关键理论的理解,后面会补充结构等。
1.YOLO1中将图像划分为7*7个网格,每个网格都预测网格中的的类别(是什么物体),以及预测到的物体所对应的框(四个位置量,一个置信度),所以最后的特征图大小为7*7*2*(5+20),也就是7*7*30。抽象出的最后一层应该是S*S*B*(5+C),S*S代表了grid的数量,B为框的数量,C为预测的类别。后面的yolo也满足这个公式。
2.在yolo中,将损失函数分为了三个部分,后续yolo也一直延续这种损失。
a.位置损失(bounding box loss)也就是预测的框的损失(xywh四个位置量的损失)(使用平方差损失)
b.置信损失(IoU相关损失)是指网络预测的框中是否有目标,有目标的话IoU是多少(使用平方差损失)
c.类别损失(classification loss)是指预测框中检测到的物体分类是否正确(使用交叉熵损失)
3.在yolo1以后得版本中都使用了DarkNet(修改为ResNet结构)作为backbone,其实就是conv加BN这种结构
4.加入了anchor 思想,使用k-means聚类获得一些anchor来作为先验框来预测框,简单来说就是在特征图上根据gt生成框的时候不在是胡乱生成以及人为设定,而是有一些规律(聚类结果)。
5.预测框生成:限制生成的框在grid(0-1)之内,后面改进为在grid的框以及两个相邻的框(-0.5,1.5)之间,这样生成的正样本就更准确且数量更多。
6.切片/Focus模块:每隔一个像素拿出一个特征值,然后把新的特征图进行通道维度的concat来增加特性的信息量,不丢失信息。大小变为1/2,数量变为*4.
7.金字塔池化(SPP和SPPF):通过金字塔池化,让输入图像的大小可以改变。
spp通过池化将不同尺寸的输入统一为统一尺寸。
sppf是将并联结构修改为串联结构,这样参数量就更小了,训练会更快,并且增加了非线性。1个9*9相当于两个5*5.类似于一个5*5=2个3*3.

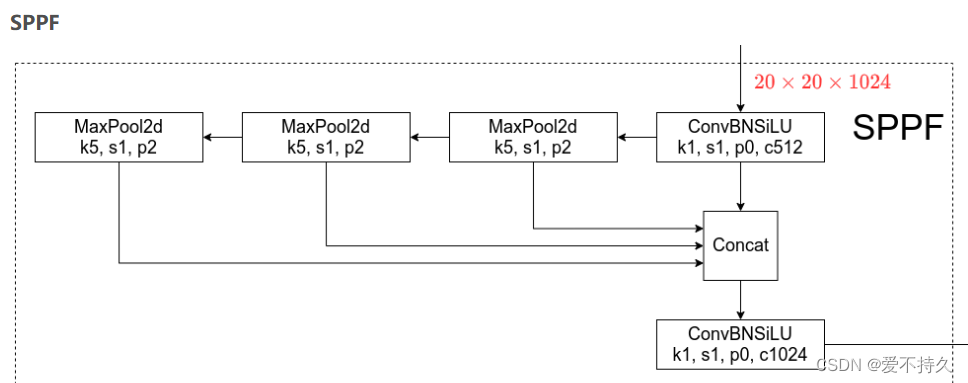
8.特征拼接:将不同维度的特征进行融合(concat),提升网络的效果。
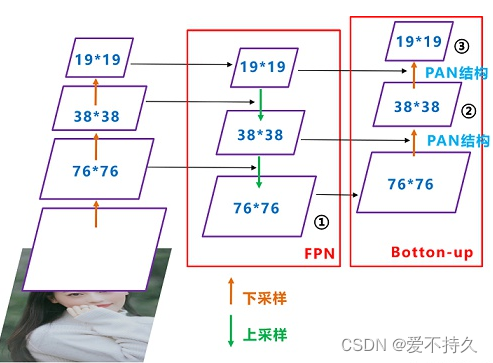
9.多尺度预测:单尺度预测对于较小的目标检测效果不好,所以多尺度预测,用较大的感受野来预测大物体(比如13*13的特征图),用26826来预测中等的物体,52*52的来预测小物体,并且在这些层之间进行拼接,增加特征量,提升预测的效果。不同网络中的使用尺寸略有不同。

10.现在的网络通常会分为三个部分:backbone(特征提取)、neck(特征融合)、head(完成用特征进行预测等任务)
11.PAN通道融合:分为两个部分:a. FPN(高层往低层融合,也就是深层往浅层融合),传递的是强语义信息。 b. 低层往高层融合,传递的是强定位信息。融合使用的是concat方法,不再是简单的add。
11.使用了CSP结构:也就是把一个特征图分为两个部分一个部分进行多次卷积操作,一部分只进行一次操作,然后再将两个部分concat。可以提速、减少内存占用、提升网络学习能力。类似下图,不同版本之间的具体的操作会有些许不同,但是就这么个思想。

12.数据增强: