参考:
DRF 官方文档:
Serializers - Django REST framework中文站点
为什么要学DRF和什么是REST API | 大江狗的博客
上一章:
一、Django REST Framework (DRF)& RESTful 风格api_做测试的喵酱的博客-CSDN博客
下一章:
四、DRF序列化器create方法与update方法_做测试的喵酱的博客-CSDN博客
三、DRF关联表的序列化(通过主表,查询从表数据)_做测试的喵酱的博客-CSDN博客
目录
一、DRF框架介绍
1.1 介绍
1.2 安装与配置
二、演示数据准备
三、序列化器Serializer
3.1 序列化&反序列化
3.2 Python数据序列化
3.3 DRF中的序列化与反序列化
3.4 DRF框架中实现序列化
3.4.1 定义序列化器类
3.4.2 序列化器字段中常用的选项(数据校验)
四、接口设计实现增删改查
4.1 定义 视图类 class StudentsView(View): 实现:
4.2 定义 视图类 class StudentsDetailView(View): 实现:
4.3 创建路由
五、序列化
5.1 应用场景:
5.2 创建序列化器类
5.3 序列化器实现 get 查询所有数据的请求
5.4 读取单条数据,处理模型类的实例
六、反序列化
6.1 应用场景:
6.2 反序列化实现 post 创建单条数据的请求
6.2.1 获取接口请求json参数,并转化为字典
6.2.3 创建数据&数据校验
6.3 反序列化实现更新一条数据
6.4 实现删除一条数据
七、序列化器中自定义校验提示信息
一、DRF框架介绍
1.1 介绍
Django REST Framework (DRF)这个神器我们可以快速开发出优秀而且规范的Web API来。Django REST framework 给Django提供了用于构建Web API 的强大而灵活的工具包, 包括:
- 序列化器Serializer,可以高效的进行序列化与反序列化操作。
- 认证:多种身份认证
- 权限
- 分页
- 过滤
- 限流
- 可扩展,插件丰富
- 提供了极为丰富的类视图、Mixin扩展类、ViewSet视图集。
1.2 安装与配置
1、安装
pip install djangorestframework其他插件:(非必需)
pip install markdown2、注册应用
INSTALLED_APPS = [
'rest_framework',
]二、演示数据准备
1、创建子应用miaoschool,注册应用
2、创建2个模型类,班级模型类MiaoClass,学生信息模型类MiaoStudent
models.py
from django.db import models
# Create your models here.
class MiaoClass(models.Model):
id = models.AutoField(primary_key=True, verbose_name='id', help_text='id')
classname = models.CharField(max_length=20, verbose_name='班级名称', help_text='班级名称')
clasleader = models.CharField(max_length=10, verbose_name='班主任姓名', help_text='班主任姓名')
classcode = models.IntegerField(unique=True, verbose_name='班级code', help_text='班级code')
ifopens = models.BooleanField(default=True, verbose_name='是否开学', help_text='是否开学')
classrate = models.IntegerField( verbose_name='班费', help_text='班费')
class Meta:
# i.db_table指定创建的数据表名称
db_table = 'tb_class'
# 为当前数据表,设置中午呢描述
verbose_name = "班级表"
verbose_name_plural = "班级表"
class MiaoStudent(models.Model):
sname = models.CharField(max_length=20, verbose_name='学生姓名', help_text='学生姓名')
sgender = models.BooleanField(verbose_name='性别', help_text='性别')
sage = models.IntegerField(verbose_name='年龄', help_text='年龄')
sid = models.IntegerField(unique=True, verbose_name='学号', help_text='学号')
sscore = models.IntegerField( verbose_name='成绩', help_text='成绩')
classid = models.ForeignKey('miaoschool.MiaoClass',on_delete=models.CASCADE,verbose_name='班级id', help_text='班级id')
class Meta:
# i.db_table指定创建的数据表名称
db_table = 'tb_student'
# 为当前数据表,设置中午呢描述
verbose_name = "学生信息表"
verbose_name_plural = "学生信息表"
插入数据:
-- ----------------------------
-- Records of tb_class
-- ----------------------------
BEGIN;
INSERT INTO `tb_class` (`id`, `classname`, `clasleader`, `classcode`, `ifopens`, `classrate`) VALUES (1, '一班', '王老师', 1001, 1, 200);
INSERT INTO `tb_class` (`id`, `classname`, `clasleader`, `classcode`, `ifopens`, `classrate`) VALUES (2, '二班', '欧阳老师', 1006, 1, 300);
