在人工智能 (AI) 进步的快节奏世界中,开发人员正在寻找最高效和突破性的解决方案来加快和提高他们的工作质量。对于 PostgreSQL 开发人员来说,选择理想的 AI 支持的工具以最专业的方式解决他们的查询至关重要。
近年来,人工智能工具的普及率飙升,开发人员越来越认识到它们在简化工作各个方面的潜力。一些最著名的 AI 工具包括 OpenAI 的 ChatGPT、Google 的 Bard、IBM 的 Watson 和 Microsoft 的 Azure Cognitive Services 等。这些工具彻底改变了开发人员解决问题的方式,并使以前耗时的任务更易于管理。在本文中,我们将重点比较 ChatGPT-4 和 Google Bard 对一系列常见 SQL 开发相关问题的响应。通过这样做,我们旨在清楚地了解每种工具的功能,并帮助您确定哪种工具更适合您在 SQL 开发领域的特定需求。

dbForge 最新下载![]() https://www.evget.com/vendor/214
https://www.evget.com/vendor/214
什么是ChatGPT?
ChatGPT 由 OpenAI 开发,是一种基于 GPT(Generative Pre-trained Transformer)架构的最先进的 AI 语言模型。作为一种大规模语言模型,ChatGPT 旨在生成类人文本并与用户进行对话,了解上下文并提供相关响应。它能够执行各种任务,例如回答问题、提供建议、创建内容等。
开发人员和企业可以通过将 ChatGPT 集成到他们的应用程序、服务或产品中来利用 ChatGPT 的强大功能,通过自然语言的理解和生成来增强用户体验。ChatGPT 已成功应用于客户支持、内容创建、虚拟协助以及自然语言处理必不可少的许多其他领域。
什么是Google Bard?
Google Bard 是一种大型语言模型,也称为对话式 AI 或聊天机器人,经过训练可提供丰富的信息和全面的信息。巴德接受过大量文本数据的训练,能够通过交流和生成类似人类的文本来响应范围广泛的提示和问题。
虽然仍处于开发阶段,但该工具已经可以通过多种方式帮助 SQL 开发人员,包括回答有关 SQL 语法和用法的问题、帮助调试 SQL 查询、生成针对特定任务定制的 SQL 代码,以及提供有关 SQL 的教程和文档,以及其他功能.
ChatGPT 与 Google Bard
ChatGPT 和 Google Bard 都是大型语言模型,但它们有一些关键的区别。
- 数据: ChatGPT 在截至 2021 年收集的文本和代码数据集上进行训练,而 Google Bard 在不断更新的数据集上进行训练。这意味着 Google Bard 可以访问更多最新信息,并可以提供更准确的答案。
