本文作者:艾宏峰
算法工程师
M6 Global赛道总排名4th
KDD Cup 2022风电功率预测飞桨赛道5th
“中国软件杯”大学生软件设计大赛——龙源风电赛道,5月31日预选赛截止,80%选手将晋级区域赛,欢迎大家抓紧报名!

赛题背景
随着清洁能源的快速发展,风力发电已经成为可再生能源的重要组成部分,然而风具有随机性特点,常规天气预报无法准确反映出风电场所在区域的真实风速,从而造成发电功率预测准确率低下,影响电力供需平衡。因此,提高风电功率预测的准确性,为电网调度提供科学支撑,对我国能源产业有十分重要的价值。

此次赛题由百度飞桨和龙源电力设置,数据集由全球最大风电运营企业龙源电力提供,采集自真实风力发电数据,要求选手基于百度飞桨 PaddlePaddle 设计一个可以通过深度学习技术实现对风力发电进行功率预测及管理的软件系统。

时序预测技术介绍
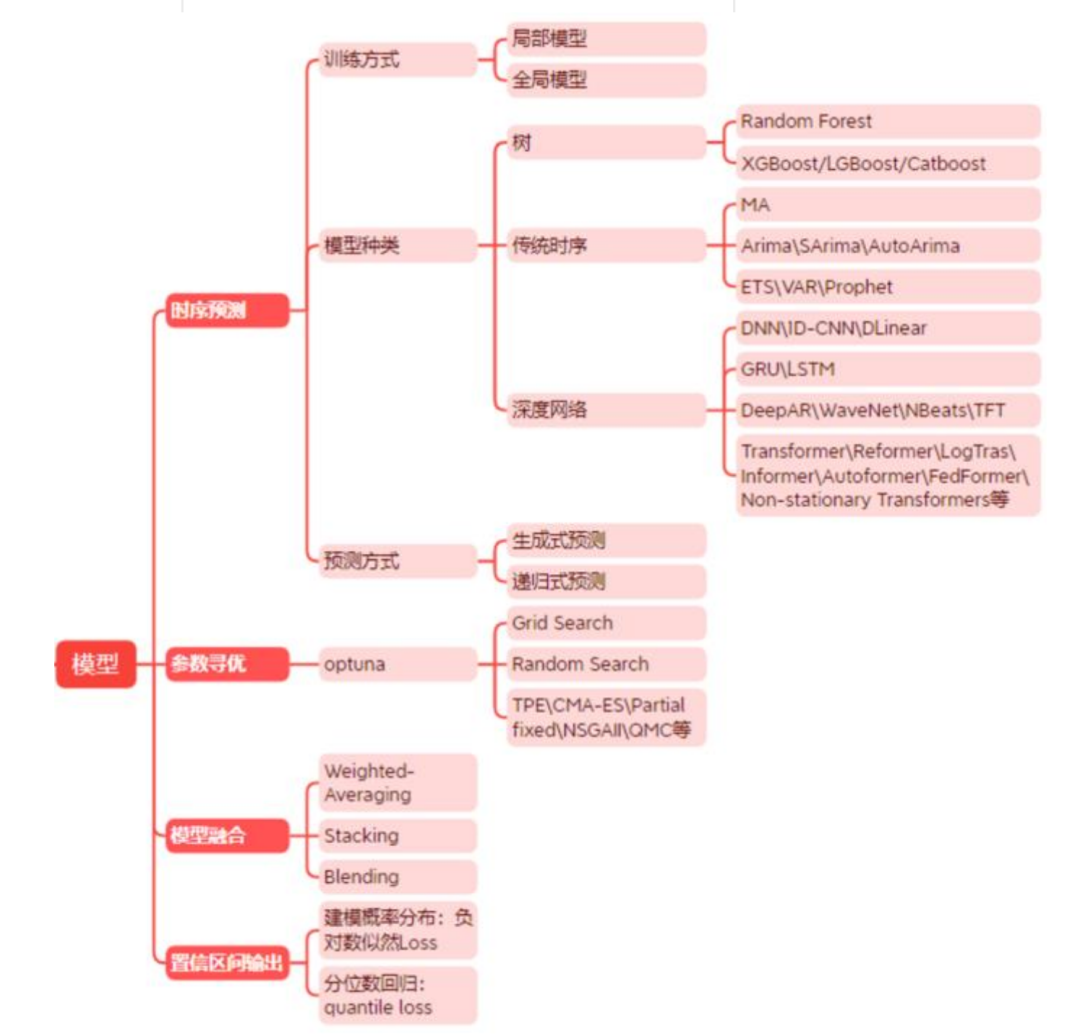
时间序列预测技术是指基于历史数据和时间变化规律,通过数学模型和算法对未来发展趋势进行预测的一种技术。时间序列预测技术广泛应用于经济、金融、交通、气象等领域,以帮助人们做出更加准确的决策。
时序预测从不同角度看有不同分类:
-
从实现原理的角度,可以分为:传统统计学,机器学习(又分非深度学习和深度学习);
-
按预测步长区分,可以分为单步预测和多步预测;
-
按输入变量区分,可以分为自回归预测和使用协变量进行预测;
-
按输出结果区分,可以分为点预测和概率预测;
-
按目标个数区分,可以分为一元、多元、多重时间序列预测

这些分类是不同角度下的分类,同一种算法往往只能是分类中的一种,例如传统的统计学算法只适合做自回归预测而不适合协变量预测。
时间序列预测技术的研究历史可以追溯到20世纪初期。最早的时间序列预测方法是基于时间平均法和线性趋势法,后来发展出了指数平滑法、ARIMA 模型、神经网络模型等预测方法。随着机器学习和深度学习的发展,时间序列预测技术也得到了不断的拓展和创新,比如 Transformer 与时序的结合。

风电功率预测研究意义与价值
时间序列预测技术有着广泛的应用场景。例如,
-
在经济领域,时间序列预测技术可以用于股票市场预测、经济增长预测、通货膨胀预测等。
-
在交通领域,时间序列预测技术可以用于公交车到站时间预测、交通拥堵预测等。
-
在气象领域,时间序列预测技术可以用于气象灾害预警、天气变化预测等。
而在风电功率预测上,其研究意义和价值更不容忽视,它们包括:
-
提高风电发电效率:通过精准预测风电功率,可以合理安排风电机组的运行,提高风电发电效率,减少能源浪费。
-
保障电网稳定运行:风电功率预测可以帮助电网运营商及时调整电网负荷,避免电网过载或供电不足等问题,保障电网稳定运行。
-
促进可再生能源发展:风电功率预测可以提高风电发电的可靠性和经济性,促进可再生能源发展,降低对传统能源的依赖。
-
降低能源成本:通过精准预测风电功率,可以有效避免风电机组的过剩和不足,降低能源成本,提高能源利用率。
-
推动智能电网建设:风电功率预测是智能电网建设的重要组成部分,可以实现对风电发电的精准监控和管理,推动智能电网建设。

赛制赛段
预选赛
5月31日截止,算法赛,80%选手晋级区域赛;
区域赛
6-7月,算法赛60%+软件赛40%,颁发省级奖项;
总决赛
8月,软件赛,颁发国赛奖项。

