【追梦之旅】— 堆的实际应用--TopK问题😎
- 前言🙌
- 堆的TopK问题的现实栗子
- 堆的TopK思路的应用场景
- 堆的TopK思路的具体实现
- fscanf函数
- fprintf函数
- 堆的TopK具体实现代码:
- 前K个数据的巧妙设置
- 运行结果截图:
- 总结撒花💞

😎博客昵称:博客小梦
😊最喜欢的座右铭:全神贯注的上吧!!!
😊作者简介:一名热爱C/C++,算法等技术、喜爱运动、热爱K歌、敢于追梦的小博主!
😘博主小留言:哈喽!😄各位CSDN的uu们,我是你的博客好友小梦,希望我的文章可以给您带来一定的帮助,话不多说,文章推上!欢迎大家在评论区唠嗑指正,觉得好的话别忘了一键三连哦!😘

前言🙌
哈喽各位友友们😊,我今天又学到了很多有趣的知识,现在迫不及待的想和大家分享一下!😘我仅已此文,介绍有关堆的实际应用–TopK问题~ 都是精华内容,可不要错过哟!!!😍😍😍
堆的TopK问题的现实栗子
堆是一种在日常开发中,经常被使用到的一种数据结构,也可以说和我们的生活息息相关。例如,我们点外卖时,美团这些外卖软件并不会将所有的店家都展示在页面上,它会有推荐店家页面,我们只能在页面直接上看到这些推荐的店家。而这一功能的实现就是因为其底层的代码应用了堆TopK的思想 + 排序。还有就是我们玩游戏的时候,也有战力榜、富豪榜、等等,这些功能的设计代码都应用到了堆的知识。
堆的TopK思路的应用场景
TopK的应用场景:简单来说,TopK的应用场景是用于大数据量前提下,选出前K个数据的业务场景。像一些比较大型的软件上,实现推荐功能或者一些大型软件上的Top排行榜等等。
堆的TopK思路的具体实现
我们这里设计是实现在文件上的数据进行Top思路的实现。为什么直接在内存上进行呢,这样编写不是更简单吗?其实这是有其原因存在的。因为我们的TopK的应用场景是大数据量的情况下,选出前k个数据的。我们知道,内存的空间是有限的,它不能存储很大量的数据。而文件是存储在磁盘上的,存储空间上比内存要大的多。我们的业务数据都是放在数据库进行管理的,学过数据库的都知道数据库中的数据也是存放到的磁盘上的,就是因为内存空间小的这个局限性。
- 在这里了我们是对数字的实现TopK。进行文件中整型数据的读和写,我们需要使用到的函数是fscanf和fprintf
- 建堆有两种算法:1、向上调整算法 ;2、向下调整算法。尽管数学公式的推算证明(错位相减法+二叉树结构特点),向上调整算法的建时间复杂度是:O( n*logn)。向下调整算法的时间复杂度是O(n) 。显然,用向下调整算法是更优的,等下我们实现也是用堆的TopK也是利用向下调整算法。
fscanf函数
-
fsanf函数的接口

