手写数字笔迹细化
对于手写数字识别实验中,经常会遇到因为笔迹较粗导致误识别的情况,所以我们通常会先将笔迹进行细化,笔迹变细以后,数字的特征会更明显,后续进行识别的准确率就会更高。
例如数字7 和 1 ,因为书写习惯的不同,在识别图像如果使用原始图像,笔迹较粗,经常会识别错误,但是经过腐蚀操作,笔迹变细以后,会很容易将二者区分开。

本期我们重点学习图像的腐蚀操作,通过图像腐蚀来将手写数字的笔迹进行细化。
完成本期内容,你可以
-
了解图像腐蚀的原理和应用
-
掌握使用图像腐蚀进行图像处理
若要运行案例代码,你需要有:
-
操作系统:Ubuntu 16 以上 或者 Windows10
-
工具软件:VScode 或者其他源码编辑器
-
硬件环境:无特殊要求
-
核心库:python 3.6.13, opencv-contrib-python 3.4.11.39,opencv-python 3.4.2.16
点击下载源码
腐蚀
OpenCV将腐蚀封装成了cv2.erode()方法。
函数原型:dst = cv2.erode(src, kernel, anchor, iterations, borderType, borderValue)
dst为输出图像。
参数描述如下:
- src:被处理的图像
- kernel:腐蚀使用的核
- anchor:可选参数,锚点的位置
- iterations:可选参数,腐蚀操作的迭代次数,默认值为1
- borderType:可选参数,边界样式,建议采用默认值
- borderValue:可选参数,边界值,建议采用默认值
具体步骤
1. 创建项目结构
创建项目名为手写数字笔迹细化,项目根目录下新建code文件夹储存代码,新建dataset文件夹储存数据,项目结构如下:
手写数字笔迹细化 # 项目名称
├── code # 储存代码文件
├── dataset # 储存数据文件
注:如项目结构已存在,无需再创建。
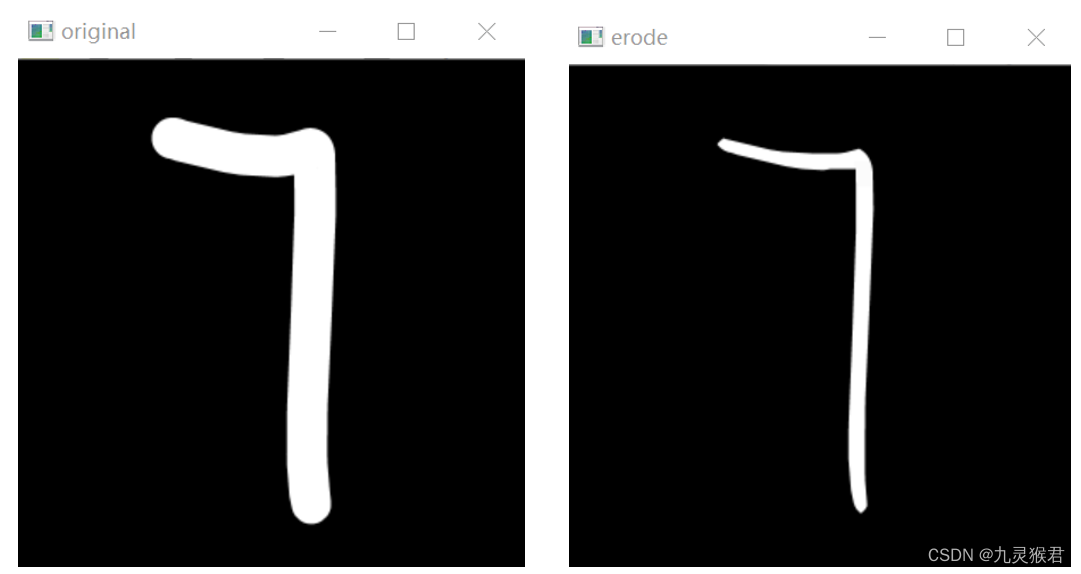
2. 使用腐蚀操作对数字 7 进行处理
- 在
