate(char* s, char* e)
{
string m = s;
int num = m.find(e);
if (num == -1)
throw "non_found";
//cout << "num=" << num << endl;
return (s + num);
}
char* locatesubstr(char* str1, char* str2)
{
if (*str2 != '\0')
while (*str1 != '\0')
{
for (int i = 0; *(str1 + i) == *(str2 + i); i++)
{
cout << "i的值为:" << i << endl;
if (*(str2 + i + 1) == '\0')
return str1;
}
throw "non_found";
cout << "str1++" << endl;
str1++;
}
return NULL;
}
int main()
{
system("color 0A");
try
{
char a[] = "hello world";
char b[] = "world";
char d[] = "print";
char* result = locate(a, b);
while (*result != '\0')
cout << *(result++);
cout << endl;
char* results = locatesubstr(a, b);
while (*results != '\0')
cout << *(results++);
}
catch (const char*ss)
{
cout << ss << endl;
}
return 0;
}输出的结果为:
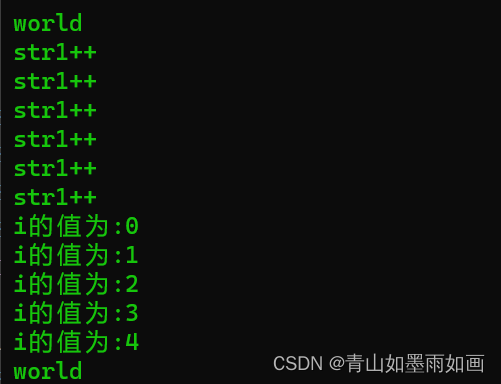
我们发现,首先,str1++这句代码执行了6次,i的值被修改了5次。 根据代码我们不难发现,这段代码的实现方法是,首先找到和子串首字符相同的字符,看看后面的字符是否也相同。
对我们调试程序输入的hello world 所运行出的结果的解释:
首先,i = 0;for循环满足的条件是*str1 == *str2,显然前6个字符都不满足。
根据BF算法,主串向后移动6次;
从第7个字符开始,程序最终进入for循环,继续依次比较子串和主串后面的内容,
因为每次都满足条件*(str1 + i) == *(str2 + i);所以i持续自加,直到自加5次后子串比较完毕,
*(str2 + i + 1) == '\0',也就是寻找成功,返回移动后的主串。
最终通过主程序输出了world。
注解2
下面的例子,我们测试一个找不到的情况:
int main()
{
system("color 0A");
try
{
char a[] = "hello world";
char b[] = "world";
char d[] = "print";
char* results = locatesubstr(a, d);
while (*results != '\0')
cout << *(results++);
}
catch (const char*ss)
{
cout << ss << endl;
}
return 0;
}运行结果为:

发现str1一直在比较并向后移动,最终返回NULL值。
注解3
再换一个:
int main()
{
system("color 0A");
try
{
char a[] = "hello world";
char b[] = "world";
char d[] = "print";
char e[] = "word";
char* results = locatesubstr(a, e);
while (*results != '\0')
cout << *(results++);
}
catch (const char*ss)
{
cout << ss << endl;
}
return 0;
} 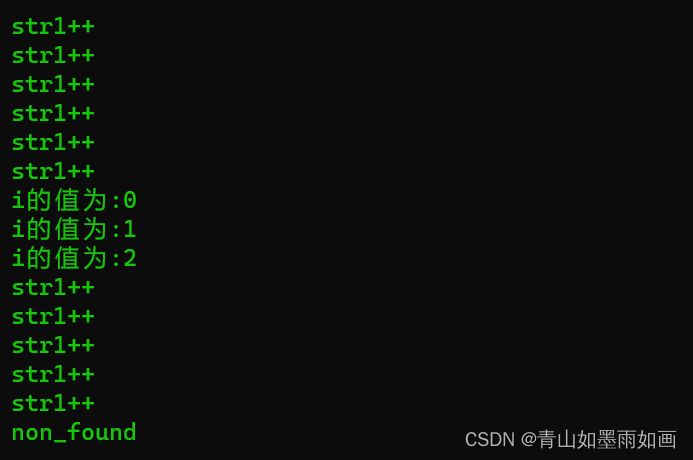
发现如我们所想,主串先向后移动6次,
然后word前三个字符相同,进入for循环,i自加3次,
发现第四个字符不同,主串继续向后移动strlen(world)这么多次,
最终返回NULL值。