Contrastive Loss
background:
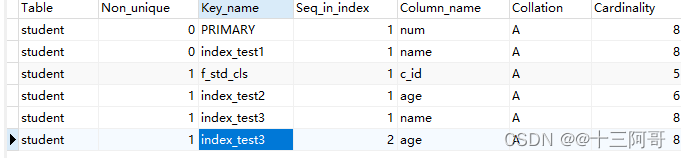
最直接的想法是我们假设存在一个损失函数,它满足如下的基本准则
- 近似样本之间的距离越小越好
- 不似样本之间的距离越大越好
相似样本的坐标被放的越来越远,不似样本之间的距离越来越大,但训练的目标却仿佛永远无法达到 … 这是因为训练目标没有边界。
- 所以提出了,对比损失

- 核心含义:同类的样本要更近,不同类的样本要更远
- 正样本不用管,把负样本分开就行,最小化损失函数就是最大化决策边界和负样本的距离
m。 - 近似样本之间的距离越小越好;不似样本之间的距离如果小于m,则通过互斥使其距离接近
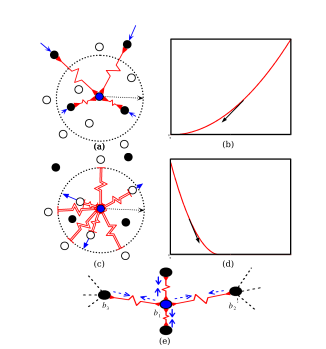
- 正样本不用管,把负样本分开就行,最小化损失函数就是最大化决策边界和负样本的距离
如图所示,同类的点会被压缩收缩,边界区域内有不同类的点会被互斥到边界区域

论文:http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
Triplet Loss
Triplet Loss是一种用于训练深度学习中的Siamese网络或者三元组网络的损失函数。它的目标是使同一类别的样本之间的距离尽可能小,不同类别之间的距离尽可能大。
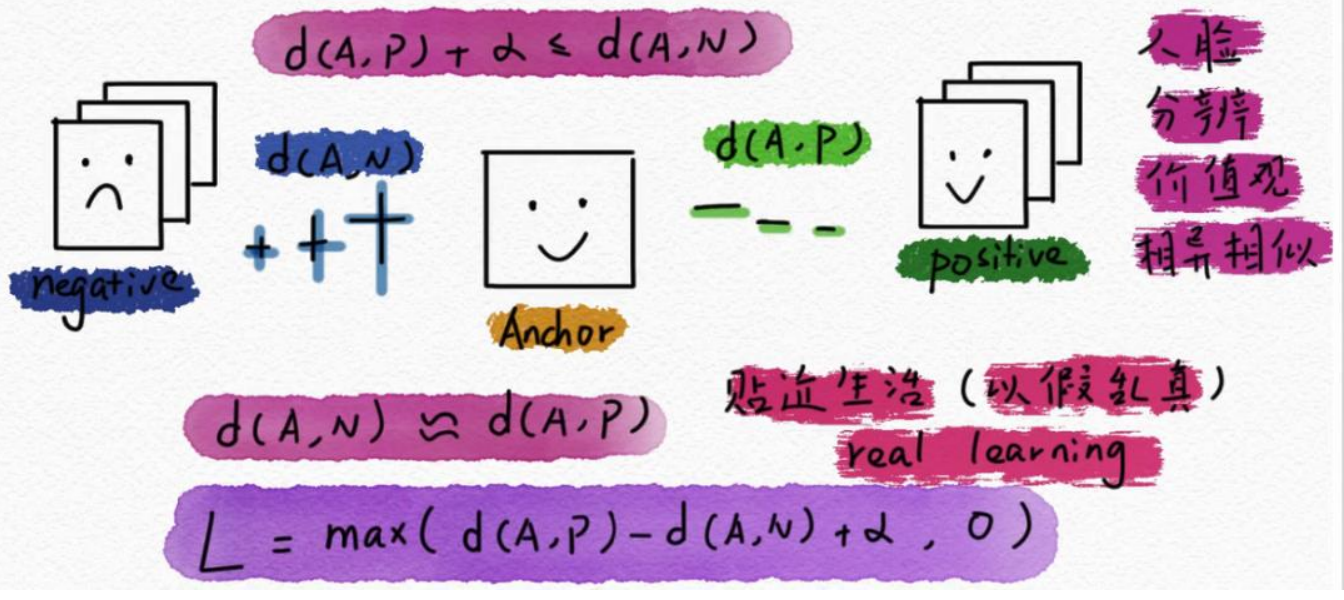
- 有一个中间标志物,来计算距离
具体地,对于一个三元组(anchor,positive,negative),其中anchor是一个样本,positive是同一类别的样本,negative是不同类别的样本。
- Triplet Loss的计算方式是:L = max(d(a, p) - d(a, n) + margin, 0)
其中,d(a, p)表示anchor和positive之间的距离,d(a, n)表示anchor和negative之间的距离,margin是一个预先设定的常数,用于控制不同类别之间的距离。
Triplet Loss的目标是使同一类别的样本之间的距离尽可能小,不同类别之间的距离尽可能大。
- 如果anchor和positive之间的距离小于anchor和negative之间的距离加上margin,那么这个三元组就是有效的,损失函数的值为0。
- 如果anchor和positive之间的距离大于anchor和negative之间的距离加上margin,那么这个三元组就是无效的,损失函数的值为d(a, p) - d(a, n) + margin。
在训练过程中,我们需要从样本集中选择大量的三元组,然后通过最小化所有有效三元组的损失函数来更新模型参数,从而使模型学习到更好的特征表示。