INSERT INTO `tb_class` (`id`, `classname`, `clasleader`, `classcode`, `ifopens`, `classrate`) VALUES (3, '三班', '东风老师', 1007, 1, 400);
INSERT INTO `tb_class` (`id`, `classname`, `clasleader`, `classcode`, `ifopens`, `classrate`) VALUES (4, '四班', '白腊图老师', 1011, 1, 20);
INSERT INTO `tb_class` (`id`, `classname`, `clasleader`, `classcode`, `ifopens`, `classrate`) VALUES (5, '五班', '张三丰老师老师', 1021, 1, 150);
COMMIT;-- ----------------------------
-- Records of tb_student
-- ----------------------------
BEGIN;
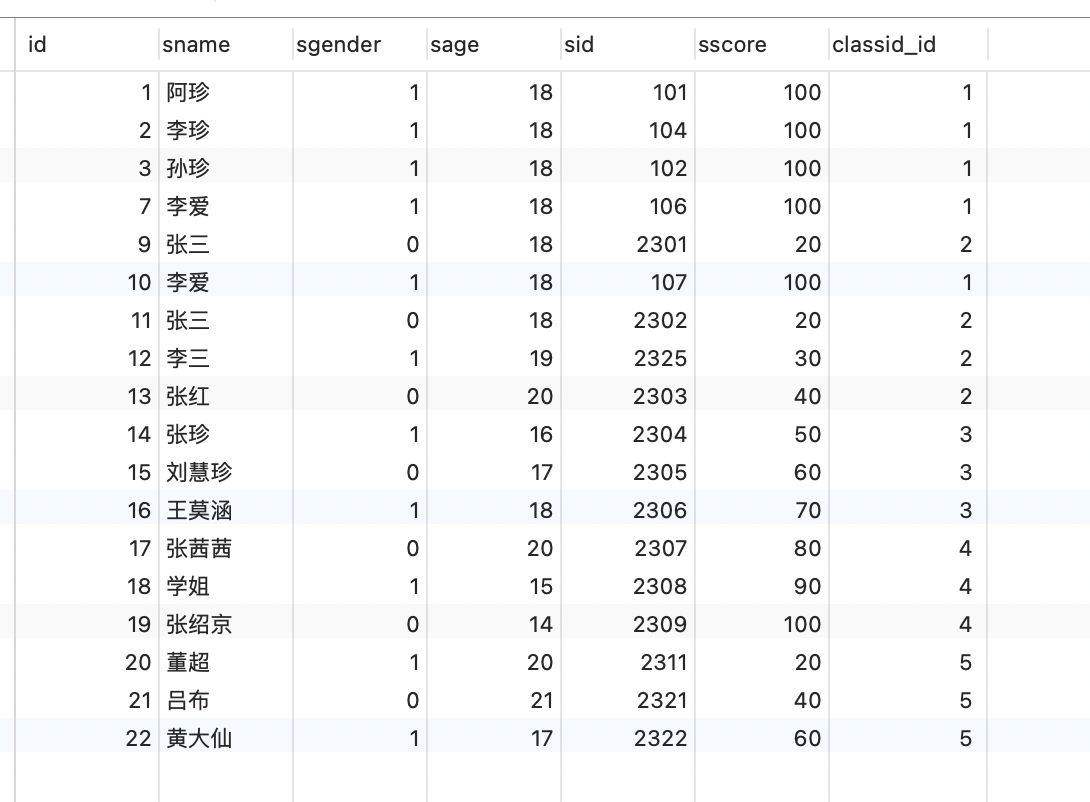
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (1, '阿珍', 1, 18, 101, 100, 1);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (2, '李珍', 1, 18, 104, 100, 1);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (3, '孙珍', 1, 18, 102, 100, 1);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (7, '李爱', 1, 18, 106, 100, 1);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (9, '张三', 0, 18, 2301, 20, 2);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (10, '李爱', 1, 18, 107, 100, 1);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (11, '张三', 0, 18, 2302, 20, 2);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (12, '李三', 1, 19, 2325, 30, 2);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (13, '张红', 0, 20, 2303, 40, 2);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (14, '张珍', 1, 16, 2304, 50, 3);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (15, '刘慧珍', 0, 17, 2305, 60, 3);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (16, '王莫涵', 1, 18, 2306, 70, 3);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (17, '张茜茜', 0, 20, 2307, 80, 4);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (18, '学姐', 1, 15, 2308, 90, 4);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (19, '张绍京', 0, 14, 2309, 100, 4);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (20, '董超', 1, 20, 2311, 20, 5);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (21, '吕布', 0, 21, 2321, 40, 5);
INSERT INTO `tb_student` (`id`, `sname`, `sgender`, `sage`, `sid`, `sscore`, `classid_id`) VALUES (22, '黄大仙', 1, 17, 2322, 60, 5);
COMMIT; 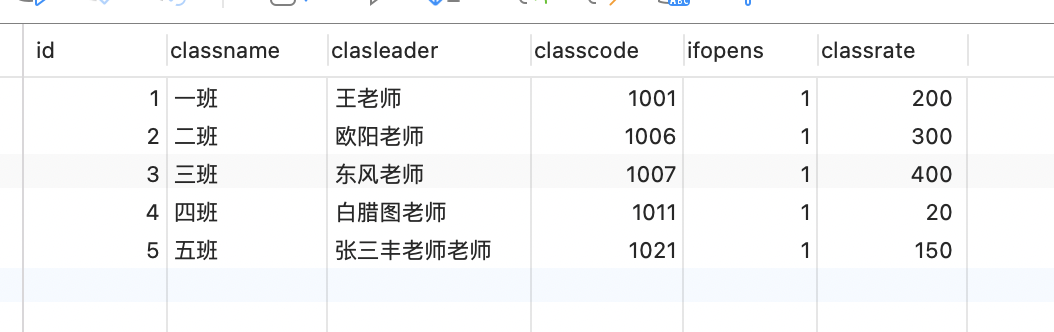
三、序列化器Serializer
3.1 序列化&反序列化
每种编程语言都有各自的数据类型, 将属于自己语言的数据类型或对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML、JSON或特定格式的字节串)的过程称为序列化(seralization);反之则称为反序列化。
API开发的本质就是各种后端语言的自己的数据类型序列化为通用的可读可传输的数据格式,比如常见的JSON类型数据。
3.2 Python数据序列化
举个简单例子。Python自带json模块的dumps方法可以将python常用数据格式(比如列表或字典)转化为json格式,如下所示。你注意到了吗? 生成的json格式数据外面都加了单引号,这说明dict类型数据已经转化成了json字符串。
>>> import json
>>> json.dumps({"name":"John", "score": 112})
'{"name": "John", "score": 112}'3.3 DRF中的序列化与反序列化
序列化: 将 查询集QuerySet (多个模型类的集合)与单个模型类的实例,通过序列化器转化为 json数据(字符串)。
反序列化:将json格式的字符串数据,通过序列化器转换为Django中的模型类的对象。
3.4 DRF框架中实现序列化
1、在应用中,创建一个名为 serializers.py 的文件。(推荐命名为serializers.py,其他命名也可以)
3.4.1 定义序列化器类
1、定义序列化器类,必须得继承Serializer类或者Serializer子类
from rest_framework import serializers