- 准确性: Google Bard 通常比 ChatGPT 更准确,尤其是在涉及事实信息时。这是因为 Google Bard 是在更大、更新的数据集上训练的。
- 创造力:在生成文本格式(例如诗歌、代码、脚本、音乐作品、电子邮件、信件等)方面,ChatGPT 比 Google Bard 更具创造力。这是因为 ChatGPT 是在包含更广泛创意的数据集上训练的文本格式。
- 可用性: ChatGPT 可供任何想使用它的人使用,而 Google Bard 目前仅供有限数量的用户使用。
| ChatGPT | Google Bard | |
| 开发商 | OpenAI | 谷歌 |
| 语言模型 | OpenAI 的 Generative Pre-training Transformer 3 (GPT-3) 或 Generative Pre-training Transformer 4 (GPT-4) 的定制版本,具体取决于版本 | Google 的对话应用程序语言模型 (LaMDA) |
| 数据源 | ChatGPT 使用大量文本数据进行训练,包括 Common Crawl、维基百科、书籍、文章和从开放互联网获得的各种文档等资源。然而,它的训练数据只延伸到 2021 年,这限制了它对最近世界事件和研究进展的了解。 | Bard 使用 Infiniset 进行训练,这是一个包含 Common Crawl、维基百科、文档以及来自互联网的对话和对话的数据集。据称,巴德可以进行实时网络搜索,以提供最新的查询答案和最新的研究成果。 |
| 价钱 | ChatGPT 向用户免费提供,而 ChatGPT Plus 每月收取 20 美元的订阅费。ChatGPT Plus 的订阅者受益于高需求期间的访问、加快响应时间、优先访问新功能以及 GPT-4 的使用。 | 有访问权限的用户可以免费使用 Bard。 |
如何使用 ChatGPT 和 Bard 进行 PostgreSQL 开发
通过提供语法和使用指导、生成 SQL 代码、协助查询调试等,人工智能可以在 PostgreSQL 开发中发挥重要作用。在本文中,我们将向 Bard 和 ChatGPT 提出与 SQL 开发相关的相同问题,然后比较和验证他们的回答。我们的目标是评估这两种人工智能在 PostgreSQL 开发环境中的可靠性和实用性。为了验证 AI 提供的答案,我们将使用市场上最好的 PostgreSQL GUI 工具之一——dbForge Studio for PostgreSQL。
先决条件
- Pagila 示例数据库
