js的堆栈和垃圾回收机制(gc)
本文目录
- js的堆栈和垃圾回收机制(gc)
- 堆栈
- 深拷贝和浅拷贝
- 实现深拷贝
- 垃圾回收机制
- 栈溢出
- 概念
- 垃圾产生
- 算法策略
- V8引擎的优化
- 新生代:Scavenge 算法
- 老生代:标记-清除-整理 算法
堆栈
在js引擎中对变量的存储主要有两种位置
栈内存(stack)
堆内存(heap)
栈内存(stack):基本数据类型(Number、String 、Boolean、Null和Undefined)存储在栈中,按值访问,栈会自动分配内存空间,自动释放,存放简单类型,简单的数据段,占据固定大小的空间。
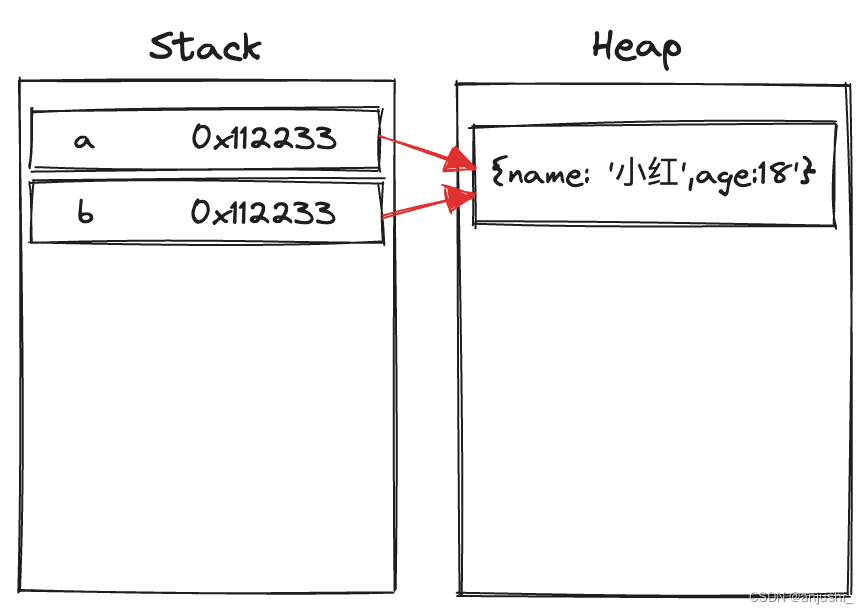
堆内存(heap):引用数据类型(Object 、Array 、Function等)的具体内容存储在堆中,其在堆内存中的引用地址(指针)存储在栈中,按引用访问(访问引用类型的数据时,首先从栈中获得该对象的地址指针,然后再从堆内存中取得所需的数据)动态分配的内存,大小不定也不会自动释放,存放引用类型
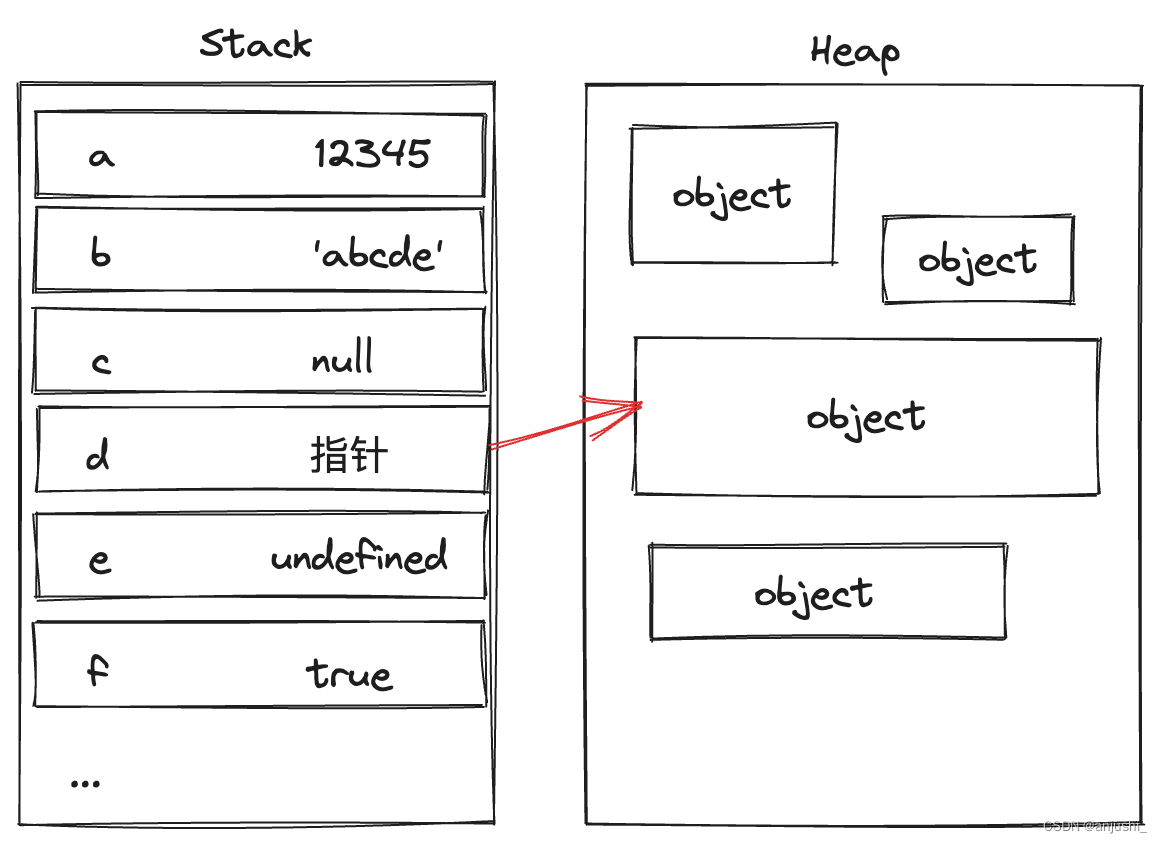
