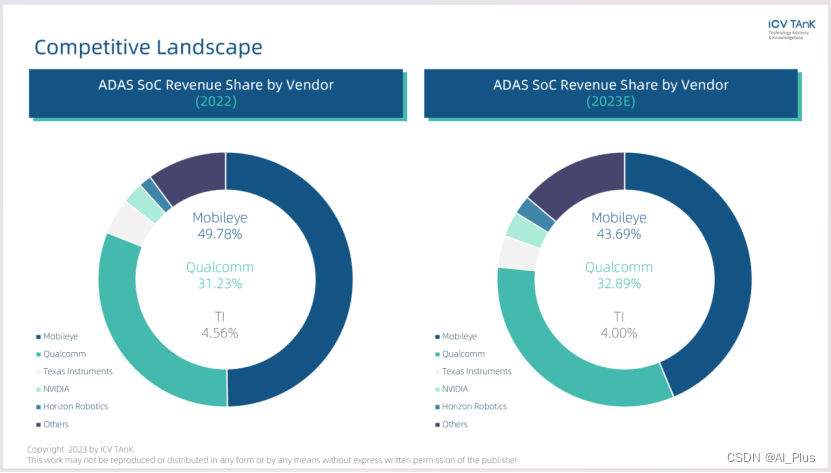
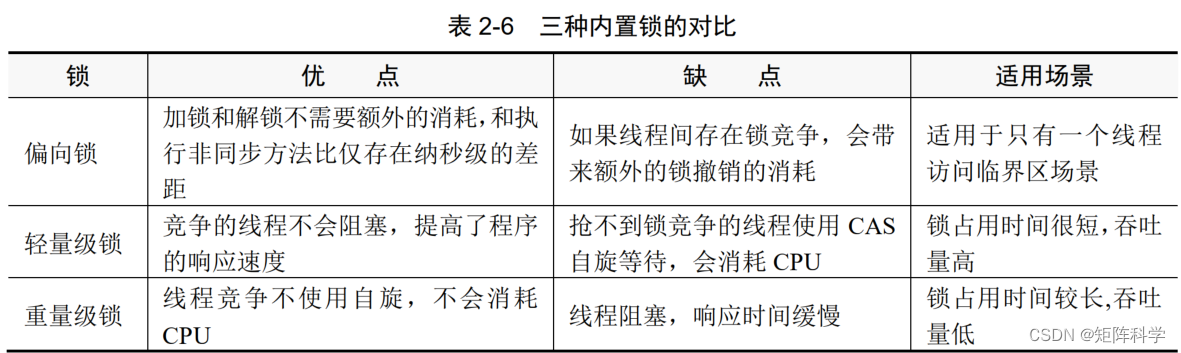
很多网站会设置反爬虫机制,如验证码、IP封禁、请求频率限制等,这些机制会增加爬虫的难度。
程序员做爬虫时,可能会遇到以下难点:
1、反爬虫机制
许多网站会设置反爬虫机制,如验证码、IP封禁、请求频率限制等,需要程序员采取相应的策略来规避这些机制。

2、数据清洗
爬虫获取的数据可能存在格式不规范、重复、缺失等问题,需要程序员进行数据清洗和处理,以保证数据的准确性和完整性。
3、动态页面
许多网站采用动态页面技术,如AJAX、Vue.js等,需要程序员使用相关技术来模拟用户行为,获取动态页面数据。
4、大规模数据处理
爬虫获取的数据可能非常庞大,需要程序员使用分布式爬虫、多线程、异步IO等技术来提高数据处理效率。
5、法律法规
在进行爬虫时,程序员需要遵守相关的法律法规,如《网络安全法》、《信息安全技术个人信息规范》等,否则可能会面临法律风险。
反爬虫机制怎么解决
反爬虫机制是为了防止恶意爬虫对网站造成损害,但有时候也会影响正常用户的访问。以下是一些解决反爬虫机制的方法:
1、使用代理IP
使用代理IP可以隐藏真实IP地址,从而避免被反爬虫机制识别。
2、使用浏览器模拟器
使用浏览器模拟器可以模拟用户的行为,从而避免被反爬虫机制识别。
3、使用验证码识别技术
使用验证码识别技术可以自动识别验证码,从而避免被反爬虫机制拦截。
4、使用分布式爬虫
使用分布式爬虫可以将爬虫任务分散到多个节点上,从而避免被反爬虫机制识别。
5、合理设置爬虫访问频率
合理设置爬虫访问频率可以避免被反爬虫机制拦截。
需要注意的是,任何爬虫行为都应该遵守网站的规则和法律法规,不得进行恶意爬虫行为。
多线程爬虫使用代理IP
在多线程爬虫中使用代理IP可以有效地提高爬虫的效率和稳定性。以下是使用代理IP的步骤:
-
获取代理IP:可以通过购买代理IP服务或者免费代理IP网站获取代理IP。
-
在爬虫代码中添加代理IP的设置:可以使用Python的requests库或者urllib库来设置代理IP。例如:
import requests
proxies = {
'http': 'http://127.0.0.1:8888',
'https': 'https://127.0.0.1:8888'
}
response = requests.get(url, proxies=proxies)
其中,http://127.0.0.1:8888和https://127.0.0.1:8888是代理IP的地址和端口号。
- 在多线程爬虫中使用代理IP:在多线程爬虫中,每个线程都需要使用不同的代理IP。可以将代理IP列表作为参数传递给每个线程,让每个线程使用不同的代理IP。例如:
import threading
import requests
def crawl(url, proxy):
proxies = {
'http': proxy,
'https': proxy
}
response = requests.get(url, proxies=proxies)
# 处理响应数据
# 代理IP池提取ip(http://jshk.com.cn/mb/http.asp)
proxy_list = ['http://127.0.0.1:8888', 'http://127.0.0.1:8889', 'http://127.0.0.1:8890']
url = 'https://www.example.com'
threads = []
for proxy in proxy_list:
t = threading.Thread(target=crawl, args=(url, proxy))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
在上面的代码中,proxy_list是代理IP列表,url是要爬取的网页地址。创建多个线程,每个线程使用不同的代理IP来爬取网页数据。