- 用于 PostgreSQL 的 dbForge Studio
- 访问 ChatGPT-4
- 访问 Google Bard
示例 #1:函数
假设,我们需要创建一个函数来返回给定时间段内租借次数最多的电影及其租借次数。让我们请 ChatGPT-4 来完成任务。

ChatGPT-4 生成了以下 SQL 代码:
CREATE OR REPLACE FUNCTION most_rented_films(start_date DATE, end_date DATE) RETURNS TABLE (film_id INTEGER, title TEXT, rental_count INTEGER) AS $$ BEGIN RETURN QUERY SELECT f.film_id, f.title, COUNT(r.rental_id) AS rental_count FROM film AS f JOIN inventory AS i ON f.film_id = i.film_id JOIN rental AS r ON i.inventory_id = r.inventory_id WHERE r.rental_date BETWEEN start_date AND end_date GROUP BY f.film_id, f.title ORDER BY rental_count DESC; END; $$ LANGUAGE plpgsql;
现在让我们打开 dbForge Studio for PostgreSQL 并验证 AI 创建的代码。
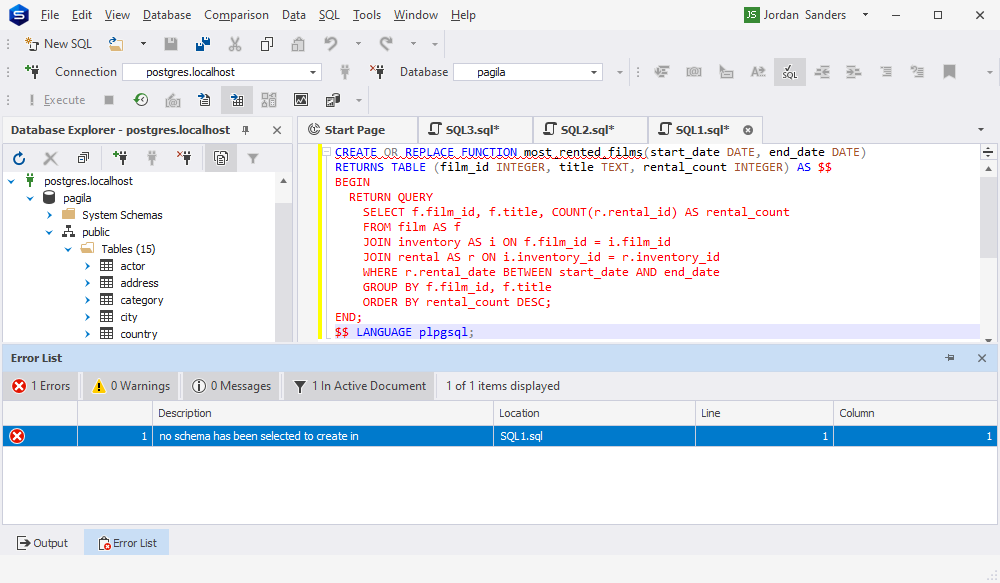
如您所见,Studio 抛出错误,因为未指定用于创建函数的架构。让我们稍微修改一下代码,然后再试一次。
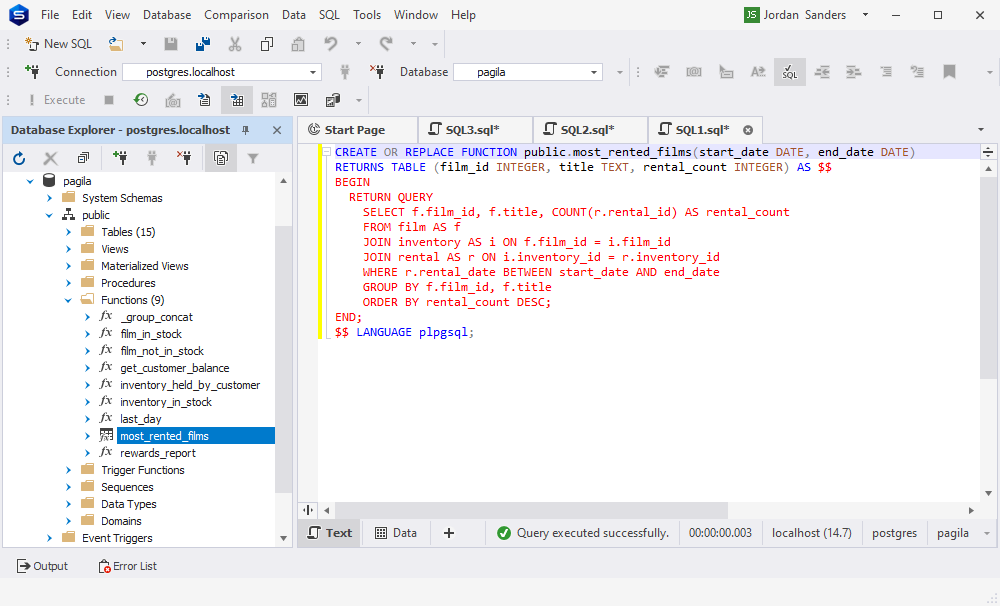
这次查询成功,并且该函数现在在数据库资源管理器中可见。
现在,是时候运行 SELECT 语句以确保一切都按要求工作了。

哎呀。又出现错误。在函数语法中,rental_count 列数据类型已指定为 INTEGER,这显然是错误的。我们需要修改语法并重试。因此,工作代码如下:
CREATE OR REPLACE FUNCTION public.most_rented_films(start_date DATE, end_date DATE)
RETURNS TABLE (film_id INTEGER, title TEXT, rental_count BIGINT) AS $$
BEGIN
RETURN QUERY