赛题数据
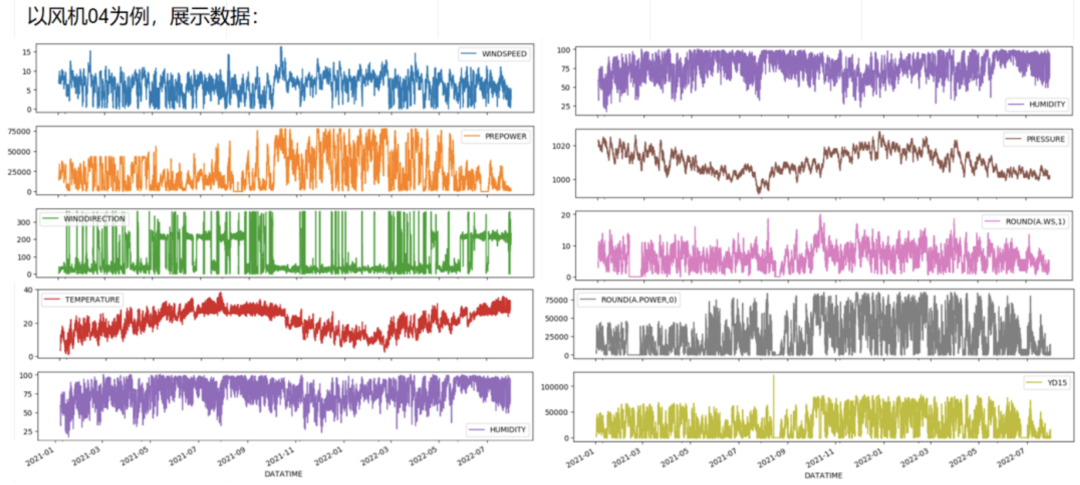
本赛题数据集由全球最大风电运营企业龙源电力提供,采集自真实风力发电数据。预选赛训练数据和区域赛训练数据分别为不同10个风电场近一年的运行数据共30万余条,每15分钟采集一次,包括风速、风向、温度、湿度、气压和真实功率等,具体的数据字段中英文对应如下:
-
WINDSPEED 预测风速
-
WINDDIRECTION 风向
-
TEMPERATURE 温度
-
HUMIDITY 湿度
-
PRESSURE 气压
-
PREPOWER 预测功率(系统生成)
-
ROUND(A.WS,1)实际风速
-
ROUND(A.POWER,0) 实际功率(计量口径一)
-
YD15 实际功率(预测目标,计量口径二)
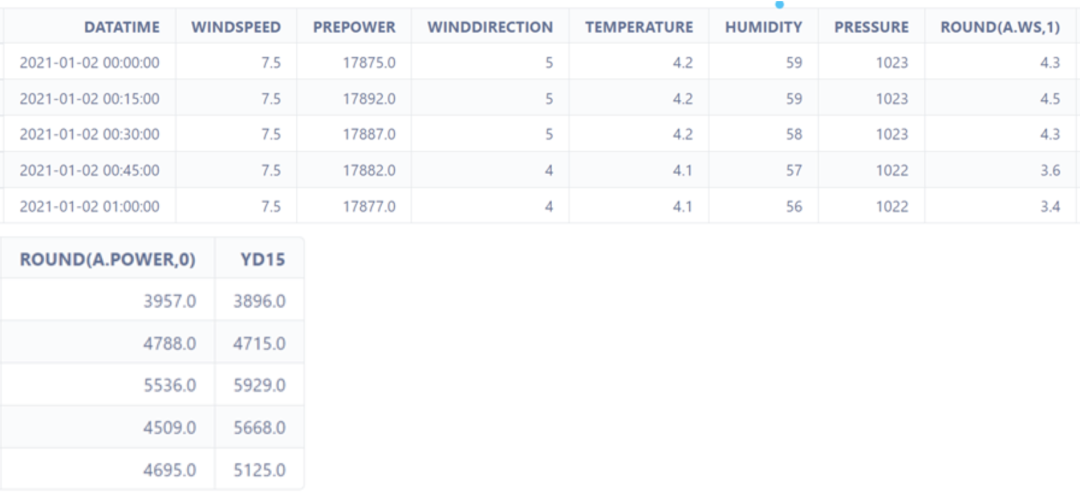
注:“预测风速”字段,指的是由权威的气象机构,像是中央气象台、欧洲国家气象中心等发布的商业气象数据源。从时间线来说,实际功率预测需要提前 36 个小时、72 个小时、240 的小时等获得数值天气预报,从而进行功率的预测。
数据注意事项
-
原始数据集存在不同格式的风机数据,需要额外的数据拼接处理工作;
-
每个风机的最后一天的 ROUND(A.POWER,0)和 YD15 两个字段数据基本为空,这是出题方希望我们预测填空的数据;
-
csv 内的时间戳未必有序,需要自行排序;
-
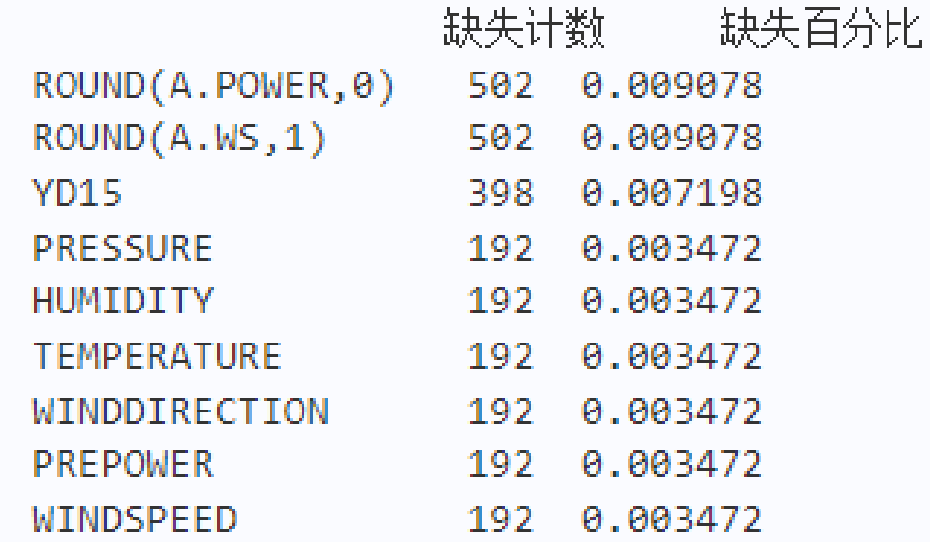
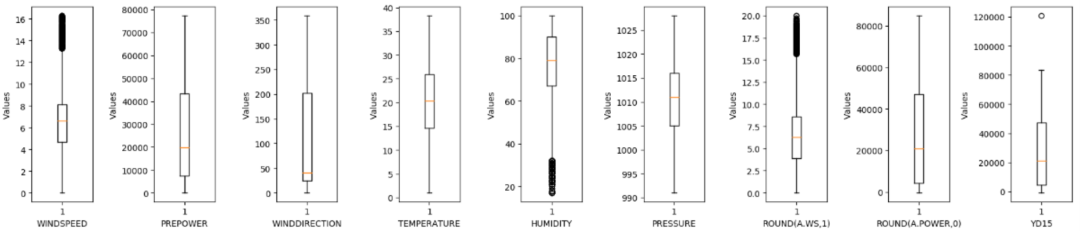
数据存在缺失和离群值;
-
数据存在重复样本(即同一时间戳有多条样本)。以风机04为例,重复样本数量: 34764, 占比: 38.68340232340766%。
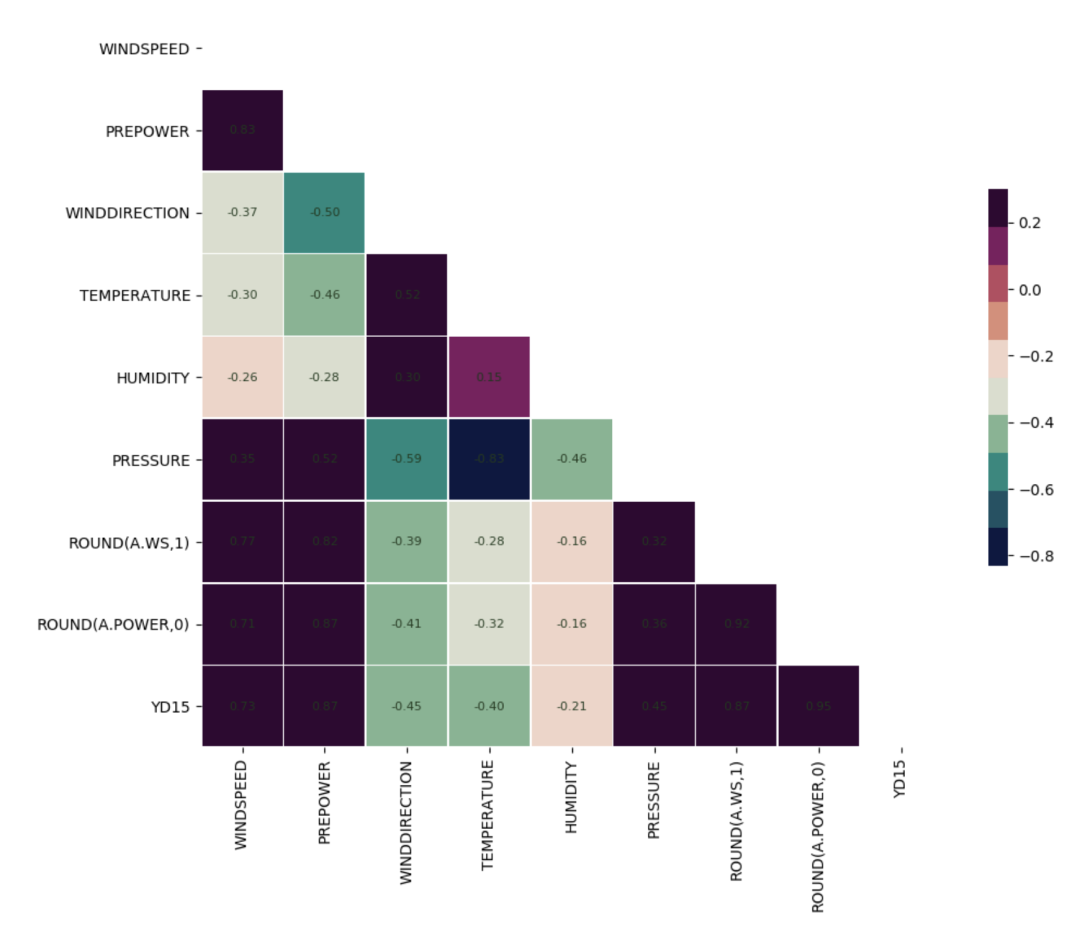
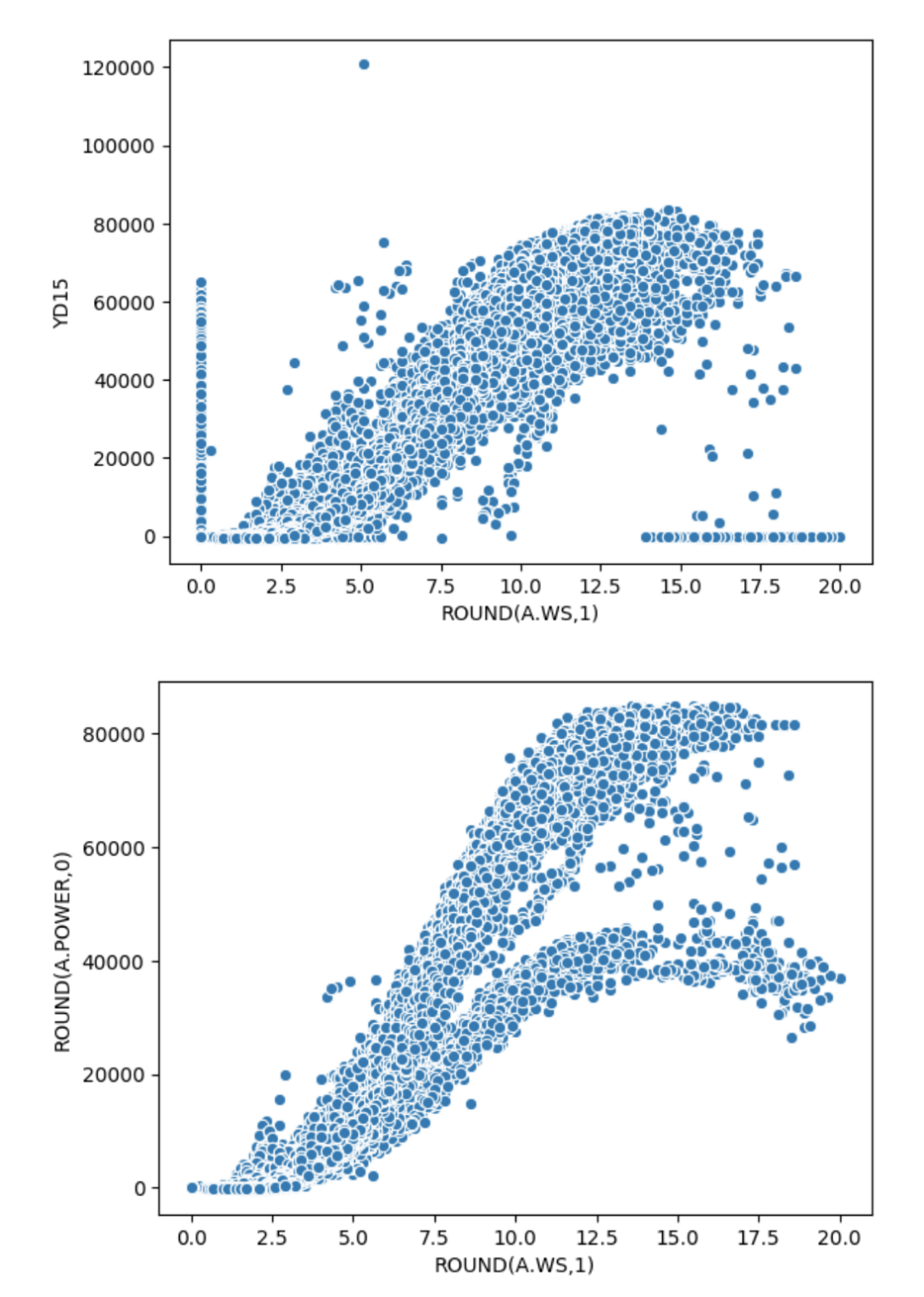
以风机4为例的EDA结果展示
官方对数据的一些回复
-
由于测量设备和网络传输问题,YD15 可能出现数据异常(包括用于评测的输入数据)。
-
实际上由于一些脏数据的存在,YD15 有时候会缺失或异常,这个时候 ROUND(A.POWER,0)如果有正常值的话,可以被视为YD15的替代。
-
YD15 的异常值处理规则是,当 YD15 为空时,按照逻辑依次用 ROUND(A.POWER,0)、PREPOWER 进行替换。
-
如何定义 YD15 存在异常?在本赛题中,YD15 异常包括两种情况:(1) 空值,(2) 在一段时间内、其它字段正常变化时,YD15 持续完全不变。除以上两种情况之外,YD15 的数值变化都可认为是正常现象,如为 0 或负值。
个人补充
-
当实际风速为 0 时,存在功率>0 有些异常,然后有些风速过大>12.5,存在功率为 0 的异常。
-
目标列 ROUND(A.POWER,0)和 YD15,与风速 WINDSPEED、PREPOWER、PRESSURE 和 ROUND(A.WS,1)强相关;
-
目标列 ROUND(A.POWER,0)和 YD15 之间就有很强的相关性;