简单数据类型是在栈里直接开辟一个空间存放它的值
复杂数据类型则是在栈里开辟一个空间存放它内容的地址(十六进制),这个地址指向存放在堆里的内容
为什么基本数据类型存储在栈中,引用数据类型存储在堆中?
JavaScript引擎需要用栈来维护程序执行期间的上下文的状态,如果栈空间大了的话,所有数据都存放在栈空间里面,会影响到上下文切换的效率,进而影响整个程序的执行效率。
- 基本类型
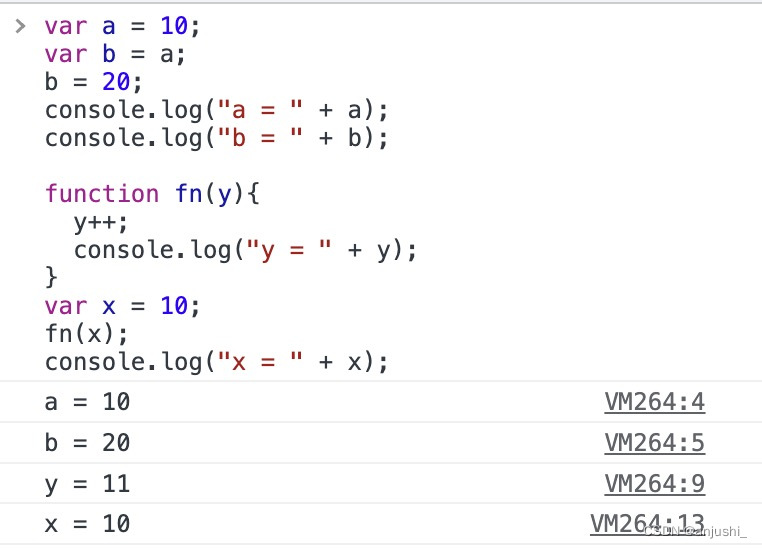
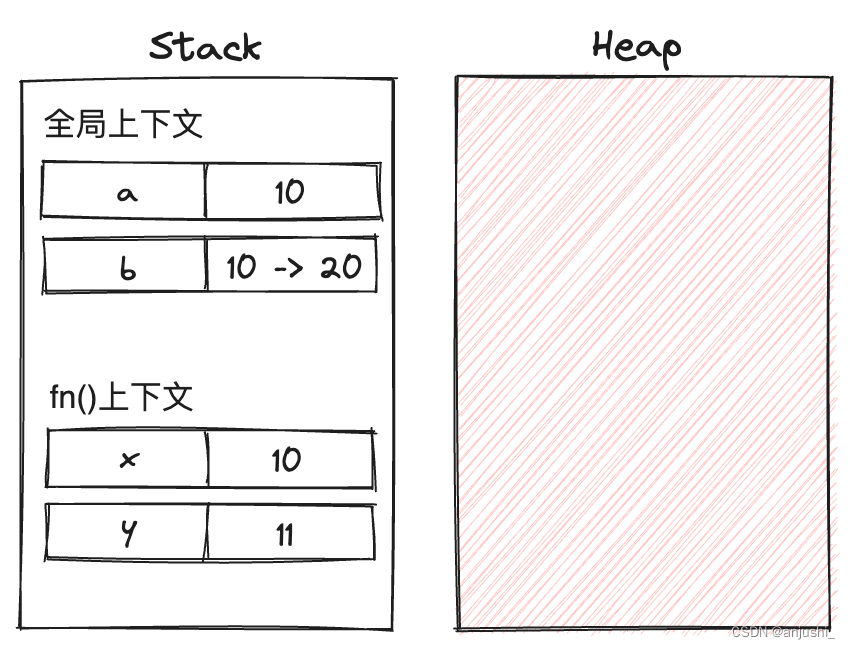
var a = 10; // 栈内存:a -> 10
var b = a; // 栈内存:b -> 10
b = 20; // 栈内存:b -> 20
// a仍然是10,b现在是20。
// 函数里的形参如果是简单数据类型,它的值也是存储在栈里的
function fn(y){
y++; // 栈内存(函数作用域内):y -> 11
console.log(y); // 输出:11
}
var x = 10; // 栈内存:x -> 10
fn(x); // 将x的值复制给a,栈内存(函数作用域内):y -> 10