class StudentSerializer(serializers.Serializer):2、定义的序列化器类中,字段名要与模型类中的字段名保持一致。(字段个数可以不一致,但是字段名称一定要保持一致)
3、定义的序列化器类的字段(类属性)为Field子类
4、序列化器类中,定义了哪些字段,在序列化与反序列化中,只处理这些定义的字段,其他字段不处理。
5.常用的序列化器字段类型。
跟模型类差不多
| 数据类型 | Field类型 |
| int | IntegerField |
| str | CharField |
| bool | BooleanField |
| datetime | DateTimeField |
6、序列化器字段中常用的选项
a、 label和help_text,与模型类中的verbose_name和help_text参数一样
b、(用于数据校验) IntegerField,可以使用max_value指定最大值,min_value指定最小值
c、 (用于数据校验)CharField,可以使用max_length指定最大长度,min_length指定最小长度
d、定义的序列化器字段中,required模式为True,既在序列化或者反序列化中,都必须处理该字段。 如果想要设置某一个字段为非必填,required=False 就可以了
如:
clasleader = models.CharField(max_length=10, verbose_name='班主任姓名', help_text='班主任姓名',required=False)
3.4.2 序列化器字段中常用的选项(数据校验)
| 关键字名称 | 作用 |
| label和help_text | 与模型类中的verbose_name和help_text参数一样。做备注用的 |
| max_value | 指定最大值 |
| min_value | 指定最小值 |
| max_length | 指定最大长度 |
| min_length | 指定最小长度 |
| required=False | 设置某一个字段为非必填 |
| allow_null=True | 这个字段允许传null |
| write_only=True | (常用)只在反序列化的时候,处理该被装饰的字段 |
| read_only=True | (常用)只在序列化的时候,处理该被装饰的字段 |
| allow_blank=True | 允许该字符串字段的值为空(只有CharField才有这个关键词) |
| default=“xx" | 在序列化/反序列化时,如该字段没有传值,则使用xx默认值 |
format='%Y年%m月%d日 %H:%M:%S' | DateTimeField可以使用format参数指定格式化字符串。如 |
a、 label和help_text,与模型类中的verbose_name和help_text参数一样
b、(用于数据校验) IntegerField,可以使用max_value指定最大值,min_value指定最小值
c、 (用于数据校验)CharField,可以使用max_length指定最大长度,min_length指定最小长度
d、设置某一个字段为非必填,required=False 就可以了(好像有的版本没有这个关键字)
e、allow_null=True,这个字段允许传null
f、write_only=True(常用),只在反序列化的时候,处理该被装饰的字段。该字段只在反序列化输入的时候,做数据校验处理,在序列化输出的时候不做输出。write_only默认为False
举个例子:
用户注册账号的场景,注册成功后,会回显用户注册时的手机号等信息,但是不会回显密码。
将密码属性设置为write_only=True
password = models.CharField(max_length=10, verbose_name='班主任姓名', help_text='班主任姓名',write_only=True)用户输入的json格式的字符串数据,通过序列化器转换为Django中的模型类的对象(反序列化),对password进行校验。
但是将模型类通过序列化器转换为json数据时(序列化)不显示password数据。
g、read_only=True(常用),只在序列化的时候,处理该被装饰的字段。
创建班级时,会自动生成一个班级id。在用户输入的json格式的字符串数据,通过序列化器转换为Django中的模型类的对象(反序列化),不会对id进行校验。
创建成功后,要给用户回显生成的id。将模型类通过序列化器转换为json数据时(序列化)显示id数据。
四、接口设计实现增删改查
通过视图类,来实现增删改查的接口。
4.1 定义 视图类 class StudentsView(View): 实现:
1、get 查询所有数据的请求
GET /students/步骤:
- 数据库操作,(ORM),读取所有数据的实例
- 序列化输出,将查询集QuerySet 转换为json数据类型
2、post 创建单条数据的请求。
POST /students/ 新的学生数据以json的形式来传递步骤:
- 对用户输入的json数据进行校验(json转字典 )
- 反序列化操作,将字典格式的数据,转成序列化器的对象。
- 序列化器对数据校验
- 用序列化器的数据,去操作数据库,创建数据
- 数据回显,序列化输出操作。将模型对象转换为json数据
4.2 定义 视图类 class StudentsDetailView(View): 实现:
1、获取1条数据的接口,获取数据详情
GET /students/<int:pk>/步骤:
- 对用户传参做校验。校验pk(主键)的值是否存在数据
- ORM框架,读取一条数据
- 序列化输出,将模型类的实例,转化为json
2、更新1条数据的接口
PUT /students/<int:pk>/传参为json
步骤:
- 数据校验
- 反序列化操作,将json数据转化为序列化器的实例
- 数据库操作,更新数据
- 数据回显,序列化输出,将模型类转换为json数据
3、删除一条数据的接口
DELETE /studentss/<int:pk>/步骤:
- 数据校验
- 数据库操作,删除一条数据
4.3 创建路由
from miaoschool import views
urlpatterns = [
path('admin/', admin.site.urls),
path("students/",views.StudentsView.as_view()),
path('students/<int:pk>/',views.StudentsDetailView.as_view()),五、序列化