SELECT f.film_id, f.title, COUNT(r.rental_id) AS rental_count
FROM film AS f
JOIN inventory AS i ON f.film_id = i.film_id
JOIN rental AS r ON i.inventory_id = r.inventory_id
WHERE r.rental_date BETWEEN start_date AND end_date
GROUP BY f.film_id, f.title
ORDER BY rental_count DESC;
END;
$$ LANGUAGE plpgsql;
因此,我们删除之前创建的函数,创建一个新函数,然后运行 SELECT。这次成功了。
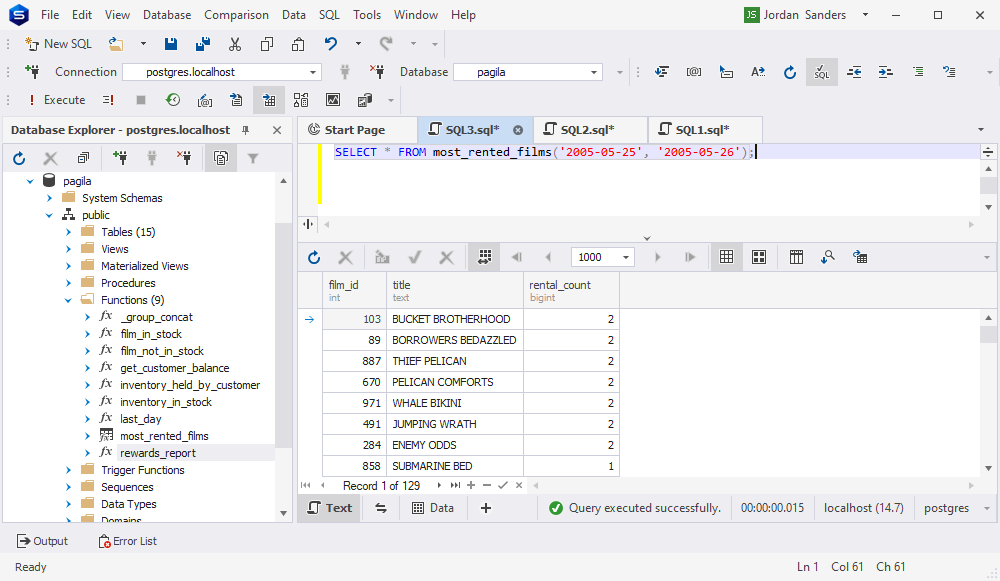
现在让我们评估一下 Google Bard。
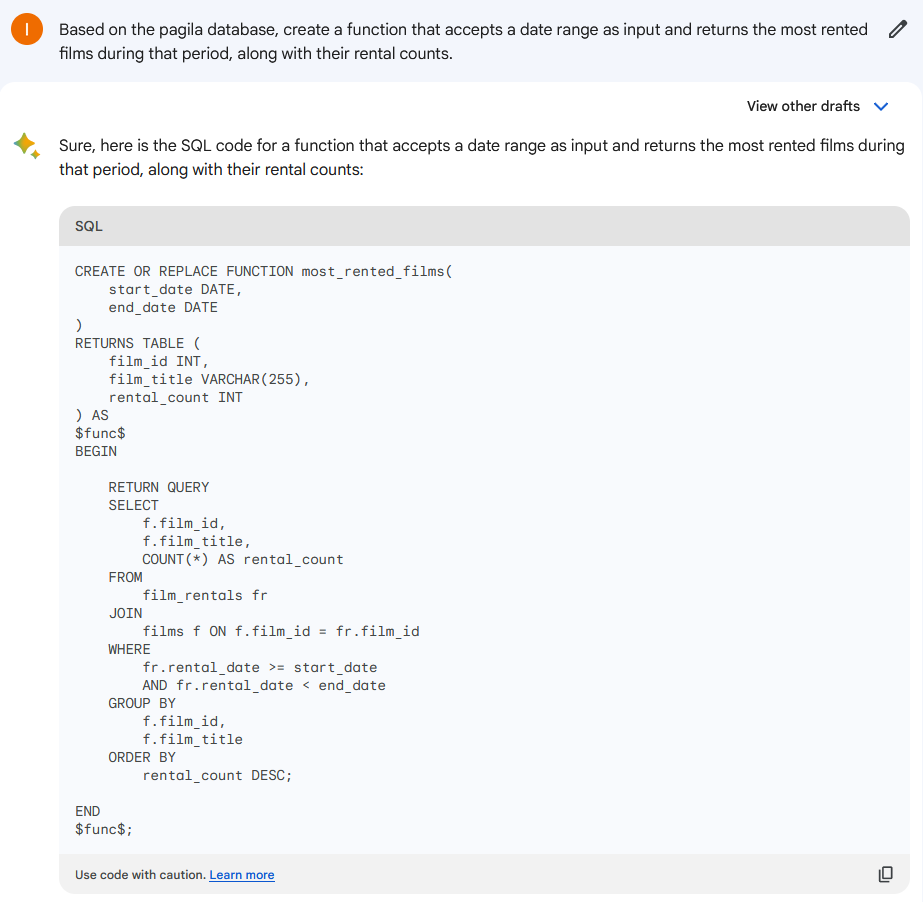
于是,我们得到了如下代码:
CREATE OR REPLACE FUNCTION most_rented_films (start_date DATE,
end_date DATE) RETURNS TABLE (
film_id INT,
film_title VARCHAR(255),
rental_count INT
)
AS
$func$
BEGINRETURN QUERY
SELECT
f.film_id,
f.film_title,
COUNT(*) AS rental_count
FROM
film_rentals fr
JOIN
films f ON f.film_id = fr.film_id
WHERE
fr.rental_date >= start_date
AND fr.rental_date < end_date
GROUP BY
f.film_id,
f.film_title
ORDER BY
rental_count DESC;END
$func$;
让我们在 Studio 中运行它,好吗?压力来了!我们得到了同样的错误——模式没有被指定。
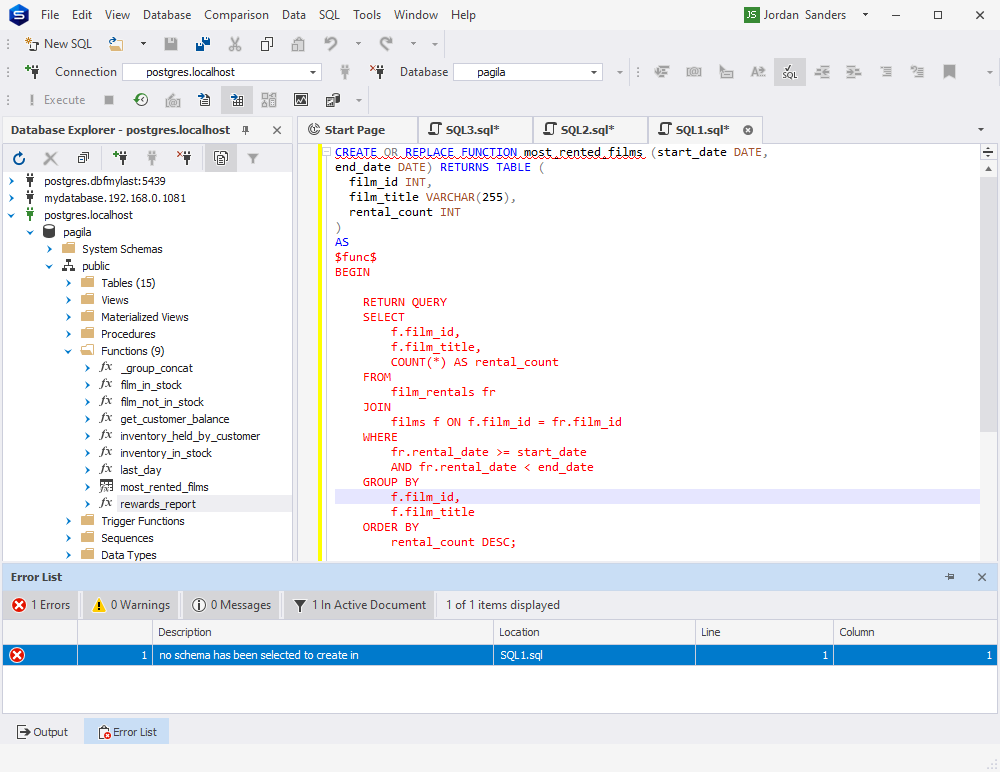
于是,我们修改代码,再次运行。并得到另一个错误。

我们需要进一步修改查询。指定语言并执行语法后,我们运行 SELECT。并且……再次出错。

Google Bard 在其脚本中引用了不存在的表;除此之外,rental_count 列的数据类型被错误地指定为 INT。在我们解决了所有这些问题之后,我们终于得到了工作代码。不好玩,对吧?使用 Google Bard,我们不得不调整生成的代码很长一段时间,这需要一定程度的专业知识,这意味着 SQL 初学者可能无法利用它的提示。
