文章目录
- UC-OWOD: Unknown-Classified Open World Object Detection
- 摘要
- 1.介绍
- 2.相关工作
- 3.未知分类的开放世界目标检测
- 3.1 问题定义
- 3.2 整体架构
- 3.3 未知物体的检测
- 3.4基于相似性的未知分类
- 3.5未知聚类优化
- 3.6训练和优化
- 4:实验
- 4.1准备工作
- 4.2结果和分析
- 4.3消融研究
- 5 结论和未来工作
- UC-OWOD:未知分类的开放世界对象检测(补充材料)
- 1.定量结果
- 2.定性结果
UC-OWOD: Unknown-Classified Open World Object Detection
摘要
开放世界对象检测(OWOD)是一个具有挑战性的计算机视觉问题,需要检测未知对象并逐渐学习所识别的未知类。但是,它不能将未知实例区分为多个未知类。在这项工作中,我们提出了一种新的OWOD问题,称为未知分类的开放世界对象检测(UC-OWOD)。UC-OWOD的目标是检测未知的实例,并将它们分类到不同的未知类。此外,我们定义这个问题,并设计了一个两阶段的对象检测器来解决UC-OWOD。首先,未知标签感知建议框proposal和未知判别分类头用于检测已知和未知对象。然后,基于相似性的未知分类和未知聚类强化模块被构建区分多个未知类。此外,两个新的评估协议被设计用于评估未知类检测。大量的实验和可视化结果证明了该方法的有效性。代码可在https://github.com/JohnWuzh/UC-OWOD上获得。
1.介绍
如今,深度学习方法在对象检测方面取得了巨大成功[20,31,47,35,8,10]。传统的目标检测方法是在封闭世界假设下开发的,因此它们只能检测已知(标记的)类别[17,46,62]。然而,真实的世界中包含许多未知的(未标记的)类,传统的检测方法很难正确地处理此类问题。因此,研究开放世界目标检测(OWOD)中的未知实例检测问题,对于促进实际应用具有重要意义。
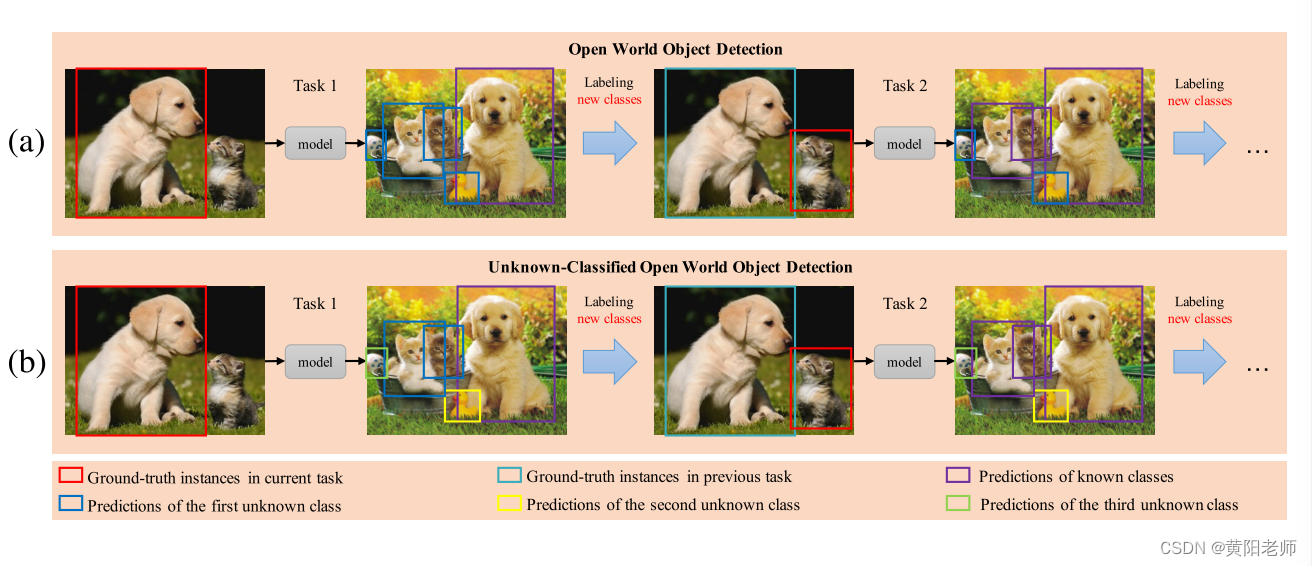
图1所示。OWOD和UC-OWOD之间的比较。他们都可以学习新标注类的通过人类的标注信息,并且在接下来的任务中没有忘记。(a) OWOD检测未知对象作为一个相同的类。(b) UC-OWOD可以检测到未知的对象作为不同的类。
OWOD问题由[24]开创,如图1(a)所示.OWOD包含多个增量任务。在每个任务中,OWOD能够将所有未知实例识别为未知。然后,人类注释者可以逐渐为感兴趣的类分配标签,模型在下一个任务中增量学习这些类。然而,除了区分未知类之外,我们还需要确定多个未知实例是否属于同一类别。因此,将OWOD用于真实世界任务时,仍然存在巨大的困难。例如,在机器人[16,28]和自动驾驶汽车[7,53]的实际应用中,需要探索未知环境,采取不同的策略针对不同的未知类别。这就要求检测算法能够自信地定位未知实例并将其分类到不同的未知类别中。
大多数现有的开放世界检测器是针对OWOD问题设计的。例如,开放世界对象检测器(ORE)[24]可以检测未知类,但它不考虑对未知对象进行分类的情况。更具体地说,ORE使用伪标签监督训练来检测未知实例。由于伪标签只能被标记为未知,因此ORE模型不能直接用于解决将未知类检测为不同类的问题。类似地,现有的OWOD方法模型,如[18,60]遵循ORE的精神,我们不知道以前的任何工作可以区分多个未知类。
研究未知对象分类问题的另一个难点是评价标准不成熟。现有的度量仅评估未知类和已知类之间的混淆程度。它们无法评估两个不同类别的未知物体被检测为同一类别的情况。但这些问题不能被忽视,因为它们可能会导致模型对未知对象进行错误分类。因此,迫切需要一种更为合理的评价指标来评价多个未知类的检测精度。
考虑到上述问题,我们提出了一种更接近真实世界设置的新颖OWOD问题,即未知分类开放世界对象检测(UC-OWOD),其可以将未知对象检测为不同的未知类(参见图1(b))。同时,我们提出了一种新的框架的基础上的两阶段检测流水线来解决这个问题。特别是,我们设计了未知的标签感知建议(ULP),以构建未知对象的真实框,未知的判别分类头(UCH)挖掘未知对象,基于相似性的未知分类(SUC),以检测未知对象作为不同的类,和未知的聚类细化(UCR),以完善未知对象的分类。为了更准确地评估UC-OWOD问题,我们提出了新的指标来评估未知实例的分类和定位性能。使用最大匹配来更合理地将真实框分配给未知对象。最终,我们的模型在现有的评估指标和新的评估指标中实现了最佳性能。我们的主要贡献如下:
- 我们引入一个新的问题设置,未知分类的开放世界对象检测,以启发未来的研究对现实世界对象检测。
- 我们提出了一种基于未知的标签感知的提议方法来解决UC-OWOD的问题,和未知判别的分类头,基于相似性的未知分类,和未知的聚类改进。
- 提出了一种新的UC-OWOD评价指标,可以对未知目标的定位和分类进行评价。大量的实验进行,结果表明,我们的方法和新的指标的UC-OWOD问题的有效性。
