文章目录
- 问题描述
- 知识点收集
- mongo的操作符:
- 匹配符:
- 选择符:
- 函数操作:
- 更新符:
- 聚集符:
- 字段操作符:
问题描述
给parts列表新增字典
新增前:

新增后:
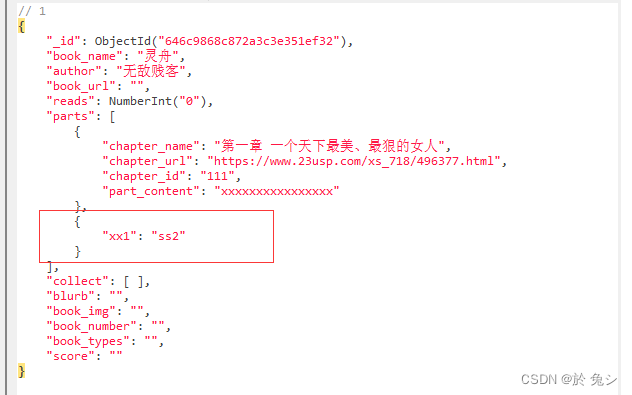
代码:
mongo_client = get_mongo_client()
col = mongo_client.col_test # 创建/进入集合
data = {
"book_name": "灵舟",
"author": "无敌贱客",
"book_url": "",
"reads": 0, # 阅读人数
"parts": [
{
'chapter_name': '第一章 一个天下最美、最狠的女人',
'chapter_url': 'https://www.23usp.com/xs_718/496377.html',
'chapter_id': "111",
"part_content": "xxxxxxxxxxxxxxxx"
},
], # 章节
"collect": [], # 收藏
"blurb": "", # 简介
"book_img": "", # 书籍封面
"book_number": "", # 书籍字数
"book_types": "", # 书籍类型
"score": "", # 书籍评分
}
# col.insert_one(data) # 插入数据
parts_data = {
"$addToSet": {"parts": {"xx1": "ss2"}} # 是向数组对象中添加元素和值,操作对象必须为数组类型的字段
}
workflow2 = col.update_one(
{"book_name": "灵舟"}, parts_data)
print(workflow2)
query = col.find({}, {"parts.part_content": 0})
for i in query:
print(i)
# 控制台的打印
# <pymongo.results.UpdateResult object at 0x0000026853CF3FD0>
# {'_id': ObjectId('646c9868c872a3c3e351ef32'), 'book_name': '灵舟', 'author': '无敌贱客', 'book_url': '', 'reads': 0, 'parts': [{'chapter_name': '第一章 一个天下最美、最狠的女人', 'chapter_url': 'https://www.23usp.com/xs_718/496377.html', 'chapter_id': '111'}, {'xx1': 'ss2'}], 'collect': [], 'blurb': '', 'book_img': '', 'book_number': '', 'book_types': '', 'score': ''}
知识点收集
mongo的操作符:
来源于: https://doc.sequoiadb.com/cn/sequoiadb-cat_id-1432190898-edition_id-306
匹配符:
匹配符可以指定匹配条件,使查询仅返回符合条件的记录;还可以与函数操作配合使用,以实现更复杂的匹配操作。
匹配符列表如下:
| 匹配符 | 描述 | 示例 |
|---|---|---|
| $gt | 大于 | db.sample.employee.find( { age: { $gt: 20 } } ) |
| $gte | 大于等于 | db.sample.employee.find( { age: { $gte: 20 } } ) |
| $lt | 小于 | db.sample.employee.find( { age: { $lt: 20 } } ) |
| $lte | 小于等于 | db.sample.employee.find( { age: { $lte: 20 } } ) |
| $ne | 不等于 | db.sample.employee.find( { age: { $ne: 20 } } ) |
| $in | 集合内存在 | db.sample.employee.find( { age: { $in: [ 20, 21 ] } } ) |
| $nin | 集合内不存在 | db.sample.employee.find( { age: { $nin: [ 20, 21 ] } } ) |
| $all | 全部 | db.sample.employee.find( { age: { $all: [ 20, 21 ] } } ) |
| $and | 与 | db.sample.employee.find( { $and: [ { age: 20 }, { name: “Tom” } ] } ) |
| $not | 非 | db.sample.employee.find( { $not: [ { age: 20 }, { name: “Tom” } ] } ) |
| $or | 或 | db.sample.employee.find( { $or: [ { age: 20 }, { name: “Tom” } ] } ) |
| $exists | 存在 | db.sample.employee.find( { age: { $exists: 1 } } ) |
| $elemMatch | 元素匹配 | db.sample.employee.find( { content: { $elemMatch: { age: 20 } } } ) |
| $+标识符 | 数组元素匹配 | db.sample.employee.find( { “array.$2”: 10 } ) |
| $regex | 正则表达式 | db.sample.employee.find( { str: { $regex: ‘dh, * fj’, $options:‘i’ } } ) |
| $mod | 取模匹配 | db.sample.employee.find( { “age”: { “$mod”: [ 5, 3 ] } } ) |
