Spark 3 AQE (Adaptive Query Execution)

序
在搭建平台的过程中,我们使用 CDH 6.3.2 进行搭建,但 CDH 中阉割掉了 spark-sql 功能,所以我们外挂了 Spark 3,补充 spark-sql 功能,版本为 3.3。在使用的过程中,查看 sql 执行图,发现了一个以前没有发现的 AQE 功能。所以今天我们就来聊一聊关于 AQE 这个 Spark 新特性(Hadoop3 也采用了这一个思路)。
AQE Adaptive Query Execution 原理 代码 讲解
AQE 面对的场景
在我们大型分布式计算框架中,遇到问题最多的就是对是否 shuffle、切块切片、谓词没有下推、数据量倾斜、小文件等等问题。而产生这些问题的根本在于解析 sql 时就已经决定了整个任务的执行规划,但没有考虑到真实的数据场景。因为开发人员也不可能每次都去实地考察每一次运行的 sql 环境,并且做出对应的参数调整。
比如以下一些任务场景:
数据分区不均衡
某类数据白天数据量很大,晚上数据量很小,白天每个文件可能都很大,但晚上的文件很小。如果我们配置了调度运行这个任务,那么可能我们的 spark.sql.shuffle.partition 是固定的,这样就决定了我们 reduce 任务的数量。那么造成白天 reduce 数量少,造成 OOM;而晚上的 reduce 数量又多,造成小文件的产生。
执行计划总是不最优的
一般我们的 CBO 是通过 Hive Metastore 的记录来进行优化策略调整,但这种策略也是静态策略,一旦开始执行就无法进行更改。
比如:一张大表 A join 一张大表 B,但其实表 B 经过过滤后,是可以 broadcast 进行关联的,但还是只能停留使用 sort merge join,造成大量的 shuffle,降低了查询性能。
热点 Key 问题
总有一些 top 流量是远远超过其他的,所以如果我们恰好使用这些热点 Key 来进行一些排序、分区,那么 shuffle 就会使得某一个节点造成数据倾斜。
一般对于这种,我们可能会考虑手动过滤,或者 加盐 处理,但并不是所有的 Key 我们都可以手动处理的。
AQE 是什么
上述的问题,其实都是关于真实运行数据时遇到的问题,而处理这些问题,大多数并不能在提交任务之前进行优化,而是基于运行过程中,产生的数据进行优化。所以, Spark 社区在 DAGScheduler 中,新增了一个 API 在支持提交单个 map 阶段,以及在运行时修改 shuffle 分区数等等,而这些就是 AQE。
