本文主要内容为介绍CUDA编程前的一些基础知识
参考资料:
高升博客
《CUDA C编程权威指南》
以及 CUDA官方文档
文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭
1:并行计算
并行程序可以分为
指令并行:一般应用在管理系统,比如淘宝交易系统,每时每刻都有很多人在同时使用,后台需要能够并行处理这些请求。
数据并行:一般应用大规模数据计算,大量数据,使用相同的计算程序计算
CUDA非常适合数据并行计算。
数学并行第一步,
数据按线程划分
(1)
块划分,把一整块数据切成小块,每个小块随机的划分给一个线程,每个块的执行顺序随机。

(2)
周期划分,线程按照顺序处理相邻的数据块,每个线程处理多个数据块,比如我们有五个线程,线程1执行块1,线程2执行块2……线程5执行块5,线程1执行块6

2:计算机架构
佛林分类法Flynn’s Taxonomy,根据指令和数据进入CPU的方式分类,分为以下四类:
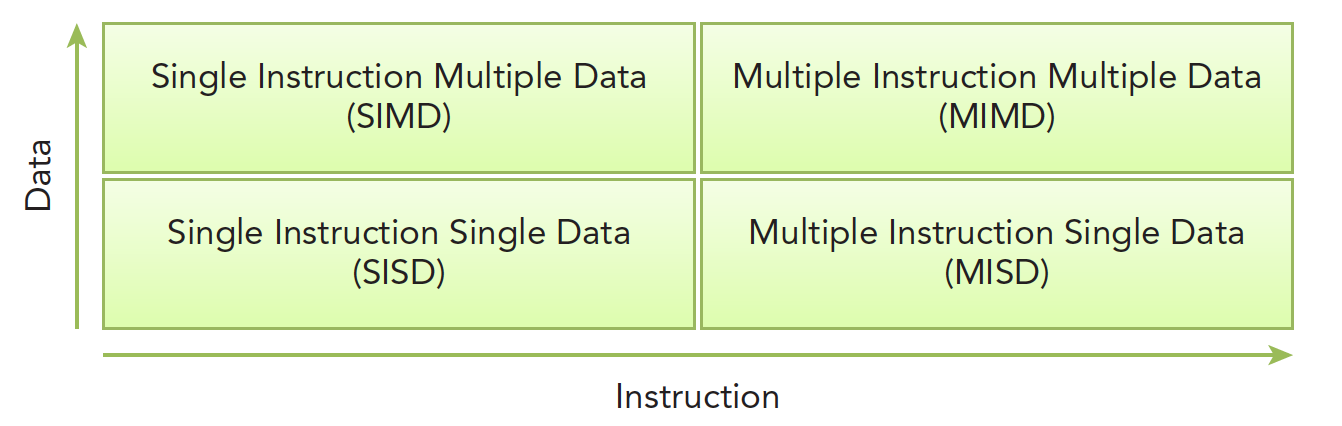
(1)分别以数据和指令进行分析:
单指令单数据SISD(传统串行计算机,386)
单指令多数据SIMD(并行架构,比如向量机,所有核心指令唯一,但是数据不同,现在CPU基本都有这类的向量指令)
多指令单数据MISD(少见,多个指令围殴一个数据)