2.相关工作
开集识别与检测
开集识别首先被定义为一个约束最小化问题[51],它可以在测试阶段将未知类提交给算法。它由[23,50]开发为多类分类器。Liu等人考虑了长尾识别环境,并开发了一个度量学习框架来识别未知类[33]。自监督学习[41]和具有重建的无监督学习[58]也已用于开集识别。Yue等人为平衡和改善可见/不可见分类失衡提供了理论基础[59]。Bendale和Boult提出了一种使深度网络适应开集识别的方法,使用OpenMax层来估计输入来自未知类的概率[6]。Dhamija等人首先提出了开集对象检测协议,并形式化了开集对象检测问题[11]。米勒等人通过在机器人视觉中常见的开放条件下提取标签不确定性来提高对象检测性能[40]。一些后续工作还利用对象检测器中的(空间和语义)不确定性的测量来拒绝未知类别[19]。米勒等人发现正确选择紧密的聚类组合可以大大提高分类的有效性,空间不确定性估计以及由此产生的目标检测性能[39]。然而,这些方法不能在动态世界中逐渐调整其知识。相比之下,我们的模型可以根据人类注释的标签动态更新已知的类。
开放世界识别和检测
与开集问题相比,开放世界问题具有动态数据集,可以不断添加新的已知类,如连续学习[42,13,48,54,26]。Bendale等人首先提出了开放世界识别,并提出了一个用于评估开放世界识别系统的协议[5]。Xu等人提出了一种针对开放世界学习问题的元学习方法,该方法仅使用即时可见的类(包括新添加的类)的示例进行分类和拒绝[57]。Joseph等人提出了一个新的计算机视觉问题,称为OWOD [24]。他们提出的ORE可以在已知类和未知类之间对提取框进行分类,但它依赖于具有弱未知监督的验证集来学习已知类和未知类的能量分布。开放世界检测变换器(OW-DETR)使用多尺度自我注意和可变形感受野来提高性能[18]。Zhao等人进一步提出了一个OWOD框架,包括一个辅助提取框和一个特定于类的驱动分类器[60]。这些方法都没有实现未知类的分类。我们的工作主要是研究未知物体的分类。
约束聚类
约束聚类是一种利用先验知识辅助聚类的半监督学习方法。所提出的用于约束聚类的方法可以分为三种类型,即,基于搜索(也称为基于约束),基于距离(也称为基于相似性)和混合(也称为基于搜索和距离)的方法[61]。基于搜索的方法中的一种常见技术是通过为不满足的约束添加惩罚项来修改目标函数。在基于距离的方法中,通常使用现有的聚类方法,但是该方法的距离度量根据先验知识进行修改。混合方法集成了基于搜索和基于距离的方法。它们受益于两者的优势,并且通常比单独的方法更好[12]。Basu等人允许违反约束,同时优化距离度量[4]。Hsu等人设计了一个新的损失函数来规范具有约束聚类损失的分类,同时使用其他相似性预测模型作为聚类过程中的成对约束[22]。Lin等人将成对约束作为先验知识来指导聚类过程[30]。我们使用成对约束来优化模型中的未知对象分类。
3.未知分类的开放世界目标检测
3.1 问题定义
UC-OWOD问题定义如下。存在一组任务T = {T1,T2,…}。在任务Tt中,我们具有已知的类集合Kt = {1,2,…C}和未知类集合Ut = {C + 1,C + 2,…},其中C是已知类的数量。任务Tt+1中的已知类集合包含任务Tt中的已知类集合,即,Kt 属于Kt+1,已知类数据集Dt = {Xt,Yt}的第k个对象的标签是yk = [lk,xk,yk,wk,hk],其中类标签lk ∈ Kt,并且xk,yk,wk,hk分别表示边界框中心坐标、宽度和高度。Xt和Yt分别是输入图像和标签。未知类的实例没有标签。对象检测器MC能够识别属于任何已知类的测试实例,并且还可以将新的或未见过的类实例检测为不同的未知类。人类用户可以从未知的实例集Ut中识别u个新的感兴趣类别,并提供相应的训练示例。更新已知类集Kt+1 = Kt∪{C+1,…,C+u}。通过在下一个任务中递增地添加u个新类,学习器创建更新的模型MC+u,而不需要在整个数据集上重新训练模型。
3.2 整体架构
图2. 展示了所提出的用于UC-OWOD的方法的总体架构。我们使用Faster R-CNN [47]作为基本检测器。我们引入(1)ULP和UCH来解决从背景中发现未知类的问题,(2)SUC来将未知对象检测为不同的类,以及(3)UCR来改善未知对象的分类并增强算法的鲁棒性。为了模拟未知对象之间的差异,我们提出了一种新的分类损失。详细信息将在以下小节中讨论。
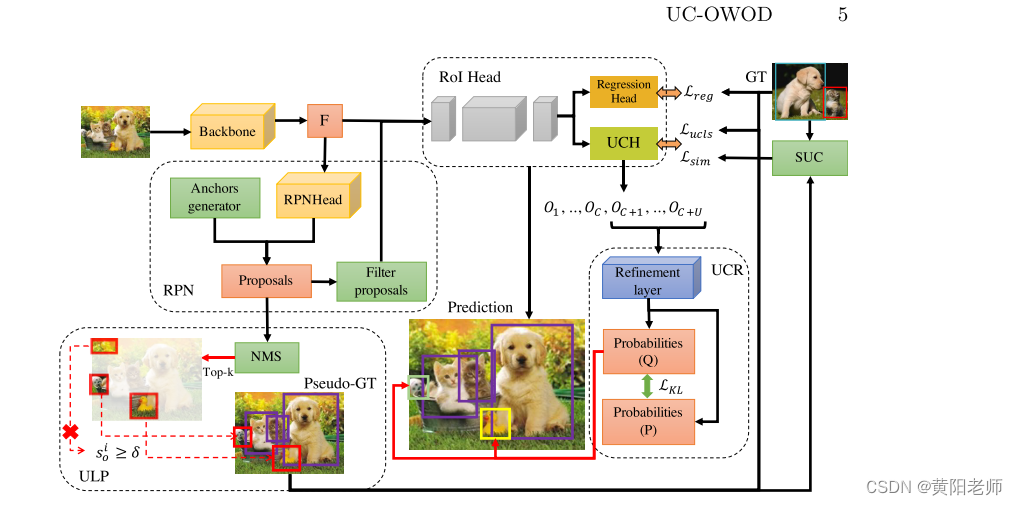
图二.我们模型的架构。根据伪标签候选框的得分S是否大于阈值δ来过滤伪标签候选框。在训练过程中,ULP根据RPN的建议框为未知对象构造伪GT。根据模型的回归头和UCH,分别计算Lreg和Lucls,并通过SUC得到Lsim。在优化期间,未知对象{OC+1,…OC+U)将通过UCH获得的OC+U输入到UCR以优化聚类,其中U是未知类的数量。