- 敏感度低,不能限制单个样本,也就是一定会有样本分错
- 算损失,首先要在全部训练集上构造二元/三元组的开销很大
Center Loss
Center Loss是一种用于人脸识别、目标检测等任务中的监督学习方法。
- 它的原理是在深度神经网络的训练过程中,通过对每个类别的中心进行约束,来增强特征的判别能力。
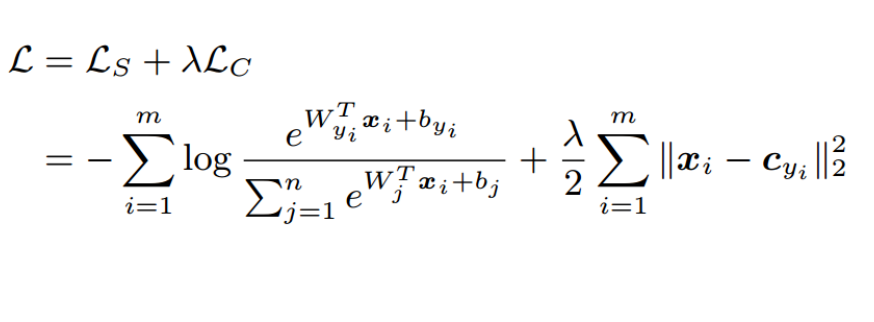
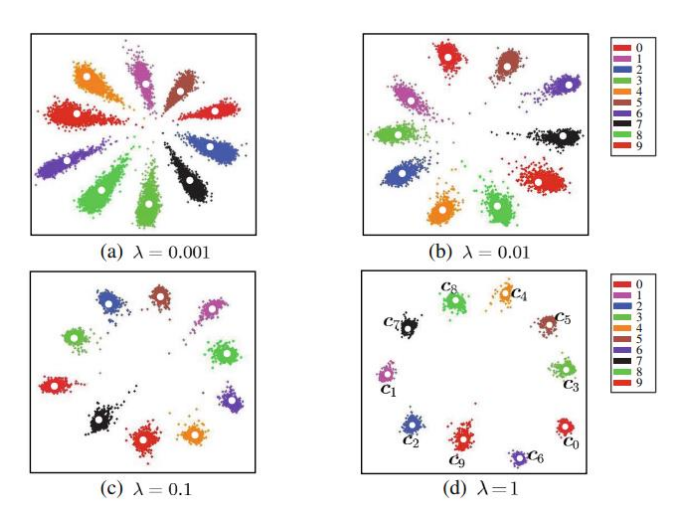
具体来说,Center Loss会为每个类别维护一个中心向量,该向量的维度与特征向量的维度相同。在训练过程中,对于每个样本,它的特征向量会被送入网络进行前向传播,在最后一层得到一个特征向量。然后,该特征向量会被用来更新该样本所属类别的中心向量。
- Center Loss的目标是最小化每个样本的特征向量与其所属类别的中心向量之间的欧几里得距离。
这个距离可以被看作是样本与其所属类别的“距离”,Center Loss的优化目标就是让同一类别的样本的特征向量更接近其中心向量,不同类别的样本的特征向量则更远离彼此的中心向量。
通过这种方式,Center Loss可以使得特征向量更好地区分不同的类别,从而提高分类的准确性。同时,由于中心向量是在训练过程中动态更新的,所以Center Loss也具有一定的适应性,可以应对数据分布的变化。