评测说明

算法部分
本次比赛要求选手将算法模型提交至人工智能学习与实训社区 AI Studio 进行自动评测,预选赛开放10个风场数据,区域赛开放新的10个风场数据,预选赛和区域赛算法成绩各占30%。
要求选手基于飞桨 PaddlePaddle 根据官方提供的数据集,设计一种利用当日05:00之前的数据,预测次日00:00至23:45实际功率的方法。准确率按日统计,根据10个风电场平均准确率进行排名;准确率相同的情形下,根据每日单点的平均最大偏差绝对值排名。
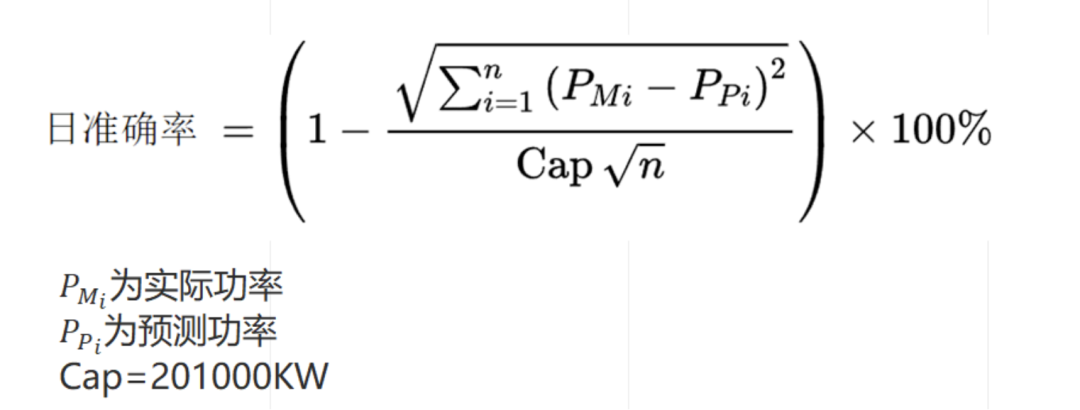
def calc_acc(y_true, y_pred):
rmse = np.sqrt(np.mean((y_true - y_pred)**2))
return 1 - rmse/201000 软件部分
软件部分
本次比赛要求选手基于 Web 技术实现:
数据可视化
将预测结果以图表等形式展示出来,便于用户进行观察和分析;
实时更新与滚动预测
能够基于提供的数据实时模拟真实功率、预测功率及其之间的差异,通过调节过去不同长度的时间段,以更新未来预测结果,且预测的时间段可调节;
响应式设计
支持多种终端,包括 PC 端、移动端等,以适应不同设备的屏幕尺寸和分辨率;
其他创新附加功能