5.1 应用场景:
序列化:
将 从数据库中读取到的数据QuerySet实例,转换为 序列化器的实例
场景:
用户请求数据,从数据库取出数据,反给用户。ORM框架,从数据库中取的数据是QuerySet。
通过序列化将QuerySet 转化为序列化器的实例,再转化为josn数据返回给用户。
实现接口:
1、get 查询所有数据的请求
GET /students/2、获取1条数据的接口,获取数据详情
GET /students/<int:pk>/5.2 创建序列化器类
序列化器类,字段与模型类字段基本一致,用来做将模型类实例与json数据相互转换的中间件。
serializers.py
# -*- coding:utf-8 -*-
# @Author: 喵酱
# @time: 2023 - 05 -21
# @File: serializers.py
# desc: 序列化器
from rest_framework import serializers
class StudentSerializer(serializers.Serializer):
id = serializers.IntegerField(label='学生id', help_text='学生id', max_value=1000, min_value=1)
sname = serializers.CharField(label='学生姓名', help_text='学生姓名',max_length=10,min_length=1 )
sgender =serializers.BooleanField(label='学生性别', help_text='学生性别',)
sage = serializers.IntegerField(label='学生年龄', help_text='学生年龄',max_value=100, min_value=1)
sid = serializers.IntegerField(label='学生学号', help_text='学生学号',)
sscore = serializers.IntegerField(label='学生成绩', help_text='学生成绩', max_value=100, min_value=0)
# 注意,转换外键的值时,输入使用类属性名称来转化,接收到的是一个主表的实例对象
classid = serializers.CharField(label='班级id', help_text='班级id',)
# 注意,转换外键的值时,输入使用从表中外键的值来转化,接收到的是一个真正的数值
classid_id = serializers.IntegerField(label='班级id', help_text='班级id', max_value=10, min_value=1)
注意外键的处理:
# 注意,转换外键的值时,输入使用类属性名称来转化,接收到的是一个主表的实例对象
classid = serializers.CharField(label='班级id', help_text='班级id',)
# 注意,转换外键的值时,输入使用从表中外键的值来转化,接收到的是一个真正的数值
classid_id = serializers.IntegerField(label='班级id', help_text='班级id', max_value=10, min_value=1)
5.3 序列化器实现 get 查询所有数据的请求
一、视图函数的处理。
步骤:
- 数据库操作,(ORM),读取所有数据的实例
- 序列化输出,将查询集QuerySet 转换为json数据类型
class StudentsView(View):
# 查询所有数据
def get(self,request):
# 获取列表数据
queryset = MiaoStudent.objects.all()
print(queryset)
serializer = StudentSerializer(instance=queryset, many=True)
return JsonResponse(serializer.data, safe=False)注意:
1、 QuerySet 是多个模型类实例的集合。返回给用户的数据格式不是json,而是一个列表,每个元素是一个json。
2、处理QuerySet,一定要使用many=True
serializer = StudentSerializer(instance=queryset, many=True)3、将序列化对象实例,转化为json的列表。
serializer.data 是序列化后的数据
JsonResponse(serializer.data, safe=False)二、请求返回数据
[
{
"id": 1,
"sname": "阿珍",
"sgender": true,
"sage": 18,
"sid": 101,
"sscore": 100,
"classid": "MiaoClass object (1)",
"classid_id": 1
},
{
"id": 2,
"sname": "李珍",
"sgender": true,
"sage": 18,
"sid": 104,
"sscore": 100,
"classid": "MiaoClass object (1)",
"classid_id": 1
},
]5.4 读取单条数据,处理模型类的实例
获取1条数据的接口,获取数据详情
GET /students/<int:pk>/步骤:
- 对用户传参做校验。校验pk(主键)的值是否存在数据
- ORM框架,读取一条数据
- 序列化输出,将模型类的实例,转化为json
一、视图函数的处理。
class StudentsDetailView(View):
def get(self, request, pk):
# 1、需要校验pk在数据库中是否存在
# 2、从数据库中读取项目数据
try:
student_obj = MiaoStudent.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
serializer = StudentSerializer(instance=student_obj)
return JsonResponse(serializer.data)注意:
student_obj是一个模型类的实例。
将模型类的实例,序列化
serializer = StudentSerializer(instance=student_obj)serializer.data 是序列化后的数据
将序列化对象实例,转化为json的数据。