在 spark 运行时,每当一个 shuffle map 阶段进行完毕,AQE 就会统计这个阶段的信息,并且基于规则进行动态调整并修正还未执行的任务逻辑计算与物理计划(在条件运行的情况下),使得 spark 程序在接下来的运行过程中得到优化。
所以,和 CBO 不同, AQE 是通过 shuffle map 中间阶段的输出文件信息进行调整。
在运行 spark 程序时,每个 Map Task 都会产出很多以 data 为后缀的数据文件,和以 index 结尾的索引文件。每个 data 的文件大小、空文件数量与占比、每个 reduce task 对应分区大小。A QE 就获取这些来进行相关优化。
与 RBO 也不同,RBO 是根据 sql 表象来进行一些经验主义的优化,如谓词下推,列剪枝等等。
后面会讲到 AQE 也会有谓词下推的优化,但一个是根据 SQL 表象(通过 sql 即可获取到的信息),一个是根据实际数据情况需要(需要部分运算后才能得到的信息)。
AQE 配置
在配置中,开启参数 spark.sql.adaptive.enabled=true,在 spark3.3 实际使用中,已经是默认开启(但 spark3.0 是 false)。
原始 Spark sql 解析以及任务提交流程
下图是描述 spark sql 的内部结构,一般来说物理计划是解析 sql 得到。
包含目录解析,基于规则的常量折叠、谓词和计算下推,转换为多个 spark 算子(一般会有多个,然后选择成本最低的)等基础优化。
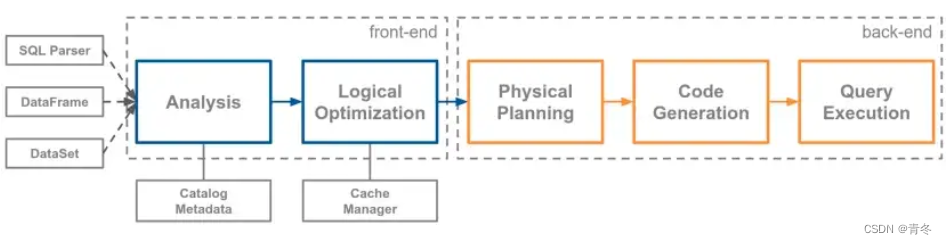
比如这个 SQL 的解析:
select a1, avg(b1)
from A
join B on A.pk = B.pk
where b1 <= 10000
group by a1
;
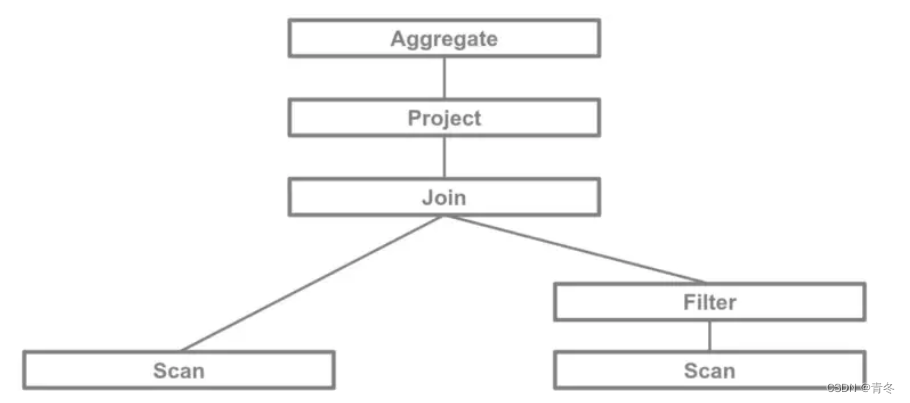
获取将 A 表和 B 表的 pk 进行关联,并且 B 表有一个筛选,A 表字段聚合。那么他的 SQL 逻辑计划如:
观察该图应该从叶节点到根节点(倒过来看),只有当下层执行完毕才会执行上层任务。
那么我们还需要将逻辑计划转变为物理计划,比如 join 操作就可能是多种中的一种:
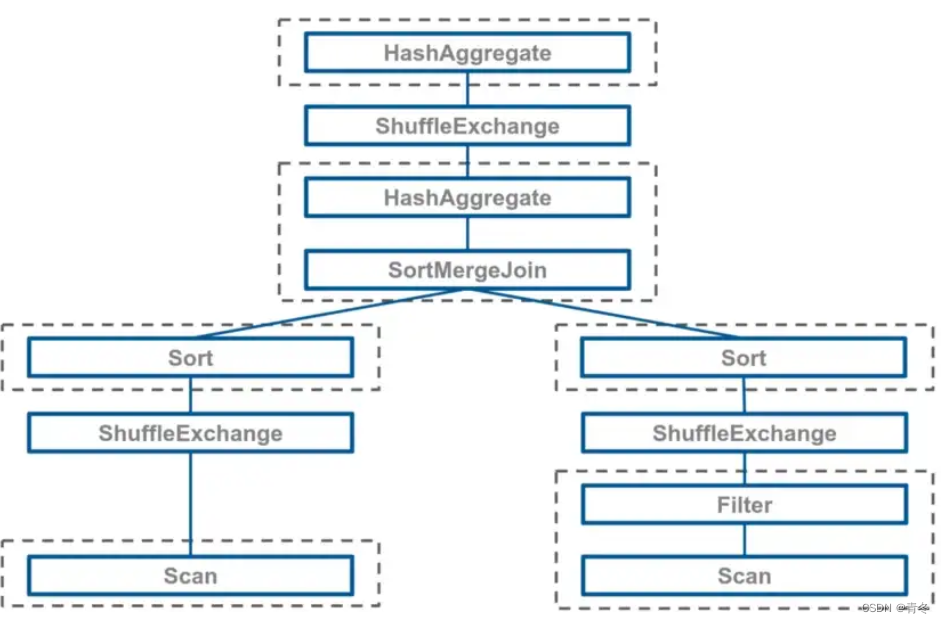
当物理计划一旦确定,那么在运行时就不能够更改,这里选择 SortMergeJoin 就是可能因为 A 表和 B 表都是很大的表(但可能其实过滤条件将大表已经化小了,如前面提到的场景 2)。物理计划确定后,就会形成 DAG 图,使用 RDD 进行计算,并且有对应的依赖关系(宽窄依赖)。最后会提交给 DAGScheduler 进行分解,然后传递 TaskSet 在 TaskScheduler 负责的物理资源上执行。