console.log(x); // 输出:10
// x仍然是10,因为函数内部修改y的值并不影响x的值。
- 引用类型
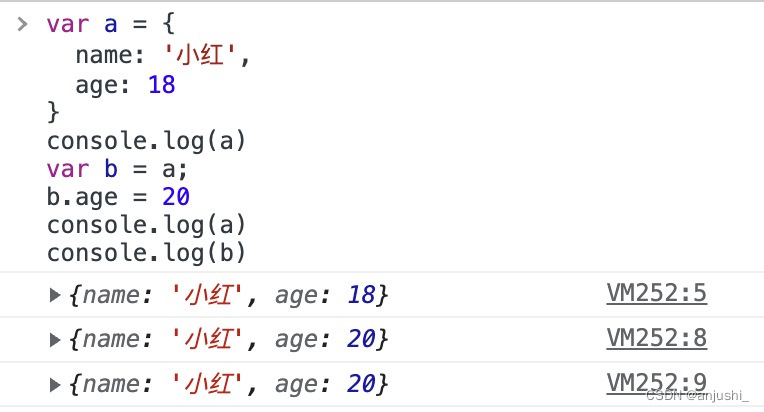
var a = {
name: '小红',
age: 18
}
console.log(a)
var b = a;
b.age = 20
console.log(a)
console.log(b)
深拷贝和浅拷贝
- 浅拷贝:只是把存储在栈里的内容进行了赋值。
- 深拷贝:就是复杂数据类型a给另一个复杂数据类型b赋值时,跳过栈,直接寻找a在堆里的内容进行拷贝,并在堆里为b开辟新的空间存储地址。
实现深拷贝
- JSON.parse(JSON.stringify(a))
var b = JSON.parse(JSON.stringify(a));
对象的属性值不能是 undefined、symbol、函数、日期和正则
- Object.assign(obj1, obj2)
let obj = {
id: 1,
name: '张三',
age: 10,
}
let newObj = Object.assign({}, obj)