图3.UCH的示意图。交通灯和香蕉是已知类。Apple、book和baseball是未知类。未知类在计算损失时仅选择具有最高分数的值。
3.3 未知物体的检测
未知标签感知的提取框
由于未知实例未被标记,因此需要构造伪标签来训练模型检测未知类的能力。我们采用了一种新的伪标记策略,该策略在多个未知类的检测中具有更好的泛化性和适用性,如图2左下方所示。基于区域建议网络(RPN)是类无关特性,我们构造伪标签与RPN和相应的对象分数生成的边界候选框。首先,通过非最大值抑制(NMS)过滤所有候选框以避免伪标签之间的部分重叠。第二,我们选择过滤后的前k个背景框作为候选框,这些候选框按其对象性得分排序。第三,为了避免将真实的背景区域候选框标记为未知类,并且使训练结果更有鲁棒性,在候选框中,对象性得分大于阈值δ的候选框被用作伪标签,即,yunk = [unknown,xi,yi,wi,hi]用作未知标签感知候选框。
未知判别分类头
为了使模型能够定位和分类未知类,我们在原始分类头中引入了多个未知类:Fcls:RD → RC+U,其中U是未知类的数量。在训练阶段,伪标签都被标记为未知。原有的分类策略不能对多种未知对象进行分类,因此对原有的分类损失进行了修正。如图1所示,3、利用伪标签和多个未知类预测的最大概率计算未知类的分类损失。新的分类损失被构造为
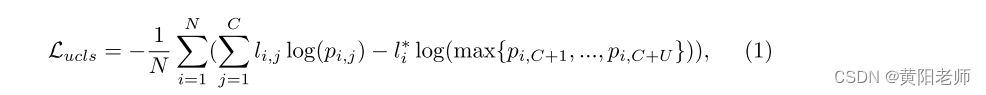
其中N是实例的数量,l是已知类的标签,l * 是未知类的伪标签,p是预测概率。
3.4基于相似性的未知分类
聚类未知类允许模型区分不同的未知类。我们采用成对分类损失来衡量样本之间的相似性。通过确定样本对是否相似,我们的模型可以对未知类别进行分类。可以表示类别信息的UCH的输出E用于计算相似度矩阵S:

||··||是L2范数且i,j ∈ {1,…,n},并且n表示候选框的数量。Sij表示第i个候选框和第j个候选框之间的相似性。如图所示4、先后采用监督和自监督两种方法对模型进行优化。

图4。建立嵌入的相似性矩阵,对已知类使用监督方法,对未知类使用自监督方法。
监督方法
我们将标记数据视为先验知识,并使用它来指导不同未知实例之间的相似关系。在监督方法中,由于未知实例之间的关系是未知的,我们只使用已知-已知实例对、未知-已知实例对、已知背景实例对和未知背景实例对。我们可以将标签矩阵M构造为
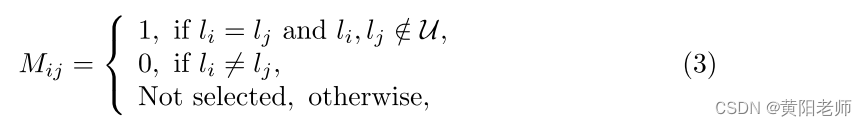
其中li是第i个实例的类标签,i,j ∈ {1,…,n},并且U是未知类的集合。利用具有真实框的已知实例来减少误差。因此,我们构造具有标签M和相似性S的相似性损失Lsim为:
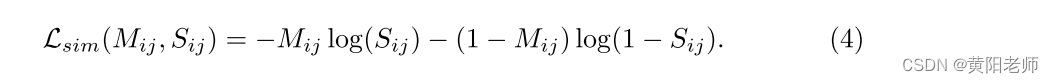
自监督方法
我们使用阈值来确定未知实例对是否相似。TH(λ)和TL(λ)是应用于相似性矩阵S以获得自标记矩阵M的动态上阈值和下阈值,其中λ是控制样本选择的自适应参数。在TH(λ)和TL(λ)之间具有相似性的那些未知实例对从训练阶段排除。M的定义如下:
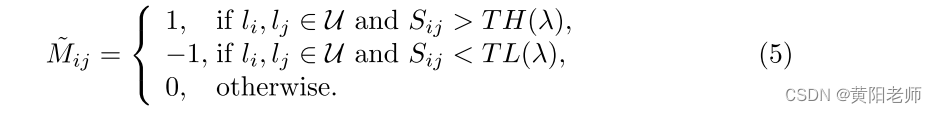
然后,我们用自标记矩阵M ~和类标记l构造标记矩阵M:
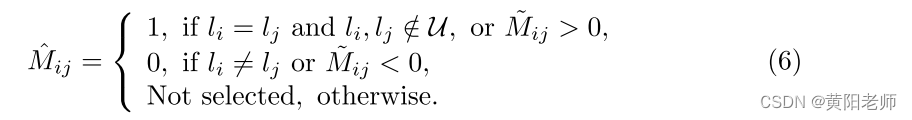
通过相似性矩阵S和标签矩阵M计算相似性损失L sim:
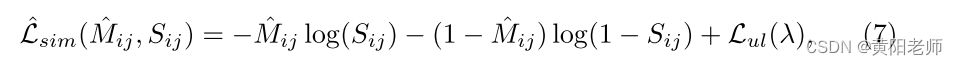
其中,针对样本数量的惩罚项Lul(λ)被给出为:

自适应参数λ更新为:

其中η是λ的学习速率。随着λ更新,越来越多的实例对参与训练阶段。为了获得聚类友好的表示,我们训练模型从容易分类的未知实例对难以分类的未知实例对迭代的阈值变化。当TH(λ)≤ TL(λ)时,迭代过程终止。
3.5未知聚类优化
为了增强所提出算法的鲁棒性,我们应用软分配方法[56]来改进基于先前网络输出的未知分类。UCR使用聚类来提高未知对象的可分性。在第一步中,根据UCH的输出,得到未知类的嵌入E和未知类的聚类质心Φ。并且我们计算保存在细化层中的Ei和Φj之间的软分配,同时使用Student的t分布[36]作为内核:
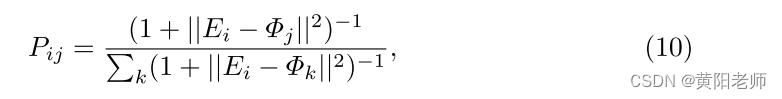
其中Pij可以被解释为将实例i分配给集群j的概率(软分配)。在第二步骤中,辅助目标分布Q用于基于集群的高置信度分配来细化集群:

