目录
0 管线
8 着色器
9 固定功能
10 渲染通道
结论
0 管线
我们将设置一个图形管道,并将其配置为绘制我们的第一个三角形。图形管道是将网格的顶点和纹理一直带到渲染目标中的像素的操作序列。
带有绿色的阶段被称为固定功能阶段。这些阶段允许你使用参数来调整它们的操作,但它们的工作方式是预定义的。另一方面,橙色的阶段是 “可编程”的。
Vulkan的图形管道几乎是完全不可改变的,所以如果你想改变着色器、绑定不同的帧缓冲器或改变混合功能,你必须从头开始重新创建管道。
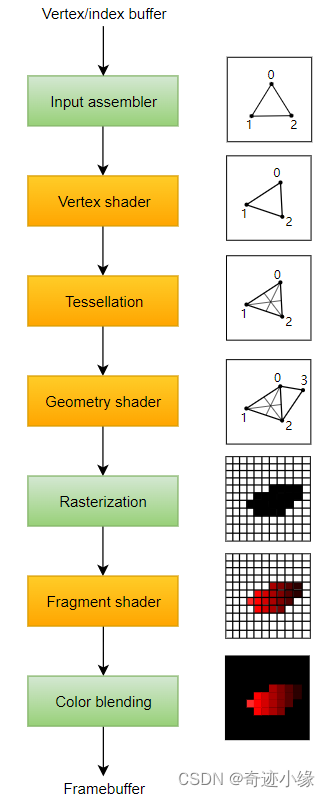
顶点着色器处理每个进入的顶点。它将其属性,如世界位置、颜色、法线和纹理坐标作为输入。输出是片段坐标的最终位置,以及需要传递给片段着色器的属性,如颜色和纹理坐标。
创建一个createGraphicsPipeline函数,在initVulkan'中createImageViews`之后立即调用。
8 着色器
GLSL是一种具有C风格语法的着色语言。用它编写的程序有一个main函数,每个对象都会被调用。GLSL使用全局变量来处理输入和输出,而不是使用参数作为输入,返回值作为输出。
在你项目的根目录下创建一个名为 shaders 的目录,将顶点着色器存储在名为 shader.vert 的文件中,将片段着色器存储在名为 shader.frag 的文件中。GLSL着色器没有一个官方的扩展名,但这两个通常用来区分它们。
#version 450
layout(location = 0) out vec3 fragColor;
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}shader.frag的内容应该是:
#version 450
layout(location = 0) in vec3 fragColor;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragColor, 1.0);
}我们现在要用
glslc程序将这些编译成SPIR-V字节码。Windows创建一个
compile.bat文件,内容如下:C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.vert -o vert.spv C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.frag -o frag.spv pause 这两条命令告诉编译器读取GLSL源文件,并使用-o(输出)标志输出一个SPIR-V字节码文件。将
glslc.exe的路径替换为你安装Vulkan SDK的路径。双击该文件来运行它。
加载一个着色器
现在我们已经有了制作SPIR-V着色器的方法,是时候把它们加载到我们的程序中,以便在某个时候把它们插入到图形管道中。我们首先要写一个简单的辅助函数,从文件中加载二进制数据。
#include <fstream>
...
//readFile 函数将从指定的文件中读取所有的字节,并在一个由 std::vector管理的字节数组中返回这些字节
static std::vector<char> readFile(const std::string& filename) {
std::ifstream file(filename, std::ios::ate | std::ios::binary);
//ate: 从文件的末端开始读取
//binary: 将文件作为二进制文件读取(避免文本转换)
if (!file.is_open()) {
throw std::runtime_error("failed to open file!");
}
//在文件末尾开始读取的好处是,我们可以使用读取位置来确定文件的大小并分配一个缓冲区
size_t fileSize = (size_t) file.tellg();
std::vector<char> buffer(fileSize);
//之后,我们可以寻回文件的开头,一次性读取所有的字节:
file.seekg(0);
file.read(buffer.data(), fileSize);
//最后关闭文件并返回字节。
file.close();
return buffer;创建着色器模块
在我们将代码传递给流水线之前,我们必须将其包裹在一个VkShaderModule对象中。让我们创建一个辅助函数createShaderModule来完成这个任务。
VkShaderModule createShaderModule(const std::vector<char>& code) {
//该函数将接收一个带有字节码的缓冲区作为参数,并从中创建一个VkShaderModule。
VkShaderModuleCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
//只需要指定一个带有字节码的缓冲区的指针和它的长度
createInfo.codeSize = code.size();
createInfo.pCode = reinterpret_cast<const uint32_t*>(code.data());
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
throw std::runtime_error("failed to create shader module!");
}
return shaderModule;
}有一个问题是字节码的大小是以字节为单位的,但是字节码的指针是一个
uint32_t的指针,而不是char的指针。因此,我们需要用reinterpret_cast来铸造这个指针
着色器模块只是对我们之前从文件中加载的着色器字节码和其中定义的函数的一个简单的包装。SPIR-V字节码的编译和链接到机器代码,以便由GPU执行,这在图形管道创建之前不会发生。我们可以在管道创建完成后再次销毁着色器模块,这就是为什么我们要在createGraphicsPipeline函数中把它们变成局部变量而不是类成员
我们可以在管道创建完成后再次销毁着色器模块,这就是为什么我们要在createGraphicsPipeline函数中把它们变成局部变量而不是类成员,现在我们将从createGraphicsPipeline中调用这个函数来加载两个着色器的字节码:
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
VkShaderModule vertShaderModule = createShaderModule(vertShaderCode);
VkShaderModule fragShaderModule = createShaderModule(fragShaderCode);
...
