大Op和小op的含义及理解
- Stochastic order notation(随机有序符号)
- 6.1.1 O p O_p Op和 o p o_p op之间的关系
- 6.2 符号速记及其算数性质
- 6.3 为什么 o p o_p op和 O p O_p Op符号很有用?
- 6.4例子:均值估计的相合性
- 参考:
Stochastic order notation(随机有序符号)
大Op(big oh-pee),或者用代数术语记为 O p O_p Op,是用来表示随机变量序列的概率收敛的一种速记方法。
大
O
p
O_p
Op意味着,某些给定的随机变量是随机有界的。若
X
n
X_n
Xn为某个随机变量,
a
n
a_n
an表示某些常数,其中n表示序列的索引符号,则
X
n
=
O
p
(
a
n
)
X_n=O_p(a_n)
Xn=Op(an)
等同于说,
P
(
∣
X
n
a
n
∣
>
δ
)
<
ϵ
,
∀
n
>
N
P(|\frac{X_n}{a_n}|>\delta)<\epsilon, \forall n>N
P(∣anXn∣>δ)<ϵ,∀n>N.
其中 δ \delta δ和 N N N是有限的数, ϵ \epsilon ϵ是某个任意(小)的数。 O p O_p Op意味着当 n n n足够大时,存在某个数( δ \delta δ)使得随机变量 X n a n \frac{X_n}{a_n} anXn大于 δ \delta δ的概率基本为0.它是“bounded in probability”(可能翻译为:依概率有界)(Vaart 1998, sec.2.2).
小
o
p
o_p
op(little oh_pee)是指依概率收敛到0。
X
n
=
o
p
(
1
)
X_n=o_p(1)
Xn=op(1)
等同于说,
lim
n
→
∞
P
(
∣
X
n
∣
≥
ϵ
)
=
0
,
∀
ϵ
>
0.
\lim_{n\rightarrow \infty} P(|X_n|\geq\epsilon)=0,\forall \epsilon>0.
n→∞limP(∣Xn∣≥ϵ)=0,∀ϵ>0.
根据
o
p
o_p
op的定义,如果
X
n
=
o
p
(
a
n
)
X_n=o_p(a_n)
Xn=op(an),则
X
n
a
n
=
o
p
(
1
)
.
\frac{X_n}{a_n}=o_p(1).
anXn=op(1).反过来,我们可以将
X
n
=
o
p
(
a
n
)
X_n=o_p(a_n)
Xn=op(an)表示为
lim
n
→
∞
P
(
∣
X
n
a
n
∣
≥
ϵ
)
=
0
,
∀
ϵ
>
0.
\lim_{n\rightarrow\infty}P(|\frac{X_n}{a_n}|\geq\epsilon)=0, \forall\epsilon>0.
n→∞limP(∣anXn∣≥ϵ)=0,∀ϵ>0.
换句话说,
X
n
=
o
p
(
a
n
)
X_n=o_p(a_n)
Xn=op(an)当且仅当
X
n
a
n
⟶
p
0.
\frac{X_{n}}{a_n} \stackrel{p}{\longrightarrow}0.
anXn⟶p0.
6.1.1 O p O_p Op和 o p o_p op之间的关系
看上去
O
p
O_p
Op和
o
p
o_p
op很像,那是因为它们确实很像!
另一种表达
X
n
=
O
p
(
a
n
)
X_n=O_p(a_n)
Xn=Op(an)的方式是通过数学语言,即
∀
ϵ
>
0
,
∃
N
ϵ
,
δ
ϵ
,
s
.
t
.
∀
n
>
N
ϵ
,
P
(
∣
X
n
a
n
∣
≥
δ
ϵ
)
≤
ϵ
.
\forall \epsilon>0,\exists N_{\epsilon},\delta_{\epsilon}, s.t. \forall n>N_\epsilon, P(|\frac{X_n}{a_n}|\geq\delta_\epsilon)\leq\epsilon.
∀ϵ>0,∃Nϵ,δϵ,s.t.∀n>Nϵ,P(∣anXn∣≥δϵ)≤ϵ.
上述这种数学语言表达形式清楚地表明, N N N和 δ \delta δ的选择与 ϵ \epsilon ϵ有关,即对于每个 ϵ \epsilon ϵ,可以在该 ϵ \epsilon ϵ下,找到满足上述不等式的 N N N和 δ \delta δ。不同的 ϵ \epsilon ϵ下, N N N和 δ \delta δ值可以是不同的。
同样,我们可以使用相同的数学语言表示
X
n
=
o
p
(
a
n
)
X_n=o_p(a_n)
Xn=op(an),即
∀
ϵ
,
δ
,
∃
N
ϵ
,
δ
,
s
.
t
.