其中Fi = Pi Pi Pi j是软簇频率。辅助目标分布的二次项可以强调高置信度分配。因此,在辅助目标分布的辅助下,该模型可以逐步学习到良好的聚类结构,提高聚类纯度。然后,我们最小化软分配P和辅助分布Q之间的Kullback-Leibler(KL)散度损失以细化聚类:
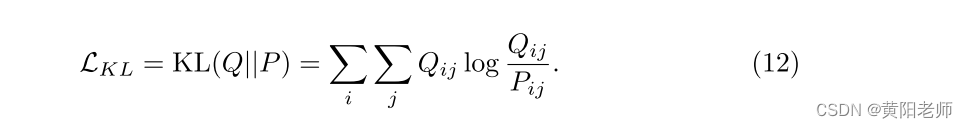
3.6训练和优化
**训练:**我们的模型是用以下损失函数端到端训练的:
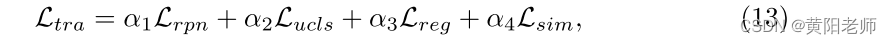
其中Lrpn和Lreg分别表示RPN和边界框回归的损失项。详细地,Lrpn使用标准RPN损失公式化[47],Lreg是标准1回归损失。α1、α2、α3、α4表示权重因子。当模型仅使用当前任务Tt类进行训练时,它将灾难性地忘记在前一个任务中学习的信息[38,15]。比较现有的解决方案,即参数正则化[2,29]、示例重放[45,9]、动态扩展网络[37,49,52]和元学习[44,25],我们选择了一种相对简单的少示例重放方法[55,43,24]。在学习任务Tt之后,使用每个已知类的存储示例集合来对模型进行微调。
优化
在对未知对象的聚类优化阶段,主要目的是提高对未知对象的分类。我们只使用KL散度损失来训练未知对象:

4:实验
4.1准备工作
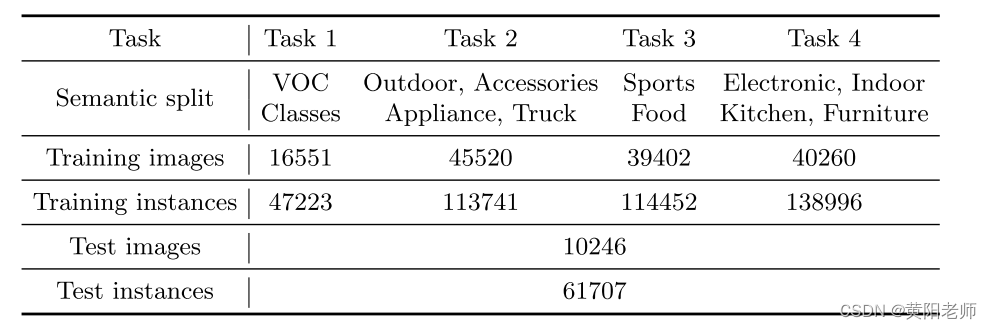
数据集。我们在任务集T = {T1,T2,· · · }上评估我们的UC-OWOD问题模型。Tλ中的类在t = λ时引入。对于任务Tt,在{Tt:τ ≤ t}是已知的,并且{Tτ:τ > t}是未知的。如表1所示,我们使用Pascal VOC [14]和MS-COCO [32]数据集构建了4个任务,每个任务中有20个类。任务T1由所有VOC类和数据组成,它们不包含任何关于未知实例的信息。这允许在训练阶段期间在没有任何未知信息的情况下对模型进行测试。剩余的60类MS-COCO分为三部分,即:T2、T3和T4。T2和T3中的训练图像虽然没有未知实例的标签,但它们包含未知实例,这可以测试模型在这种情况下的效果。在每个任务中,评估数据由Pascal VOC测试分割和MS-COCO验证分割组成。
表1.每个任务的数据集。显示了每个任务包含的语义以及图像和实例的数量。
评价指标
对于未知类的总体评估,我们使用两个评估度量,即,绝对开集误差(A-OSE)[40,24]和(WI)[11,24]。A-OSE是错误分类为已知的未知对象的数量。WI由当前已知的真建议框TPK和假建议框FPK计算:

对于未知类的细化,没有标签预测对,因此平均精度(mAP)不起作用。我们也不知道有任何其他度量可以处理评估多个未知类别。受聚类评估度量的启发,即,在聚类精度[1]中,我们引入了一种新的评估度量,未知均值平均精度(UC-mAP),以评估未知类的检测。因此,UC-mAP是自动类别匹配的mAP:
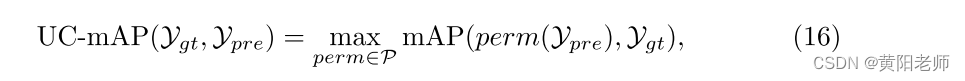
其中P是1到U中的所有排列的集合,U是未知类别的数量,Ypre是预测值,并且Ygt是真实值。最佳匹配使用匈牙利算法[27]进行快速计算。如果该模型可以检测到MS-COCO数据集中未标记的一些新实例,则该模型也更好,但是传统的mAP度量对缺失的注释非常敏感,并且将这种检测视为误报。因此,我们也使用最大匹配后的未知类Recall [34,3,18]作为评估度量,即,UC-Recall。