AQE 基于任务统计信息进行任务修订
在没有 AQE 时,spark 会在确定了物理执行计划之后,根据每个算子定义生成 RDD 以及对应的 DAG,然后 spark DAGScheduler 通过 shuffle 来划分 RDD Graph,并以此创建每个 stage,以及挨个执行 stage。
在开启 AQE 时,会将逻辑计划拆分为 QueryStage 独立的子图,更早的拆分 Stage。通过单独提交 mapStage(与 Stage 不同),收集它们的 MapOutputStatistics 对象。
在 AQE 的 plan 中,定义了两种类型的 QueryStage:
-
Shuffle query stages
将输出物化为 Shuffle 文件。
-
Broadcast query stages
将输出物化到 Driver 内存中的数组。
所以如果要支持这个新特性,必须依靠上面的 DAGScheduler 单个提交任务。
AQE 是会包含物理和执行计划的修改。
物理规划调整
Spark 会找到 Exchange,并引入两个新的操作节点。
- QueryStage 是一个阶段的根节点,负责运行时决策。
- QueryStageInput 是一个 stage 的叶节点,主要目的是在物理计划更新后,将子 stage 的结果提供给他的父亲。
下图黄色部分就是新引入的两个操作节点:
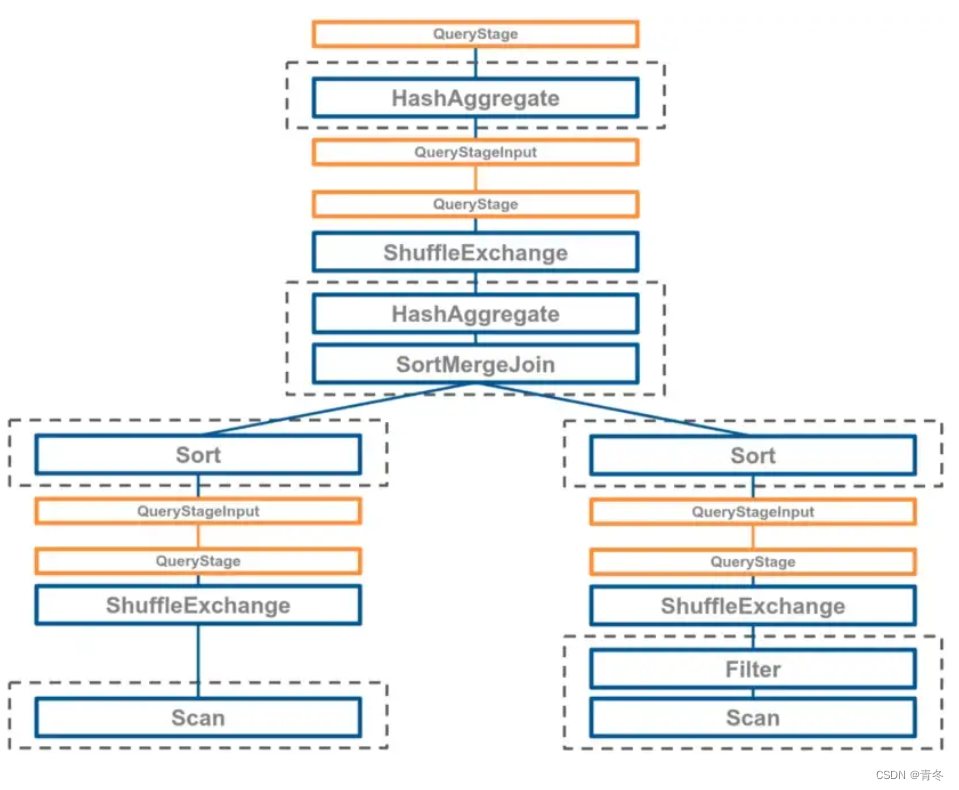
执行阶段调整
可以看到树上任何 QueryStage 都对其子阶段部分的引用,并递归的执行它们。在 QueryStage 的所有子级都完成后,运行时随机写入统计信息将被收集,并用于进一步优化。spark 会重启逻辑优化和物理规划阶段,并再次根据这些新信息动态更新查询计划。
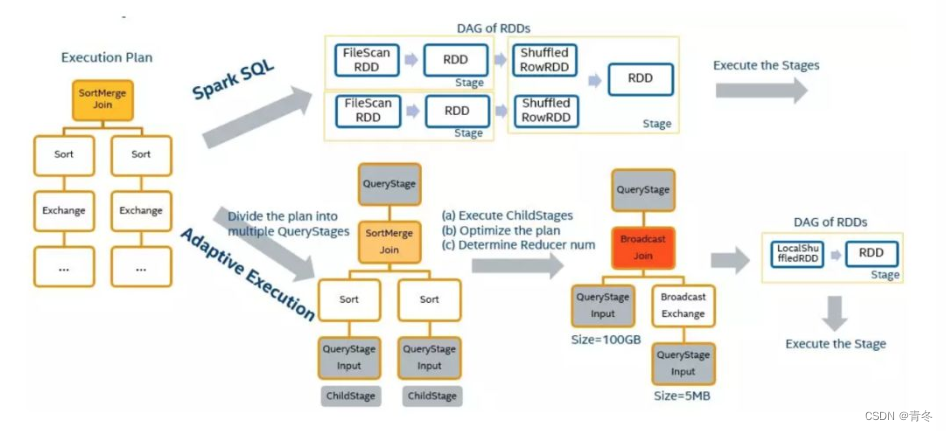
可以看到,在 AQE 情况下,会将 plan 树拆分为多个 QueryStages,在执行时会将子 QueryStages 进行提交,在所有的子节点完成后,收集 shuffle 中间数据信息,然后调整当前的执行计划,继续执行。(图中也是 AB 两表 join,在筛选后发现 B 表数据量下降 BroadcastJoin 代价比 SortMergeJoin 更小,所以进行了替换)
AQE 功能
动态合并分区
在 Shuffle 过后,Reduce Task 数据分布参差不齐,AQE 将自动合并过小的数据分区。在 Reduce 阶段,当 Reduce Task 把数据分片从 map 端拉回,AQE 按照分区编号的顺序,依次把小于目标尺寸的分区合并在一起。
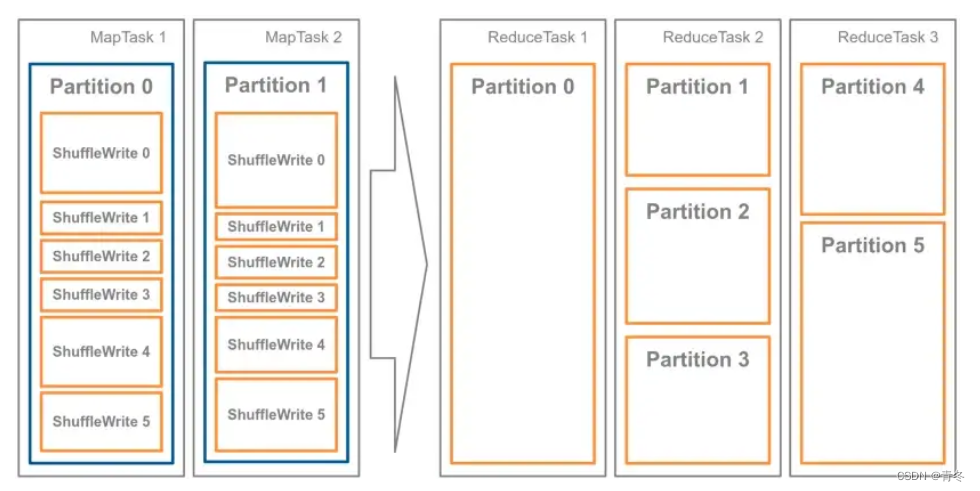