JsonResponse(serializer.data, safe=False)六、反序列化
6.1 应用场景:
用户传入json请求数据,先将用户传入的json 字符串,转为字典,再将这个字典反序列化转化为模型类的实例,然后再调用ORM框架,执行sql。
比如创建学生信息,用户输入一个json,然后将这个json生成一行表的数据。
实现接口:
1、post 创建单条数据的请求。
POST /students/ 新的学生数据以json的形式来传递2、更新1条数据的接口
PUT /students/<int:pk>/3、删除一条数据的接口
DELETE /studentss/<int:pk>/6.2 反序列化实现 post 创建单条数据的请求
post 创建单条数据的请求。
POST /students/ 新的学生数据以json的形式来传递步骤:
- 对用户输入的json数据进行校验(json转字典 )
- 反序列化操作,将字典格式的数据,转成序列化器的对象。
- 序列化器对数据校验
- 用序列化器的数据,去操作数据库,创建数据
- 数据回显,序列化输出操作。将模型对象转换为json数据
class StudentsView(View) 下的方法:
# 创建数据
def post(self, request):
# 1、获取json参数并转化为python中的数据类型(字典)
try:
dic_data = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 获取反序列化的实例对象
student_obj = StudentSerializer(data=dic_data)
# 对数据进行校验
# 校验不通过
if not student_obj.is_valid():
return JsonResponse(student_obj.errors, status=400)
# 创建数据,执行saql
student=MiaoStudent.objects.create(**student_obj.validated_data)
# 对创建的数据进行数据回显(序列化)
serializer = StudentSerializer(instance=student)
return JsonResponse(serializer.data, status=201)6.2.1 获取接口请求json参数,并转化为字典
1、获取接口请求json参数,并转化为字典。
我们手动对输入数据做一次简单的校验,是否能转成字典
def get_json(request):
try:
# 1、获取接口请求json参数,并转化为字典
data = json.loads(request.body)
except Exception as e:
return JsonResponse({"msg":"参数有误"},status=400)6.2.3 创建数据&数据校验
序列化器提供了数据校验功能。
定义序列化器类,使用data关键字参数传递字典参数。
1、序列化器类:
在创建序列化器类时,如
sscore = serializers.IntegerField(label='学生成绩', help_text='学生成绩', max_value=100, min_value=0)指定了sscore字段的校验规则,大于等于0,小于等于100。
sname = serializers.CharField(label='学生姓名', help_text='学生姓名',max_length=10,min_length=1 )指定了sname字段的校验规则,最少1个字符,最多10个字符。
2、调用校验功能:
序列化器对象调用.is_valid()方法,才会开始对前端输入的参数进行校验
# 获取反序列化的实例对象
student_obj=StudentSerializer(data=dic_data)调用校验方法
student_obj.is_valid()返回值为布尔类型,校验通过为True,校验失败为False。
3、获取校验失败的报错信息:
.只有在调用.is_valid()方法之后,才可以使用序列化器对象调用.errors属性,来获取错误提示信息(字典类型)
只有在调用
student_obj.is_valid()校验之后,才可以查看报错信息,不然报错。
查看报错信息
student_obj.errors4、在校验不通过时,直接抛出异常。
调用.is_valid()方法,添加raise_exeception=True,校验不通过会抛出异常。
student_obj.is_valid(raise_exeception=True)5、校验之后的数据.validated_data
student_obj.validated_data只有在调用.is_valid()方法之后,才可以使用序列化器对象调用.validated_data属性,来获取校验通过之后的数据。
.validated_data 数据与 使用json.load转化之后的数据有区别
6、整体代码:
# 创建数据
def post(self, request):
# 1、获取json参数并转化为python中的数据类型(字典)
try:
python_data = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 获取反序列化的实例对象
student_obj = StudentSerializer(data=data)
# 对数据进行校验
# 校验不通过
if not student_obj.is_valid():
return JsonResponse(student_obj.errors, status=400)
# 创建数据,执行saql
student=MiaoStudent.objects.create(**student_obj.validated_data)
# 对创建的数据进行数据回显(序列化)
serializer = StudentSerializer(instance=student)
return JsonResponse(serializer.data, status=201)7、功能演示
a、传入sscore大于100的数字
http://127.0.0.1:8000/students/
参数:
{
"sname":"浩轩",
"sgender":1,
"sage":17,
"sid":2046,
"sscore":101,
"id":26,
"classid_id":3
}返回结果:
{
"sscore": [
"Ensure this value is less than or equal to 100."