//为了实际使用这些着色器,我们需要通过结构将它们分配到一个特定的流水线阶段
VkPipelineShaderStageCreateInfo vertShaderStageInfo{};
//首先填写顶点着色器
vertShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
vertShaderStageInfo.stage = VK_SHADER_STAGE_VERTEX_BIT;
vertShaderStageInfo.module = vertShaderModule;
vertShaderStageInfo.pName = "main";
VkPipelineShaderStageCreateInfo fragShaderStageInfo{};
fragShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
fragShaderStageInfo.stage = VK_SHADER_STAGE_FRAGMENT_BIT;
fragShaderStageInfo.module = fragShaderModule;
fragShaderStageInfo.pName = "main";
//定义一个包含这两个结构的数组,以后我们将在实际的管道创建步骤中用来引用它们。
VkPipelineShaderStageCreateInfo shaderStages[] = {vertShaderStageInfo, fragShaderStageInfo};
vkDestroyShaderModule(device, fragShaderModule, nullptr);
vkDestroyShaderModule(device, vertShaderModule, nullptr);
}9 固定功能
旧的图形API为图形管道的大部分阶段提供了默认状态。在Vulkan中,你必须明确从视口大小到颜色混合功能的一切。
顶点输入
VkPipelineVertexInputStateCreateInfo结构描述了将传递给顶点着色器的顶点数据的格式。它大致以两种方式描述。
- 绑定:数据之间的间距以及数据是逐顶点还是逐实例(参见 实例)
- 属性描述:传递给顶点着色器的属性的类型,从哪个绑定加载它们以及在哪个偏移量
VkPipelineVertexInputStateCreateInfo vertexInputInfo{};
vertexInputInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO;
vertexInputInfo.vertexBindingDescriptionCount = 0;
vertexInputInfo.pVertexBindingDescriptions = nullptr; // Optional
vertexInputInfo.vertexAttributeDescriptionCount = 0;
vertexInputInfo.pVertexAttributeDescriptions = nullptr; // Optional
//在顶点着色器中对顶点数据进行了硬编码,所以我们将在这个结构中指定暂时没有顶点数据需要加载输入装配
VkPipelineInputAssemblyStateCreateInfo结构描述了两件事:将从顶点绘制什么样的几何图形,以及是否应启用原始重启。前者是在topology成员中指定的,可以有以下值:
VK_PRIMITIVE_TOPOLOGY_POINT_LIST: 从顶点输入的点VK_PRIMITIVE_TOPOLOGY_LINE_LIST: 每2个顶点的线,不重复使用VK_PRIMITIVE_TOPOLOGY_LINE_STRIP: 每一行的结束顶点被用作下一行的起始顶点。VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST: 从每3个顶点出发的三角形,不重复使用VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP: 每个三角形的第二个和第三个顶点被用作下一个三角形的前两个顶点。
通常情况下,顶点是按索引顺序从顶点缓冲区加载的,但是有了元素缓冲区,你可以自己指定要使用的索引。这使你可以进行优化,比如重复使用顶点。如果你将
primitiveRestartEnable成员设置为VK_TRUE,那么在_STRIP拓扑模式下,可以通过使用0xFFFF或0xFFFF的特殊索引来分解线条和三角形。
VkPipelineInputAssemblyStateCreateInfo inputAssembly{};
inputAssembly.sType = VK_STRUCTURE_TYPE_PIPELINE_INPUT_ASSEMBLY_STATE_CREATE_INFO;
inputAssembly.topology = VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST;
inputAssembly.primitiveRestartEnable = VK_FALSE;视口和剪切
视口基本上描述了输出将被渲染到的framebuffer的区域。这几乎总是(0,0)到(width, height)
VkViewport viewport{};
viewport.x = 0.0f;
viewport.y = 0.0f;
//交换链及其图像的大小可能与窗口的WIDTH和HEIGHT不同。
//交换链的图像以后将被用作帧缓冲器,所以我们应该坚持它们的尺寸。
viewport.width = (float) swapChainExtent.width;
viewport.height = (float) swapChainExtent.height;
//minDepth和maxDepth值指定了用于帧缓冲区的深度值范围。这些值必须在[0.0f, 1.0f]范围内
//
viewport.minDepth = 0.0f;