-
fscanf函数的返回值

当读取到文件末尾时,fscanf函数会返回一个EOF。
fprintf函数
- fprintf函数的接口

- fprintf函数函数的返回

堆的TopK具体实现代码:
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
void CreateNDate()
{
// 造数据
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
void Swap(int* p1, int* p2)
{
int tem = *p1;
*p1 = *p2;
*p2 = tem;
}
void AdjustDown(int* a, int k, int parent)
{
int child = parent * 2 + 1;
while (child < k)
{
if (child + 1 < k && a[child + 1] < a[child])
{
child++;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void PrintTopk(int k)
{
int* topk = (int*)malloc(sizeof(int) * k);
const char* file = "data.txt";
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
perror("fopen fail!\n");
return;
}
//读k个数据
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &topk[i]);
}
//建堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(topk, k, i);
}
int val = 0;
int ret = fscanf(fout, "%d", &val);
while (ret != EOF)
{
if (val > topk[0])
{
topk[0] = val;
AdjustDown(topk, k, 0);
}
ret = fscanf(fout, "%d", &val);
}
for (int i = 0; i < k; i++)
{
printf("%d ", topk[i]);
}
printf("\n");
free(topk);
fclose(fout);
}
int main()
{
//CreateNDate();
PrintTopk(10);
return 0;
}
前K个数据的巧妙设置
需要注意的是:在造数据时,只需要调用一次就行了,然后注释掉。不然的话每一次带调用都会在“data.txt"文件中生成不同的数据。在测试的时候,由于数据量太大了不好验证是否得到Top k个数据,我们可以在文件中自己设置k个大的数据,然后查看返回的结果是不是自己设计的前k个数据。
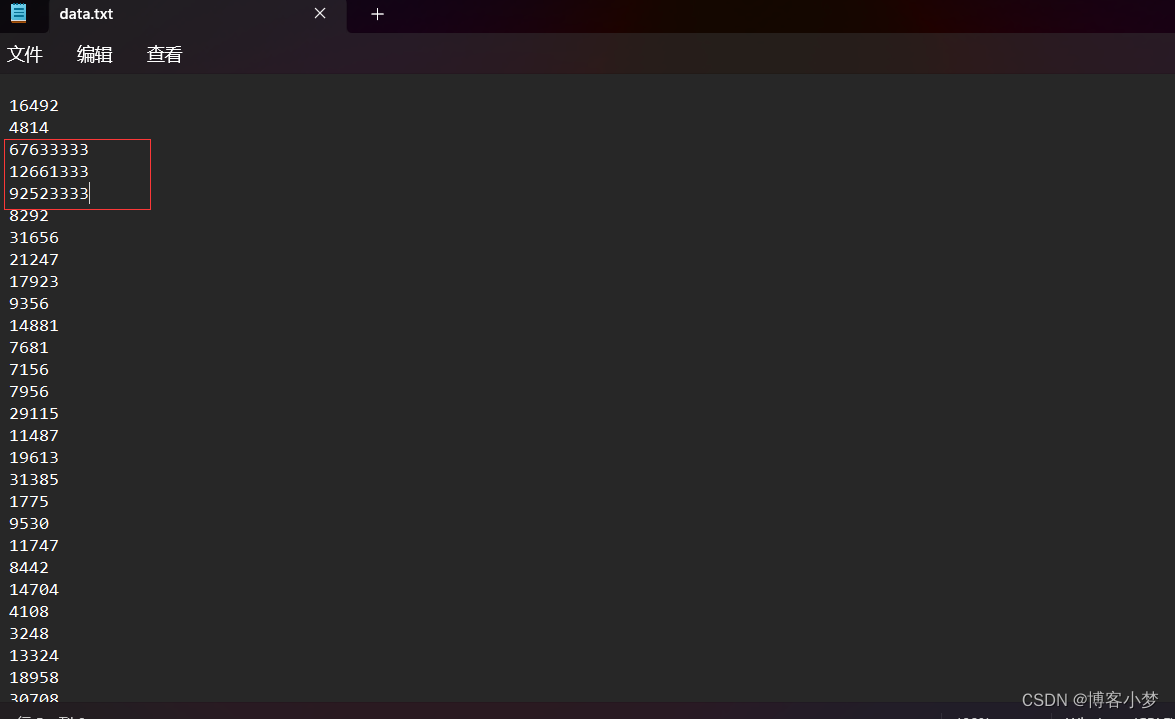
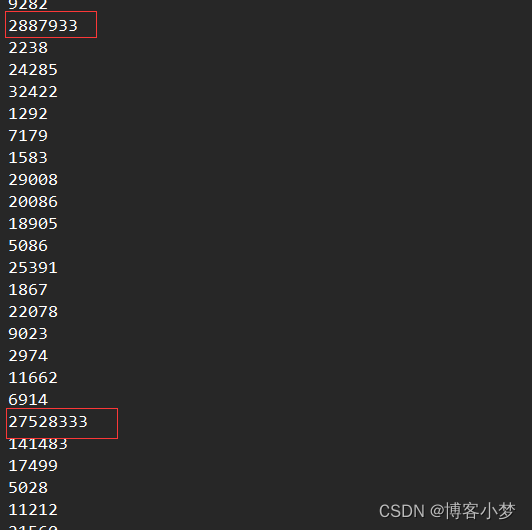
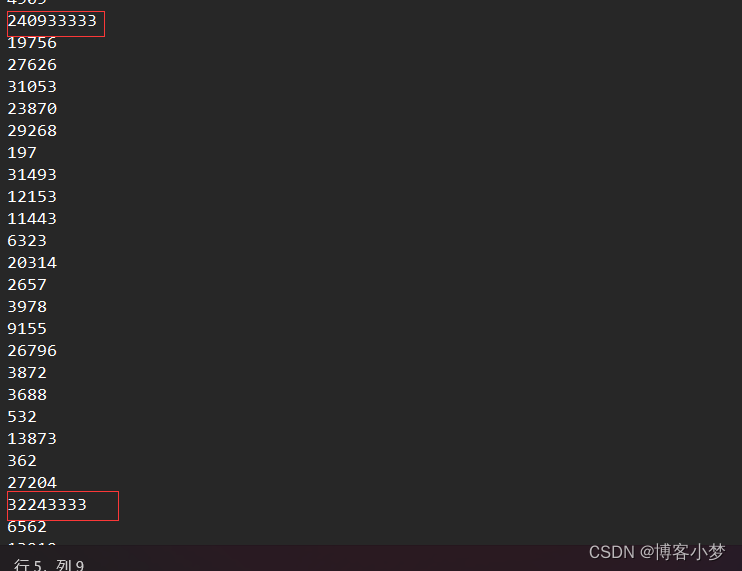