多指令多数据MIMD(并行架构,多核心,多指令,异步处理多个数据流,从而实现空间上的并行,MIMD多数情况下包含SIMD,就是MIMD有很多计算核,计算核支持SIMD)
(2)为了提高并行的计算能力,我们要从架构上实现下面这些性能提升:
降低延迟
提高带宽
提高吞吐量
延迟是指操作从开始到结束所需要的时间,一般用微秒计算,延迟越低越好。
带宽是单位时间内处理的数据量,一般用MB/s或者GB/s表示。
吞吐量是单位时间内成功处理的运算数量,一般用gflops来表示(十亿次浮点计算),吞吐量和延迟有一定关系,都是反应计算速度的,一个是时间除以运算次数,得到的是单位次数用的时间–延迟,一个是运算次数除以时间,得到的是单位时间执行次数–吞吐量
3:异构架构
CPU我们可以把它看做一个指挥者,主机端,host,而完成大量计算的GPU是我们的计算设备,device
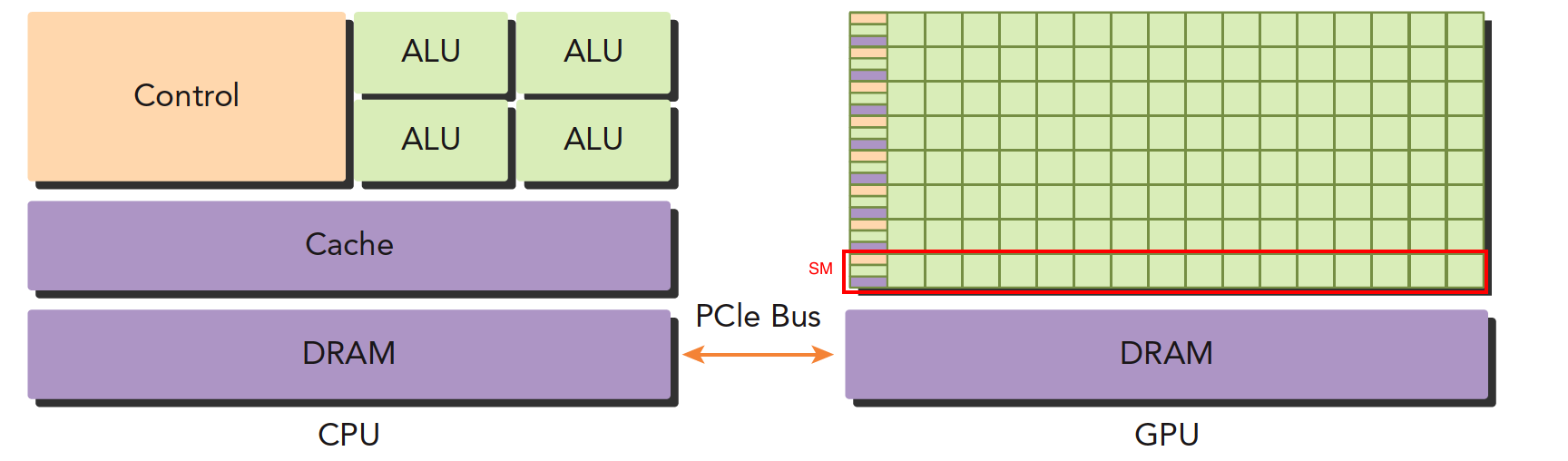
(1)上面这张图能大致反应CPU和GPU的架构不同。
左图:CPU,4个ALU,主要负责逻辑计算,1个控制单元Control,1个DRAM内存,1个Cache缓存
右图:GPU,绿色小方块是ALU,我们注意红色框内的部分SM,这一组ALU公用一个Control单元和Cache,这个部分相当于一个完整的多核CPU,但是不同的是ALU多了,control部分变小,可见计算能力提升了,控制能力减弱了,所以对于控制(逻辑)复杂的程序,一个GPU的SM是没办法和CPU比较的,但是对了逻辑简单,数据量大的任务,GPU更搞笑,并且,注意,一个GPU有好多个SM,而且越来越多