只有一级属性为深拷贝,二级属性后就是浅拷贝

二级属性例子
let obj = {
id: 1,
name: '张三',
age: 10,
friends: ['李四', '王五'],
address: {
street: '某某街',
number: 100
}
};
let newObj = Object.assign({}, obj);
在栈内存中,obj和newObj的friends和address属性并不直接存储这些对象的值,而是存储了指向堆内存中相应数据的引用地址(也就是Address3和Address4)
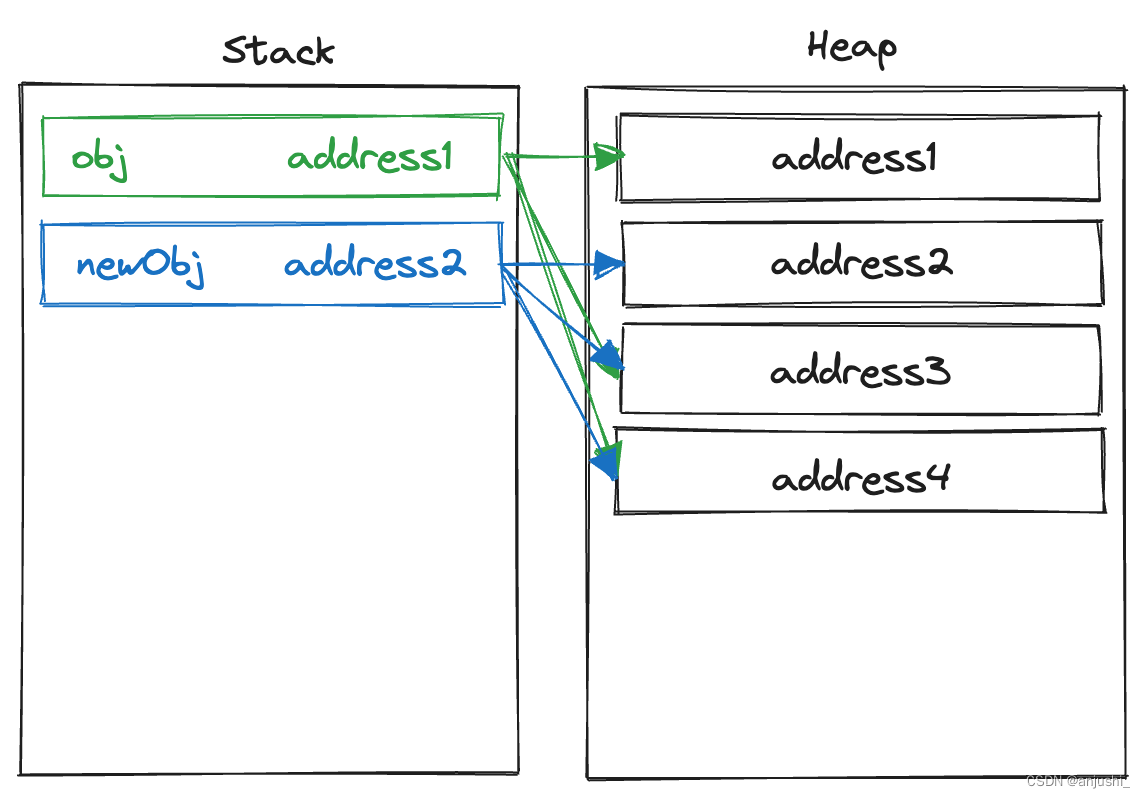
Address3和Address4是表示friends数组和address对象在堆内存中的地址。这两个属性是复杂数据类型(即它们是对象),因此他们的值被存储在堆内存中
这是因为JavaScript对于复杂数据类型(例如对象、数组)总是通过引用来处理的,而非直接存储其值。这就意味着,当你修改了obj的friends或address属性时,由于newObj的这些属性引用的是同一块堆内存,因此newObj中相应的属性值也会随之改变。这就是为什么Object.assign()方法只能实现一层深拷贝的原因