viewport.maxDepth = 1.0f;
//只想在整个帧缓冲区内作画,所以我们将指定一个完全覆盖它的剪切矩形
VkRect2D scissor{};
scissor.offset = {0, 0};
scissor.extent = swapChainExtent;
//将这个视口和剪切形矩形组合成一个视口状态
VkPipelineViewportStateCreateInfo viewportState{};
viewportState.sType = VK_STRUCTURE_TYPE_PIPELINE_VIEWPORT_STATE_CREATE_INFO;
viewportState.viewportCount = 1;
viewportState.pViewports = &viewport;
viewportState.scissorCount = 1;
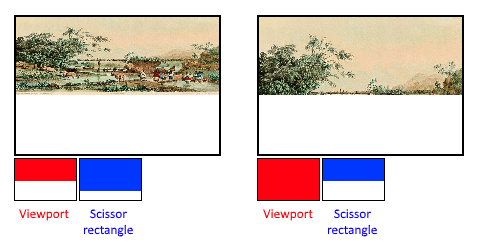
viewportState.pScissors = &scissor;视口定义了从图像到帧缓冲区的转换,但剪切矩形:定义了像素将被实际存储在哪些区域。剪切矩形之外的任何像素都会被光栅化器丢弃。它们的功能就像一个过滤器,而不是一个转换。区别如下图所示。请注意,左边的剪刀矩形只是产生该图像的众多可能性之一,只要它大于视口就可以了。
光栅化
光栅化从顶点着色器中获取由顶点塑造的几何体,并将其转化为片段,由片段着色器进行着色。它还执行depth testing、face culling和scissor test,并且它可以被配置为输出填充整个多边形或仅填充边缘的片段(wireframe rendering)。所有这些都是通过VkPipelineRasterizationStateCreateInfo结构配置的。
VkPipelineRasterizationStateCreateInfo rasterizer{};
rasterizer.sType = VK_STRUCTURE_TYPE_PIPELINE_RASTERIZATION_STATE_CREATE_INFO;
rasterizer.depthClampEnable = VK_FALSE;
//depthClampEnable被设置为VK_TRUE,那么超出近平面和远平面的片段会被夹住,而不是丢弃
//使用这个需要启用一个GPU功能。
rasterizer.rasterizerDiscardEnable = VK_FALSE;
//如果rasterizerDiscardEnable被设置为VK_TRUE,那么几何体就不会通过光栅化器阶段。
//这基本上是禁用任何输出到帧缓冲区的功能。
rasterizer.polygonMode = VK_POLYGON_MODE_FILL;
//它以片段的数量来描述线条的厚度
rasterizer.lineWidth = 1.0f;
//任何比1.0f厚的线都需要你启用wideLinesGPU功能。
//cullMode 变量确定要使用的面剔除类型。您可以禁用剔除、剔除正面、剔除背面或两者。
rasterizer.cullMode = VK_CULL_MODE_BACK_BIT;
//frontFace 变量指定被视为正面的面的顶点顺序,可以是顺时针或逆时针。
rasterizer.frontFace = VK_FRONT_FACE_CLOCKWISE;
//通过添加一个常量值或根据片段的斜率对其进行偏置来改变深度值
rasterizer.depthBiasEnable = VK_FALSE;
rasterizer.depthBiasConstantFactor = 0.0f; // Optional
rasterizer.depthBiasClamp = 0.0f; // Optional
rasterizer.depthBiasSlopeFactor = 0.0f; // Optional
polygonMode 决定了如何生成几何体的片段。有以下模式可供选择。
VK_POLYGON_MODE_FILL:用片段填充多边形的区域。VK_POLYGON_MODE_LINE:多边形的边缘被绘制成线。VK_POLYGON_MODE_POINT:多边形顶点被画成点。
多重采样
VkPipelineMultisampleStateCreateInfo结构配置了多重采样,这是执行抗锯齿的方法之一。
VkPipelineMultisampleStateCreateInfo multisampling{};
multisampling.sType = VK_STRUCTURE_TYPE_PIPELINE_MULTISAMPLE_STATE_CREATE_INFO;
multisampling.sampleShadingEnable = VK_FALSE;
multisampling.rasterizationSamples = VK_SAMPLE_COUNT_1_BIT;
multisampling.minSampleShading = 1.0f; // Optional
multisampling.pSampleMask = nullptr; // Optional
multisampling.alphaToCoverageEnable = VK_FALSE; // Optional
multisampling.alphaToOneEnable = VK_FALSE; // Optional深度和模版测试
如果你使用深度和/或钢网缓冲器,那么你还需要使用VkPipelineDepthStencilStateCreateInfo配置深度和钢网测试。我们现在没有,所以我们可以简单地传递一个nullptr
颜色混合
在片段着色器返回颜色后,需要将其与已经存在于帧缓冲器中的颜色结合起来。这种转换被称为颜色混合,有两种方法可以做到这一点。
- 将新旧值混合,产生最终的颜色
- 使用位操作将新旧值结合起来
有两种类型的结构可以配置颜色混合。第一个结构,VkPipelineColorBlendAttachmentState包含每个附加帧缓冲区的配置,第二个结构,VkPipelineColorBlendStateCreateInfo包含全球颜色混合设置。在我们的例子中,我们只有一个帧缓冲器。