(2)主机代码在主机端运行**,被编译成主机架构的机器码,设备端的在设备上执行,被编译成设备架构的机器码,所以主机端的机器码和设备端的机器码是隔离的,自己执行自己的,没办法交换执行。
主机端代码主要是控制设备,完成数据传输等控制类工作,设备端主要的任务就是计算。
因为当没有GPU的时候CPU也能完成这些计算,只是速度会慢很多,所以可以把GPU看成CPU的一个加速设备。
(3)CPU和GPU线程的区别:
CPU线程是重量级实体,操作系统交替执行线程,线程上下文切换花销很大
GPU线程是轻量级的,GPU应用一般包含成千上万的线程,多数在排队状态,线程之间切换基本没有开销。
CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU核则是大量线程,最大幅度提高吞吐量
4:CUDA编程结构
一个完整的CUDA应用可能的执行顺序如下图:
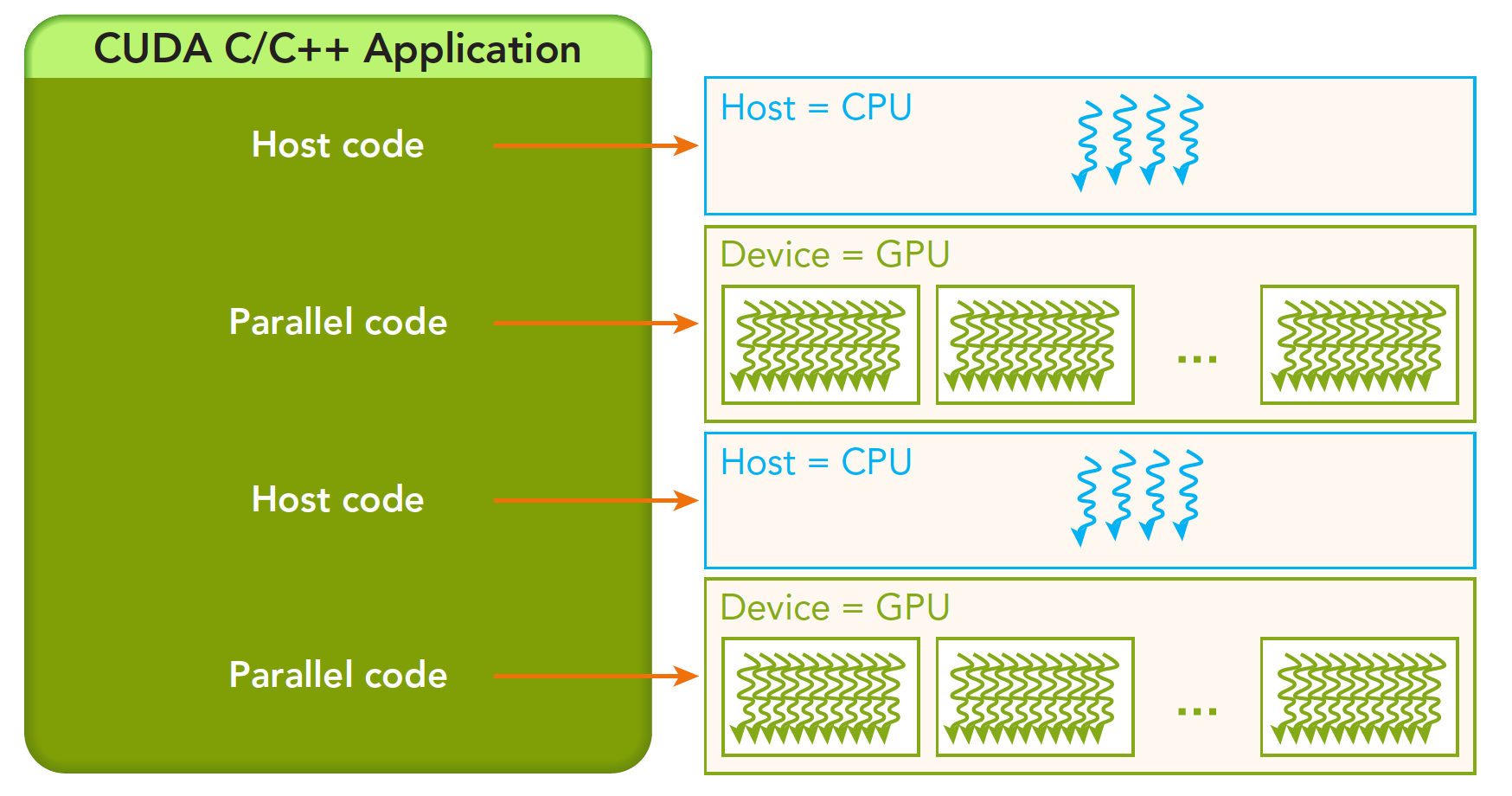
从host的串行到调用核函数(核函数被调用后控制马上归还主机线程,也就是在第一个并行代码执行时,很有可能第二段host代码已经开始同步执行了)。
5:内存管理
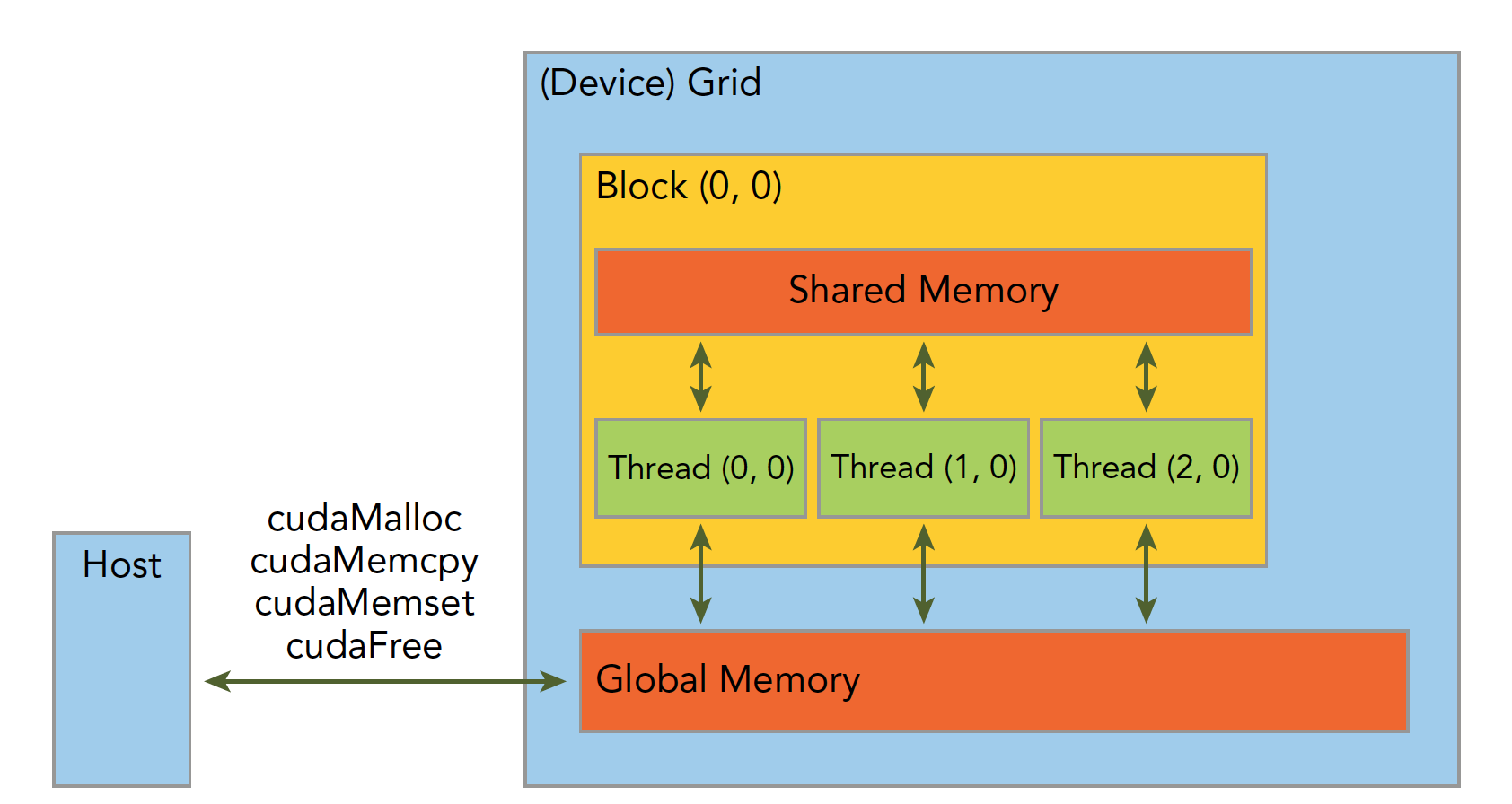
(1)Host(CPU) 通过 cudaMalloc ,cudaMemcpy,cudaMemset,cudaFree等方式与Device(GPU)进行内存管理