提交说明
测评数据的格式如下:
| --- ./infile(内置于测评系统中,参赛选手不可见)
| --- 0001in.csv
| --- 0002in.csv
| --- ...参赛选手需要提交一个命名为 submission.zip 的压缩包,并且压缩包内应包含:
| --- ./model # 存放模型的目录,并且大小不超过200M(必选)
| --- ./env # 存放依赖库的目录(可选)
| --- predict.py # 评估代码(必选)
| --- pip-requirements.txt # 存放依赖库的文件(可选)
| --- …参赛选手在代码提交页面提交压缩包后,测评系统会解压选手提交的压缩包,并执行如下命令:
python predict.py测评文件 predict.py 应该完成的功能是:读取 infile 文件夹下的测评数据,并将预测结果保存到 pred 文件夹中。
| --- ./pred(需要选手生成)
| --- 0001out.csv
| --- 0002out.csv
| --- …
基线模型流程
基于飞桨 PaddlePaddle 的多任务 LSTM 时序预测基线模型 pipeline 如下:
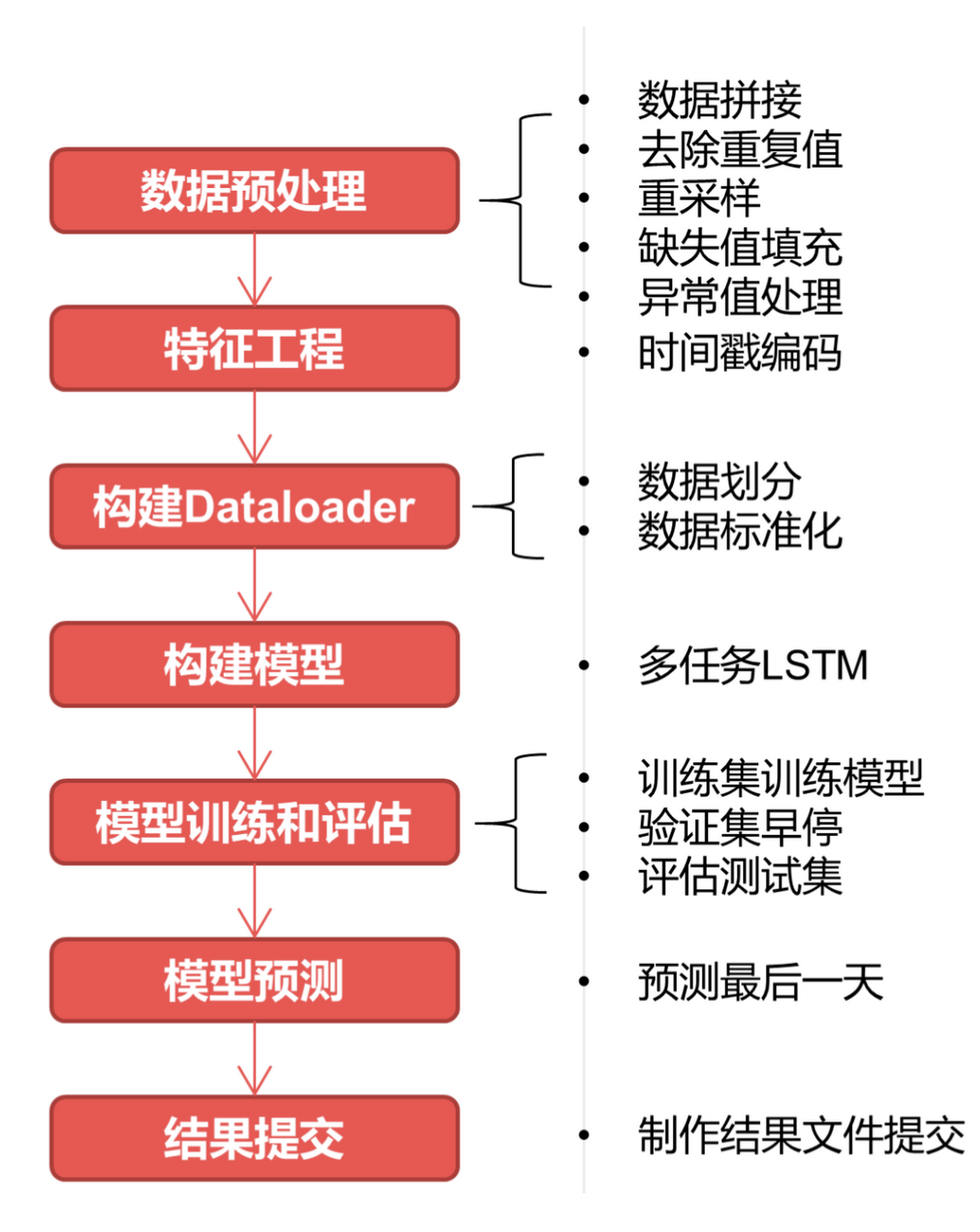
以时间序列举例,因为一般测试集也会是未来数据,所以我们也要保证训练集是历史数据,而划分出的验证集是未来数据,不然会发生“时间穿越”的数据泄露问题,导致模型过拟合(例如用未来预测历史数据),这个时候就有两种验证划分方式可参考使用:
-
TimeSeriesSplit:Sklearn 提供的 TimeSeriesSplit;
-
固定窗口滑动划分法:固定时间窗口,不断在数据集上滑动,获得训练集和验证集。(个人推荐这种)
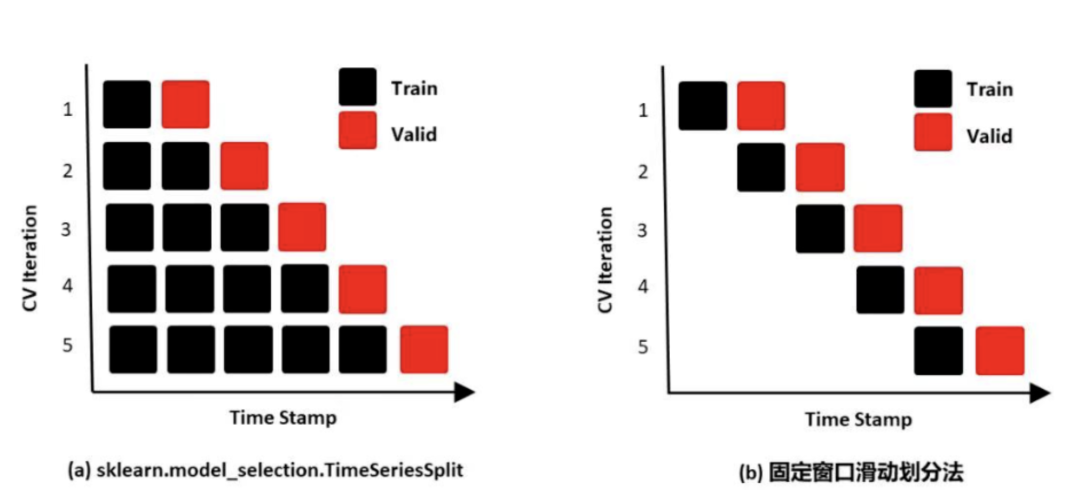
在时序任务中,有2类数据源,如下图所示:
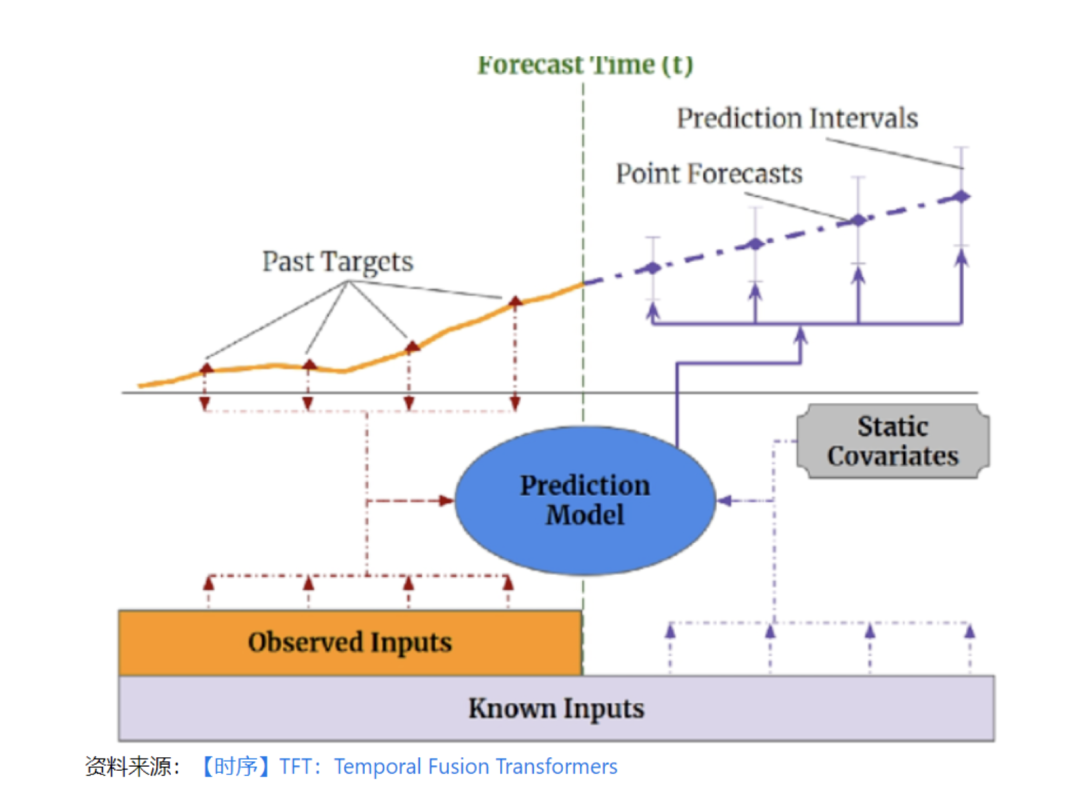
(1)静态变量(Static Covariates):不会随时间变化的变量,例如风机id、风机位置;
(2)时变变量(Time-dependent Inputs):随时间变化的变量;
-
过去观测的时变变量(Past-observed Inputs):过去可知,但未来不可知,例如历史风速、温度、气压等
-
先验已知未来的时变变量(Apriori-known Future Inputs):过去和未来都可知,例如天气预报未来风速、温度、气压等;
数据加载器的代码如下:
# unix时间戳转换
def to_unix_time(dt):
# timestamp to unix
epoch = datetime.datetime.utcfromtimestamp(0)
return int((dt - epoch).total_seconds())
def from_unix_time(unix_time):
# unix to timestamp
return datetime.datetime.utcfromtimestamp(unix_time)
class TSDataset(paddle.io.Dataset):
"""时序DataSet
划分数据集、适配dataloader所需的dataset格式
ref: https://github.com/thuml/Autoformer/blob/main/data_provider/data_loader.py
"""
def __init__(self, data,
ts_col='DATATIME',
use_cols =['WINDSPEED', 'PREPOWER', 'WINDDIRECTION', 'TEMPERATURE', 'HUMIDITY',
'PRESSURE', 'ROUND(A.WS,1)', 'ROUND(A.POWER,0)', 'YD15',
'month', 'day', 'weekday', 'hour', 'minute'],
labels = ['ROUND(A.POWER,0)', 'YD15'],
input_len = 24*4*5, pred_len = 24*4, stride=19*4, data_type='train',
train_ratio = 0.7, val_ratio = 0.15):
super(TSDataset, self).__init__()
self.ts_col = ts_col # 时间戳列
self.use_cols = use_cols # 训练时使用的特征列
self.labels = labels # 待预测的标签列
self.input_len = input_len # 模型输入数据的样本点长度,15分钟间隔,一个小时14个点,近5天的数据就是24*4*5
self.pred_len = pred_len # 预测长度,预测次日00:00至23:45实际功率,即1天:24*4
self.data_type = data_type # 需要加载的数据类型
self.scale = True # 是否需要标准化
self.train_ratio = train_ratio # 训练集划分比例
self.val_ratio = val_ratio # 验证集划分比例
# 由于赛题要求利用当日05:00之前的数据,预测次日00:00至23:45实际功率
# 所以x和label要间隔19*4个点
self.stride = stride
assert data_type in ['train', 'val', 'test'] # 确保data_type输入符合要求
type_map = {'train': 0, 'val': 1, 'test': 2}
self.set_type = type_map[self.data_type]
self.transform(data)
def transform(self, df):
# 获取unix时间戳、输入特征和预测标签
time_stamps, x_values, y_values = df[self.ts_col].apply(lambda x:to_unix_time(x)).values, df[self.use_cols].values, df[self.labels].values
# 划分数据集
# 这里可以按需设置划分比例
num_train = int(len(df) * self.train_ratio)
num_vali = int(len(df) * self.val_ratio)
num_test = len(df) - num_train - num_vali
border1s = [0, num_train-self.input_len-self.stride, len(df)-num_test-self.input_len-self.stride]
border2s = [num_train, num_train + num_vali, len(df)]
# 获取data_type下的左右数据截取边界
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
# 标准化
self.scaler = StandardScaler()
if self.scale:
# 使用训练集得到scaler对象
train_data = x_values[border1s[0]:border2s[0]]
self.scaler.fit(train_data)
data = self.scaler.transform(x_values)
# 保存scaler
pickle.dump(self.scaler, open('/home/aistudio/submission/model/scaler.pkl', 'wb'))
else:
data = x_values
# array to paddle tensor
self.time_stamps = paddle.to_tensor(time_stamps[border1:border2], dtype='int64')
self.data_x = paddle.to_tensor(data[border1:border2], dtype='float32')
self.data_y = paddle.to_tensor(y_values[border1:border2], dtype='float32')
def __getitem__(self, index):
"""
实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据)
"""
# 由于赛题要求利用当日05:00之前的数据,预测次日00:00至23:45实际功率
# 所以x和label要间隔19*4个点
s_begin = index
s_end = s_begin + self.input_len
r_begin = s_end + self.stride
r_end = r_begin + self.pred_len
# TODO 可以增加对未来可见数据的获取
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[r_begin:r_end]
ts_x = self.time_stamps[s_begin:s_end]
ts_y = self.time_stamps[r_begin:r_end]
return seq_x, seq_y, ts_x, ts_y
def __len__(self):
"""
实现__len__方法,返回数据集总数目
"""
return len(self.data_x) - self.input_len - self.stride - self.pred_len + 1
class TSPredDataset(paddle.io.Dataset):
