文章目录
- 一、JAVA的序列化
- 1. 简介
- 2. 对象序列化的步骤
- 3. 小结
- 4. 序列化
- 4. 解序列化
- 二、对象的序列化
- 1. 简介
- 2. Java.io.File.class
- 3. 缓冲区
- 三、序列化版本控制
一、JAVA的序列化
1. 简介
如何将我们的java对象存储起来,这里介绍两种思路:
- 如果我们只有自己写的java程序会用到这些数据:此时我们就可以用序列化,将被序列化的对象写到文件中,然后就可以让你的程序去文件中读取序列化的对象并把它们展开回到活生生的状态。
- 如果数据需要被其他程序引用:写一个纯文本文件,用其他程序可以解析的特殊字符写到文件中。
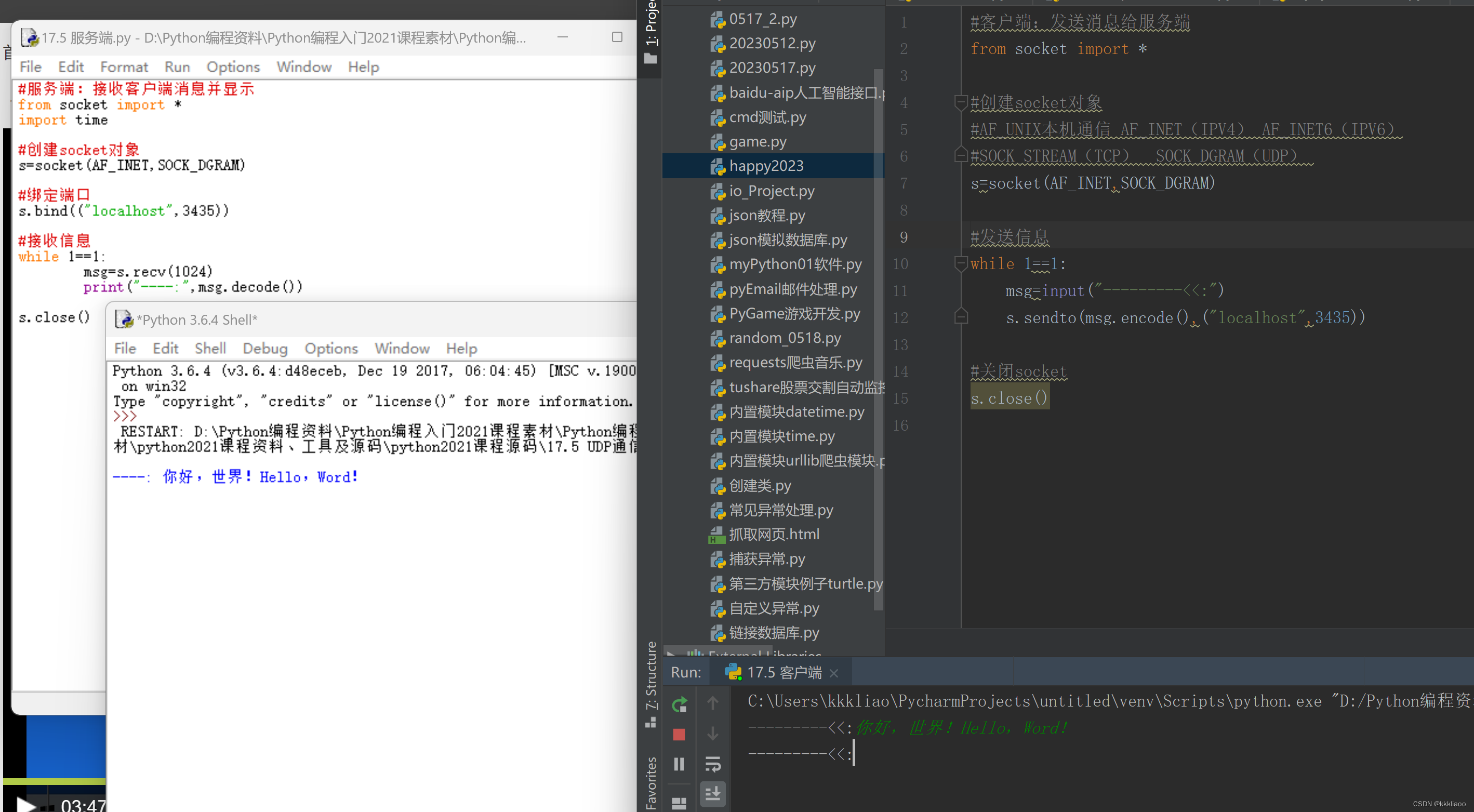
Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化,也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。整个过程都是 Java 虚拟机(JVM)独立的,也就是说,在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化该对象。类 ObjectInputStream 和 ObjectOutputStream 是高层次的数据流,它们包含反序列化和序列化对象的方法。
2. 对象序列化的步骤
- 创建出FileOutPutStream
FileOutputStream fileStream = new FileOutputSream("MyGame.ser")
- 创建ObjectOutputStream
ObjectOutputStream os=new ObjectOutputStream(fileStream);
- 写入对象
os.writeObject(characterOne)
- 关闭ObjectOutputStream
os.close()
将串流(Stream)连接起来代表源与目的地(文件或网络端口)的连接。串流必须要连接到某处才能算是个串流,一般来说,串流要两两连接才能做出有意义的事,其中一个代表连接,另一个则是要被调用方法,因为连接的串流通常都是很底层的。以FileOutStream为例,它有可以写入字节的方法。但我们通常不会直接去写字节,而是以对象层次的观点来写入,所以需要高层的连接串流。那为什么不以单一的串流来执行?这就要考虑到良好的面向对象设计了,每个类只要做好一件事。FileOutputStream把字节写入文件,ObjectOutputStream把对象转换成可以写入串流的数据。当我们调用ObjectOutputStream的writeObject方法时,对象就会被打成串流送到FileOutputStream中来写入文件中。
3. 小结
Java序列化是将Java对象转换为字节流的过程,以便在网络上传输或保存到磁盘中。序列化的主要目的是实现对象的持久化存储和传输,即使在不同的操作系统和编程语言之间也能保持对象的一致性。以下是Java序列化的几个重要意义:
-
持久化存储:通过序列化,可以将对象保存到磁盘上或数据库中,以便在程序重新启动或在不同的应用程序之间共享数据。这对于需要长期存储和检索数据的应用程序非常有用,例如文件系统、缓存系统和持久化框架。
-
网络传输:在网络编程中,通过序列化,可以将Java对象转换为字节流,然后通过网络传输到远程机器上。这种方式在分布式系统、客户端-服务器应用程序和远程方法调用(RPC)中非常常见。通过序列化,可以轻松地在不同的计算机之间传递对象,并在远程机器上进行反序列化以还原对象。
-
对象复制:通过序列化,可以实现对象的深层复制。当需要创建一个已有对象的独立副本时,序列化提供了一种简单而有效的方法。通过将对象序列化到字节流中,然后再从字节流中反序列化,可以获得一个与原始对象相同的副本。
-
缓存和缓存共享:序列化可以用于实现缓存系统,将经过计算的对象序列化并保存在内存中,以便下次需要时可以快速检索。此外,序列化还可以实现将缓存数据共享到不同的应用程序实例或服务器之间,以提高系统性能和减少重复计算。
尽管Java序列化具有上述优点,但它也有一些限制。例如,序列化的性能相对较低,并且对于频繁变化的对象结构可能不稳定。此外,Java序列化还存在安全性和版本兼容性的考虑因素。因此,在使用Java序列化时,需要谨慎考虑这些因素,并评估是否有更好的替代方案,例如JSON、XML或Protocol Buffers等。
4. 序列化
当一个对象被序列化时,被该对象引用的实例变量也会被序列化。且所有被引用的对象也会被序列化,且这些操作都是自动进行的。如果要让类能够被序列化,该类就需要实现Serializable接口。
