文章目录
- 前言
- 环境
- 一、构建知识库
- 二、将知识库向量化
- 三、召回
- 四、利用LLM做阅读理解
- 五、效果
- 总结
前言
通过本文, 你将学会如何使用langchain来构建一个自己的知识库问答
其实大多数类chatpdf产品的原理都差不多, 我将其简单粗暴地分为以下四步:
- 构建知识库
- 将知识库向量化
- 召回
- 利用LLM做阅读理解
下面, 我们就来看看, 如何利用我们自己写的博客, 打造一个ChatBlog
环境
老规矩, 环境是必不可少的一部分:
langchain==0.0.148
openai==0.27.4
chromadb==0.3.21
一、构建知识库
比较简单, 直接上代码吧
def get_blog_text():
data_path = 'blog.txt'
with open(data_path, 'r') as f:
data = f.read()
soup = BeautifulSoup(data, 'lxml')
text = soup.get_text()
return text
# 自定义句子分段的方式,保证句子不被截断
def split_paragraph(text, max_length=300):
text = text.replace('\n', '')
text = text.replace('\n\n', '')
text = re.sub(r'\s+', ' ', text)
"""
将文章分段
"""
# 首先按照句子分割文章
sentences = re.split('(;|。|!|\!|\.|?|\?)',text)
new_sents = []
for i in range(int(len(sentences)/2)):
sent = sentences[2*i] + sentences[2*i+1]
new_sents.append(sent)
if len(sentences) % 2 == 1:
new_sents.append(sentences[len(sentences)-1])
# 按照要求分段
paragraphs = []
current_length = 0
current_paragraph = ""
for sentence in new_sents:
sentence_length = len(sentence)
if current_length + sentence_length <= max_length:
current_paragraph += sentence
current_length += sentence_length
else:
paragraphs.append(current_paragraph.strip())
current_paragraph = sentence
current_length = sentence_length
paragraphs.append(current_paragraph.strip())
documents = []
for paragraph in paragraphs:
new_doc = Document(page_content=paragraph)
print(new_doc)
documents.append(new_doc)
return documents
content = get_blog_text()
documents = split_paragraph(content)
这里必须要说明一下, 我没有使用langchain提供的文档划分函数, langchain提供了很多种文档划分方式, 感兴趣的同学可以查看 langchain.text_splitter里面的源码. 这里我给截出来了, 大概有这么些种吧, 其实都差不多, 目的都差不多是为了将段划分得比较合理.
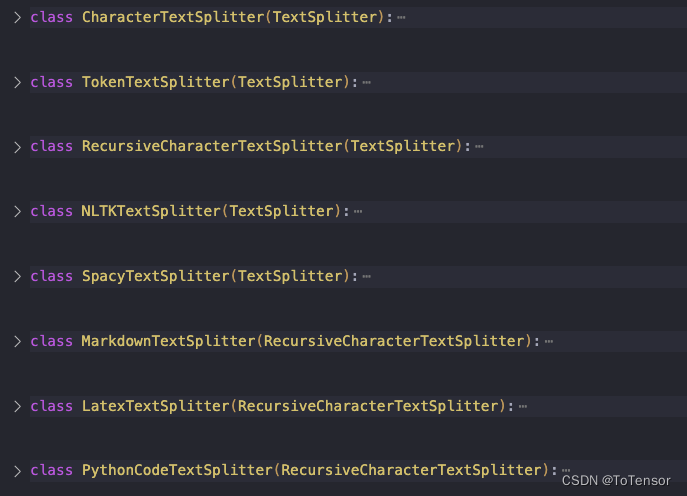
我们这里设置了一个max_length, 这个长度, 如果使用的是chatgpt的话, 最大可以是4096, 因为chatgpt允许的最大输入Token是4096, 换算成中文的话, 实际还要更短一些, 还要加上prompt的Token长度, 所以需要预留出一定空间.