∀
n
>
N
ϵ
,
δ
,
P
(
∣
X
n
a
n
∣
≥
δ
)
≤
ϵ
.
\forall \epsilon, \delta, \exists N_{\epsilon, \delta}, s.t. \forall n>N_{\epsilon,\delta}, P(|\frac{X_n}{a_n}|\geq\delta)\leq \epsilon.
∀ϵ,δ,∃Nϵ,δ,s.t.∀n>Nϵ,δ,P(∣anXn∣≥δ)≤ϵ.
因此,从上述关于 O p O_p Op和 o p o_p op的数学语言表达可以看出, o p o_p op是一个更general的说法,因为 o p o_p op涵盖了(1) ϵ \epsilon ϵ和 δ \delta δ所有值,以及(2) ϵ \epsilon ϵ和 δ \delta δ的任意组合。此外,通过上述数学语言表达可以看出, o p ( a n ) o_p(a_n) op(an)蕴含着 O p ( a n ) O_p(a_n) Op(an),即如果 X n = o p ( a n ) X_n=o_p(a_n) Xn=op(an),那么一定有 X n = O p ( a n ) X_n=O_p(a_n) Xn=Op(an)。因为,根据 o p o_p op的数学语言表达,对于任意的 ϵ \epsilon ϵ和 δ \delta δ都可以找到满足上述不等式的 N N N,那么对任意的 ϵ \epsilon ϵ,可以从上述任意的 δ \delta δ中找到要给 δ \delta δ以及 N N N,使得有不等式成立。但是,仅仅对某个 δ \delta δ有不等式成立,这不意味着对所有的 δ \delta δ,不等式都成立。
6.2 符号速记及其算数性质
像 X n = o p ( 1 ( n ) ) X_n=o_p(\frac{1}{\sqrt(n)}) Xn=op((n)1)的表达不包含任意的文字。 O p O_p Op和 o p o_p op只是用来表达随机变量序列如何收敛(要么收敛到一个bound,要么收敛到0)。
例如,假设 X n = o p ( 1 n ) X_n=o_p(\frac{1}{n}) Xn=op(n1),因此我们也直到 X n = o p ( 1 n 0.5 ) X_n=o_p(\frac{1}{n^{0.5}}) Xn=op(n0.51).类似的,想象一个物体以至少10 m s − 2 ms^{-2} ms−2的速度加速,那辆车也在以至少 5 m s − 2 5ms^{-2} 5ms−2.但是,并不是说 o p 1 n = o p ( 1 n 0.5 ) o_p{\frac{1}{n}}=o_p(\frac{1}{n^{0.5}}) opn1=op(n0.51).例如,加速至少5 m s − 2 ms^{-2} ms−2的汽车不一定加速至少10 m s − 2 ms^{-2} ms−2。
因此,当我们使用这些随机顺序符号时(stochastic order notation,准确的翻译没有查),我们应该认为这些 o p o_p op和 O p O_p Op意味着什么,而不是说随机变量序列或者包含随机变量的表达式等于某个 o p o_p op和 O p O_p Op.
下面给出 O p O_p Op与 o p o_p op组合项的含义:
- o p ( 1 ) + o p ( 1 ) = o p ( 1 ) o_p(1)+o_p(1)=o_p(1) op(1)+op(1)=op(1):这两项都是以相同的速率收敛到0,那么其和以该速率收敛到0. 注意到,这是连续映射定理(continuous mapping theorem)的一个简单应用。因为,如果 X n = o p ( 1 ) , Y n = o p ( 1 ) X_n=o_p(1),Y_n=o_p(1) Xn=op(1),Yn=op(1),则 X n ⟶ 0 p , Y n ⟶ 0 p X_n\stackrel{p}{\longrightarrow 0},Y_n\stackrel{p}{\longrightarrow 0} Xn⟶0p,Yn⟶0p,则由两项的相加是一个连续映射函数,因此, X n + Y n ⟶ p 0 X_n+Y_n\stackrel{p}{\longrightarrow}0 Xn+Yn⟶p0,所以 X n + Y n = o p ( 1 ) . X_n+Y_n=o_p(1). Xn+Yn=op(1).