(2)Device空间里面有Grid,其由许多Block以及GlobalMemory组成,Grid的大小就是其包含的Block数量
(3)Block里面包含许多Thread和Shared Memory共享空间,Block大小等于其包含的线程数量
6:线程管理
(1)当内核函数开始执行,如何组织GPU的线程就变成了最主要的问题了,我们必须明确,一个核函数只能有一个grid,一个grid可以有很多个块,每个块可以有很多的线程,这种分层的组织结构使得我们的并行过程更加自如灵活:
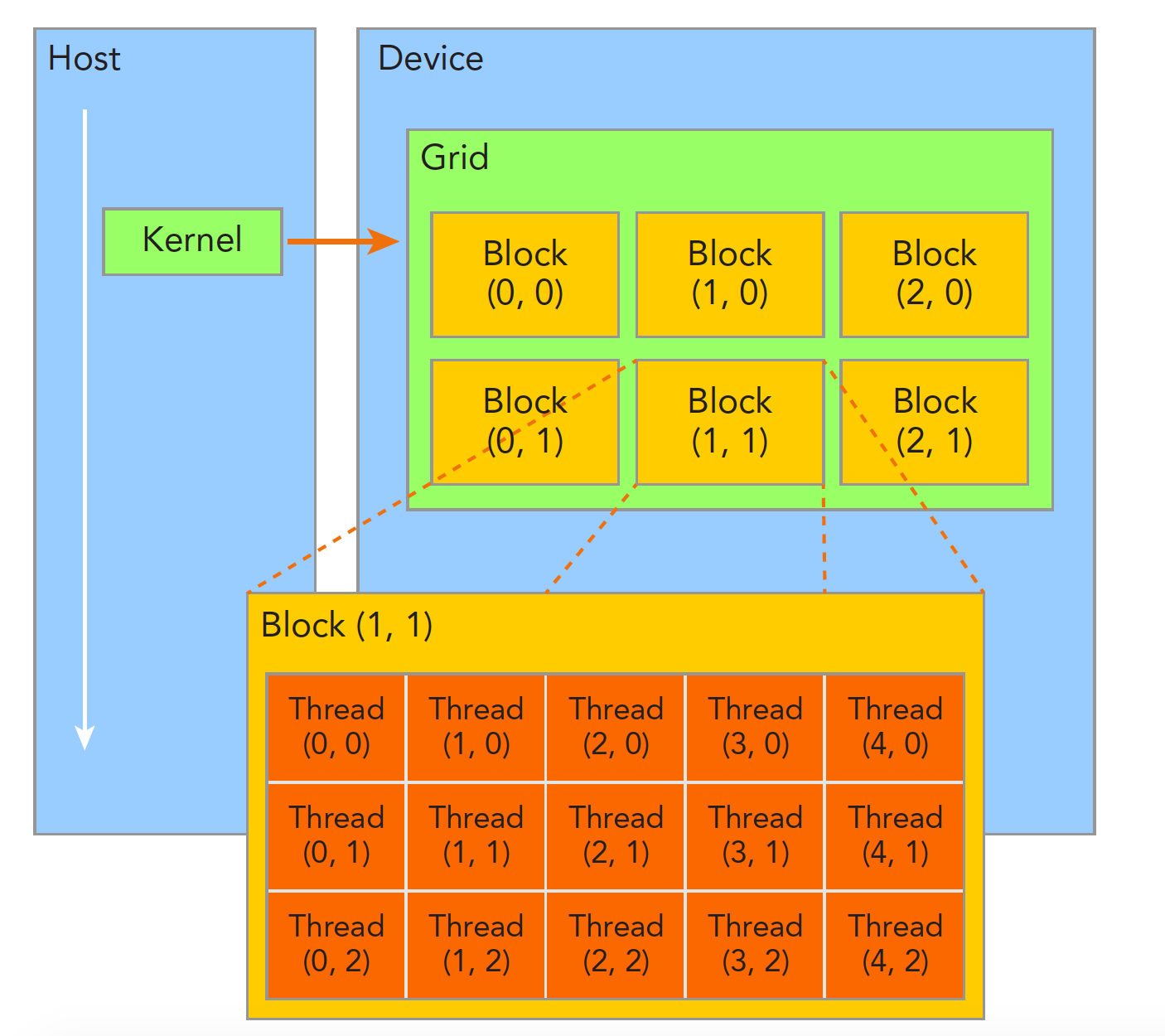
一个线程块block中的线程可以完成下述协作:
1同步
2共享内存
不同块内线程不能相互影响!他们是物理隔离的!
(2)每个线程都执行同样的一段串行代码,为了让这段相同的代码对应不同的数据,首先第一步就是让这些线程彼此区分开,才能对应到相应从线程,使得这些线程也能区分自己的数据。如果线程本身没有任何标记,那么没办法确认其行为。
依靠下面两个内置结构体确定线程标号:
blockIdx(线程块在线程网格内的位置索引)
threadIdx(线程在线程块内的位置索引)
上面这两个是坐标,当然我们要有同样对应的两个结构体来保存其范围,也就是blockIdx中三个字段的范围threadIdx中三个字段的范围:
blockDim
gridDim
7:核函数