图5.汽车未知-1和长颈鹿未知-2。两个图像都将右侧的汽车误检测为已知,并且左侧图像将长颈鹿误检测为未知-1。

表2. UC-mAP和UC-Recall的验证结果。无标记UC-mAP可以实现与基于标记的mAP相同的评估结果,如Recall。
实施细节
我们的模型基于标准的Faster RCNN [47]对象检测器,具有ResNet-50 [21]主干。我们将未知类和已知类的总数设置为80,这对应于MS-COCO数据集。如前所述,在分类损失中,我们只学习预测概率最高的未知类。这是通过将不可见类的logit设置为一个大的负值(v)来实现的,这样它们对softmax的贡献就可以忽略不计(e-v → 0)。我们设置TH(λ)= 0.95 − λ,TL(λ)= 0.455 + 0.1λ,α1 = α2 = α3 = 1,α4 = 0.5,学习率为0.01。在细化时,我们固定细化层之前的层,并使用0.1的学习率。使用K-均值获得未知类的初始聚类质心。因为细化阶段依赖于训练集中的未知对象信息,所以我们只对任务2和任务3使用UCR。
UC-mAP和UC-Recall的有效性
我们分析了WI、A-OSE、U-Recall、UC-Recall和UC-mAP在不同情况下的评估结果(见图5)。所有度量反映未知对象被错误分类为已知的情况。WI、A-OSE和U-Recall [18]不能确定未知-1和未知-2是否被错误地分类为同一类,但UC-Recall和UC-mAP在正确检测下可能导致更高的分数。UC-Recall和UC-mAP使用已知类的Oracle检测器进一步评估,其可以在任何任务中访问所有已知和未知标签(参见表2)。我们可以看到,当模型使用相应的标签进行训练时,UC-mAP/UC-Recall等效于mAP/Recall。

表3.我们的模型在已知类上的性能。PK表示先前已知实例的mAP,CK表示当前已知实例的mAP。
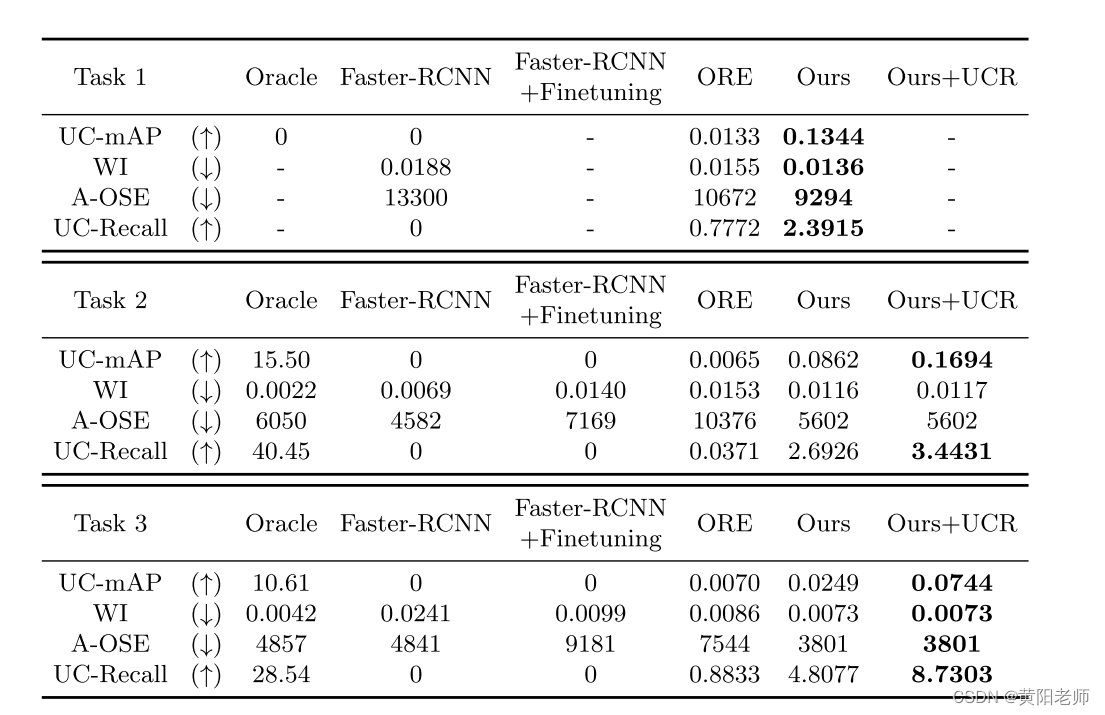
表4.我们的模型在UC-OWOD上的性能。WI、A-OSE、UC-mAP和UC-Recall量化了模型如何处理未知类。
4.2结果和分析
如表3所示,我们的模型能够避免灾难性地忘记以前的类。为了更好地分析UC-OWOD问题的性能,我们将我们的模型与Faster-RCNN和ORE进行了比较,它们在未知对象检测方面的性能如表4所示。由于篇幅有限,在补充材料中给出了完整的实验数据。WI和A-OSE度量用于量化未知实例和任何已知类之间的混淆程度。UC-Recall度量用于量化模型检索未知对象实例的能力。UC-mAP度量用于量化模型对所有未知类的平均检测水平。在UC-OWOD的设置下,Faster-RCNN和Faster-RCNN +Finetuning不具备检测未知实例的能力,而Finetuning会导致WI和A-OSE的得分降低。在所有的任务中,我们取得了更好的结果比ORE对未知类的措施。加入UCR后,模型对未知目标的检测能力得到显著提高。图6和补充材料示出了示例图像上的定性结果。