示例 #2:日期函数
假设,我们要创建一个日期函数,返回指定范围内电影租金最高的星期几。让我们首先请 ChatGPT-4 协助我们完成这项任务。
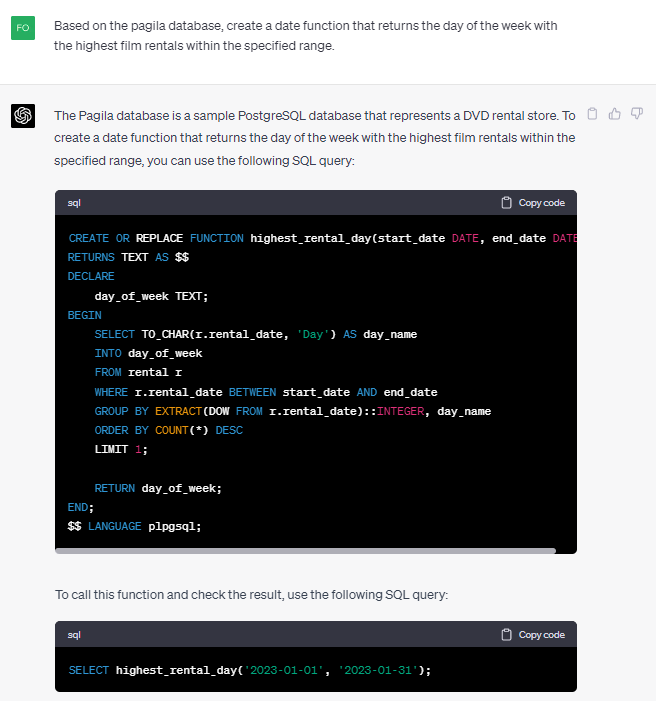
因此,ChatGPT-4 为我们生成了以下查询:
CREATE OR REPLACE FUNCTION highest_rental_day(start_date DATE, end_date DATE)
RETURNS TEXT AS $$
DECLARE
day_of_week TEXT;
BEGIN
SELECT TO_CHAR(r.rental_date, 'Day') AS day_name
INTO day_of_week
FROM rental r
WHERE r.rental_date BETWEEN start_date AND end_date
GROUP BY EXTRACT(DOW FROM r.rental_date)::INTEGER, day_name
ORDER BY COUNT(*) DESC
LIMIT 1;RETURN day_of_week;
END;
$$ LANGUAGE plpgsql;
您可能还记得示例 #1,在 dbForge Studio for PostgreSQL 中运行此代码之前,我们需要指定架构。否则,我们会得到一个错误。
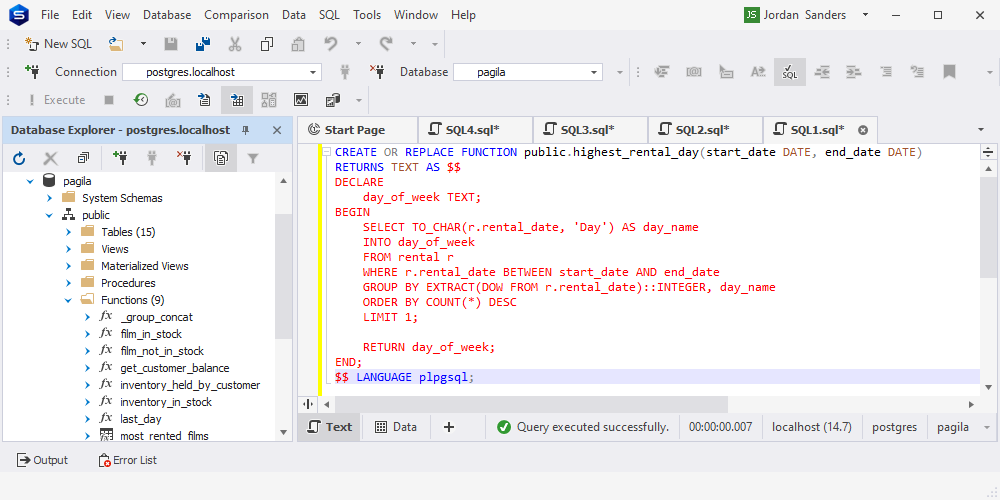
该函数已成功创建。让我们检查一下它是如何工作的。
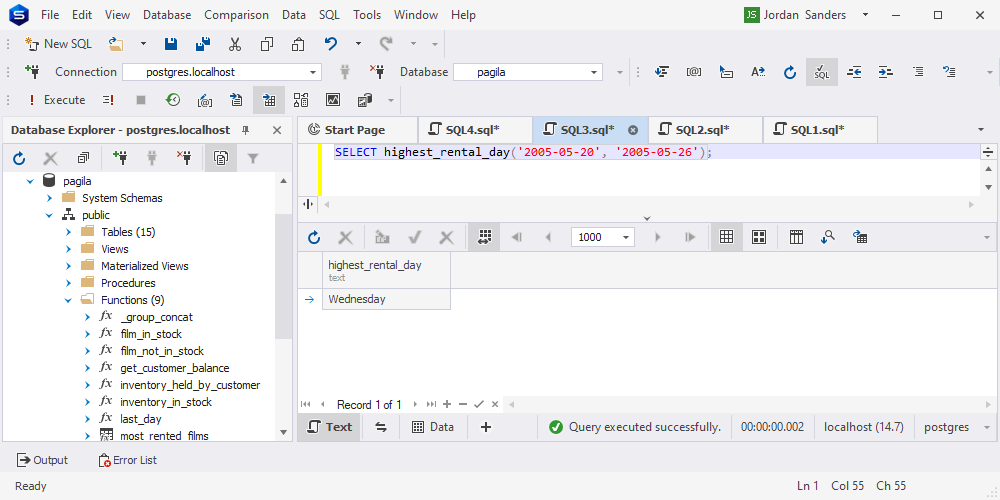
让我们看看 Google Bard 将如何应对这项任务。
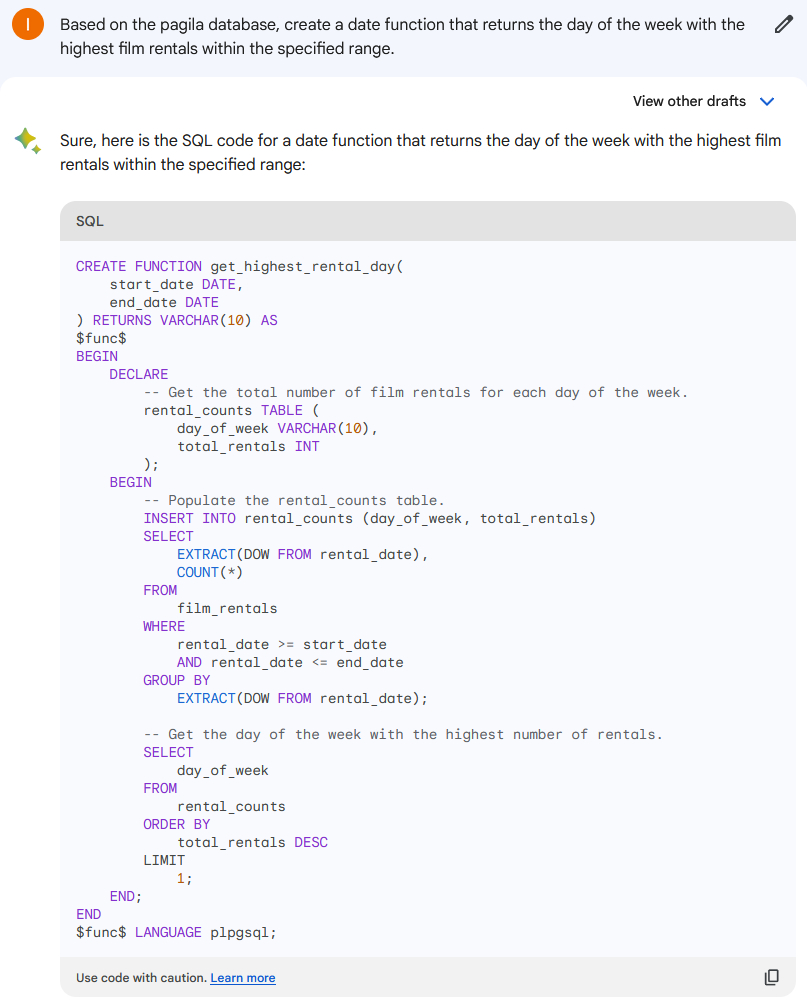
这是我们得到的代码。
CREATE FUNCTION get_highest_rental_day(
start_date DATE,
end_date DATE
) RETURNS VARCHAR(10) AS
$func$
BEGIN
DECLARE
-- Get the total number of film rentals for each day of the week.
rental_counts TABLE (
day_of_week VARCHAR(10),
total_rentals INT
);
BEGIN
-- Populate the rental_counts table.