Serializable接口又被称为marker或tag类标记用接口,因为此接口并没有任何方法需要实现,它的唯一目的就是声明有实现它的类是可以被序列化的。也就是说,此类型的对象可以通过序列化的机制来存储。如果某类是可序列化的,则它的子类也是可以序列化的(类的继承关系可以知道)
//Serializable接口源码
public interface Serializable {
}
public class Main {
public static void main(String[] args) throws InterruptedException {
Box mybox=new Box();
mybox.setHeight(50);
mybox.setWidth(20);
try {
//定义文件输出流
FileOutputStream fs=new FileOutputStream("foo.ser");
ObjectOutputStream os=new ObjectOutputStream(fs);
os.writeObject(mybox);
os.close();
}catch (Exception ex){
ex.printStackTrace();
}
}
}
class Box implements Serializable{
private int width;
private int height;
public void setWidth(int width) {
this.width = width;
}
public void setHeight(int height) {
this.height = height;
}
}
如果某类的某实例变量不能或不应该被实例化,我们可以使用
transient关键字对其标记,序列化程序会自动跳过
4. 解序列化
将对象序列化整个事情的重点在于你可以事后,在不同Java虚拟机执行期,把对象恢复到存储时的状态。解序列化的步骤如下:
- 创建FileInputStream
FileInputStream fileStream =new FileInputStream("mygame.ser")
- 创建ObjectInputStream
ObjectInputStream os=new ObjectInputStream(fileStream);
- 读取对象
//该方法会从Stream中读出下一个对象,读取顺序会和写入顺序相同,次数超过会抛出异常
Object one=os.readObject();
- 转换对象类型
myObject mot=(myObject) one;
- 关闭流
当对象被解序列化时,Java虚拟机会通过尝试在堆上创建新的对象,让它维持与被序列化时有相同的状态来恢复对象的原状(说明对象反序列化是多例的,它会创建新的对象)。所以解序列化底层的过程其实是下面这样:
- 对象从stream中读出来
- Jvm通过存储的信息判断出对象的class类型
- Jvm虚拟机尝试寻找和加载对象的类。如果Java虚拟机找不到或无法加载该类,则Java虚拟机会抛出异常
- 新的对象会被配置在堆上,但构造函数不会执行!很明显的,这样会把对象的状态抹去又变成全新的,而这不是我们想要的结果,我们需要对象回到序列化之前的状态
- 如果对象在继承树上有个不可序列化的祖先类,则该不可序列化类以及在它之上的类的构造函数(就算是可序列化也一样)就会执行。一旦构造函数连锁启动后就无法停止。也就是说,从第一个不可序列化的父类开始,全部都会重新初始状态
- 对象的实例变量会被还原成序列化时的状态值,transient变量会被赋值为null的对象引用或primitive主类型的默认为0、false等值
public class Main {
public static void main(String[] args) throws InterruptedException {
GameCharacter one=new GameCharacter(50,"Elf",new String[]{"bow","sword","dust"});
GameCharacter two=new GameCharacter(200,"Troll",new String[]{"bare hands","big ax"});
GameCharacter three=new GameCharacter(120,"Magician",new String[]{"spelld","invisibility"});
System.out.println("序列化之前的one的hash值:"+one.hashCode());