]
}b、传入ssname长度为11位字符
传参:
{
"sname":"浩哈哈哈哈哈哈哈哈哈哈哈哈哈哈轩",
"sgender":1,
"sage":17,
"sid":2046,
"sscore":101,
"id":26,
"classid_id":3
}返回结果:
{
"sname": [
"Ensure this field has no more than 10 characters."
],
"sscore": [
"Ensure this value is less than or equal to 100."
]
}疑问:
为啥我的提示是英文?明天查查。
c、正常创建数据

6.3 反序列化实现更新一条数据
更新1条数据的接口
PUT /students/<int:pk>/传参为json
步骤:
- 数据校验
- 反序列化操作,将json数据转化为序列化器的实例
- 数据库操作,更新数据
- 数据回显,序列化输出,将模型类转换为json数据
def put(self, request, pk):
# 1、需要校验pk在数据库中是否存在
# 2、从数据库中读取项目数据
try:
student_obj = MiaoStudent.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 3、获取json参数并转化为字典
try:
dic = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 4、序列化,将 用户输入的字典,转化为序列化实例
serializer_obj=StudentSerializer(data=dic)
# 5、序列化器对用户传入的参数进行校验
# is_valid() 数据校验
# serializer_obj.errors 校验后报错信息
if not serializer_obj.is_valid():
return JsonResponse(serializer_obj.errors, status=400)
# 6、更新数据,操作数据库
student_obj.sname = serializer_obj.validated_data.get('sname')
student_obj.sgender = serializer_obj.validated_data.get('sgender')
student_obj.sid = serializer_obj.validated_data.get('sid')
student_obj.sscore = serializer_obj.validated_data.get('sscore')
student_obj.classid_id = serializer_obj.validated_data.get('classid_id')
student_obj.save()
# 7、数据回显示(非必需的)。将读取的项目数据转化为字典
serializer = StudentSerializer(instance=student_obj)
return JsonResponse(serializer.data, status=201)
接口演示:
1、使用put请求
2、http://127.0.0.1:8000/students/1/
3、参数
{
"sname":"阿珍二号",
"sgender":1,
"sage":17,
"sid":101,
"sscore":100,
"id":26,
"classid_id":3
}
6.4 实现删除一条数据
删除一条数据的接口
DELETE /studentss/<int:pk>/步骤:
- 数据校验
- 数据库操作,删除一条数据
def delete(self, request, pk):
# 1、需要校验pk在数据库中是否存在
# 2、读取主键为pk的项目数据
try:
project_obj = MiaoStudent.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
# 3、执行删除
project_obj.delete()
return JsonResponse({'msg': '删除成功'}, status=204)七、序列化器中自定义校验提示信息
1、修改语言与时区
setting.py
简体中文
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'2、序列化器中自定义校验提示信息
sage = serializers.IntegerField(label='学生年龄', help_text='学生年龄',max_value=100, min_value=1,
error_messages = {
'max_value': '学生年龄不能超过100岁',
'min_value':'学生年龄不能小于1岁'
})通过关键字 error_messages = {} 实现
字典中,key为定义校验字段的值,value是自定义的提示。
八、数据其他类型的校验 validators=[]
validators=[]列表中,可以设置多种校验规则,如唯一约束校验,字符串内容校验
8.1 唯一约束校验
模版:
validators=[UniqueValidator(queryset=MiaoStudent.objects.all(),message='学生id不能重复')])1、validators=[] 在列表里面,设置多种校验规则
2、UniqueValidator 校验器,drf框架自带。
from rest_framework.validators import UniqueValidator3、UniqueValidator(queryset=MiaoStudent.objects.all(),message='学生id不能重复')