"""时序Pred DataSet
划分数据集、适配dataloader所需的dataset格式
ref: https://github.com/thuml/Autoformer/blob/main/data_provider/data_loader.py
"""
def __init__(self, data,
ts_col='DATATIME',
use_cols =['WINDSPEED', 'PREPOWER', 'WINDDIRECTION', 'TEMPERATURE', 'HUMIDITY',
'PRESSURE', 'ROUND(A.WS,1)', 'ROUND(A.POWER,0)', 'YD15',
'month', 'day', 'weekday', 'hour', 'minute'],
labels = ['ROUND(A.POWER,0)', 'YD15'],
input_len = 24*4*5, pred_len = 24*4, stride=19*4):
super(TSPredDataset, self).__init__()
self.ts_col = ts_col # 时间戳列
self.use_cols = use_cols # 训练时使用的特征列
self.labels = labels # 待预测的标签列
self.input_len = input_len # 模型输入数据的样本点长度,15分钟间隔,一个小时14个点,近5天的数据就是24*4*5
self.pred_len = pred_len # 预测长度,预测次日00:00至23:45实际功率,即1天:24*4
# 由于赛题要求利用当日05:00之前的数据,预测次日00:00至23:45实际功率
# 所以x和label要间隔19*4个点
self.stride = stride
self.scale = True # 是否需要标准化
self.transform(data)
def transform(self, df):
# 获取unix时间戳、输入特征和预测标签
time_stamps, x_values, y_values = df[self.ts_col].apply(lambda x:to_unix_time(x)).values, df[self.use_cols].values, df[self.labels].values
# 截取边界
border1 = len(df) - self.input_len - self.stride - self.pred_len
border2 = len(df)
# 标准化
self.scaler = StandardScaler()
if self.scale:
# 读取预训练好的scaler
self.scaler = pickle.load(open('/home/aistudio/submission/model/scaler.pkl', 'rb'))
data = self.scaler.transform(x_values)
else:
data = x_values
# array to paddle tensor
self.time_stamps = paddle.to_tensor(time_stamps[border1:border2], dtype='int64')
self.data_x = paddle.to_tensor(data[border1:border2], dtype='float32')
self.data_y = paddle.to_tensor(y_values[border1:border2], dtype='float32')
def __getitem__(self, index):
"""
实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据)
"""
# 由于赛题要求利用当日05:00之前的数据,预测次日00:00至23:45实际功率
# 所以x和label要间隔19*4个点
s_begin = index
s_end = s_begin + self.input_len
r_begin = s_end + self.stride
r_end = r_begin + self.pred_len
# TODO 可以增加对未来可见数据的获取
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[r_begin:r_end]
ts_x = self.time_stamps[s_begin:s_end]
ts_y = self.time_stamps[r_begin:r_end]
return seq_x, seq_y, ts_x, ts_y
def __len__(self):
"""
实现__len__方法,返回数据集总数目
"""
return len(self.data_x) - self.input_len - self.stride - self.pred_len + 1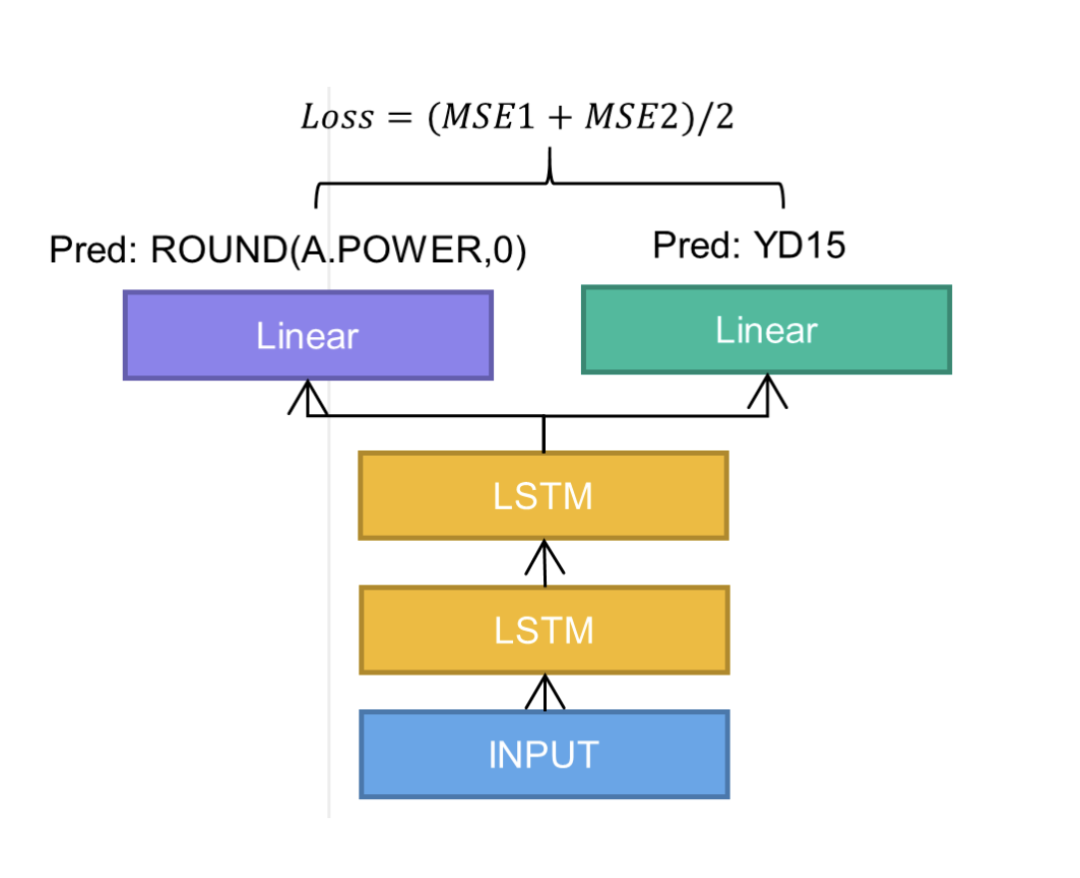
模型代码如下:
class MultiTaskLSTM(paddle.nn.Layer):
"""多任务LSTM时序预测模型
LSTM为共享层网络,对两个预测目标分别有两个分支独立线性层网络
TODO 其实该模型就是个Encoder,如果后续要引入天气预测未来的变量,补充个Decoder,
然后Encoder负责历史变量的编码,Decoder负责将 编码后的历史编码结果 和 它编码未来变量的编码结果 合并后,做解码预测即可
"""
def __init__(self,feat_num=14, hidden_size=64, num_layers=2, dropout_rate=0.7, input_len=120*4, pred_len=24*4):
super(MultiTaskLSTM, self).__init__()
# LSTM为共享层网络
self.lstm_layer = paddle.nn.LSTM(feat_num, hidden_size,
num_layers=num_layers,
direction='forward',
dropout=dropout_rate)
# 为'ROUND(A.POWER,0)'构建分支网络
self.linear1_1 = paddle.nn.Linear(in_features=input_len*hidden_size, out_features=hidden_size*2)
self.linear1_2 = paddle.nn.Linear(in_features=hidden_size*2, out_features=hidden_size)
self.linear1_3 = paddle.nn.Linear(in_features=hidden_size, out_features=pred_len)
# 为'YD15'构建分支网络
self.linear2_1 = paddle.nn.Linear(in_features=input_len*hidden_size, out_features=hidden_size*2)
self.linear2_2 = paddle.nn.Linear(in_features=hidden_size*2, out_features=hidden_size)
self.linear2_3 = paddle.nn.Linear(in_features=hidden_size, out_features=pred_len)
self.dropout = paddle.nn.Dropout(dropout_rate)
def forward(self, x):
# x形状大小为[batch_size, input_len, feature_size]
# output形状大小为[batch_size, input_len, hidden_size]
# hidden形状大小为[num_layers, batch_size, hidden_size]
output, (hidden, cell) = self.lstm_layer(x)
# output: [batch_size, input_len, hidden_size] -> [batch_size, input_len*hidden_size]
output = paddle.reshape(output, [len(output), -1])
output1 = self.linear1_1(output)
output1 = self.dropout(output1)
output1 = self.linear1_2(output1)
output1 = self.dropout(output1)
output1 = self.linear1_3(output1)
output2 = self.linear2_1(output)
output2 = self.dropout(output2)
output2 = self.linear2_2(output2)
output2 = self.dropout(output2)
output2 = self.linear2_3(output2)
# outputs: ([batch_size, pre_len, 1], [batch_size, pre_len, 1])
return [output1, output2]模型训练、验证和测试代码:
def train(df, turbine_id):
# 设置数据集
train_dataset = TSDataset(df, input_len = input_len, pred_len = pred_len, data_type='train')
val_dataset = TSDataset(df, input_len = input_len, pred_len = pred_len, data_type='val')