try{
ObjectOutputStream os=new ObjectOutputStream(new FileOutputStream("Game.ser"));
os.writeObject(one);
os.writeObject(two);
os.writeObject(three);
os.close();
}catch (Exception e){
e.printStackTrace();
}
//设置成null,因此无法获取堆上的这些对象
one=null;
two=null;
three=null;
try{
ObjectInputStream is=new ObjectInputStream(new FileInputStream("Game.ser"));
GameCharacter oneRestore=(GameCharacter) is.readObject();
GameCharacter twoRestore=(GameCharacter) is.readObject();
GameCharacter threeRestore=(GameCharacter) is.readObject();
System.out.println("One`s type:"+oneRestore.getType());
System.out.println("反序列化之后的one的hash值:"+oneRestore.hashCode());
}catch (Exception e){
e.printStackTrace();
}
}
}
class GameCharacter implements Serializable{
int power;
String type;
String[] weapons;
public GameCharacter(int p,String t, String[] w){
power=p;
type=t;
weapons=w;
}
public int getPower(){
return power;
}
public String getType(){
return type;
}
public String getWeapons(){
String weaponList="";
for (int i = 0; i < weapons.length; i++) {
weaponList+=weapons[i]+"";
}
return weaponList;
}
}

从结果来看,序列化之前和反序列化之后的对象并不是同一个,但状态是一样的
二、对象的序列化
1. 简介
通过序列化来存储对象是Java程序在来回执行间存储和恢复数据最简单的方法。但有时你还得把数据存储到单纯的文本文件中。假设你的Java程序必须把数据写到文本文件中以让其他可能是非java的程序读取。假设你的Servlet(在web服务器上执行的Java程序)会读取用户在网页上输入的数据,并将它写入文本文件以让网站管理入能够用电子表格来分析数据。
2. Java.io.File.class
File这个类代表磁盘上的文件,但并不是文件中的内容。你可以把File对象想象成文件的路径,而不是文件本身。例如File并没有读写文件的方法。关于File有个很有用的功能是它提供一种比使用字符串文件名来表示文件名的类也可以用File对象来代替该参数,以便检查路径是否合法,然后再把对象传给FileWriter或FileInputStream,下面是File的常用使用:
- 创建出代表现存盘文件的File对象
File f=new File("MyCode.txt")
- 建立新的目录
File dir=new File("Chapter7")
- 列出目录下的内容
if(dir.isDirectory()){
{
String[] dirContents=dir.list();
for(int i=0;i<dirContents.length;i++){
System.out.println(dirContents[i]);
}
}
- 取得文件或目录的绝对路径
System.out.println(dir.getAbsolutePath());
- 删除文件或目录
boolean isDeleted=f.delete();
3. 缓冲区