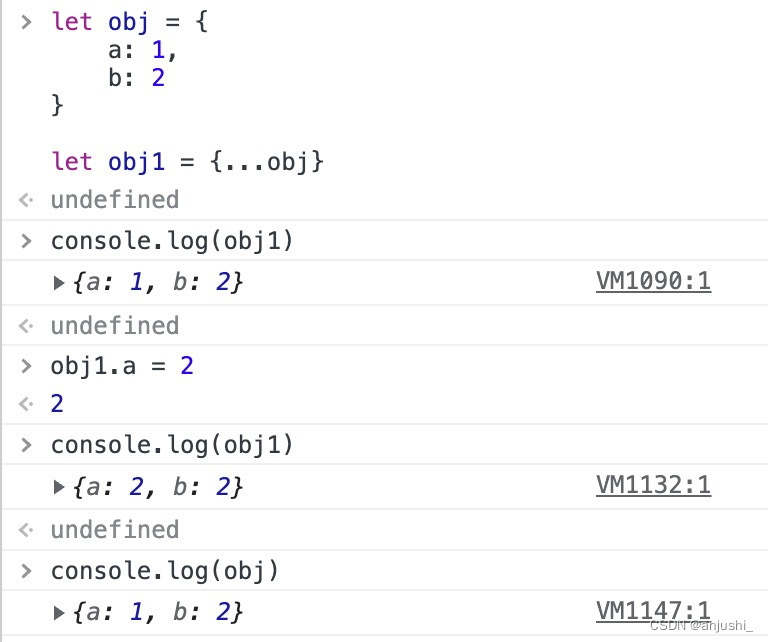
- 扩展运算符
var obj = {
a: 1,
b: 2
}
var obj1 = {…obj}
// 数组
let newArr = [...arr]
只有一级属性为深拷贝,二级属性后就是浅拷贝
- 数组使用数组方法进行深拷贝
var arr1 = [1, 2, 3, 4]
var arr2 = arr1.concat()
var arr3 = arr1.slice(1)
只有一级属性为深拷贝,二级属性后就是浅拷贝,如[1,2,3,[1,2,3]]

垃圾回收机制
栈溢出
(function foo() {
foo()
})()
栈虽然很轻量,在使用时创建,使用结束后销毁,但是不是可以无限增长的,被分配的调用栈空间被占满时,就会引起”栈溢出“的错误
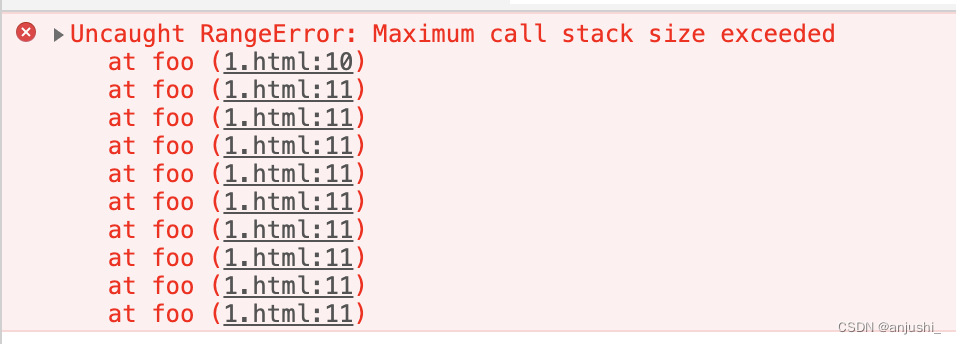
Maximum call stack size exceeded
概念
在 JavaScript 内存管理中有一个概念叫做 可达性,就是那些以某种方式可访问或者说可用的值,它们被保证存储在内存中,反之不可访问则需回收