VkPipelineColorBlendAttachmentState colorBlendAttachment{};
//每个附加帧缓冲区的配置
colorBlendAttachment.colorWriteMask = VK_COLOR_COMPONENT_R_BIT | VK_COLOR_COMPONENT_G_BIT | VK_COLOR_COMPONENT_B_BIT | VK_COLOR_COMPONENT_A_BIT;
colorBlendAttachment.blendEnable = VK_FALSE;
colorBlendAttachment.srcColorBlendFactor = VK_BLEND_FACTOR_ONE; // Optional
colorBlendAttachment.dstColorBlendFactor = VK_BLEND_FACTOR_ZERO; // Optional
colorBlendAttachment.colorBlendOp = VK_BLEND_OP_ADD; // Optional
colorBlendAttachment.srcAlphaBlendFactor = VK_BLEND_FACTOR_ONE; // Optional
colorBlendAttachment.dstAlphaBlendFactor = VK_BLEND_FACTOR_ZERO; // Optional
colorBlendAttachment.alphaBlendOp = VK_BLEND_OP_ADD; // Optional
//如果blendEnable被设置为VK_FALSE,那么来自片段着色器的新颜色就会不加修改地通过。
//否则,两个混合操作将被执行以计算出一个新的颜色
if (blendEnable) {
finalColor.rgb = (srcColorBlendFactor * newColor.rgb) <colorBlendOp> (dstColorBlendFactor * oldColor.rgb);
finalColor.a = (srcAlphaBlendFactor * newColor.a) <alphaBlendOp> (dstAlphaBlendFactor * oldColor.a);
} else {
finalColor = newColor;
}
//得到的颜色与 “colorWriteMask”相乘,以确定哪些通道实际被通过
finalColor = finalColor & colorWriteMask;第二个结构引用了所有帧缓冲器的结构数组,并允许你设置混合常数,你可以在上述计算中作为混合系数使用。
VkPipelineColorBlendStateCreateInfo colorBlending{};
colorBlending.sType = VK_STRUCTURE_TYPE_PIPELINE_COLOR_BLEND_STATE_CREATE_INFO;
colorBlending.logicOpEnable = VK_FALSE;
colorBlending.logicOp = VK_LOGIC_OP_COPY; // Optional
colorBlending.attachmentCount = 1;
colorBlending.pAttachments = &colorBlendAttachment;
colorBlending.blendConstants[0] = 0.0f; // Optional
colorBlending.blendConstants[1] = 0.0f; // Optional
colorBlending.blendConstants[2] = 0.0f; // Optional
colorBlending.blendConstants[3] = 0.0f; // Optional动态状态
我们在前面的结构中指定的有限数量的状态可以在不重新创建管道的情况下实际改变。例如,视口的大小、线宽和混合常数。如果你想这样做,那么你必须填写一个VkPipelineDynamicStateCreateInfo结构,像这样:
std::vector<VkDynamicState> dynamicStates = {
VK_DYNAMIC_STATE_VIEWPORT,
VK_DYNAMIC_STATE_LINE_WIDTH
};
VkPipelineDynamicStateCreateInfo dynamicState{};
dynamicState.sType = VK_STRUCTURE_TYPE_PIPELINE_DYNAMIC_STATE_CREATE_INFO;
dynamicState.dynamicStateCount = static_cast<uint32_t>(dynamicStates.size());
dynamicState.pDynamicStates = dynamicStates.data();管线布局
你可以在着色器中使用uniform值,它是类似于动态状态变量的球状物,可以在绘制时改变,以改变着色器的行为,而不必重新创建它们。它们通常被用来向顶点着色器传递变换矩阵,或者在片段着色器中创建纹理采样器。
VkPipelineLayout pipelineLayout;
VkPipelineLayoutCreateInfo pipelineLayoutInfo{};
pipelineLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
pipelineLayoutInfo.setLayoutCount = 0; // Optional
pipelineLayoutInfo.pSetLayouts = nullptr; // Optional
pipelineLayoutInfo.pushConstantRangeCount = 0; // Optional
pipelineLayoutInfo.pPushConstantRanges = nullptr; // Optional