缓冲区的奥妙之处在于使用缓冲区比没有缓冲区的效率更好。你也可以直接使用FileWriter,调用它的write()来写文件,但它每次都会直接写下去。而通过BufferedWriter和FileWriter的链接,BufferedWriter可以暂存一堆数据,然后到满的时候再实际写入磁盘,这样就可以减少对磁盘的操作的次数。如果你想要强制缓冲区立即写入,只要调用writer.flush()这个方法就可以要求缓冲区马上把内容写下去。BufferedReader是Java IO包中用于读取字符数据的缓冲输入流。它提供了对底层输入流的缓冲读取,以提高读取性能。下面是BufferedReader缓存原理的简要说明:
-
缓冲区:BufferedReader内部维护了一个字符缓冲区(char数组),用于临时存储从底层输入流读取的字符数据。缓冲区的大小可以根据需要进行配置,默认为8192个字符。
-
填充缓冲区:当我们调用BufferedReader的读取方法(如read()、readLine())时,它会尝试从缓冲区中读取字符数据。如果缓冲区已经为空,它会从底层输入流中读取一定数量的字符数据,并将其存储到缓冲区中。
-
读取缓冲区:一旦缓冲区中有数据,BufferedReader会直接从缓冲区返回所需的字符数据,而无需每次都直接访问底层输入流。这样可以减少对底层输入流的频繁读取操作,提高读取效率。
-
缓冲区管理:当缓冲区中的数据被读取完毕后,BufferedReader会再次尝试从底层输入流中读取新的字符数据,并填充到缓冲区中,以供后续读取操作使用。这个过程在需要的时候会自动进行,我们不需要手动管理缓冲区。
通过使用缓冲区,BufferedReader实现了批量读取字符数据,减少了对底层输入流的频繁读取操作,从而提高了读取的效率。缓冲区的大小可以根据需要进行调整,以平衡内存消耗和读取性能。需要注意的是,在使用BufferedReader读取字符数据时,我们应该使用其提供的读取方法(如read()、readLine()),而不是直接操作底层输入流。这样可以确保数据按照缓冲区的方式进行读取,以获得更好的性能和可靠性。总结而言,BufferedReader通过内部的字符缓冲区实现了对底层输入流的缓冲读取,减少了IO操作次数,提高了读取性能。BufferedWriter是Java IO包中用于写入字符数据的缓冲输出流。它提供了对底层输出流的缓冲写入,以提高写入性能。下面是BufferedWriter的工作原理的简要说明:
-
缓冲区:BufferedWriter内部维护了一个字符缓冲区(char数组),用于临时存储待写入底层输出流的字符数据。缓冲区的大小可以根据需要进行配置,默认为8192个字符。
-
写入缓冲区:当我们调用BufferedWriter的写入方法(如write()、append())时,它会将待写入的字符数据暂时存储到缓冲区中。
-
刷新缓冲区:当缓冲区被填满或我们显式调用flush()方法时,BufferedWriter会将缓冲区中的数据一次性写入底层输出流。这样可以减少对底层输出流的频繁写入操作,提高写入效率。
-
关闭流:当我们调用BufferedWriter的close()方法关闭流时,它会先自动调用flush()方法将缓冲区中的剩余数据写入底层输出流,然后关闭底层输出流。
通过使用缓冲区,BufferedWriter实现了批量写入字符数据,减少了对底层输出流的频繁写入操作,从而提高了写入的效率。缓冲区的大小可以根据需要进行调整,以平衡内存消耗和写入性能。需要注意的是,在使用BufferedWriter写入字符数据时,我们应该使用其提供的写入方法(如write()、append()),而不是直接操作底层输出流。这样可以确保数据按照缓冲区的方式进行写入,以获得更好的性能和可靠性。总结而言,BufferedWriter通过内部的字符缓冲区实现了对底层输出流的缓冲写入,减少了IO操作次数,提高了写入性能。
-
准备一个txt文件
-
读取文件文件
public class QuizCardBuilder {
public static void main(String[] args) {
try {
File myfile=new File("MyText.txt");
FileReader fileReader=new FileReader(myfile);
//将FileReader链接到BufferdReader以获取更高的效率,它只会在缓冲区空的时候才会去磁盘取
BufferedReader reader=new BufferedReader(fileReader);
String line=null;
while((line=reader.readLine())!=null ){
System.out.println(line);
}
reader.close();
}catch (Exception e){
e.printStackTrace();
}
}
}

三、序列化版本控制