INSERT INTO rental_counts (day_of_week, total_rentals)
SELECT
EXTRACT(DOW FROM rental_date),
COUNT(*)
FROM
film_rentals
WHERE
rental_date >= start_date
AND rental_date <= end_date
GROUP BY
EXTRACT(DOW FROM rental_date);
-- Get the day of the week with the highest number of rentals.
SELECT
day_of_week
FROM
rental_counts
ORDER BY
total_rentals DESC
LIMIT
1;
END;
END
$func$ LANGUAGE plpgsql;
我们指定架构并在 Studio for PostgreSQL 中运行它。当试图从此函数执行 SELECT 时,我们得到一个错误。PostgreSQL 中没有 TABLE 数据类型。

我们要求 Google Bard 重写语法,但我们没有得到功能代码。因此,它会因这项特定任务而被记过。
示例 #3:窗口函数
PostgreSQL 中的窗口函数是一种对与当前行相关的一组行执行计算的函数。它允许您执行高级计算,包括将当前行与指定窗口或分区内的其他行进行比较。窗口函数对于排名、累积和、移动平均等任务很有用。
假设,我们要计算每个客户的累计付款金额,并获得按付款日期排序的金额。让我们首先向 ChatGPT-4 寻求帮助。

这是我们得到的语法,如果您想自己检查一下:
SELECT
customer_id,
payment_date,
amount,
SUM(amount) OVER (PARTITION BY customer_id ORDER BY payment_date) as cumulative_amount
FROM
payment
ORDER BY
payment_date;
现在我们打开 dbForge Studio for PostgreSQL 并运行 ChatGPT-4 为我们生成的查询。

让我们向 Google Bard 问同样的问题。
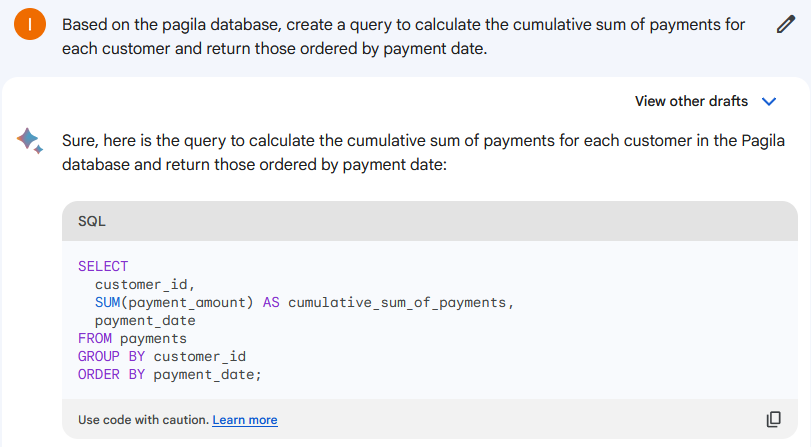
这是我们得到的代码:
SELECT
customer_id,
SUM(payment_amount) AS cumulative_sum_of_payments,
payment_date
FROM payments
GROUP BY customer_id
ORDER BY payment_date;
但是,它有很多问题:
- pagila 数据库中没有payments表,它被称为payment。
- payment_amount列也不存在。它被称为数量。
- 没有按日期分组。
- 排序由错误的列完成。
新手可能很难使用该提示,因为需要对查询进行大量修改才能正常工作。
示例 #4:JOIN 子句
JOIN用于根据它们之间的相关列组合来自关系数据库中两个或多个表的数据。它们允许您在单个查询中从多个表中检索信息,使其成为使用关系数据库的重要工具。
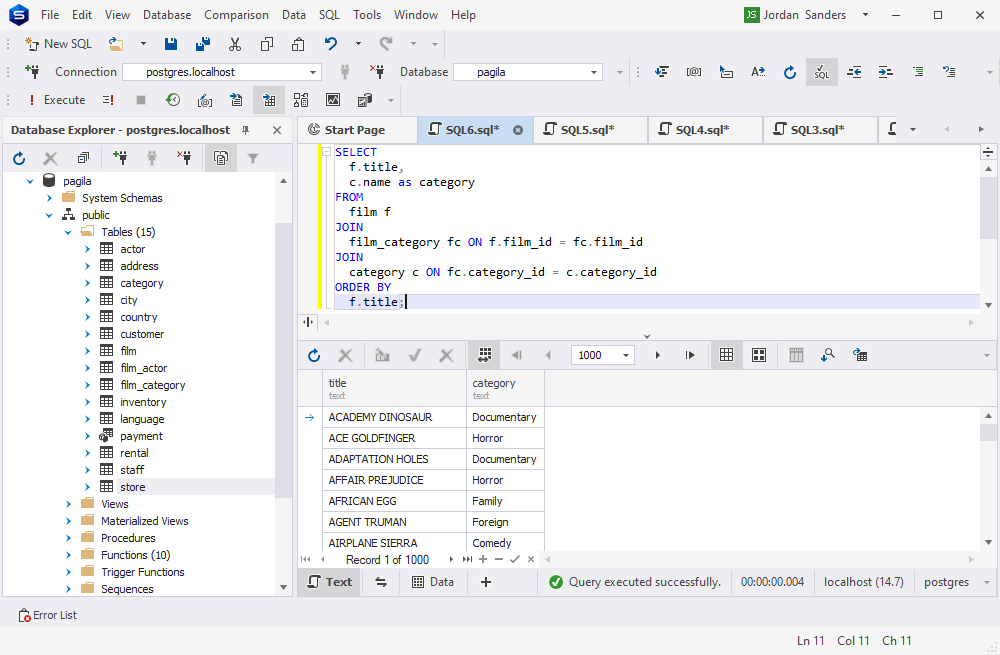
假设,我们想要获得所有电影及其所属类别的列表。让我们先问一下ChatGPT-4。

这是我们得到的语法
SELECT
f.title,