垃圾回收过程是不实时进行的,因为JavaScript是一门单线程的语言,每次执行垃圾回收,会使程序应用逻辑暂停,执行完垃圾后回收在执行应用逻辑,这种行为称为全停顿,所以一般垃圾回收会在cpu闲时进行
垃圾产生
程序的运行需要内存,只要程序提出要求,操作系统或者运行时就必须提供内存,那么对于持续运行的服务进程,必须要及时释放内存,否则,内存占用越来越高,轻则影响系统性能,重则就会导致进程崩溃
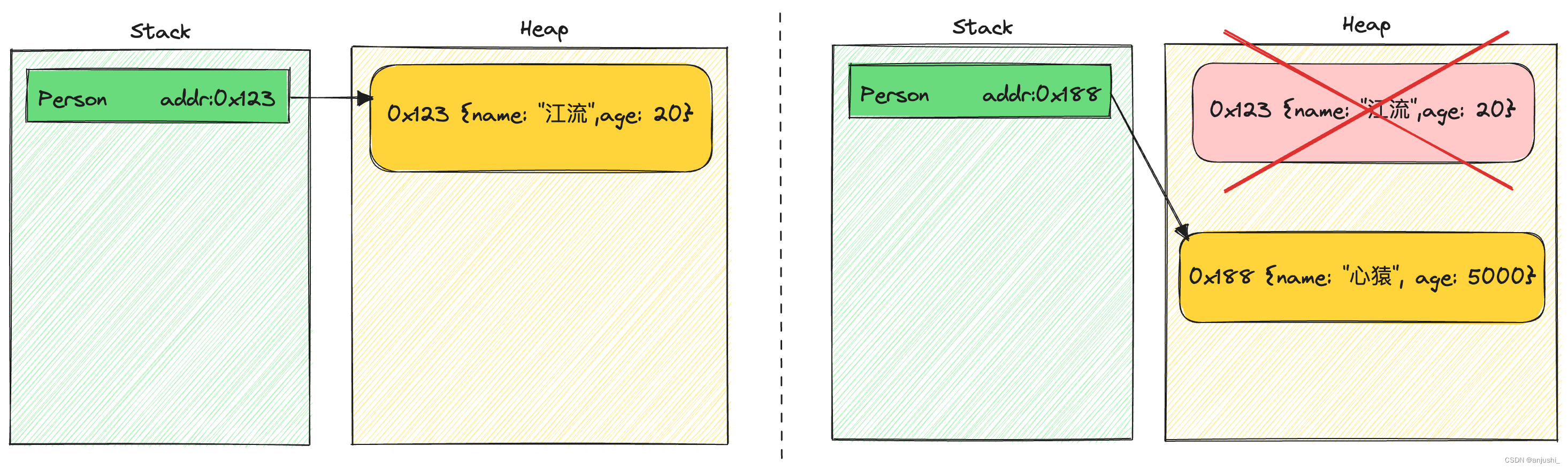
先声明了一个Person变量,它引用了对象
{name: "江流",age: 20}
接着又将这个Person变量指向了另一个对象
{name: "心猿", age: 5000}
那么之前被引用的对象,现在就成了无用对象,也永远无法使用操作该对象,这种对象就是一个垃圾
算法策略
V8引擎的优化
- 新生代内存是临时分配的内存,存活时间短,新生对象或只经过一次垃圾回收的对象
- 老生代内存是常驻内存,存活时间长,经历过一次或多次垃圾回收的对象
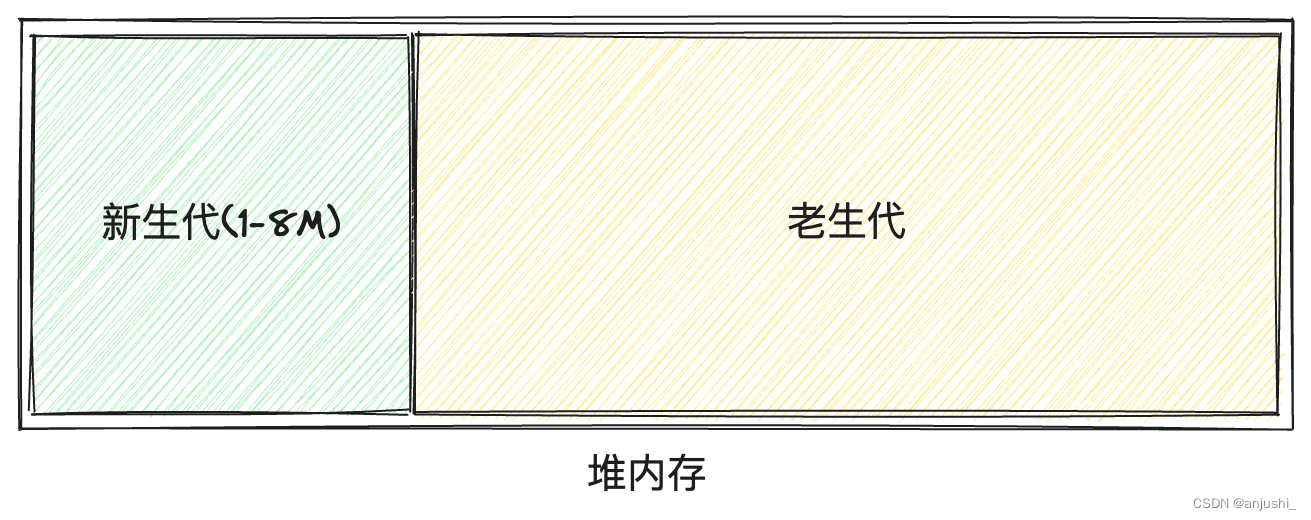