code文件夹下创建number_7.py文件; - 导入所需的库,OpenCV、numpy;
- 读取
dataset文件夹下的7.png图片,并进行展示; - 创建一个
13*13的都为1 的数组作为滤波核; - 对图像进行腐蚀处理,并展示结果;
代码实现
# 导入OpenCV、numpy
import cv2
import numpy as np
# 读取图像
img = cv2.imread("../dataset/7.png")
cv2.imshow("original",img)
# 创建13*13的都为1的数组作为核
k = np.ones((13, 13), np.uint8)
# 进行腐蚀操作
dst = cv2.erode(img, k)
cv2.imshow("erode",dst)
cv2.waitKey()
cv2.destroyAllWindows()
3. 使用腐蚀操作对数字 1 进行处理
- 在
code文件夹下创建number_1.py文件; - 导入所需的库,OpenCV、numpy;
- 读取
dataset文件夹下的1.png图片,并进行展示; - 创建一个
13*13的都为1 的数组作为滤波核; - 对图像进行腐蚀处理,并展示结果;
代码实现
# 导入OpenCV、numpy
import cv2
import numpy as np
# 读取图像
img = cv2.imread("../dataset/1.png")
cv2.imshow("original",img)
# 创建13*13的都为1的数组作为核
k = np.ones((13, 13), np.uint8)
# 进行腐蚀操作
dst = cv2.erode(img, k)
cv2.imshow("erode",dst)
cv2.waitKey()
cv2.destroyAllWindows()
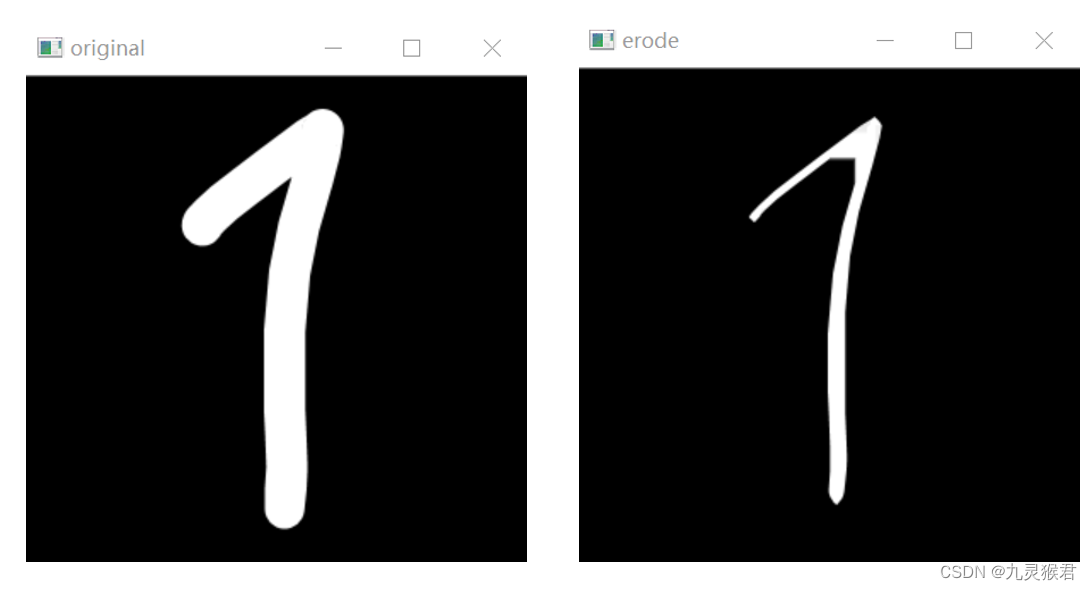
经过腐蚀操作之后,图像的笔迹明显变细,数字的结构特征也更为明显,更有助于后续的处理和识别。
点击下载源码