图6 :我们模型的定性结果。未知x表示第x类的未知对象。我们的模型将房子检测为未知-11,并能够将其与同一图像中的其他未知类别区分开来。这意味着我们的模型不仅可以检测MS-COCO数据集中注释的类别,还可以挖掘新的类别并将其与其他类别区分开来。还示出了一些其他未知类,即,马桶为未知-24,刀为未知-39等等。最后一列显示了一个失败案例,将冲浪板错误分类为未知-38,而实际上是蛋糕。补充材料包含更多可视化结果。
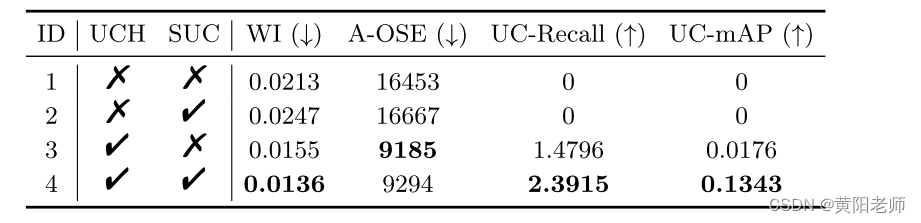
在表5中。我们模型的消融实验结果。
4.3消融研究
组件消融
我们设计消融实验来研究模型中UCH和SUC的贡献(见表5)。当UCH和SUC(行1和行2)缺失时,模型将失去检测未知类的能力。仅添加SUC(第2行)不会提高模型检测未知类的能力。只有SUC的缺失(行3)影响未知类的分类能力,但模型在已知类的检测上表现最好。因此,WI、UC-Recall和UC-mAP的分数比具有UCH和SUC两者的分数更差(第4行)。因此,当两种组分都存在时实现最佳性能。
超参数的灵敏度分析
如表6所示,我们分析了模型在不同超参数设置下的检测性能。当NMS阈值较大时,未知类别的召回率较低,因为模型可能将与已知类别标签具有高重合度的区域设置为伪标签。该模型只能定位已知的实例区域,而不能定位未知的实例区域。当δ的值较大时,模型倾向于标记较少的未知类别,导致模型对未知类别的检测性能较差。类似地,当伪GT的数量设置为1时,由于标记的未知类较少,模型的有效性将降低。我们选择了WI、A-OSE、UC-回忆和UC-mAP评分更好的超参数设置,即:NMS阈值为0.3,δ为0.3,并且伪GT的数量为5。
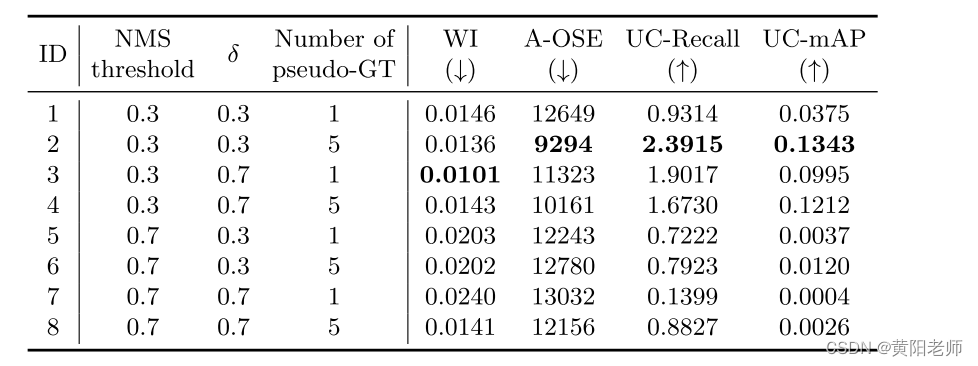
表6 超参数的灵敏度分析
5 结论和未来工作
在这项工作中,我们提出了一个新的问题UC-OWOD的基础上,OWOD,这是更接近真实的世界。UC-OWOD要求将未知对象检测为不同的未知类。我们还建立了这个问题的评估协议。此外,我们提出了一种新的方法,包括ULP,UCH,SUC,和UCR。大量的实验证明了该方法在UC-OWOD问题上的有效性,同时也验证了该度量的合理性。在未来的工作中,我们希望将我们的方法应用到一些现实世界的在线任务,实现开放世界的自动标注。
致谢
这项工作部分得到了中国国家重点研究与发展计划项目2019YFB1310300的支持,部分得到了国家自然科学基金项目62022090的支持。
UC-OWOD:未知分类的开放世界对象检测(补充材料)
1.定量结果