新生代:Scavenge 算法
新生代对象是通过一个名为 Scavenge 的算法进行垃圾回收,在 Scavenge 算法 的具体实现中,主要采用了一种复制式的方法即 Cheney 算法
Cheney算法 中将堆内存一分为二,一个是处于使用状态的空间 使用区(from),一个是处于闲置状态的空间 空闲区(to)
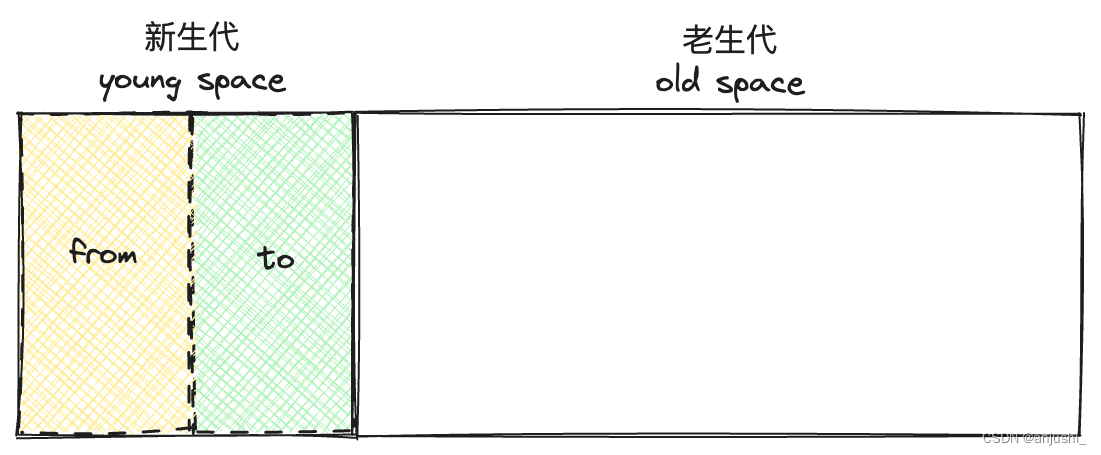
- 新的对象会首先被分配到对象(from)空间,当对象区域快写满时,就需要执行一次垃圾清理操作。
- 当进行垃圾收回时,先将 from 空间中存活的对象复制到空闲(to)空间进行保存,对未存活的空间进行回收。
- 复制完成后,对象空间和空闲空间进行角色调换,空闲空间变成新的对象空间,原来的对象空间则变成空闲空间。
- 这样就完成了垃圾对象的回收操作,同时这种角色调换的操作能让新生代中的这两块区域无限重复使用下去
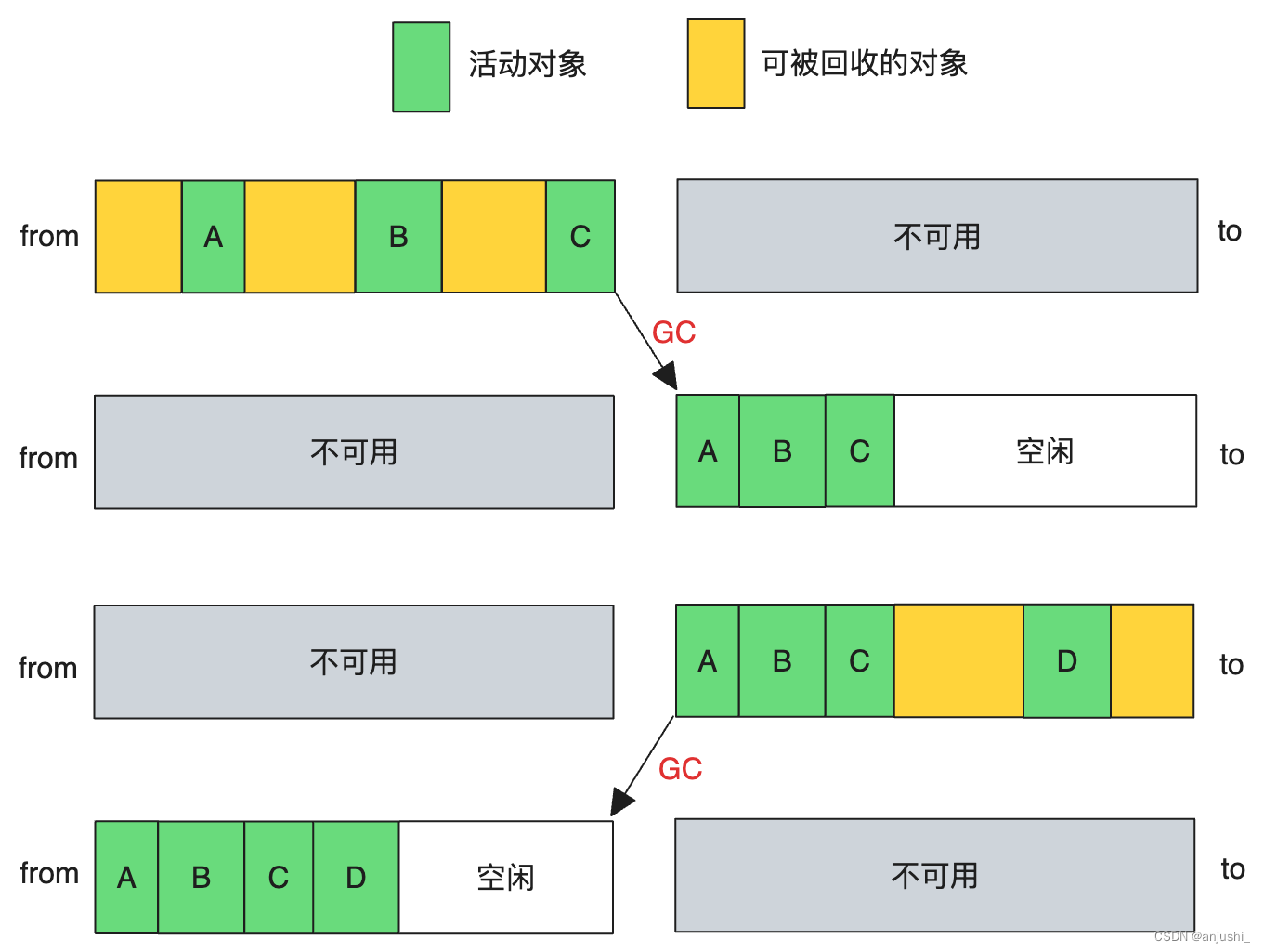
缺点:堆使用效率低下
当一个对象在两次变换中还存在时,就会从 新生代区 晋升到 老生代区,这一过程被称为对象晋升策略
老生代:标记-清除-整理 算法
