代码来自文中地址
目录
一、前向传播过程
1、Path Embedding
2、BiFormer Block
BRA模块
网络结构
一、前向传播过程
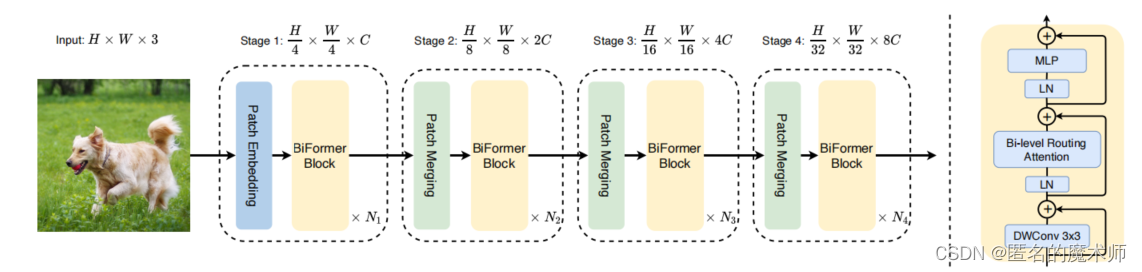
1、Path Embedding
见网络结构部分,4倍下采样
2、BiFormer Block
对应
x = x + self.pos_embed(x)
对应
x = x + self.drop_path(self.attn(self.norm1(x)))接下来仔细记录其中的细节。
BRA模块
BRA模块的运行需要满足前提条件
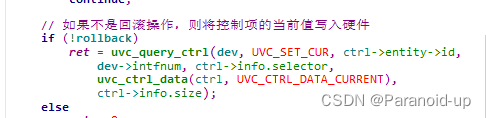
else: # True
N, H, W, C = x.size() # 1,56,56,64
assert H%self.n_win == 0 and W%self.n_win == 0其中的self.n_win就是 论文中的 S,论文中

以及论文中的 Algorithm1
# patchify input (H, W, C) -> (Sˆ2, HW/Sˆ2, C)x = patchify(input, patch_size=H//S)
对应代码
# patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv size
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win) # (1,49,8,8,64)论文中的公式3
![]()
以及Algorithm1中的
# linear projection of query, key, valuequery, key, value = linear_qkv(x).chunk(3, dim=-1)
对应
q, kv = self.qkv(x) # to 103 q (1,49,8,8,64) kv (1,49,8,8,128)
# pixel-wise qkv
# q_pix: (n, p^2, w^2, c_qk)
# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c') # (1,49,64,64)
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w')) # (49,128,8,8)
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win) # (1,49,64,128)只不过这里将 k v 放在一起了。
论文中

对应
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean([2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk) q_win (1,49,64) k_win (1,49,64) 这里是k_min所以截至到0:self.dim这个不是按通道进行平均,而是按 每个区域的8x8个vector进行平均
代码中接下来会执行
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win, i=self.n_win).contiguous()) # (1,64,56,56)
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win) # (1,56,56,64)对应文中的公式7中的LCE(V)
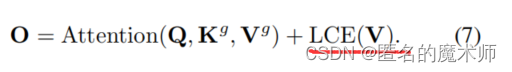