if (vkCreatePipelineLayout(device, &pipelineLayoutInfo, nullptr, &pipelineLayout) != VK_SUCCESS) {
throw std::runtime_error("failed to create pipeline layout!");
}
void cleanup() {
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
...
}
10 渲染通道
在我们完成创建管道之前,我们需要告诉Vulkan渲染时将使用的帧缓冲器附件。我们需要指定有多少个颜色和深度缓冲区,每个缓冲区要使用多少个样本,以及在整个渲染操作中如何处理它们的内容。所有这些信息都被包裹在一个渲染通道对象中,我们将为它创建一个新的createRenderPass函数。
void createRenderPass() {
//只有一个单一的颜色缓冲区附件,由交换链中的一个图像代表
VkAttachmentDescription colorAttachment{};
//颜色附件的format应该与交换链图像的格式相匹配
colorAttachment.format = swapChainImageFormat;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
colorAttachment.storeOp = VK_ATTACHMENT_STORE_OP_STORE;
//这里采用存储操作。
//stencilLoadOp / stencilStoreOp 适用于模板数据
colorAttachment.stencilLoadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
colorAttachment.stencilStoreOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;
}loadOp和storeOp决定在渲染前和渲染后如何处理附件中的数据。我们对loadOp有以下选择。
vk_attachment_load_op_load: 保留附件中的现有内容vk_attachment_load_op_clear: 在开始时清除数值到一个常数vk_attachment_load_op_dont_care: 现有的内容是未定义的;我们不关心它们
在我们的例子中,我们要使用清除操作,在绘制新帧之前将帧缓冲区清除为黑色。storeOp只有两种可能性。
vk_attachment_store_op_store:渲染的内容将被保存在内存中,以后可以被读取vk_attachment_store_op_dont_care: 渲染操作后,帧缓冲区的内容将不被定义。
Vulkan 中的纹理和帧缓冲区由具有特定像素格式的 VkImage 对象表示,但是布局内存中的像素可以根据您尝试对图像执行的操作而改变。
一些最常见的布局是:
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL:用作颜色附件的图像VK_IMAGE_LAYOUT_PRESENT_SRC_KHR:要在交换链中呈现的图像VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL:用作内存复制操作目标的图像
子通道和引用附件
一个渲染通道可以由多个子通道组成。子通道是依赖于之前通道中帧缓冲区内容的后续渲染操作,例如,一连串的后期处理效果被相继应用。如果你将这些渲染操作归入一个渲染通道,那么Vulkan就能够重新安排这些操作的顺序,并节省内存带宽,从而可能获得更好的性能。然而,对于我们的第一个三角形,我们将坚持使用单一的子通道。
每个子通道都会引用一个或多个我们在前面章节中使用结构描述的附件。这些引用本身是VkAttachmentReference 结构,看起来像这样。
VkAttachmentReference colorAttachmentRef{};
//attachment参数通过附件描述数组中的索引指定要引用的附件
colorAttachmentRef.attachment = 0;
colorAttachmentRef.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;
VkSubpassDescription subpass{};//子通道
subpass.pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;
//明确指出这是一个图形子通道
subpass.colorAttachmentCount = 1;
subpass.pColorAttachments = &colorAttachmentRef;
VkRenderPassCreateInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO;
renderPassInfo.attachmentCount = 1;
renderPassInfo.pAttachments = &colorAttachment;
renderPassInfo.subpassCount = 1;
renderPassInfo.pSubpasses = &subpass;
if (vkCreateRenderPass(device, &renderPassInfo, nullptr, &renderPass) != VK_SUCCESS) {
throw std::runtime_error("failed to create render pass!");
}就像管道布局一样,渲染通道将在整个程序中被引用,所以它应该在最后才被清理掉:
void cleanup() {
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
vkDestroyRenderPass(device, renderPass, nullptr);
...