核函数就是在CUDA模型上诸多线程中运行的那段串行代码,这段代码在设备上运行,用NVCC编译,产生的机器码是GPU的机器码,所以我们写CUDA程序就是写核函数,第一步我们要确保核函数能正确的运行产生正切的结果,第二优化CUDA程序的部分,无论是优化算法,还是调整内存结构,线程结构都是要调整核函数内的代码,来完成这些优化的。
我们一直把我们的CPU当做一个控制者,运行核函数,要从CPU发起,那么我们开始学习如何启动一个核函数
(1)核函数调用
kernel_name<<<4,8>>>(argument list);
这个三个尖括号’<<<grid,block>>>’内是对设备代码执行的线程结构的配置(或者简称为对内核进行配置)
上面这条指令的线程布局是:(4个块,每个块内分配调用8个线程)

我们的核函数是同时复制到多个线程执行的,上文我们说过一个对应问题,多个计算执行在一个数据,肯定是浪费时间,所以为了让多线程按照我们的意愿对应到不同的数据,就要给线程一个唯一的标识,由于设备内存是线性的(基本市面上的内存硬件都是线性形式存储数据的)我们观察上图,可以用threadIdx.x 和blockIdx.x 来组合获得对应的线程的唯一标识(后面我们会看到,threadIdx和blockIdx能组合出很多不一样的效果)
kernel_name<<<1,32>>>(argument list); // 调用1个块
kernel_name<<<32,1>>>(argument list);// 调用32个块