test_dataset = TSDataset(df, input_len = input_len, pred_len = pred_len, data_type='test')
print(f'LEN | train_dataset:{len(train_dataset)}, val_dataset:{len(val_dataset)}, test_dataset:{len(test_dataset)}')
# 设置数据读取器
train_loader = paddle.io.DataLoader(train_dataset, shuffle=True, batch_size=batch_size, drop_last=True)
val_loader = paddle.io.DataLoader(val_dataset, shuffle=False, batch_size=batch_size, drop_last=True)
test_loader = paddle.io.DataLoader(test_dataset, shuffle=False, batch_size=1, drop_last=False)
# 设置模型
model = MultiTaskLSTM()
# 设置优化器
scheduler = paddle.optimizer.lr.ReduceOnPlateau(learning_rate=learning_rate, factor=0.5, patience=3, verbose=True)
opt = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
# 设置损失
mse_loss = MultiTaskMSELoss()
train_loss = []
valid_loss = []
train_epochs_loss = []
valid_epochs_loss = []
early_stopping = EarlyStopping(patience=patience, verbose=True, ckp_save_path=f'/home/aistudio/submission/model/model_checkpoint_windid_{turbine_id}.pdparams')
for epoch in tqdm(range(epoch_num)):
# =====================train============================
train_epoch_loss, train_epoch_mse1, train_epoch_mse2 = [], [], []
model.train() # 开启训练
for batch_id, data in enumerate(train_loader()):
x = data[0]
y = data[1]
# 预测
outputs = model(x)
# 计算损失
mse1, mse2, avg_loss = mse_loss(outputs, y)
# 反向传播
avg_loss.backward()
# 梯度下降
opt.step()
# 清空梯度
opt.clear_grad()
train_epoch_loss.append(avg_loss.numpy()[0])
train_loss.append(avg_loss.item())
train_epoch_mse1.append(mse1.item())
train_epoch_mse2.append(mse2.item())
train_epochs_loss.append(np.average(train_epoch_loss))
print("epoch={}/{} of train | loss={}, MSE of ROUND(A.POWER,0):{}, MSE of YD15:{} ".format(epoch, epoch_num,
np.average(train_epoch_loss), np.average(train_epoch_mse1), np.average(train_epoch_mse2)))
# =====================valid============================
model.eval() # 开启评估/预测
valid_epoch_loss, valid_epochs_mse1, valid_epochs_mse2 = [], [], []
for batch_id, data in enumerate(val_loader()):
x = data[0]
y = data[1]
outputs = model(x)
mse1, mse2, avg_loss = mse_loss(outputs, y)
valid_epoch_loss.append(avg_loss.numpy()[0])
valid_loss.append(avg_loss.numpy()[0])
valid_epochs_mse1.append(mse1.item())
valid_epochs_mse2.append(mse2.item())
valid_epochs_loss.append(np.average(valid_epoch_loss))
print('Valid: MSE of ROUND(A.POWER,0):{}, MSE of YD15:{}'.format(np.average(train_epoch_mse1), np.average(train_epoch_mse2)))
# ==================early stopping======================
early_stopping(valid_epochs_loss[-1], model=model)
if early_stopping.early_stop:
print(f"Early stopping at Epoch {epoch-patience}")
break
print('Train & Valid: ')
plt.figure(figsize=(12,3))
plt.subplot(121)
plt.plot(train_loss[:],label="train")
plt.title("train_loss")
plt.xlabel('iteration')
plt.subplot(122)
plt.plot(train_epochs_loss[1:],'-o',label="train")
plt.plot(valid_epochs_loss[1:],'-o',label="valid")
plt.title("epochs_loss")
plt.xlabel('epoch')
plt.legend()
plt.tight_layout()
plt.show()
# =====================test============================
# 加载最优epoch节点下的模型
model = MultiTaskLSTM()
model.set_state_dict(paddle.load(f'/home/aistudio/submission/model/model_checkpoint_windid_{turbine_id}.pdparams'))
model.eval() # 开启评估/预测
test_loss, test_epoch_mse1, test_epoch_mse2 = [], [], []
test_accs1, test_accs2 = [], []
for batch_id, data in tqdm(enumerate(test_loader())):
x = data[0]
y = data[1]
ts_y = [from_unix_time(x) for x in data[3].numpy().squeeze(0)]
outputs = model(x)
mse1, mse2, avg_loss = mse_loss(outputs, y)
acc1 = calc_acc(y.numpy().squeeze(0)[:,0], outputs[0].numpy().squeeze(0))
acc2 = calc_acc(y.numpy().squeeze(0)[:,1], outputs[1].numpy().squeeze(0))
test_loss.append(avg_loss.numpy()[0])
test_epoch_mse1.append(mse1.numpy()[0])
test_epoch_mse2.append(mse2.numpy()[0])
test_accs1.append(acc1)
test_accs2.append(acc2)
print('Test: ')
print('MSE of ROUND(A.POWER,0):{}, MSE of YD15:{}'.format(np.average(test_epoch_mse1), np.average(test_epoch_mse2)))
print('Mean MSE:', np.mean(test_loss))
print('ACC of ROUND(A.POWER,0):{}, ACC of YD15:{}'.format(np.average(test_accs1), np.average(test_accs2)))更多代码,详见:
-
龙源风电赛Baseline - 多任务LSTM深度网络模型 (Paddle)
https://aistudio.baidu.com/aistudio/projectdetail/5911966?contributionType=1&sUid=397884&shared=1&ts=1683175097635

