论文链接:https://arxiv.org/abs/2304.10817
代码链接:https://github.com/vision-intelligence-and-robots-group/count-anything
目的
探索SAM在few-shot setting的object counting的能力。
结论
它目前落后于最先进的few-shot object counting方法,特别是对于小而拥挤的物体。两个主要原因。首先,SAM倾向于使用单个掩码分割同一类别的拥挤对象。其次,SAM 使用缺乏语义类注释的掩码进行训练,这可能会阻碍其区分不同对象的能力。
如何将SAM用到few-shot object counting
不使用额外的zero-shot detector(grounding DINO)或者zero-shot classifier(CLIP),使用SAM的原始图像特征来区分不同的物体。这样做是为了节省计算资源。
- 首先,通过使用SAM的图像编码器(ViT-H)提取给定的密集图像特征图像。
- 我们利用给定的边界框作为提示来生成参考示例的分割掩码。然后将这些掩码与密集图像特征相乘,然后平均以生成参考对象的特征向量。
- 我们使用点网格(每边 32 个点)**作为提示来分割所有内容,输出掩码与密集图像特征相乘,然后平均以生成所有掩码的特征向量**。
- 我们计算了预测掩码的特征向量与参考示例之间的余弦相似性。如果余弦相似度超过预定阈值,我们将它视为目标对象。
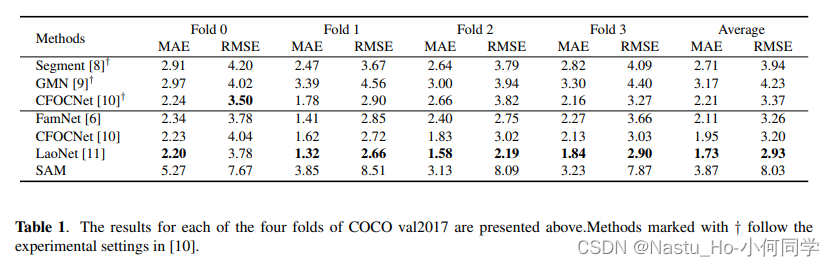
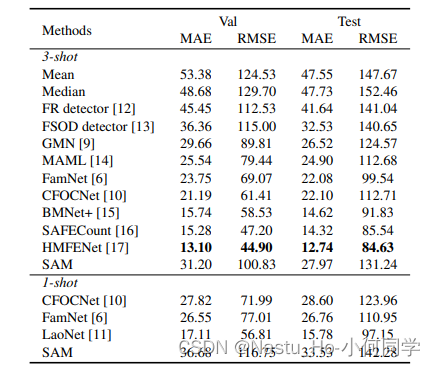
实验数据