serialVersionUID是Java中用于序列化和反序列化对象的一个特殊属性,它是一个静态常量,用于标识类的版本。在Java的序列化机制中,每个可序列化的类都被赋予一个唯一的标识符,即serialVersionUID。它用于判断序列化的对象与反序列化时使用的类定义是否兼容。以下是serialVersionUID的一些特点和使用方式:
-
版本控制:serialVersionUID用于控制类的版本。当一个类进行了更改,如添加或删除字段、修改方法等,serialVersionUID的值也应相应更改。通过版本控制,可以确保序列化和反序列化的兼容性,防止因类定义的更改而导致的版本冲突。
-
默认值生成:如果在类定义中未显式声明serialVersionUID,Java序列化机制会自动生成一个值。生成规则基于类的结构,如类名、字段和方法等。这种自动生成的serialVersionUID对于不涉及版本控制的简单场景可能是足够的。
-
显式声明:可以在类定义中显式声明serialVersionUID,通过指定一个固定的值来控制版本。在进行序列化和反序列化时,Java会比较序列化对象的serialVersionUID与反序列化时使用的类定义的serialVersionUID,如果两者不匹配,则会抛出InvalidClassException。
-
序列化兼容性:当对一个已序列化的对象进行反序列化时,Java会通过比较对象的serialVersionUID与当前类定义的serialVersionUID来判断兼容性。如果两者匹配,则可以成功反序列化;如果不匹配,则会抛出InvalidClassException。
注意事项:序列化和反序列化的兼容性要求类的结构和逻辑保持一致,即不能改变类的实例变量和方法的签名。
如果类定义中未显式声明serialVersionUID,并且进行了类结构的更改,如添加或删除字段等,反序列化时可能会导致InvalidClassException。为避免此问题,建议在进行类结构更改时显式声明serialVersionUID并进行版本控制。
总结而言,serialVersionUID是用于版本控制和兼容性验证的一个特殊属性,在Java的序列化和反序列化过程中起着重要的作用。通过正确管理和使用serialVersionUID,可以确保序列化和反序列化的正确性和兼容性。
- 首先进行序列化
public class QuizCardBuilder {
public static void main(String[] args) {
dog mydog=new dog();
try {
//定义文件输出流
FileOutputStream fs=new FileOutputStream("foo2.ser");
ObjectOutputStream os=new ObjectOutputStream(fs);
os.writeObject(mydog);
os.close();
}catch (Exception ex){
ex.printStackTrace();
}
}
}
class dog implements Serializable{
static final long serialVersionUID=21321312L;
private String name;
private int size;
}
- 查看序列化版本
serialver dog

- 更改代码结构查看会不会出问题
class dog implements Serializable{
static final long serialVersionUID=21321313L;
private String name;
private int size;
private int age;
}
- 反序列化
public class QuizCardBuilder {
public static void main(String[] args) {
dog mydog=null;
try{
ObjectInputStream is=new ObjectInputStream(new FileInputStream("foo2.ser"));
dog oneRestore=(dog) is.readObject();
}catch (Exception e){
e.printStackTrace();
}
}
}
出现版本不一致问题





![[论文阅读72]Parameter-Efficient Transfer Learning for NLP](https://img-blog.csdnimg.cn/img_convert/304a147bc5561db67d63e09b31a605f0.png)