比如我们有 5 个 partition(shuffle 分区为 5),每个 reducer 尽量希望自己都处理 64MB。在 map 阶段的结果 Parittion 1/2/3 都太小了,在尽量不拆分分区的情况下,让每个 post-shuffle 分区的大小小于目标大小,确定使用 3 个 reducer 就可以达到平衡。
在合并分区时,会依次将 shuffle 分区打包到单个 coalesced 分区,直到添加另一个 shuffle 分区会导致 coalesced 分区的大小大于目标大小。
此外,在 AQE 中,每个 QueryStage 都知道它的所有子阶段结果数据情况,这使得可以很好地处理 3 个以上的表 join,避免引入更多的 shuffle。
自动合并分区大小参数:
- spark.sql.adaptive.coalescePartitions.enabled
开启动态合并分区;default true;3.0.0
- spark.sql.adaptive.advisoryPartitionSizeInBytes
合并分区的期望目标大小; default 64MB; 3.0.0;
- spark.sql.adaptive.coalescePartitions.minPartitionSize
合并后随机分区的最小大小; default 1 MB; 3.2.0; 最多为 spark.sql.adaptive.advisoryPartitionSizeInBytes 的 20%
- spark.sql.adaptive.coalescePartitions.initialPartitionNum
初始化的分区数; default spark.sql.shuffle.partitions; 3.0.0;
其他参数请移步 https://spark.apache.org/docs/latest/sql-performance-tuning.html
在 spark3.3.2 源码(注意 targetSize 的计算方式 org.apache.spark.sql.execution.adaptive.ShufflePartitionsUtil#coalescePartitions):
// org.apache.spark.sql.execution.adaptive.ShufflePartitionsUtil#coalescePartitions
def coalescePartitions(
mapOutputStatistics: Seq[Option[MapOutputStatistics]],
inputPartitionSpecs: Seq[Option[Seq[ShufflePartitionSpec]]],