UniqueValidato:唯一约束校验
queryset=指定查询集(字段,在哪个查询集里面唯一校验)
message= 报错提示
8.1.1 例子:创建学生校验
序列化器类
class StudentSerializer(serializers.Serializer):
id = serializers.IntegerField(label='学生id', help_text='学生id', max_value=1000, min_value=1,
validators=[UniqueValidator(queryset=MiaoStudent.objects.all(),message='学生id不能重复')])
sname = serializers.CharField(label='学生姓名', help_text='学生姓名',max_length=10,min_length=1 )
sgender =serializers.BooleanField(label='学生性别', help_text='学生性别',)
sage = serializers.IntegerField(label='学生年龄', help_text='学生年龄',max_value=100, min_value=1,
error_messages = {
'max_value': '学生年龄不能超过100岁',
'min_value':'学生年龄不能小于1岁'
})
sid = serializers.IntegerField(label='学生学号', help_text='学生学号',)
sscore = serializers.IntegerField(label='学生成绩', help_text='学生成绩', max_value=100, min_value=0)
# 注意,转换外键的值时,输入使用类属性名称来转化,接收到的是一个主表的实例对象
# classid = serializers.CharField(label='班级id', help_text='班级id',)
# 注意,转换外键的值时,输入使用从表中外键的值来转化,接收到的是一个真正的数值
classid_id = serializers.IntegerField(label='班级id', help_text='班级id', max_value=10, min_value=1)接口请求:

8.1.2 例子:创建班级校验
class ClassSerializer(serializers.Serializer):
id = serializers.IntegerField(label='班级id', help_text='班级id')
classname = serializers.CharField(label='班级名称',
help_text='班级名称',
max_length=20,
min_length=2,
error_messages={
'max_length': '班级名称不能超过20个字',
'min_length': '班级名称不能小于2个字'
},
validators=[UniqueValidator(queryset=MiaoClass.objects.all(),message='班级名称不能重复')]
)
8.2 自定义校验规则函数
实现功能:
实现一个自定义校验规则的函数。在进行校验时,调用我们这个函数
8.2.1 自定义外部校验函数
1、定义校验方法
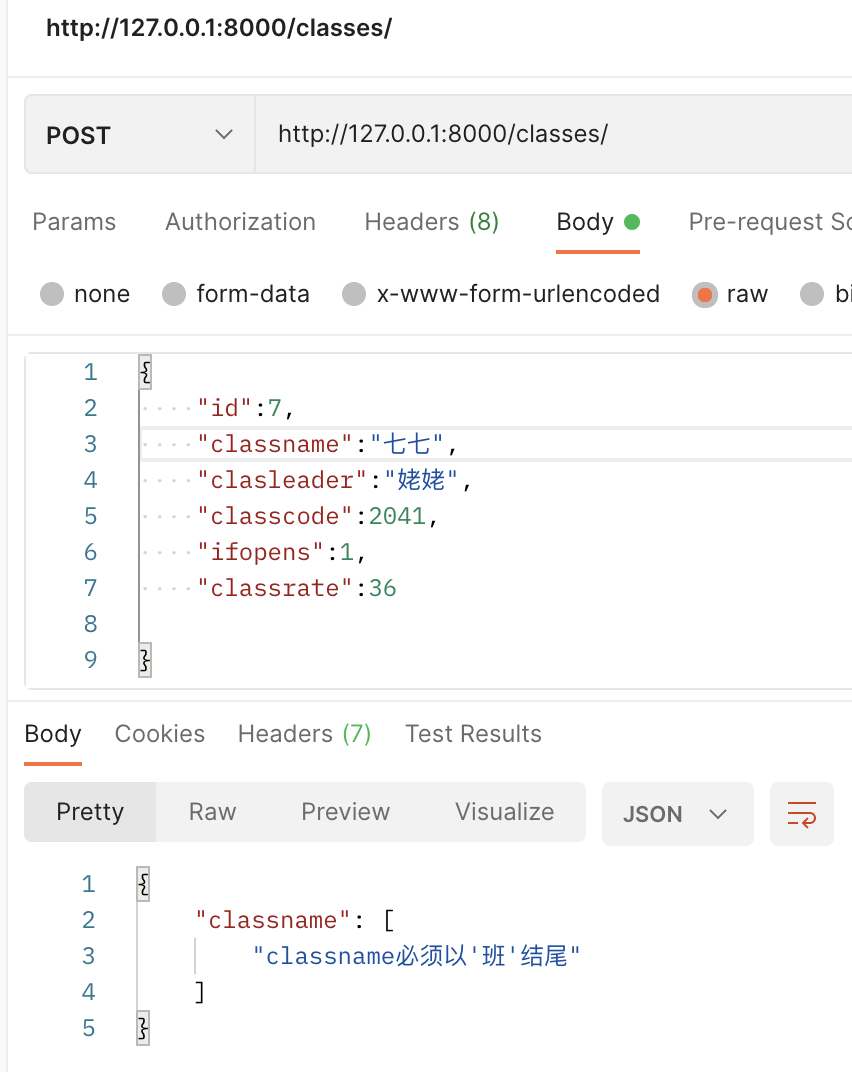
def check_class_name(classname:str):
if not classname.endswith("班"):
raise serializers.ValidationError("classname必须以'班'结尾")
注意:
- 必须抛出异常
- 没有要求return ture false
2、序列化器中,调用校验方法
在 validators=[check_class_name] 中,调用。注意函数名后没有小括号
class ClassSerializer(serializers.Serializer):
id = serializers.IntegerField(label='班级id', help_text='班级id')
classname = serializers.CharField(label='班级名称',
help_text='班级名称',
max_length=20,
min_length=2,
error_messages={
'max_length': '班级名称不能超过20个字',
'min_length': '班级名称不能小于2个字'
},
validators=[UniqueValidator(queryset=MiaoClass.objects.all(),message='班级名称不能重复'),
check_class_name]
)
8.2.2 自定义序列化器内部的校验函数
1、可以在序列化器类中对单个字段进行校验。在序列化器类中,定义校验方法函数
2、校验函数的命名:
- 必须以validate_开头
- 后面跟上字段名。与模型类的属性名称保持一致。
- 如果校验不通过,必须得返回serializers.ValidationError('具体报错信息')异常
- 如果校验通过,往往需要将校验之后的值,返回
- 如果该字段在定义时添加的校验规则不通过,那么是不会调用单字段的校验方法
对classname 字段的校验,定义函数如下:
def validate_classname(self, classname: str):
if not classname.endswith('班'):