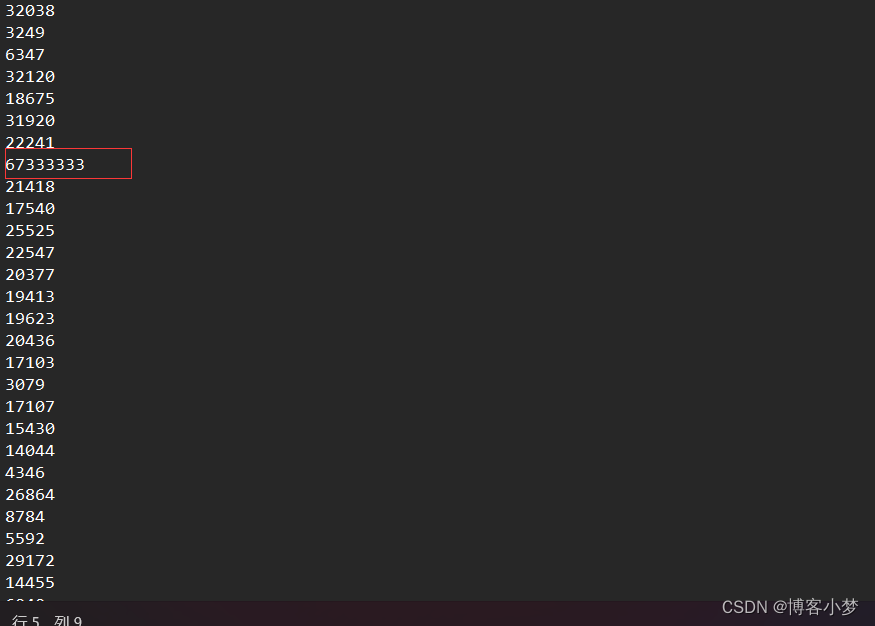
运行结果截图:
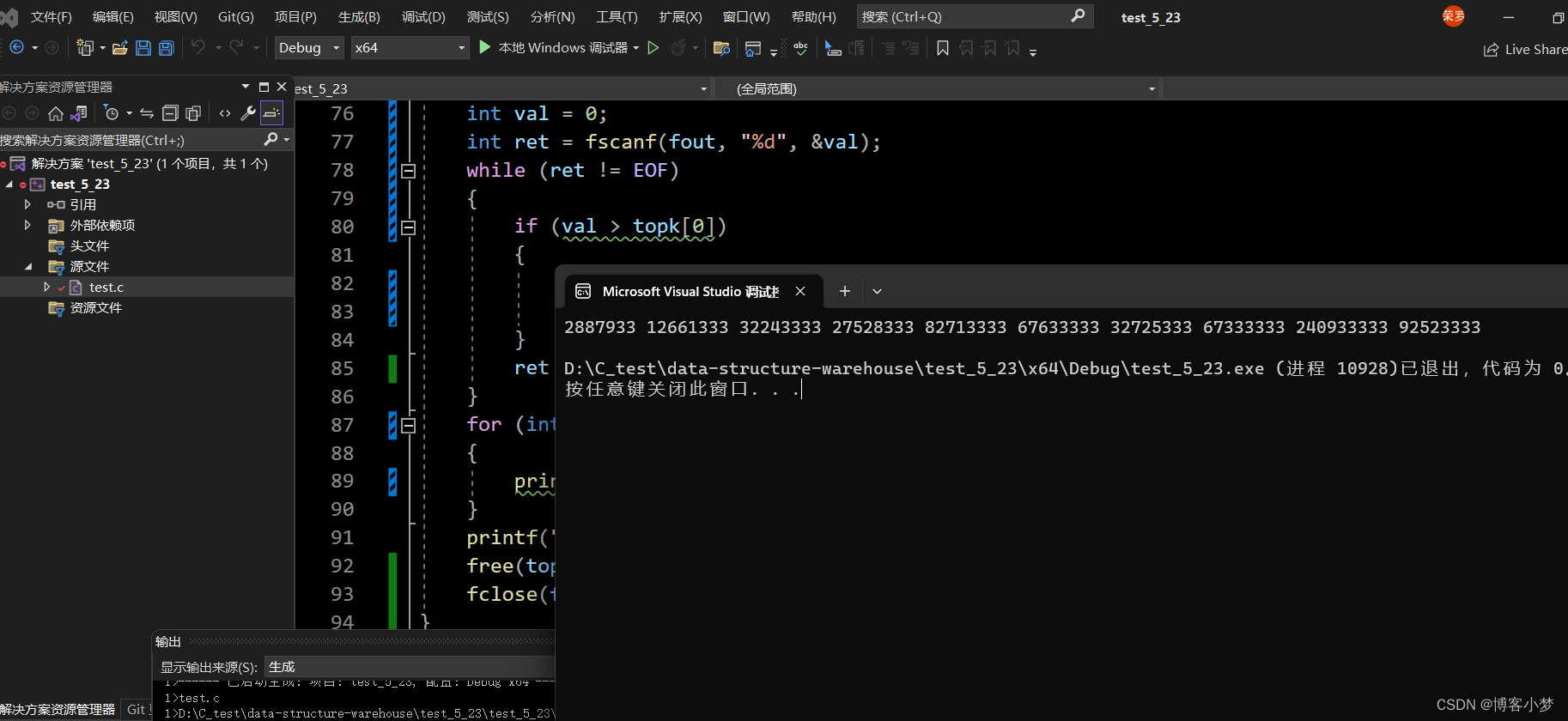 可以看到,结果是正常返回到我们设置的前k个最大的数值的。
可以看到,结果是正常返回到我们设置的前k个最大的数值的。
总结撒花💞
本篇文章旨在分享的是堆的实际应用–TopK问题的相关知识。希望大家通过阅读此文有所收获!
😘如果我写的有什么不好之处,请在文章下方给出你宝贵的意见😊。如果觉得我写的好的话请点个赞赞和关注哦~😘😘😘