advisoryTargetSize: Long,
minNumPartitions: Int,
minPartitionSize: Long): Seq[Seq[ShufflePartitionSpec]] = {
<em>assert</em>(mapOutputStatistics.length == inputPartitionSpecs.length)
if (mapOutputStatistics.isEmpty) {
return <em>Seq</em>.empty
}
// If `minNumPartitions` is very large, it is possible that we need to use a value less than
// `advisoryTargetSize` as the target size of a coalesced task.
val totalPostShuffleInputSize = mapOutputStatistics.flatMap(_.map(_.bytesByPartitionId.sum)).sum
val maxTargetSize = math.<em>ceil</em>(totalPostShuffleInputSize / minNumPartitions.toDouble).toLong
// It's meaningless to make target size smaller than minPartitionSize.
val targetSize = maxTargetSize.min(advisoryTargetSize).max(minPartitionSize)
val shuffleIds = mapOutputStatistics.flatMap(_.map(_.shuffleId)).mkString(", ")
logInfo(s"For shuffle(<strong>$</strong>shuffleIds), advisory target size: <strong>$</strong>advisoryTargetSize, " +
s"actual target size <strong>$</strong>targetSize, minimum partition size: <strong>$</strong>minPartitionSize")
// If `inputPartitionSpecs` are all empty, it means skew join optimization is not applied.
