问题描述
1、在使用python实现自动化网络爬虫时,我使用到selenium来驱动谷歌Chrome浏览器来打开某一个网页,然后爬取数据,代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://klatasds.ecnu.edu.cn/xydt/list.htm')
time.sleep(5)
print(driver.page_source)2、但是当执行到driver.get(url)访问网站时,页面是空白的,如下所示,没有正常显示该网站的数据
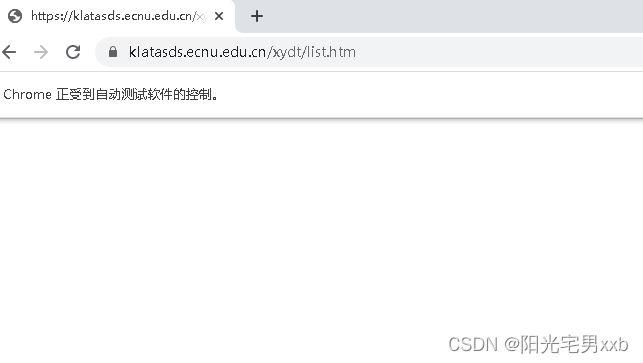
print输出的网页html也只有如下数据:
<html><head></head><body></body></html>
3、而我将该url网址收到复制到其他浏览器中访问是正常的,可以看到网页数据,说明这个网址是没有问题的。
原因分析:
既然手动复制到其他浏览器可以正常访问,排除网址和网络的问题,手动另起一个Chrome浏览器,复制访问该网站还是OK的,而且换成访问百度首页,也是可以的,说明不是Chromedriver和浏览器版本的问题。
因此,应该是该网站被反爬了,这个反爬是监测到我们使用了selenium自动化浏览器后就不返回数据在浏览器中显示。
我们在使用selenium打开浏览器后,会看到一行文字:显示浏览器正收到自动化软件的控制:

selenium启动的浏览器与手动打开的浏览器的浏览器指纹是不一样的,所以能够被网站检测到。
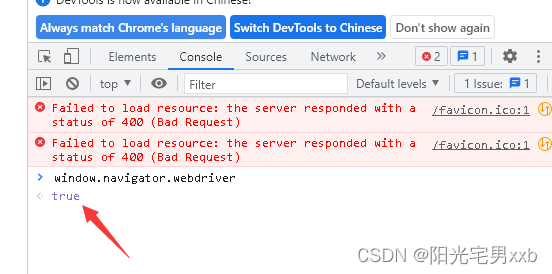
而浏览器指纹,大家比较熟悉就是window.navigator.webdriver属性,如果是在selenium打开的浏览器,其结果为true,而正常浏览器结果为undefined。我们可以复制这个值到浏览器中试试:
打开一个普通的浏览器,F12,控制台,输入window.navigator.webdriver:

由selenium打开一个浏览器,F12,控制台,输入window.navigator.webdriver:
当然,浏览器的指纹不止这一个属性,还有其他的属性。网站监测是否是selenium启动的判断方法具体根据哪些浏览器指纹判断的不得而知。
解决方案:
1、修改
window.navigator.webdriver属性值,让其返回值为undefinedfrom selenium import webdriver import time driver = webdriver.Chrome() driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) """ }) driver.get('https://klatasds.ecnu.edu.cn/xydt/list.htm')2、如果上述方法不行,使用undetected_chromedriver库
(1)pip install undetected_chromedriver
如果安装找不到,使用-i 参数更换pip安装源试试
(2)修改代码
import undetected_chromedriver as wd import time driver = wd.Chrome() driver.get('https://klatasds.ecnu.edu.cn/xydt/list.htm') time.sleep(5)要注意使用undetected_chromedriver ,Chrome浏览器必须更新到最新的版本,否则会报错。
我最后是使用第2中方法成功解决了我的问题