raise serializers.ValidationError('班级名称,必须以班结尾')
return classname3、定义完函数,不需要手动调用。
class ClassSerializer(serializers.Serializer):
id = serializers.IntegerField(label='班级id', help_text='班级id')
classname = serializers.CharField(label='班级名称',
help_text='班级名称',
max_length=20,
min_length=2,
error_messages={
'max_length': '班级名称不能超过20个字',
'min_length': '班级名称不能小于2个字'
},
# validators=[UniqueValidator(queryset=MiaoClass.objects.all(),message='班级名称不能重复'),
# check_class_name],
validators=[UniqueValidator(queryset=MiaoClass.objects.all(), message='班级名称不能重复'),
]
)
clasleader = serializers.CharField(max_length=10, label='班主任姓名', help_text='班主任姓名')
classcode = serializers.IntegerField(label='班级code', help_text='班级code')
ifopens = serializers.BooleanField(label='是否开学', help_text='是否开学')
classrate = serializers.IntegerField(label='班费', help_text='班费')
# miaostudent_set = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id',read_only=True,many=True)
# sid = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id', read_only=True, many=True)
# sid = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id',
# queryset = MiaoStudent.objects.all(),
# write_only=True,
# many=True)
# sid = serializers.StringRelatedField(many=True)
# sid = serializers.SlugRelatedField(slug_field='sname',many=True,queryset=MiaoStudent.objects.all())
# sid = serializers.SlugRelatedField(slug_field='sname', many=True, read_only=True)
miaostudent_set = StudentINfoSerializer(read_only=True,many=True)
def validate_classname(self, classname: str):
if not classname.endswith('班'):
raise serializers.ValidationError('班级名称,必须以班结尾')
return classname九、多字段联合校验
# 1、可以在序列化器类中对多个字段进行联合校验
# 2、使用固定的validate方法,会接收上面校验通过之后的字典数据
# 3、当所有字段定义时添加的校验规则都通过,且每个字段的单字段校验方法通过的情况下,才会调用validate
def validate(self, attrs: dict):
if len(attrs.get('leader')) <= 4 or not attrs.get('is_execute'):
raise serializers.ValidationError('项目负责人名称长度不能少于4位或者is_execute参数为False')
return attrs
十、to_internal_value
def to_internal_value(self, data):
# 1、to_internal_value方法,是所有字段开始进行校验时入口方法(最先调用的方法)
# 2、会依次对序列化器类的各个序列化器字段进行校验:
# 对字段类型进行校验 -> 依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法
# to_internal_value调用结束 -> 调用多字段联合校验方法validate方法
tmp = super().to_internal_value(data)
# 对各个单字段校验结束之后的数据进行修改
return tmp十一、to_representation
def to_representation(self, instance):
# 1、to_representation方法,是所有字段开始进行序列化输出时的入口方法(最先调用的方法)
tmp =super().to_representation(instance)
return tmp十二、字段校验规则的顺序
字段校验,有多种方式,顺序是:
依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法-> 调用多字段联合校验方法validate方法