if (inputPartitionSpecs.forall(_.isEmpty)) {
<em>coalescePartitionsWithoutSkew</em>(
mapOutputStatistics, targetSize, minPartitionSize)
} else {
<em>coalescePartitionsWithSkew</em>(
mapOutputStatistics, inputPartitionSpecs, targetSize, minPartitionSize)
}
m a x T a r g e t S i z e = 总 输 入 数 据 / 最 小 分 区 数 maxTargetSize=总输入数据/最小分区数 maxTargetSize=总输入数据/最小分区数
t
a
r
g
e
t
S
i
z
e
=
m
a
x
(
m
i
n
(
m
a
x
T
a
r
g
e
t
S
i
z
e
,
期
望
目
标
大
小
)
,
分
区
最
小
大
小
)
targetSize=max(min(maxTargetSize, 期望目标大小), 分区最小大小)
targetSize=max(min(maxTargetSize,期望目标大小),分区最小大小)
$$
期望和分区最小大小就是上面的两个参数。
Join 动态策略调整
在 AQE 我们能够获取到 shuffle 输入的统计信息,可以为当前的 QueryStage Plan 提供更好的建议优化。如果一个 join 表实际需要 shuffle 的大小小于阈值时,那么就可以将 SortMegeJoin 替换为 BroadcastHashJoin,以获得更好的性能。
其实在 spark2.X 也有相关的优化,但必须在产生物理执行图之前决定,所以常规操作可能是开发人员手动 cache table ,并且调整阈值。当然这种情况下,很难精确到最佳。
这里有两个优化规则,一个逻辑策略,一个物理策略:DemoteBroadcastHashJoin 和 OptimizeLocalShuffleReader。
DemoteBroadcastHashJoin
参考
https://www.waitingforcode.com/apache-spark-sql/whats-new-apache-spark-3-demote-broadcast-hash-join/read
DemoteBroadcastHashJoin 规则的作用,是把 ShuffleSortMergeJoin 降级为 Broadcast Join。对于参与 Join 的两张表来说,在它们分别完成 Shuffle Map 阶段的计算之后,DemoteBroadcastHashJoin 会判断中间文件是否满足如下条件:
-
spark.sql.autoBroadcastJoinThreshold
参与 join 的数据大小小于多少能降级为
Broadcast Join; default 10485760 (10 MB);1.1.0;一般建议可以到50MB -
spark.sql.adaptive.autoBroadcastJoinThreshold
同上,但在adaptive中…; default (none); 3.2.0; 这个参数应该默认与上者相等(建议一起修改)。
-
spark.sql.adaptive.localShuffleReader.enabled
是否开启上者的条件; default true;;建议开启
但是,这里有一个问题,我们之所以想进行降级,其实是为了避免 shuffle 带来的网络和磁盘IO资源的负担。但如果我们想获取信息,又必须 shuffle 后才知道是否切换到 BroadcastJoin,这样的话整个步骤已经没有了任何意义。
所以,我们还需要 OptimizeLocalShuffleReader 物理策略。
OptimizeLocalShuffleReader
虽然大表完成了 sort + shuffle Map 的计算,但我们可以省去 shuffle 中的网络分发,让Reduce Task 就地获取本地节点的中间文件,进行广播小表的关联操作。
所以上面参数名才叫 spark.sql.adaptive.localShuffleReader.enabled
