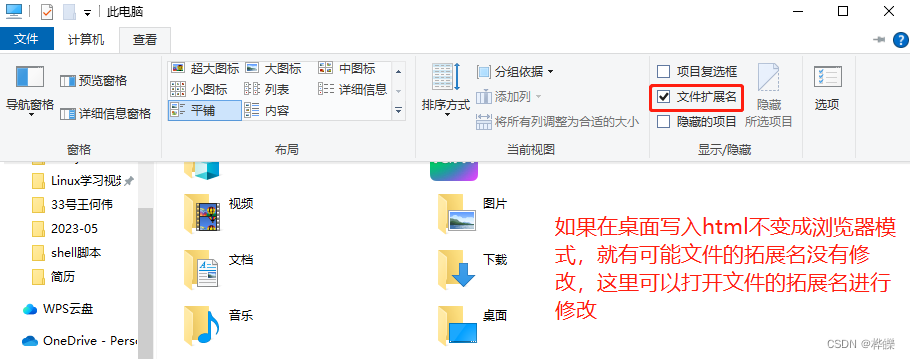
测试程序
编写内存消耗程序 eatMemory.c
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <string.h>
#include <unistd.h>
#include <sys/time.h>
#include <sched.h>
#include <errno.h>
#include <pthread.h>
// 1GB
#define BLOCK_SIZE 1024 * 1024 * 1024
int main(int argc, char *argv[])
{
//动态申请256G 内存
void *buff[256];
for (int i = 0; i < 256; i++)
{
buff[i] = malloc(BLOCK_SIZE);
if (buff[i] != NULL)
{
memset(buff[i], 0, BLOCK_SIZE);
}
else
{
printf("malloc failed, %d\n", i);
}
}
sleep(60);
return 0;
}编译
gcc eatMemory.c -o eatMemory开启状态(默认)
开机查看状态
dmesg | grep -i numa
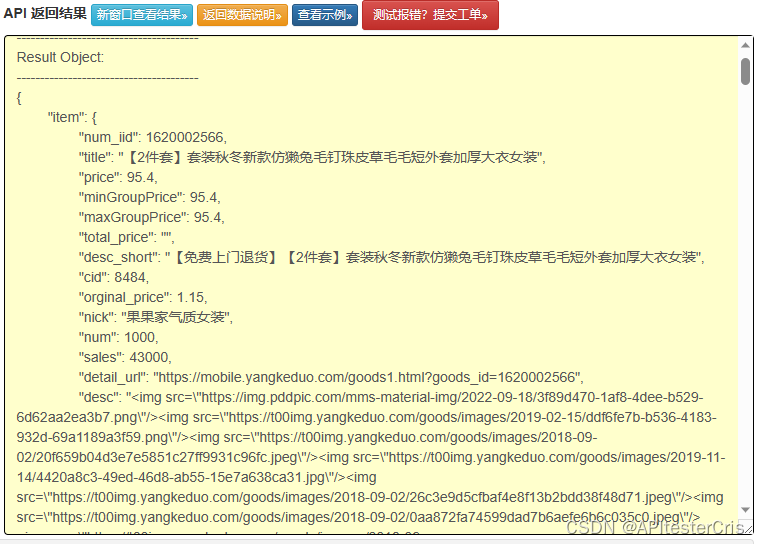
执行测试
./eatMemory &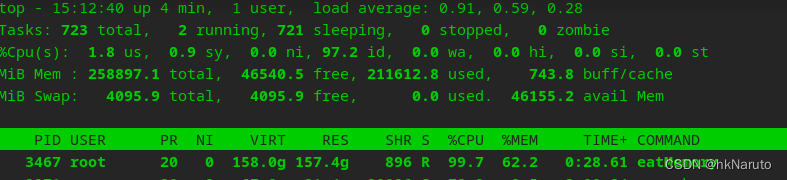
被kill时消耗内存total-vm:214973696kB

关闭状态(OS numa=off ;bios启用NUMA)
启动时,grub零时关闭:添加
numa=off
dmesg验证已关闭
dmesg | grep -i numa
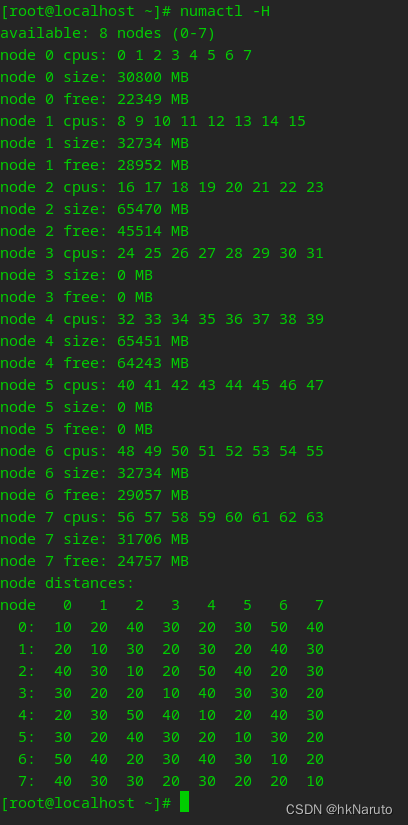
此时,numactl看到的只有一个node(物理上有8个node)

执行测试


最终消耗了206G内存后被oom-kill

关闭状态(OS numa=off ;bios停用NUMA)

同时
启动后
dmesg | grep -i numa

测试

总结
对应用程序eatMemory而言,numa的开关状态对内存申请大小并没有差别,同样可以用到系统可用内存范围,此环境约200GB。
并没有因为关闭numa导致只能使用某个node上的内存。
附:NUMA开关作用
NUMA options in BIOS - Intel Community
部分内容翻译:
启用/禁用NUMA的性能有点复杂。
让我们从bios中禁用NUMA开始。如果我没有记错的话,在这种情况下,硬件将从每个套接字中循环缓存线。也就是说,当操作系统分配一页内存时,它将从套接字0中获得第一个64字节,从套接字1中获得下一个64字节。这导致所有内存分配都分布在所有套接字上。这在某些情况下可能很有用,比如软件不支持NUMA,并且不知何故属于“启用NUMA时运行速度较慢”的情况。我认为交织的级别可能与某些系统或操作系统上的“每个缓存行”不同(例如,您可以在“每页”级别上进行交织)。
启用NUMA的情况更为复杂。在linux上,有一个“numactl”命令来显示numa设置和内存分配策略。这是最简单、最好的情况。假设bios中启用了numa,操作系统支持numa,并且占用了1个以上的套接字。该软件可以最快地访问“本地”内存。因此,如果sw线程在本地numa节点上分配内存,并且sw线程从同一numa节点访问内存,那么它将能够尽快访问内存。如果sw线程在分配内存后出于某种原因迁移到另一个numa节点,那么sw线程将无法快速访问内存。这种放缓是否真的会影响应用程序的性能是非常具体的应用程序。
在linux上(也许现在在windows上…我只是没有检查过),你可以设置每个进程或每个线程的numa策略。也就是说,您可以在启用numa的情况下启动,然后告诉操作系统“就像禁用numa一样”进行特定的内存分配。也就是说,操作系统可以在numa节点之间交错分配(我认为是在每页交错级别)。如果分配超过了任何单个节点上的内存量,这可能会很有用。