}
结论
我们现在可以把前几章中的所有结构和对象结合起来,创建图形管道了!这就是我们现在拥有的对象的类型。下面是我们现在拥有的对象的类型,作为快速回顾。
- 着色器阶段:定义图形管道可编程阶段功能的着色器模块。
- 固定功能状态:定义流水线固定功能阶段的所有结构,如输入组件、光栅化器、视口和颜色混合等
- 管道布局:着色器所引用的统一和推送值,可以在绘制时进行更新
- 渲染通道:流水线阶段所引用的附件及其使用。
所有这些结合起来完全定义了图形管道的功能,所以我们现在可以开始在 createGraphicsPipeline函数的最后填写VkGraphicsPipelineCreateInfo结构。但是在调用vkDestroyShaderModule之前,因为这些仍然要在创建期间使用。
VkGraphicsPipelineCreateInfo pipelineInfo{};
pipelineInfo.sType = VK_STRUCTURE_TYPE_GRAPHICS_PIPELINE_CREATE_INFO;
pipelineInfo.stageCount = 2;
pipelineInfo.pStages = shaderStages;
//引用VkPipelineShaderStageCreateInfo结构的阵列。
pipelineInfo.pVertexInputState = &vertexInputInfo;
pipelineInfo.pInputAssemblyState = &inputAssembly;
pipelineInfo.pViewportState = &viewportState;
pipelineInfo.pRasterizationState = &rasterizer;
pipelineInfo.pMultisampleState = &multisampling;
pipelineInfo.pDepthStencilState = nullptr; // Optional
pipelineInfo.pColorBlendState = &colorBlending;
pipelineInfo.pDynamicState = nullptr; // Optional
//引用所有描述固定功能阶段的结构。
//之后是管道布局,它是一个Vulkan句柄而不是一个结构指针。
pipelineInfo.layout = pipelineLayout;
//渲染通道的引用和子通道的索引
pipelineInfo.renderPass = renderPass;
pipelineInfo.subpass = 0;
//Vulkan允许你通过衍生现有的管道来创建一个新的图形管道
//可以用basePipelineHandle指定一个现有管道的句柄
//或者用basePipelineIndex引用另一个即将创建的管道的索引
///现在只有一个管道,所以我们将简单地指定一个空手柄和一个无效的索引
pipelineInfo.basePipelineHandle = VK_NULL_HANDLE; // Optional
pipelineInfo.basePipelineIndex = -1; // Optional最后创建图形管道:
if (vkCreateGraphicsPipelines(device, VK_NULL_HANDLE, 1, &pipelineInfo, nullptr, &graphicsPipeline) != VK_SUCCESS) {
throw std::runtime_error("failed to create graphics pipeline!");
}vkCreateGraphicsPipelines函数实际上比Vulkan中通常的对象创建函数有更多参数。它被设计用来接收多个VkGraphicsPipelineCreateInfo对象并在一次调用中创建多个VkPipeline对象。
第二个参数,我们为其传递了VK_NULL_HANDLE参数,引用了一个可选的VkPipelineCache对象。管线缓存可以用来存储和重用与管线创建相关的数据,跨越对vkCreateGraphicsPipelines的多次调用,如果缓存被存储到文件中,甚至跨越程序执行。
图形管道对于所有常见的绘图操作都是必需的,所以它也应该只在程序结束时被销毁。
void cleanup() {
vkDestroyPipeline(device, graphicsPipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
...
}