- O p ( 1 ) + o p ( 1 ) = O p ( 1 ) O_p(1)+o_p(1)=O_p(1) Op(1)+op(1)=Op(1):一个依概率有界的项 加上 依概率收敛到0的项,等于依概率有界。
- O p ( 1 ) o p ( 1 ) = o p ( 1 ) O_p(1)o_p(1)=o_p(1) Op(1)op(1)=op(1):一个依概率有界的项 乘以 (以相同顺序)依概率收敛到0的项等于依概率收敛到0.
- o p ( R ) = R × o p ( 1 ) o_p(R)=R\times o_{p}(1) op(R)=R×op(1):这很容易看出,因为如果 X n = o p ( R ) X_n=o_{p}(R) Xn=op(R),则 X n / R = o p ( 1 ) X_n/R=o_p(1) Xn/R=op(1),因此, X n = R o p ( 1 ) X_{n}=Ro_{p}(1) Xn=Rop(1).
进一步的规则和对其有效性的直观解释可以在Vaart (1998)的第2.2节中找到。
然而,上述最后一条规则值得简单的讨论以下,因为它清楚的说明了,为什么我们在 o p o_{p} op算子中使用不同的速度rate项R。
考虑两个速度rate R ( 1 ) = 1 ( n ) R^{(1)}=\frac{1}{\sqrt(n)} R(1)=(n)1, R ( 2 ) = 1 2 1 3 R^{(2)}=\frac{1}{2^{\frac{1}{3}}} R(2)=2311,随机变量序列 Y n ⟶ 0 p Y_n\stackrel{p}{\longrightarrow 0} Yn⟶0p,即 Y n = o p ( 1 ) Y_n=o_p(1) Yn=op(1).
根据上述最后一条性质,并且我们要时刻记住,其中等号不应该按照字面意思来理解。
若
X
n
(
1
)
=
o
p
(
R
(
1
)
)
X_n^{(1)}=o_p(R^{(1)})
Xn(1)=op(R(1)),则
X
n
(
1
)
=
1
n
×
Y
n
,
X_{n}^{(1)}=\frac{1}{\sqrt{n}}\times Y_n,
Xn(1)=n1×Yn,
若
X
n
(
2
)
=
o
p
(
R
(
2
)
)
X_n^{(2)}=o_p(R^{(2)})
Xn(2)=op(R(2)),则
X
n
(
2
)
=
1
n
1
3
×
Y
n
,
X_{n}^{(2)}=\frac{1}{n^{\frac{1}{3}}}\times Y_n,
Xn(2)=n311×Yn,
当 n n n趋于无穷时,对于 Y n Y_n Yn的每个值, X n ( 1 ) X_n^{(1)} Xn(1)比 X n ( 2 ) X_n^{(2)} Xn(2)小,换句话说, X n ( 1 ) X_n^{(1)} Xn(1)收敛于0的速度更快。
6.3 为什么 o p o_p op和 O p O_p Op符号很有用?
这里我们通过一个简单的例子对此进行说明。考虑一个随机变量序列 X n X_n Xn,其期望为 E ( X n ) = X E(X_n)=X E(Xn)=X,因此 X n = X + o p ( 1 ) X_n=X+o_p(1) Xn=X+op(1),根据弱大数定律(weak law of large numbers)知 X n ⟶ X p X_n\stackrel{p}{\longrightarrow X} Xn⟶Xp。这是非常有用的,因为我们不必在方程中引入明确的极限,在 X n = X + o p ( 1 ) X_n=X+o_p(1) Xn=X+op(1)中的第二项收敛于零,因此我们可以忽略它。
考虑一个更有意义的例子。若
X
n
∼
N
(
0
,
n
)
X_n\sim N(0,n)
Xn∼N(0,n)。根据正态分布的性质知,
X
n
(
n
)
∼
N
(
0
,
1
)
\frac{X_n}{\sqrt(n)}\sim N(0,1)
(n)Xn∼N(0,1)
存在某个
M
M
M使得从
N
(
0
,
1
)
N(0,1)
N(0,1)中生成的某个数超过
M
M
M的概率小于
ϵ
>
0
\epsilon>0
ϵ>0,因此
X
n
=
O
p
(
(
n
)
)
X_n=O_p(\sqrt(n))
Xn=Op((n))
同时 X n = o p ( n ) X_n=o_p(n) Xn=op(n)。
下面我们证明 X n = o p ( n ) X_n=o_p(n) Xn=op(n)。
由于
X