但还是 sort + shuffle Map 了啊,这部分计算其实是窄依赖,计算还好,而且后续关联,也比随机关联会快很多(有序关联了),所以代价不算很大。
spark3.3:
org.apache.spark.sql.execution.adaptive.OptimizeShuffleWithLocalRead
数据倾斜动态优化
上面场景C也说过,如果涉及到部分key倾斜,那么会造成数据倾斜的问题。一般我们会筛选、过滤、加盐重聚合等等方式处理。但现在有了AQE以后,我们可以轻松一点,通过执行的 QueryStages 后,收集每个 shuffle 数据大小和记录数。
如果某一个数据大小比中位数大F倍,那么就会被判断为倾斜分区,连接未倾斜连接,这时候就会利用OptimizeSkewedJoin策略,将大分区拆分为N个小分区。
有些博客有些记录数也会判断倾斜,但并未找到;如果找到了会加回来。
提一句,很多别的博客写的参数,我都没能在spark手册中找到,3.0.0~3.3.1。
具体判断倾斜分区:
- 分区大小大于MaxSize,并且分区大小大于中位数的F倍。
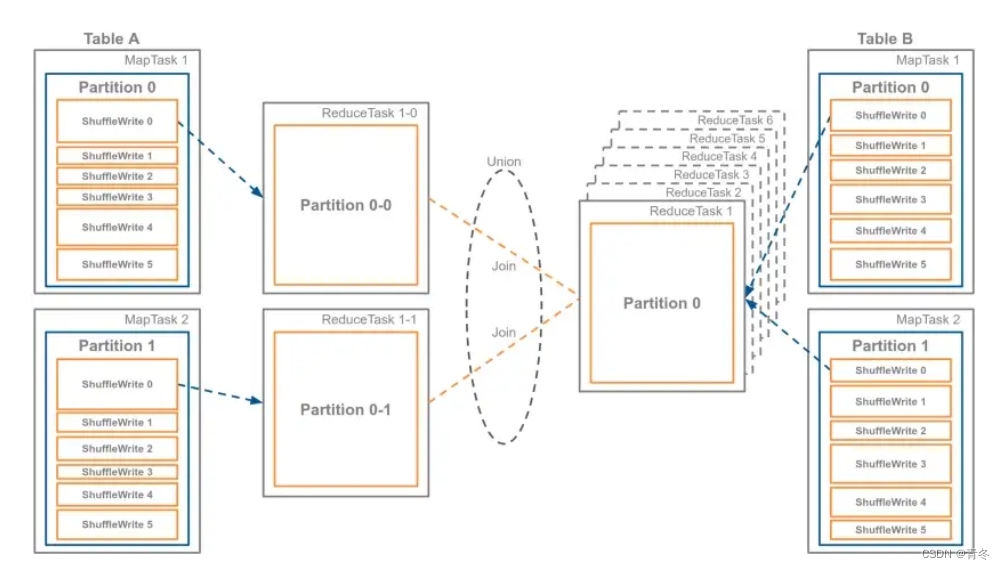
如上图所示,当A表与B表进行关联时,Partition0 中的数据可能有数据倾斜,那么判断出数据倾斜了后,会创建多个 ReduceTask 来处理 Partition0 中的数据。如果是A表数据量较大,一般会仅从几个mapper中获取数据,但会多次获取B表 Partition0中的数据。
再来一个文字例子:
例如,需要排序合并联接有4个分区:左:[L1,L2,L3,L4]右:[R1,R2,R3,R4]
假设L2、L4和R3、R4是倾斜的,它们每个都被分成2个子分区。
这plan在开始时运行4个任务:
(L1,R1),(L2,R2),(L3,R3),(L4,R4)。
AQE 将其扩展为9个任务以提高并行性:
(L1, R1), (L2-1, R2), (L2-2, R2), (L3, R3-1), (L3, R3-2), (L4-1, R4-1), (L4-2, R4-1), (L4-1, R4-2), (L4-2, R4-2)
对应的参数改动有:
-
spark.sql.adaptive.skewJoin.enabled
开启数据倾斜动态优化 ;default true;3.0.0;
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor
中位数的多少倍认为是倾斜分区;default 5;3.0.0;上述的F倍就是这个参数
-
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes
可被认为是倾斜分区的最小阈值;default 256MB;3.0.0;上述的MaxSize
-
spark.sql.adaptive.localShuffleReader.enabled
开启本地读;default true;3.0.0;
spark3.3:
org.apache.spark.sql.execution.adaptive.OptimizeSkewedJoin
结语
好久没碰 spark 了,一眼就看到了新东西,再回过头去看代码的时候,发现已经多了这么多东西。当初做优化的时候,一直抱怨为什么这些东西没有,现在终于有了,感激(说不定德特萨维用上了spark3.3顿时节约好多资源呢)。


![[附源码]Python计算机毕业设计Django旅游度假村管理系统](https://img-blog.csdnimg.cn/c28ca93a6e844bff86751b574db126a7.png)

![[附源码]计算机毕业设计作业管理系统Springboot程序](https://img-blog.csdnimg.cn/edf9db8a48da4f53ba345c31bf812c3d.png)



![[附源码]计算机毕业设计springboot小太阳幼儿园学生管理系统](https://img-blog.csdnimg.cn/acdab7701e184472a2814edcfc05b710.png)