文本的公式4 和公式5

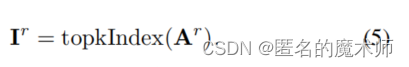
分别由
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors to 51 (1,49,1) (1,49,1)返回,里面的前向传播
def forward(self, query:Tensor, key:Tensor)->Tuple[Tensor]: # q (1,49,64), k (1,49,64)
"""
Args:
q, k: (n, p^2, c) tensor
Return:
r_weight, topk_index: (n, p^2, topk) tensor
"""
if not self.diff_routing: # True
query, key = query.detach(), key.detach()
query_hat, key_hat = self.emb(query), self.emb(key) # per-window pooling -> (n, p^2, c) (1,49,64)
attn_logit = (query_hat*self.scale) @ key_hat.transpose(-2, -1) # (n, p^2, p^2) (1,49,49)
topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1) # (n, p^2, k), (n, p^2, k) (1,49,1) (1,49,1)
r_weight = self.routing_act(topk_attn_logit) # (n, p^2, k) (1,49,1)
return r_weight, topk_indexself.emb 为 Identity 恒等函数,然后进行公式4 attention,拿出top k 个,self.routing_act为softmax激活函数。这个过程,可以看到,经过attention的输出为 (1,49,49),第一个49表是区域数,第二个49表示每一个区域与其它区域的 affifinity graph 分数,按通道 -1拿出top k 个 最大分数和索引。
文中公式6
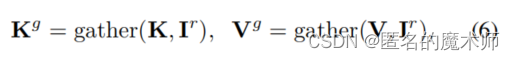
对应
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) #(n, p^2, topk, h_kv*w_kv, c_qk+c_v) (1,49,1,64,128)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1) # (1,49,1,64,64) (1,49,1,64,64)self.kv_gather没啥好说的。
然后进行多头 self attention,对应论文中的公式7
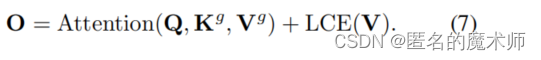
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here? (49,2,32,64)
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m) (49,2,64,32)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c', m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m) (49,2,64,32)
# param-free multihead attention
attn_weight = (q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv) (49,2,64,64)
attn_weight = self.attn_act(attn_weight) # (49,2,64,64)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c) (49,2,64,32)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H//self.n_win, w=W//self.n_win) # (1,56,56,64)
out = out + lepe # (1,56,56,64)这里将 n 和SxS 合并在一起了,也就是batch和 区域数,最后输出重新reshape回 H W。
最后再经过一个线性层输出。
接下来进入 mlp模块,没什么好说的。
网络结构
BiFormer--T
BiFormer(
(downsample_layers): ModuleList(
(0): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stages): ModuleList(
(0): Sequential(
(0): Block(
(pos_embed): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=64, out_features=192, bias=True)
)
(wo): Linear(in_features=64, out_features=64, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=64, out_features=192, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=192, out_features=64, bias=True)
)
(drop_path): Identity()
)
(1): Block(
(pos_embed): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=64, out_features=192, bias=True)
)
(wo): Linear(in_features=64, out_features=64, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=64, out_features=192, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=192, out_features=64, bias=True)
)
(drop_path): Identity()
)
)
(1): Sequential(
(0): Block(
(pos_embed): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(128, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=128)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=128, out_features=384, bias=True)
)
(wo): Linear(in_features=128, out_features=128, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=128, out_features=384, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=384, out_features=128, bias=True)
)
(drop_path): Identity()
)
(1): Block(
(pos_embed): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(128, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=128)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=128, out_features=384, bias=True)
)
(wo): Linear(in_features=128, out_features=128, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=128, out_features=384, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=384, out_features=128, bias=True)
)
(drop_path): Identity()
)
)
(2): Sequential(
(0): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(1): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(2): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(3): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(4): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(5): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(6): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
(7): Block(
(pos_embed): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(norm1): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(attn): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(norm2): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=256, out_features=768, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=768, out_features=256, bias=True)
)
(drop_path): Identity()
)
)
(3): Sequential(
(0): Block(
(pos_embed): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
(norm1): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(attn): AttentionLePE(
(qkv): Linear(in_features=512, out_features=1536, bias=False)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=512, out_features=512, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(lepe): Conv2d(512, 512, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=512)
)
(norm2): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=512, out_features=1536, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=1536, out_features=512, bias=True)
)
(drop_path): Identity()
)
(1): Block(
(pos_embed): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
(norm1): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(attn): AttentionLePE(
(qkv): Linear(in_features=512, out_features=1536, bias=False)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=512, out_features=512, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(lepe): Conv2d(512, 512, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=512)
)
(norm2): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=512, out_features=1536, bias=True)
(1): Identity()
(2): GELU()
(3): Linear(in_features=1536, out_features=512, bias=True)
)
(drop_path): Identity()
)
)
)
(norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pre_logits): Identity()
(head): Linear(in_features=512, out_features=1000, bias=True)
)