n
n
∼
N
(
0
,
n
n
2
)
=
N
(
0
,
1
n
)
\frac{X_n}{n}\sim N(0,\frac{n}{n^2})=N(0,\frac{1}{n})
nXn∼N(0,n2n)=N(0,n1)
我们只需要证明 N ( 0 , 1 n ) = o p ( 1 ) N(0,\frac{1}{n})=o_{p}(1) N(0,n1)=op(1)即可,这样有 X n n = o p ( 1 ) \frac{X_n}{n}=o_p(1) nXn=op(1),进而 X n = n o p ( 1 ) = o p ( n ) X_n=no_p(1)=o_p(n) Xn=nop(1)=op(n)。
注意到
P
(
∣
N
(
0
,
1
n
)
∣
>
ϵ
)
=
P
(
1
(
n
)
∣
N
(
0
,
1
)
∣
>
ϵ
)
=
P
(
∣
N
(
0
,
1
)
∣
>
(
n
)
ϵ
)
⟶
0
p
P(|N(0,\frac{1}{n})|>\epsilon)=P(\frac{1}{\sqrt(n)}|N(0,1)|>\epsilon)=P(|N(0,1)|>\sqrt(n)\epsilon)\stackrel{p}{\longrightarrow 0}
P(∣N(0,n1)∣>ϵ)=P((n)1∣N(0,1)∣>ϵ)=P(∣N(0,1)∣>(n)ϵ)⟶0p
最后一项成立,是因为 ( n ) → ∞ \sqrt(n)\rightarrow \infty (n)→∞,故来自标准正态分布的数大于∞的概率降低到0,因此 X n = o p ( n ) X_n=o_p(n) Xn=op(n)
使用大O和小o表示,捕捉了方程的复杂性,或者等价地捕捉了方程收敛的速度。一种理解 X n = o p ( a n ) X_n=o_p(a_n) Xn=op(an)的方式是, X n X_n Xn通过由 a n a_n an确定的速度收敛到0。例如, o p ( a n 2 ) o_p(a_n^2) op(an2)的收敛速度比 o p ( a n ) o_p(a_n) op(an)快,因为对随机变量序列 X n X_n Xn, X n a n 2 < X n a n , n > 1 \frac{X_n}{a_n^2}<\frac{X_n}{a_n},n>1 an2Xn<anXn,n>1.
当我们想要计算一个更复杂的方程的渐近极限时,其中多个项受到观测个数(即样本量)的影响。如果我们有一个项比其他项更快的依概率收敛到0,那么我们完全可以忽略这个项。
6.4例子:均值估计的相合性
如果一个参数的估计量,随着样本量n的增加,参数的估计量依概率收敛到一个参数,则该估计量是“相合的”(consistent)。更正式的表示为,一个参数估计
θ
^
\hat{\theta}
θ^是相合估计,若
P
(
∣
θ
^
−
θ
∣
≥
ϵ
)
⟶
0
p
P(|\hat{\theta}-\theta|\geq\epsilon)\stackrel{p}{\longrightarrow 0}
P(∣θ^−θ∣≥ϵ)⟶0p
其中
θ
\theta
θ是参数真值。
一个感兴趣的问题:我们的这个相合估计向参数真值收敛的速度如何。这个一个“应用”方法的问题,为寻求对参数真值进行推断,对这个参数,我们可能得到许多不同的估计量,我么希望从中挑选一个有效的估计量,即一个能最快达到参数真值的估计量。
假如我们想要估计 X X X的总体均值,即 X ˉ \bar{X} Xˉ。此时我们有两个潜在的估计量,样本均值 1 N ∑ i = 1 N X i \frac{1}{N}\sum_{i=1}^{N}X_{i} N1∑i=1NXi,中位数 X ( N + 1 ) / 2 X_{(N+1)/2} X(N+1)/2,其中 N = 2 n + 1 N=2n+1 N=2n+1.(为了便于计算,我们假设样本量N为奇数),X是从小到大的有序序列。
由中心极限定理知,样本均值
X
ˉ
N
∼
N
(
0
,
δ
2
N
)
\bar{X}_N\sim N(0,\frac{\delta^2}{N})
XˉN∼N(0,Nδ2)
不需要证明可以给出,中位数估计量的大样本分布可以近似地表示为:
M
e
d
(
X
1
,
X
2
,
⋯
,
X
N
)
∼
N
(
θ
,
π
δ
2
2
N
)
Med(X_{1},X_{2},\cdots,X_{N})\sim N(\theta,\frac{\pi\delta^2}{2N})
Med(X1,X2,⋯,XN)∼N(θ,2Nπδ2).