提分技巧

挖掘风机间关联信息
虽然赛方没给出不同风机的地理位置,且不同风机的数据分布时间段不完全不一致,但可以从风场维度,联合多个风机开展数据分析,看是否能挖掘出风机之间的关联信息,以减少单风机的数据噪声、帮助填补缺失或处理异常等。
还有例如求功率/温度相关性,Kmeans 聚类获取风机 cluster,把近邻风机的特征们求均值加入特征,或者分 cluster 建模预测。
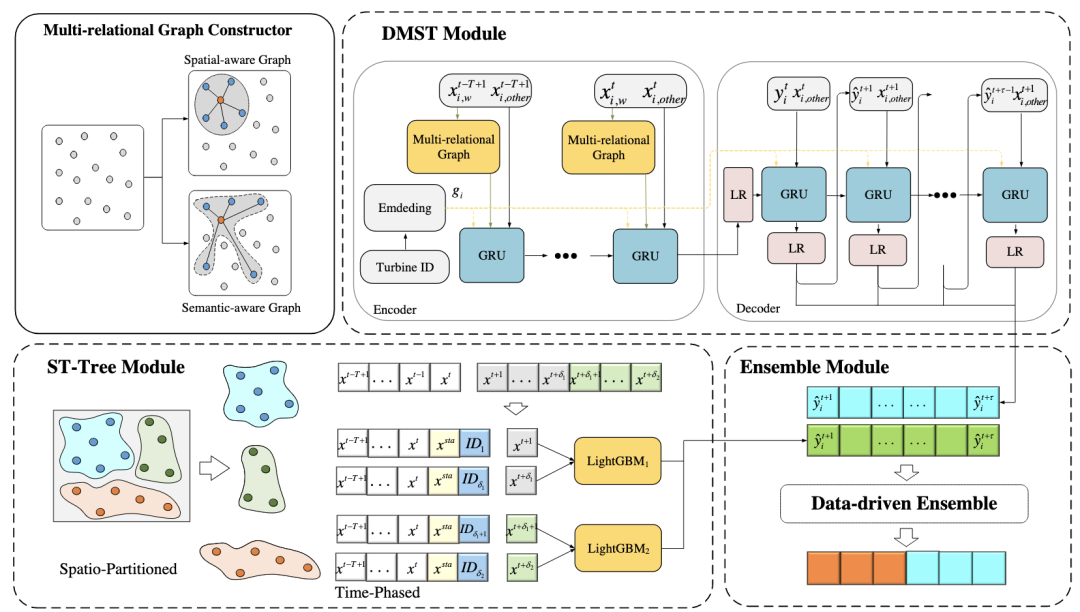
ST-Tree module:ST-Tree:Spatio-Partitioned Time-Phased Tree Model。它算每个风机之间的皮尔逊系数,再用 K-means 聚类,然后针对聚类的风机训练 LightGBM。
--KDD 第1名方案(海康)

-
在图网络表征上,选手是把与风机有 Top-K 高相关性的风机们,确认连接边,构建图关系。
-
用 k-shape 算法将风机聚类成39类,每类风机用一个 LightGBM 预测。
-
附属风机可被看做是一类风机们,它们之间有最相似的发电规律。通过平均附属风机的功率,当做特征加入模型,能缓解数据噪声。
--KDD 第4名方案(清华、浙江工商、多伦多大学)

