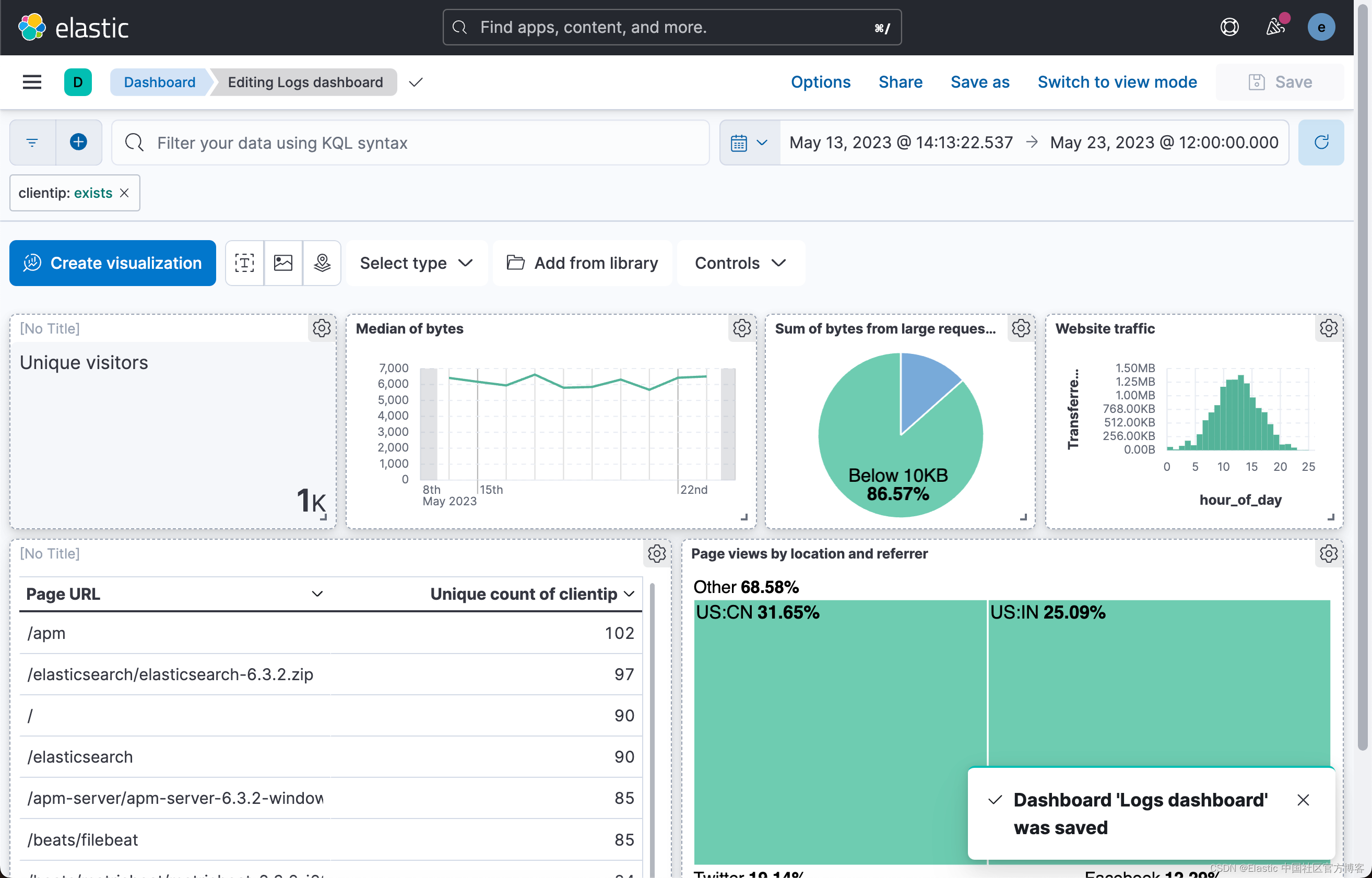
TLV解析Ⅰ
题目描述
TLV编码是按[Tag Length Value]格式进行编码的,一段码流中的信元用Tag标识,Tag在码流中唯一不重复,Length表示信元Value的长度,Value表示信元的值。
码流以某信元的Tag开头,Tag固定占一个字节,Length固定占两个字节,字节序为小端序。
现给定TLV格式编码的码流,以及需要解码的信元Tag,请输出该信元的Value。
输入码流的16进制字符中,不包括小写字母,且要求输出的16进制字符串中也不要包含小写字母;码流字符串的最大长度不超过50000个字节。
输入描述
输入的第一行为一个字符串,表示待解码信元的Tag;
输入的第二行为一个字符串,表示待解码的16进制码流,字节之间用空格分隔。
输出描述
输出一个字符串,表示待解码信元以16进制表示的Value。
| 输入 | 输出 | 说明 |
|---|---|---|
| 31 32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC | 32 33 | 需要解析的信元的Tag是31, 从码流的起始处开始匹配, 第一个信元的Tag是32,信元长度为1(01 00,小端序表示为1); 第二个信元的Tag是90,其长度为2; 第三个信元的Tag是30,其长度为3; 第四个信元的Tag是31,其长度为2(02 00), 所以返回长度后面的两个字节即可,即32 33。 |
源码和解析
解析:
这个题首先要理解题目还是挺难的。小编拿到这个题读了三五遍还是理解不了题目要我们做个啥。后面也是参考别人的博客理解的题意。
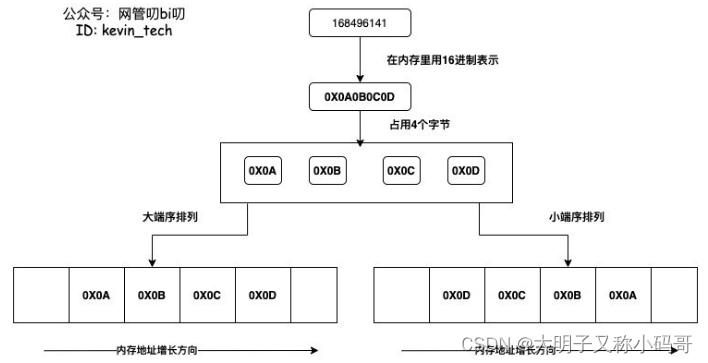
首先要理解的一个概念就是 小端序
字节的排列方式有两个通用规则:大端序Big-Endian: 将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
小端序Little-Endian: 将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。
也就是说 小端序的排列方式 Len的两个字节需要交换顺序才能得到值的长度
比如02 00 = 其长度表示应该为 0002 也就是2位长度
示例中的码流可以做如下解析:
也就是每个tag对应的值 长度是变化的。我们需要依据tag后的两个字节长度推出后面的值。

示例代码:
public class T14 {
public static void main(String[] args) {
String objTag="31";
String input="32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC";
String[] chArr = input.split(" ");
for(int i=0;i<chArr.length;){
String tag=chArr[i];
int len=Integer.parseInt(chArr[i+2]+chArr[i+1]);// 小端序排列 还原长度时要交换位置
StringBuilder value=new StringBuilder();
i+=2;// tag 移动完
for(int j=1;j<=len;j++){
value.append(chArr[i+j]+" ");
i++;//移动值
}
if(tag.equals(objTag)){
System.out.println(value);
break;
}
if(i<=(chArr.length-1))i++;// 移动tag
}
}
}