这些估计量在实践中表现如何?我们通过蒙特卡洛模拟来进行说明。通过模拟,我们可以绘制上述两个估计量的最终分布。
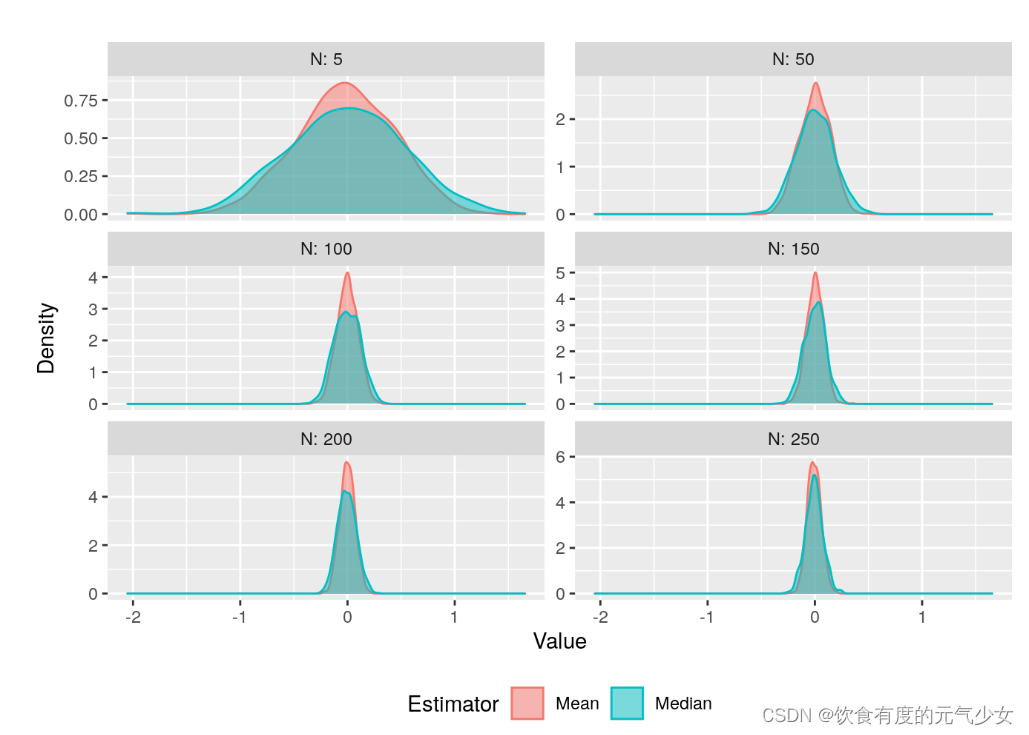
从图中我们可以看到,这两个估计量都是服从正态分布,样本均值分布的方差比样本中位数估计量的方差收缩的快,也就是说,样本中位数估计量的方差比样本均值的方差大,从图中我们可以看到,绿色(表示中位数估计量)图像是扁平的,红色(均值估计量)是瘦长的,红色取值相对较集中,绿色取值相对较分散,说明绿色的方差大。换句话说,红色的估计更有效。这里的有效性体现了我们在数学上提到的,样本均值收敛到参数真值的收敛速度比中位数估计量收敛到参数真值的收敛速度快!
值得注意的是,上述两个估计量都是无偏估计,都是服从正态分布,并且都是相合估计(随着样本量的增加,估计量向参数真值收敛),但是方差缩小的速度略有不同。
我们可以使用 o p o_p op符号在大样本下,对这些估计量进行刻画。
首先,我们定义均值估计的估计误差和中位数估计的估计误差,即
ψ
M
e
a
n
=
θ
^
−
θ
=
N
(
0
,
δ
2
N
)
−
N
(
θ
,
0
)
=
N
(
0
,
δ
2
N
)
.
\psi_{Mean}=\hat{\theta}-\theta=N(0,\frac{\delta^2}{N})-N(\theta,0)=N(0,\frac{\delta^2}{N}).
ψMean=θ^−θ=N(0,Nδ2)−N(θ,0)=N(0,Nδ2).