c.name as category
FROM
film f
JOIN
film_category fc ON f.film_id = fc.film_id
JOIN
category c ON fc.category_id = c.category_id
ORDER BY
f.title;
乍一看,查询看起来不错。让我们验证一下。
我们现在尝试Google
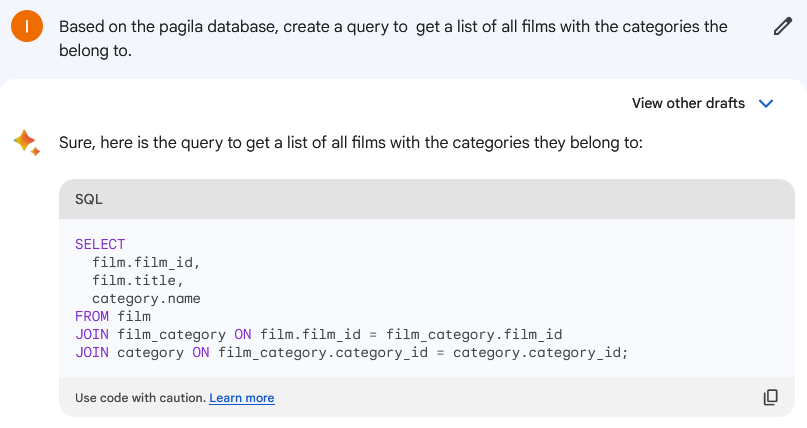
下面是我们得到的语法
SELECT
film.film_id,
film.title,
category.name
FROM film
JOIN film_category ON film.film_id = film_category.film_id
JOIN category ON film_category.category_id = category.category_id;
让我们在 Studio 中运行由 Google Bard 生成的查询。

如您所见,Google Bard 也完成了这项任务。查询非常相似,唯一的区别是 ChatGPT-4 添加了 ORDER BY 子句以实现更好的结果分析和可见性。
示例 #5:数据透视表
在 PostgreSQL 中,数据透视表是一种数据汇总工具,可让您聚合数据并将其从数据库转换为更易读的格式。
假设,我们想要获得一个数据透视表,按电影类别显示每个客户的总租赁金额。让我们去请 ChatGPT 为我们编写相应的查询。

ChatGPT 向我们提供了以下查询:
WITH rental_amounts AS (
SELECT
c.customer_id,
cat.name AS category,
SUM(p.amount) AS total_amount
FROM
rental r
JOIN payment p ON r.rental_id = p.rental_id
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
JOIN film_category fc ON f.film_id = fc.film_id
JOIN category cat ON fc.category_id = cat.category_id
JOIN customer c ON r.customer_id = c.customer_id
GROUP BY
c.customer_id,
cat.name
)
SELECT
customer_id,
SUM(CASE WHEN category = 'Action' THEN total_amount ELSE 0 END) AS "Action",
SUM(CASE WHEN category = 'Animation' THEN total_amount ELSE 0 END) AS "Animation",
SUM(CASE WHEN category = 'Children' THEN total_amount ELSE 0 END) AS "Children",
-- Add more categories as needed
SUM(total_amount) AS "Total"
FROM
rental_amounts
GROUP BY
customer_id
ORDER BY
customer_id;
现在是时候在 dbForge Studio for PostgreSQL 中验证它了。准备好?