分段建模预测
风机的发电功率预测难度是挺大的,模型一般偏好均值预测,所以我们要争取把可预测性强的短期预测部分预测好,再考虑如何提升模型的中长期预测能力。其实短期预测可以考虑递归预测,因为它强调时序前后依赖,对短期信息依赖程度会更高些,不足在于中后期会误差累积。所以在中长期则可以考虑多步生成式预测。
论文《DeepSpatio-TemporalWind Power Forecasting》反应到:
-
随着时间滞后项的增加,自相关系数迅速衰减,说明短期预测可能性更大,中长期就比较困难了。
-
随机抽取几个不同的风速时序,结果显示风速时序没有展示出极端的长期依赖。而且 GRU 用更少的参数反而避免了过拟合问题。
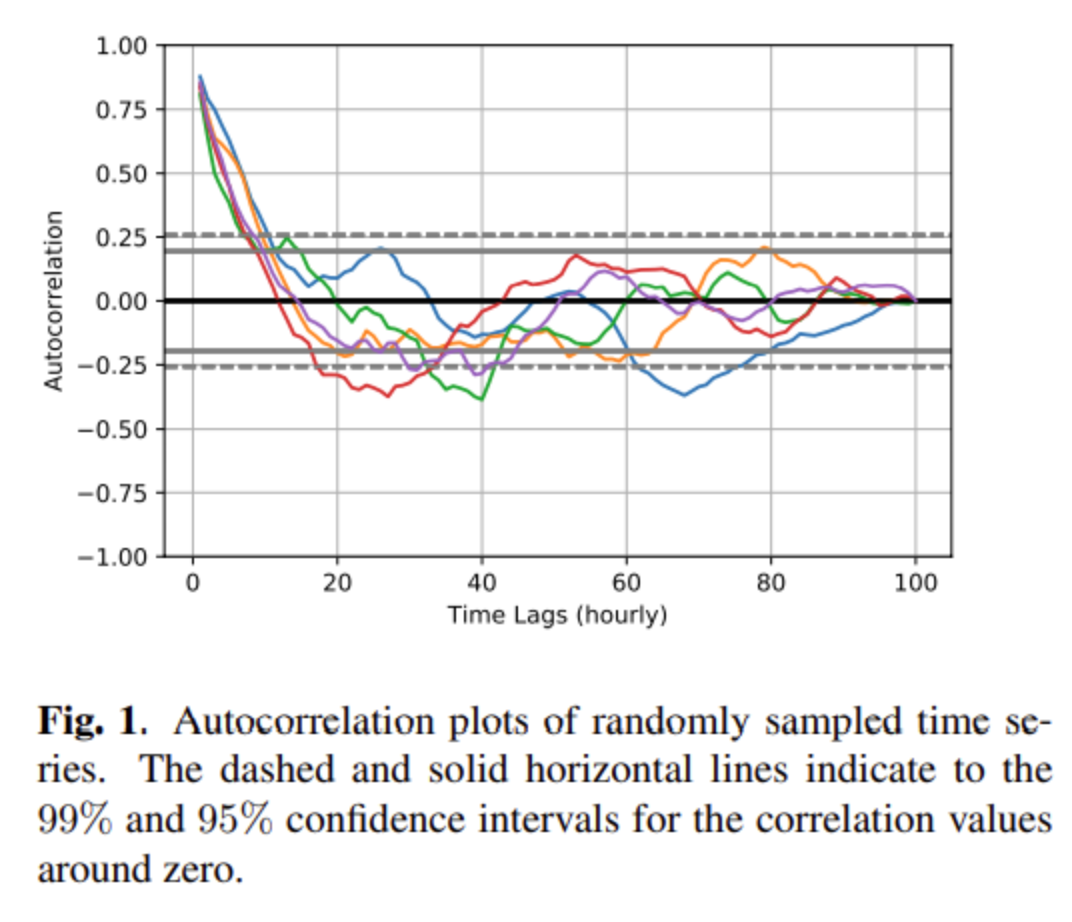
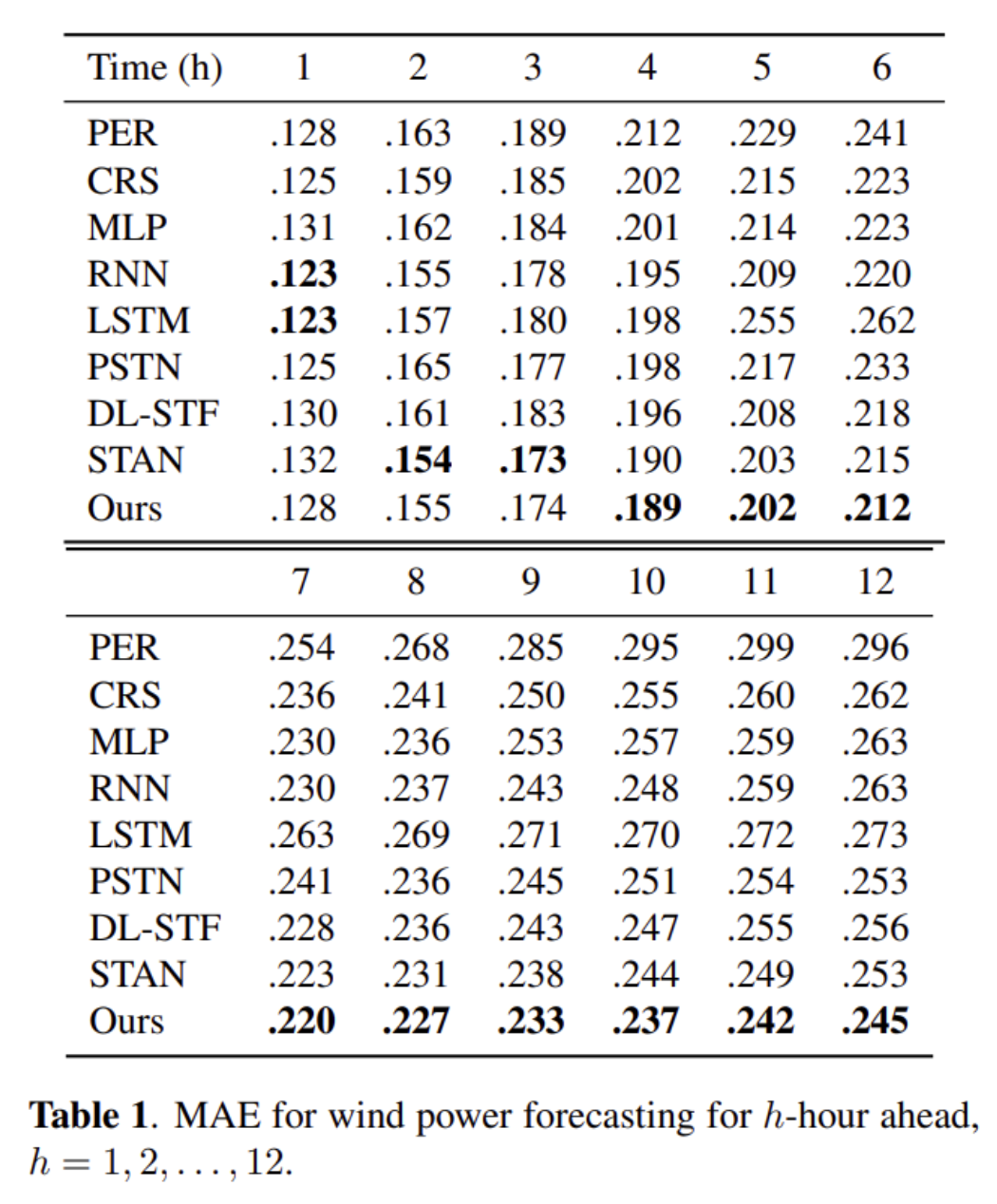
下图展示了头几个小时下的 MAE,也反映出相同的结论。所以风电功率预测时大多用户选择了分段建模预测。

其他
-
异常值处理,尤其是标签矫正: 例如风速过大但功率为0的异常,在特定风速下的离群功率等;
-
标签融合: 融合两个标签,以 YD15 为主,A.Power 为辅;
-
利用天气预报的数据: 加 decoder 部分加入即可;
-
挖掘更多特征: 差分序列、同时刻风场/邻近风机的特征均值/标准差等;
-
尝试树模型: XGB、LGB 等;
-
模型参数调优: optuna;
-
模型融合: 人工加权或配合寻参算法。
官方交流QQ群
QQ 搜索479266219,加入官方交流 QQ 群~