ψ M e d = N ( θ , π δ 2 2 N ) − N ( θ , 0 ) = N ( 0 , π δ 2 2 N ) . \psi_{Med}=N(\theta,\frac{\pi\delta^2}{2N})-N(\theta,0)=N(0,\frac{\pi\delta^2}{2N}). ψMed=N(θ,2Nπδ2)−N(θ,0)=N(0,2Nπδ2).
从上面的表达式中,我们可以看到,估计量的估计误差以0为中心,估计量是无偏的。
根据本章前面的讨论,我们可以对上述两个估计量重新进行改写,以找出这两个估计量的收敛到参数真值的速度。
ψ
M
e
a
n
=
1
(
N
)
N
(
0
,
δ
2
)
\psi_{Mean}=\frac{1}{\sqrt(N)}N(0,\delta^2)
ψMean=(N)1N(0,δ2)
ψ
M
e
a
n
N
−
0.5
=
N
(
0
,
δ
2
)
.
\frac{\psi_{Mean}}{N^{-0.5}}=N(0,\delta^{2}).
N−0.5ψMean=N(0,δ2).
我们知道,对于一个正态分布,存在某个
M
ϵ
M_{\epsilon}
Mϵ和
N
ϵ
N_{\epsilon}
Nϵ,使得
P
(
∣
N
(
0
,
δ
2
)
∣
≥
M
ϵ
<
ϵ
)
P(|N(0,\delta^2)|\geq M_{\epsilon}<\epsilon)
P(∣N(0,δ2)∣≥Mϵ<ϵ),
因此,
ψ
M
e
a
n
=
O
p
(
1
(
N
)
)
.
\psi_{Mean}=O_{p}(\frac{1}{\sqrt(N)}).
ψMean=Op((N)1).
类似的,对于样本中位数:
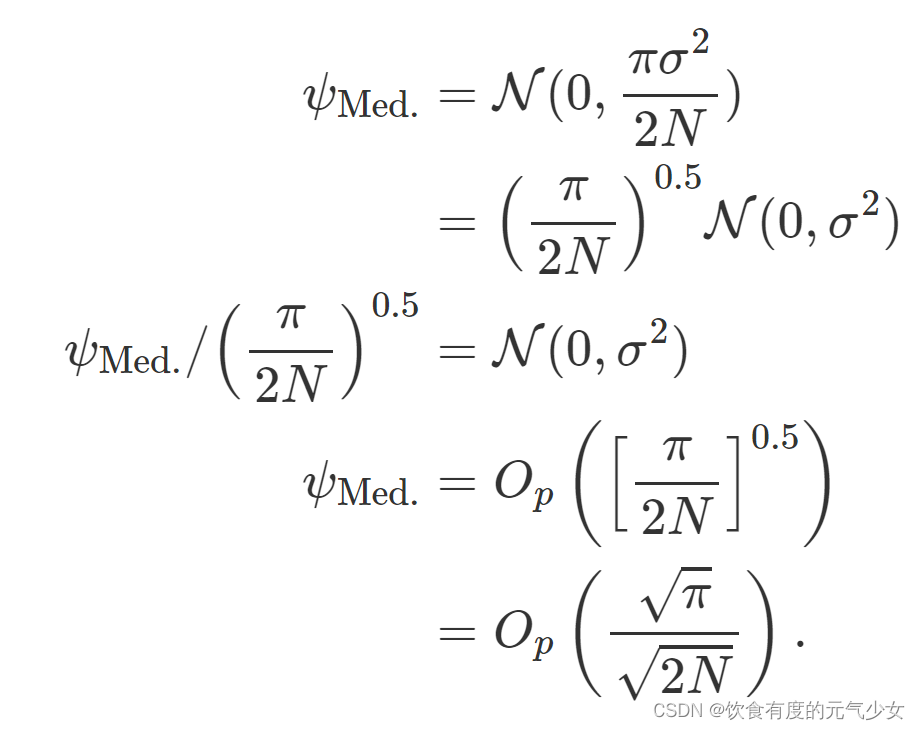
因此,我们可以看到
ψ
M
e
d
\psi_{Med}
ψMed比
ψ
M
e
a
n
\psi_{Mean}
ψMean要慢,意味着Mean比Med需要更少的样本量就可以收敛到参数真值。
参考:
https://bookdown.org/ts_robinson1994/10_fundamental_theorems_for_econometrics/big-op-and-little-op.html