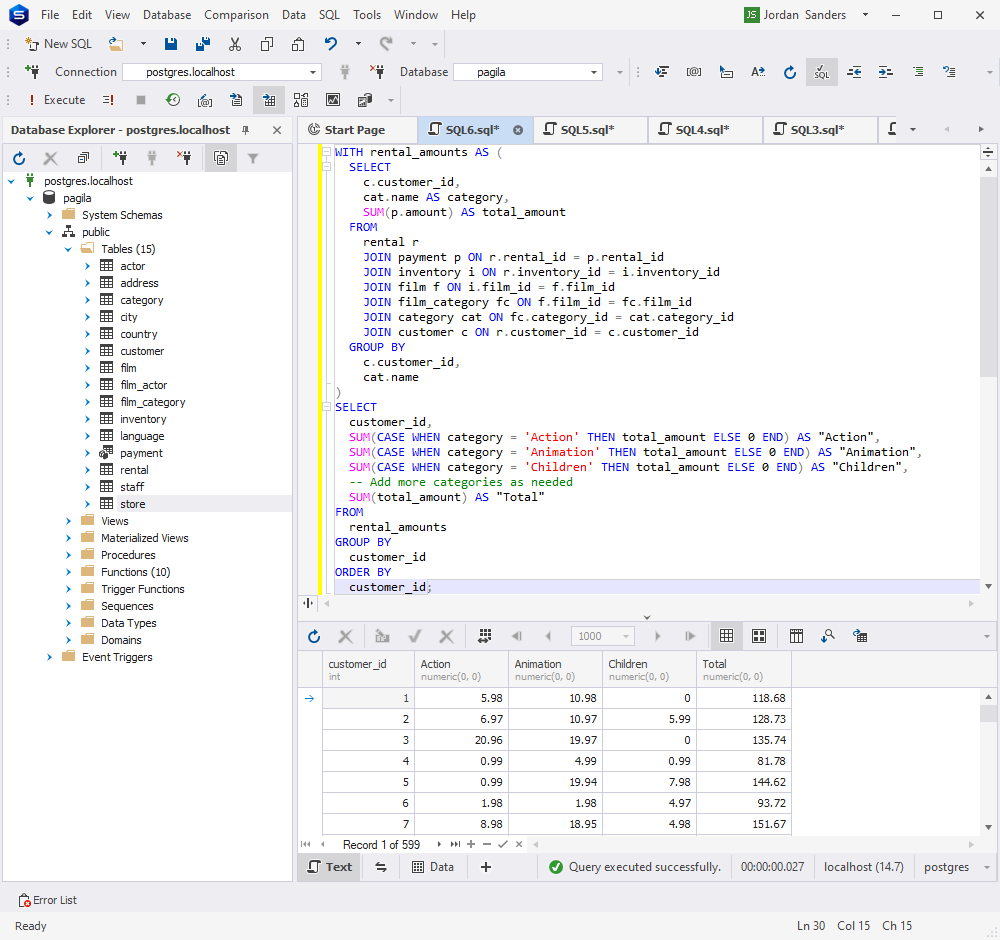
相当令人印象深刻,不是吗?现在我们带着同样的请求去谷歌验证
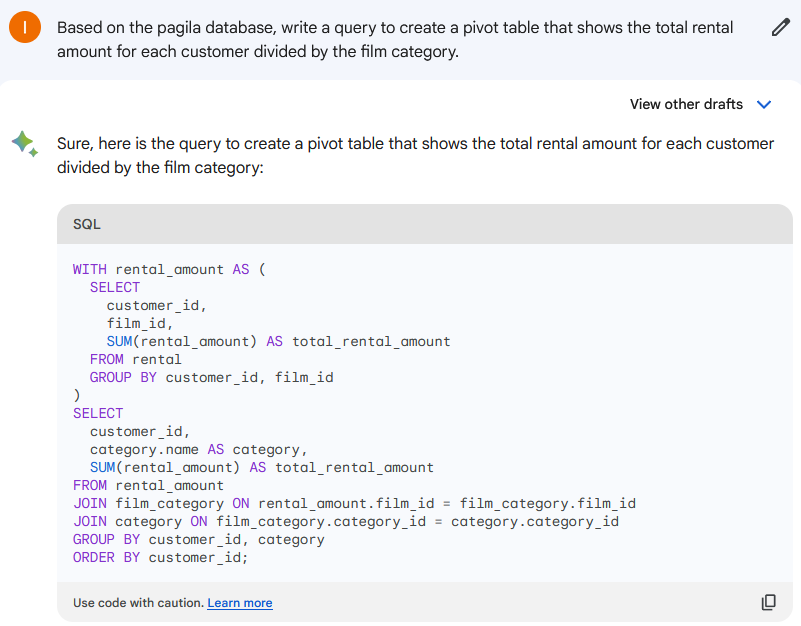
我们得到以下代码:
WITH rental_amount AS (
SELECT
customer_id,
film_id,
SUM(rental_amount) AS total_rental_amount
FROM rental
GROUP BY customer_id, film_id
)
SELECT
customer_id,
category.name AS category,
SUM(rental_amount) AS total_rental_amount
FROM rental_amount
JOIN film_category ON rental_amount.film_id = film_category.film_id
JOIN category ON film_category.category_id = category.category_id
GROUP BY customer_id, category
ORDER BY customer_id;
然而,当我们运行 Google Bard 为我们生成的查询时,我们会遇到一些错误。
- rental表中没有film_id列,因此也无法按它进行分组。
- rental_amount列不存在。
- rental_amount.film_id = film_category.film_id JOIN 无效,因为如上所述,rental中没有film_id。
哪个人工智能工具更好?
Google Bard 和 ChatGPT-4 都在不断发展,这些工具在 AI 语言模型领域具有巨大的潜力。但是,根据本文中进行的分析,ChatGPT-4 在处理 PostgreSQL 提示方面表现出卓越的性能。ChatGPT-4 生成的代码通常需要较少的修改,从而提高了效率。此外,ChatGPT-4 拥有更高的可访问性,因为与对应的模型相比,获得对该 AI 模型的访问是一个更直接的过程。
此外,ChatGPT 生成的代码更加人性化;例如,AI 贴心地包含了 ORDER BY 和 GROUP BY 等子句,使结果更易于理解和分析。这有助于识别趋势和模式,最终改善使用输出时的整体用户体验。
Devart 提供包括Oracle、SQL Server、MySQL、PostgreSQL、InterBase以及Firebird在内的专业数据库远程管理软件,dbForge Studio for MySQL是一个在Windows平台被广泛使用的MySQL客户端,它能够使MySQL开发人员和管理人员在一个方便的环境中与他人一起完成创建和执行查询,开发和调试MySQL程序,自动化管理MySQL数据库对象等工作。