表1示出了所提出的UC-OWOD评估协议的全部结果。已知类的检测性能由mAP计算。如上所述,Oracle是用所有已知和未知实例的注释训练的检测器。由于任务1中训练集只有已知类的标签,因此不考虑Oracle对未知类的检测结果。在没有微调的情况下,模型将完全忘记先前的类,这导致显著的mAP下降(55.38% vs. 0%)。通过微调,可以恢复精确已知类的部分检测能力(40.90%mAP),但WI/A-OSE性能确实受到影响。微调检测器更倾向于将对象分类到已知类别中。关于未知类的分数,由于缺乏未知的地面实况,任务4无法测量。在先前已知的任务上,我们的方法在当前已知的任务上比ORE学习得更好。然而,由于验证集的不完整注释,诸如房屋的未知对象的检测被认为是错误检测。由于这个原因,我们模型的两个mAP都低于ORE。因此,mAP只能在一定程度上测量模型对已知类别的检测性能。
2.定性结果
由于Faster-RCNN无法检测到任何未知对象,因此我们仅定性比较Oracle,ORE和我们的模型,如图所示。1.对于每个测试图像,从左到右的列是Oracle,ORE和我们的模型的检测结果。Oracle和ORE都无法检测棒球棒和甜甜圈等。这意味着我们的模型在检测未知物体方面更好。为了更好地分析模型在UC-OWOD问题上的性能,我们使用一些具有多个未知实例的图像进行测试,如图所示。2.结果表明,我们的模型可以正确区分未知对象,即,将棒球分类为未知-34,将帽子分类为未知-17。相比之下,Oracle和ORE只能将未知对象作为一个类进行检测。图3示出了不同图像上的同类未知对象的检测结果。我们的模型是能够检测网球拍为未知-37在不同的图像,Oracle和ORE都未能做到这一点。图4显示了我们的模型在不同任务上的增量学习的定性结果。我们的模型能够检测未知的对象,并将它们分类为已知的类时,他们的标签被引入,如斑马。
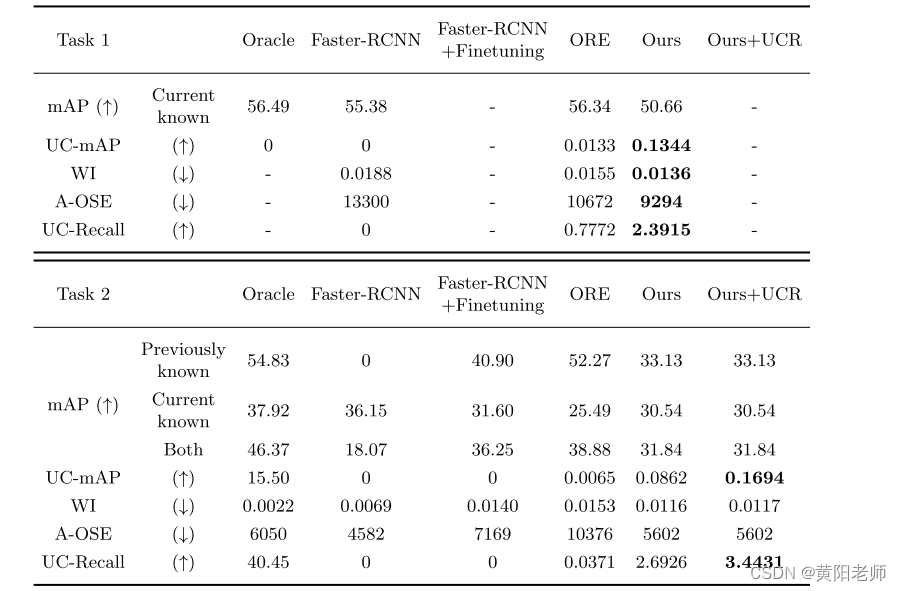
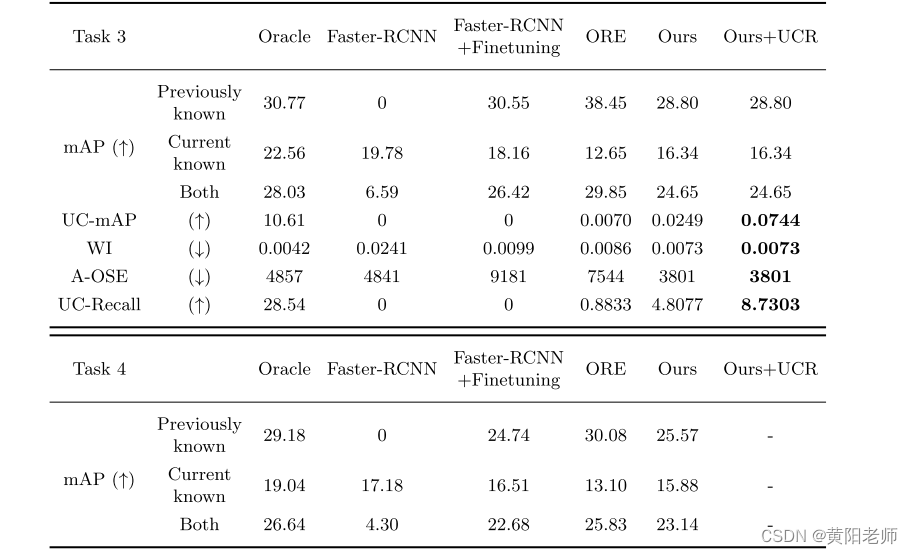
表1.Oracle、ORE和我们的UC-OWOD模型的比较。WI、AOSE、UC-mAP和UC-Recall反映了模型如何处理未知类,而mAP衡量检测已知类的能力。可以看出,我们的模型在处理未知类方面远远优于其他模型。
 图1.Oracle、ORE和我们模型的检测结果。在第一行中,Oracle和ORE未能检测到图像中的棒球棒。在第二行中,我们的模型能够正确地检测到甜甜圈,而其他模型将其误检测为餐桌。在第三行中,我们的模型和ORE可以检测广播,但我们的模型的定位更准确。
图1.Oracle、ORE和我们模型的检测结果。在第一行中,Oracle和ORE未能检测到图像中的棒球棒。在第二行中,我们的模型能够正确地检测到甜甜圈,而其他模型将其误检测为餐桌。在第三行中,我们的模型和ORE可以检测广播,但我们的模型的定位更准确。


图2.多个未知物体的检测结果。只有我们的模型才能正确区分图像中的不同未知类别。


图三.同一类未知对象的检测结果。只有我们的模型才能正确定位未知对象,并将其分类为同一未知类。


图4。左侧显示了任务4之前我们模型的检测结果。右侧示出了使用任务4进行增量训练后的相应预测。在第一行中,左边的未知-44被正确地预测为任务4中的斑马。在第二行中,未知-29被正确地检测为风筝。在第三行中,任务4正确地检测未知-31为滑板。