复制大对象所花费的时间长,执行效率并不高
-
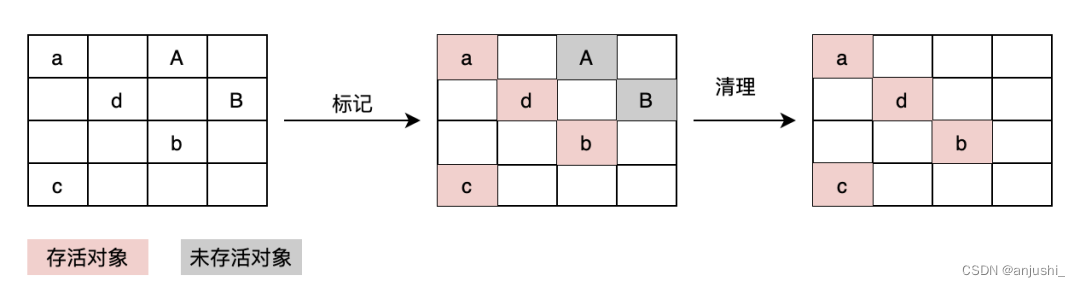
标记-清除(Mark-Sweep)
分为标记和清除两个阶段。标记阶段会遍历堆中所有的对象,并对存活的对象进行标记,清除阶段则是对未标记的对象进行清除
-
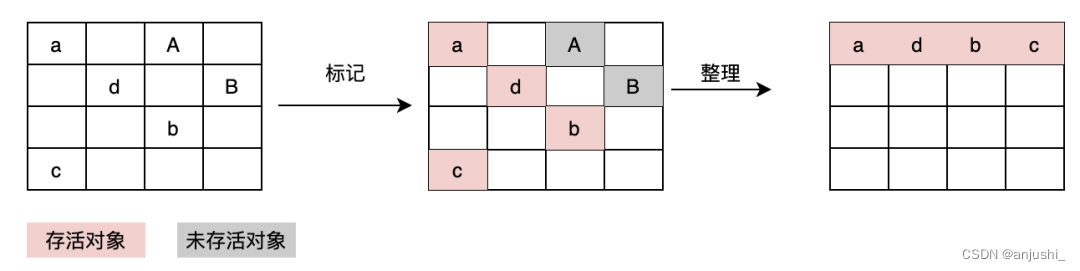
标记-整理(Mark-Compact)
经过标记清除之后的内存空间会生产很多不连续的碎片空间,这种不连续的碎片空间中,在遇到较大的对象时可能会由于空间不足而导致无法存储。为了解决内存碎片的问题,需要使用另外一种算法 - 标记-整理(Mark-Compact)。标记整理对待未存活对象不是立即回收,而是将存活对象移动到一边,然后直接清掉端边界以外的内存
-
增量标记
为了避免垃圾回收时间过长影响其他程序的执行,V8将标记过程分成一个个小的子标记过程,同时让垃圾回收和JavaScript应用逻辑代码交替执行,直到标记阶段完成,这个过程为增量标记算法
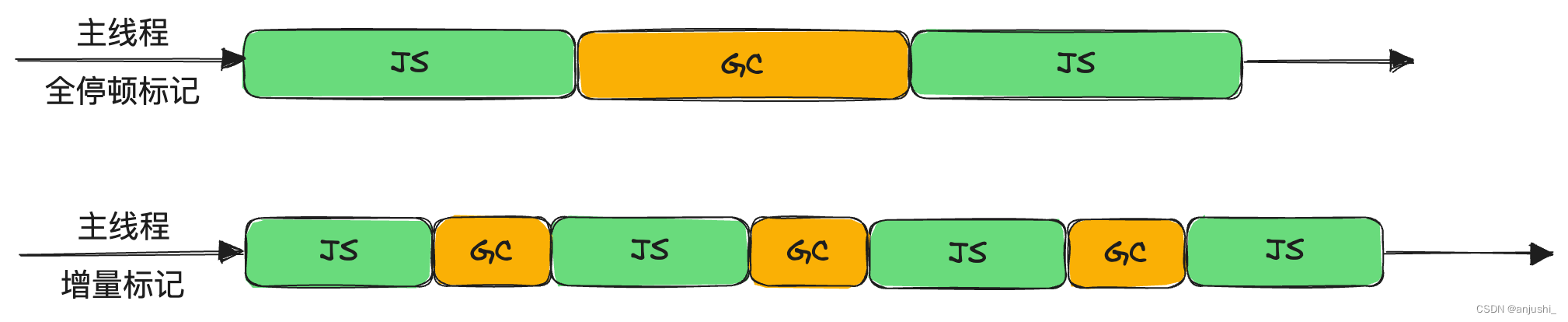
把垃圾回收这个大的任务分成一个个小任务,穿插在 JavaScript任务中间执行