分段分不好的话, 对输出的影响还是挺大的, 我们这里是按句划分, 其实更合理的是按博客的小标题划分, CSDN的问答机器人就是这么做的, 哈哈, 这里硬推一波, 效果还是很不错的, 超越了所有人类, 不服的可以来挑战一下:
https://ask.csdn.net/
后面我也会抽空写一篇CSDN问答机器人的博客来和大家分享一下实现细节, 点点关注不迷路

二、将知识库向量化
# 持久化向量数据
def persist_embedding(documents):
# 将embedding数据持久化到本地磁盘
persist_directory = 'db'
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=documents, embedding=embedding, persist_directory=persist_directory)
vectordb.persist()
vectordb = None
这里的OpenAIEmbeddings默认使用的是text-embedding-ada-002模型来做emdedding, 你也可以换成别的, langchain提供了以下embedding的方式
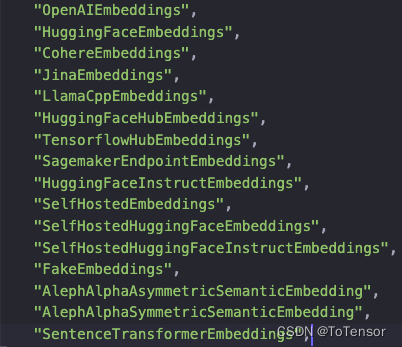
你也可以自己从本地加载一个句向量模型去embedding, 这里需要注意一下, 如果使用的是openai的向量化模型的话, 是需要打开科学上网的.
向量化完了后, 我们需要将向量化后的结果存起来, 下次用 , 直接加载就行了, 我这里使用的是Chroma来存储向量化后的数据, 不过, langchain还支持其他的向量数据库, 如下:
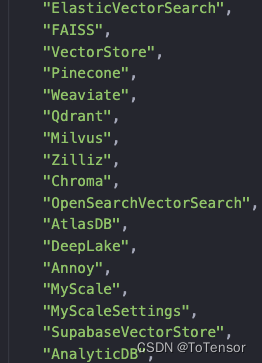
Chroma我也是第一次用, 感兴趣的同学可以自己去了解一下, FAISS应该是用的比较多的, 我在问答机器人中用的是pgvector, 因为我们数据库用的是PostgresSQL, pgvector是PG的向量化存储插件, 所以我们用了这个, 并没有什么特别的原因, 其实各种向量化数据库都差不多, 影响召回速度和效果的是索引的构建方式, 其中比较知名的是HNSW, 感兴趣的可以去了解一下
三、召回
global retriever
def load_embedding():
embedding = OpenAIEmbeddings()
global retriever
vectordb = Chroma(persist_directory='db', embedding_function=embedding)
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
k=5是指指召回top 5的结果
as_retriever函数还有个search_type的参数, 默认的是similarity, 参数解释如下:
search_type 搜索类型:“similarity” 或 “mmr”。search_type=“similarity” 在检索器对象中使用相似性搜索,在其中选择与问题向量最相似的文本块向量。search_type=“mmr” 使用最大边际相关性搜索,其中优化相似性以查询所选文档之间的多样性。
四、利用LLM做阅读理解
def prompt(query):
prompt_template = """请注意:请谨慎评估query与提示的Context信息的相关性,只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答"我不知道",另外也不要回答无关答案:
Context: {context}
Question: {question}
Answer:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
docs = retriever.get_relevant_documents(query)
# 基于docs来prompt,返回你想要的内容
chain = load_qa_chain(ChatOpenAI(temperature=0), chain_type="stuff", prompt=PROMPT)
result = chain({"input_documents": docs, "question": query}, return_only_outputs=True)
return result['output_text']
其实就是将召回的文本, 作为prompt的一部分, 再让chatgpt从prompt中总结答案, 跟阅读理解简直一模一样.
前面说的分段对结果影响很大, 在这个地方也有体现, 分段分不好, 召回的数据就不好, chatgpt就很难从中总结出答案.
注意: 这里也需要科学上网.
五、效果

非常正确
总结
1、整体跟阅读理解类似, 不过你可以调整prompt, 比如: 请你结合Context和你自己现有的知识, 回答以下问题
2、全部代码: https://github.com/seanzhang-zhichen/ChatBlog