Hadoop是什么
Hadoop是一个分布式系统基础架构
主要解决海量数据的存储和分析计算问题
Hadoop优势–4高
高可靠性:Hadoop底层维护多个数据版本,单个计算元素或存储故障也不会导致数据丢失
高扩展性:在集群中分配任务数据,可以方便的扩展数以千计的节点
高效性:在MapReduce思想下,Hadoop是并行的
高容错性:能够自动将失败任务重新分配
版本变化
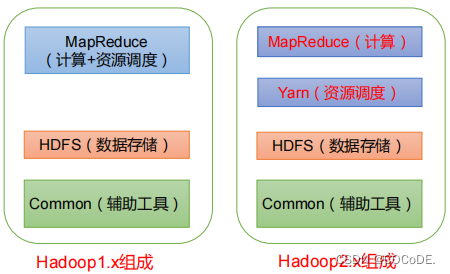
Hadoop1.x中MapReduce同时处理业务逻辑运算和资源调度,耦合性较大
Hadoop2.x和Hadoop3.x增加了Yarn,Yarn只负责资源调度,MapReduce只负责运算
HDFS架构
HDFS:Hadoop Distributed File System Hadoop分布式文件系统
NameNode(nn)名字节点:存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等
DataNode(dn)数据节点:在本地文件系统存储文件块数据,以及块数据的校验和
Secondary NameNode(2nn)次名字节点:每隔一段时间对NameNode元数据备份
分布式文件系统将集群看成一个整体,忽略节点之间的连接,直接当作一个整体看待。
而将不同的节点组成的集群当作一个整体看待的实现方式就是hdfs架构,通过nn管理dn的元数据,例如dn存储的文件的命名空间等,从而可以通过命名空间像一层一层的文件夹一样把所有文件看成一个有逻辑的文件整体
YARN架构
YARN:Yet Another Negotiator,另一种资源协调者,Hadoop的资源管理器
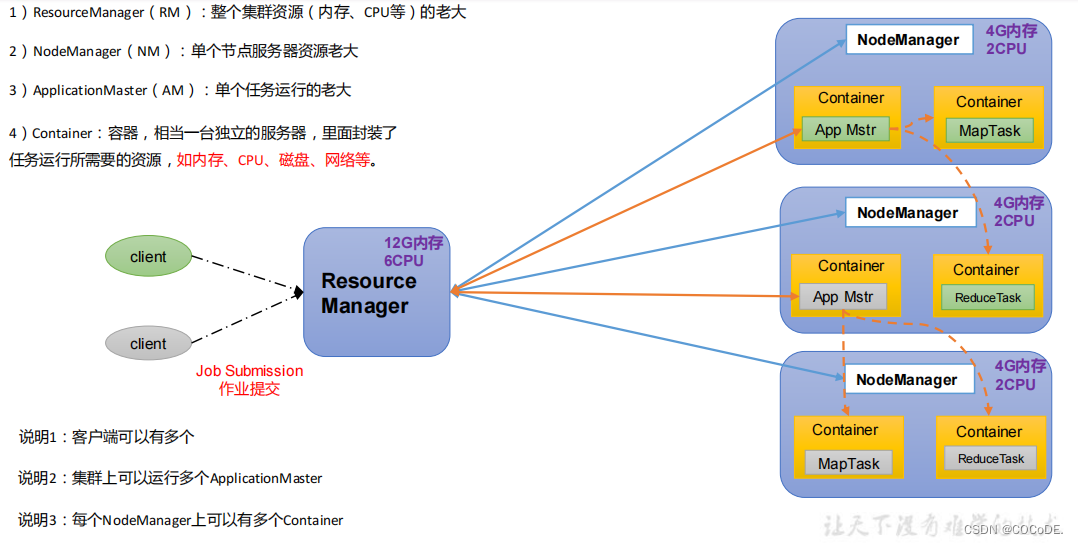
- ResourceManager(rm):资源管理者,协调整个集群资源
- NodeManager(nm):节点管理者,协调单个服务器节点资源
- ApplicationMaster(am):任务管理者,单个任务的管理者
- Container:容器,相当于一台独立的机器,封装了任务运行所需的内存 CPU 磁盘 网络等资源
MapReduce流程
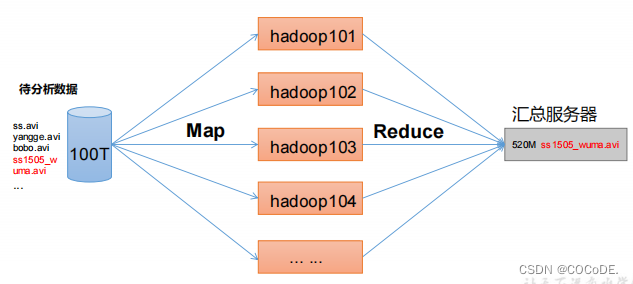
MapReduce将计算过程分为两个阶段Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
HDFS、YARN、MapReduce三者关系
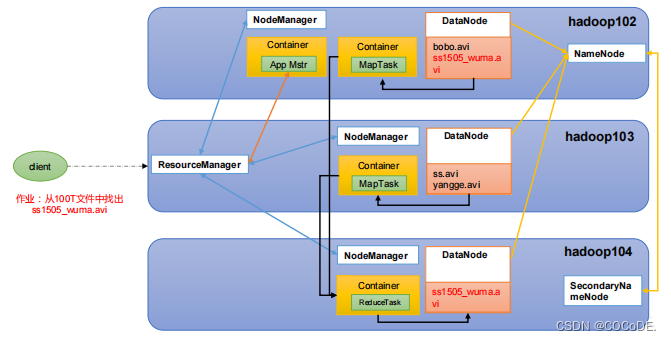
流程
Client->RM->找一个NM生成Container,生成AM->AM找RM申请机器资源->生成两个MapTask的Container->MapTask的Container查找自己所在节点的信息,并且生成返回值->一个ReduceTask节点接收所有MapTask节点的信息并且汇总,写在一个DN上,再由DN去写在NN上和2NN上
Hadoop重要目录
- bin 服务脚本:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc 配置文件:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 本地库:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 启停脚本:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
Hadoop运行模式
- 本地模式:单机运行
- 伪分布式模式:单机模拟分布式环境,具备Hadoop集群全部功能
- 完全分布式模式:多台服务器组成的真实的分布式环境
------笔记来自尚硅谷课件的自学
![CodeForces.1806A .平面移动.[判断可达范围][找步数规律]](https://img-blog.csdnimg.cn/37cf21f553ea41b3bf64ff6d7b864175.png)