| $et | 相等匹配 | db.sample.employee.find( { “id”: { “$et”: 1 } } ) |
| $isnull | 选择集合中指定字段是否为空或不存在 | db.sample.employee.find( { age: { $isnull: 0 } } ) |
数组属性操作
| 数组属性操作 | 描述 | 示例 |
|---|---|---|
| $expand | 数组展开成多条记录 | db.sample.employee.find( { a: { $expand: 1 } } ) |
| $returnMatch | 返回匹配的数组元素 | db.sample.employee.find( { a: { $returnMatch: 0, $in: [ 1, 4, 7 ] } } ) |
选择符:
实现对查询的结果字段进行拆分、筛选等功能
选择符可以实现对查询的结果字段进行拆分、筛选等功能。在选择符中使用函数操作还能实现对结果的重写和转换等操作。
支持的选择符如下:
| 选择符 | 描述 | 示例 |
|---|---|---|
| $include | 选择或移除某个字段 | db.sample.employee.find({}, {“a”: {“$include”: 1}}) |
| $default | 当字段不存在时返回默认值 | db.sample.employee.find({}, {“a”: {“$default”: “myvalue”}}) |
| $elemMatch | 返回数组或者对象中满足条件的元素集合 | db.sample.employee.find({}, {“a”: {“$elemMatch”: {“a”: 1}}}) |
| $elemMatchOne | 返回数组或者对象中满足条件的第一个元素 | db.sample.employee.find({}, {“a”: {“$elemMatchOne”: {“a”: 1}}}) |
函数操作:
配合匹配符和选择符使用,以实现更复杂的功能
函数操作可以配合匹配符和选择符使用,以实现更复杂的功能。
-
配合匹配符一起使用,可以对字段进行各种函数运算之后,再执行匹配操作。
以下示例,匹配字段 a 长度为 3 的记录:
> db.sample.employee.find({a:{$strlen:1, $et:3}})Copy
Note:
先获取字段 a 的长度,再用该长度与 3 比较,返回长度为 3 的记录。
-
作为选择符使用,可以对选取的字段进行函数运算,返回运算后的结果。
以下示例,返回将字段 a 转大写的结果:
> db.sample.employee.find({}, {a:{$upper:1}})Copy
所有支持的函数操作如下:
| 函数 | 描述 | 示例 |
|---|---|---|
| $abs | 取绝对值 | db.sample.employee.find({}, {a:{$abs:1}}) |
| $ceiling | 向上取整 | db.sample.employee.find({}, {a:{$ceiling:1}}) |
| $floor | 向下取整 | db.sample.employee.find({}, {a:{$floor:1}}) |
| $mod | 取模运算 | db.sample.employee.find({}, {a:{$mod:1}}) |
| $add | 加法运算 | db.sample.employee.find({}, {a:{$add:10}}) |
| $subtract | 减法运算 | db.sample.employee.find({}, {a:{$subtract:10}}) |
| $multiply | 乘法运算 | db.sample.employee.find({}, {a:{$multiply:10}}) |
| $divide | 除法运算 | db.sample.employee.find({}, {a:{$divide:10}}) |
| $substr | 截取子串 | db.sample.employee.find({}, {a:{$substr:[0,4]}}) |
| $strlen | 获取指定字段的字节数 | db.sample.employee.find({}, {a:{$strlen:10}}) |
| $strlenBytes | 获取指定字段的字节数 | db.sample.employee.find({}, {a:{$strlenBytes:10}}) |
| $strlenCP | 获取指定字段的字符数 | db.sample.employee.find({}, {a:{$strlenCP:10}}) |
| $lower | 字符串转为小写 | db.sample.employee.find({}, {a:{$lower:1}}) |
| $upper | 字符串转为大写 | db.sample.employee.find({}, {a:{$upper:1}}) |
| $ltrim | 去除左侧空格 | db.sample.employee.find({}, {a:{$ltrim:1}}) |
| $rtrim | 去除右侧空格 | db.sample.employee.find({}, {a:{$rtrim:1}}) |
| $trim | 去除左右两侧空格 | db.sample.employee.find({}, {a:{$trim:1}}) |
| $cast | 转换字段类型 | db.sample.employee.find({}, {a:{$cast:“int32”}}) |
| $size | 获取数组元素个数 | db.sample.employee.find({}, {a:{$size:1}}) |
| $type | 获取字段类型 | db.sample.employee.find({}, {a:{$type:1}}) |
| $slice | 截取数组元素 | db.sample.employee.find({}, {a:{$slice:[0,2]}}) |
函数操作可以支持流水线式处理,多个函数流水线执行:
> db.sample.employee.find({a:{$trim:1, $upper:1, $et:"ABC"}})
Copy
Note:
先对字段 a 去除左右两侧空格,然后再转换成大写,最后匹配与"ABC"相等的记录
当字段类型为数组类型时,函数会对该字段做一次展开,并对每个数组元素执行函数操作。
以取绝对函值函数为例:
> db.sample.employee.find()
{
"a": [
1,
-3,
-9
]
}
> db.sample.employee.find({}, {a:{$abs:1}})
{
"a": [
1,
3,
9
]
}
更新符:
实现对字段的添加、修改和删除操作
更新符可以实现对字段的添加、修改和删除操作,SequoiaDB 巨杉数据库支持的更新符如下:
| 更新符 | 描述 | 示例 |
|---|---|---|
| $inc | 增加指定字段的值 | db.sample.employee.update({KaTeX parse error: Expected 'EOF', got '}' at position 17: …nc:{age:5,ID:1}}̲,{age:{gt:15}}) |
| $set | 将指定字段更新为指定的值 | db.sample.employee.update({$set:{str:“abd”}}) |
| $unset | 删除指定的字段 | db.sample.employee.update({$unset:{name:“”,age:“”}}) |
| $bit | 将指定字段的值与指定的值进行位运算 | db.sample.employee.update({$bit:{a:{xor:5}}}) |
| $rename | 将指定字段重命名 | db.sample.employee.update({$rename:{‘a’:‘c’,‘b’:‘d’}}) |
| $addtoset | 向数组中添加元素和值 | db.sample.employee.update({KaTeX parse error: Expected 'EOF', got '}' at position 23: …t:{arr:[1,3,5]}}̲,{arr:{exists:1}}) |
| $pop | 删除指定数组中的最后N个元素 | db.sample.employee.update({$pop:{arr:2}}) |
$pull $pull_by | 清除指定数组中的指定值 | db.sample.employee.update({KaTeX parse error: Expected 'EOF', got '}' at position 24: …r:2,name:"Tom"}}̲) db.sample.emp…pull_by:{arr:2,name:“Tom”}}) |
$pull_all $pull_all_by | 清除指定数组中的指定值 | db.sample.employee.update({KaTeX parse error: Expected 'EOF', got '}' at position 34: …],name:["Tom"]}}̲) db.sample.emp…pull_all_by:{arr:[2,3],name:[“Tom”]}}) |
| $push | 将给定值插入到数组中 | db.sample.employee.update({$push:{arr:1}}) |
| $push_all | 向指定数组中插入所有给定值 | db.sample.employee.update({$push_all:{arr:[1,2,8,9]}}) |
| $replace | 将集合中除 _id 字段和自增字段外的文档内容全部替换 | db.sample.employee.update({KaTeX parse error: Expected 'EOF', got '}' at position 31: …name:'default'}}̲,{age:{exists:0}}) |
聚集符:
配合 aggregate() 使用,计算集合中数据的聚合值
SequoiaDB 巨杉数据库支持以下聚集符:
| 参数名 | 描述 | 示例 |
|---|---|---|
| $project | 选择需要输出的字段名,1 表示输出,0 表示不输出,还可以实现字段的重命名 | { KaTeX parse error: Expected '}', got 'EOF' at end of input: …d: 0, aliase: "field3" } } |
| $match | 实现从集合中选择匹配条件的记录,相当于 SQL 语句的 where | {$match: { field: { $lte: value } } } |
| $limit | 限制返回的记录条数 | { $limit: 10 } |
| $skip | 控制结果集的开始点,即跳过结果集中指定条数的记录 | { $skip: 5 } |
| $group | 实现对记录的分组,类似于 SQL 的 group by 语句,_id 指定分组字段 | { KaTeX parse error: Expected '}', got 'EOF' at end of input: group: { _id: "field" } } |
| $sort | 实现对结果集的排序,1 代表升序,-1 代表降序 | { $sort: { field1: 1, field2: -1, … } } |
Note:
聚集符的使用方法可以参考 SdbCollection.aggregate()。
字段操作符:
实现对字段值进行匹配查询、修改等功能
字段操作符可以实现对字段值进行匹配查询、修改等功能,SequoiaDB 巨杉数据库支持以下字段操作符:
| 参数名 | 描述 | 示例 |
|---|---|---|
| $field | 取出指定字段的值,应用于其它操作 | ({KaTeX parse error: Expected '}', got 'EOF' at end of input: … {t1: {Value: {field: “t2”}}}}) |