P4 P5 主要讲解了 detect.py 中的参数的使用
如何利用 YOLOv5 进行预测(一)_哔哩哔哩_bilibili
如何利用YOLOv5进行预测(二)_哔哩哔哩_bilibili
(一)weight:代码如下
parser.add_argument('--weights', nargs='+', type=str, default='yolov5m.pt', help='model.pt path(s)')
1、权重参数会自动下载
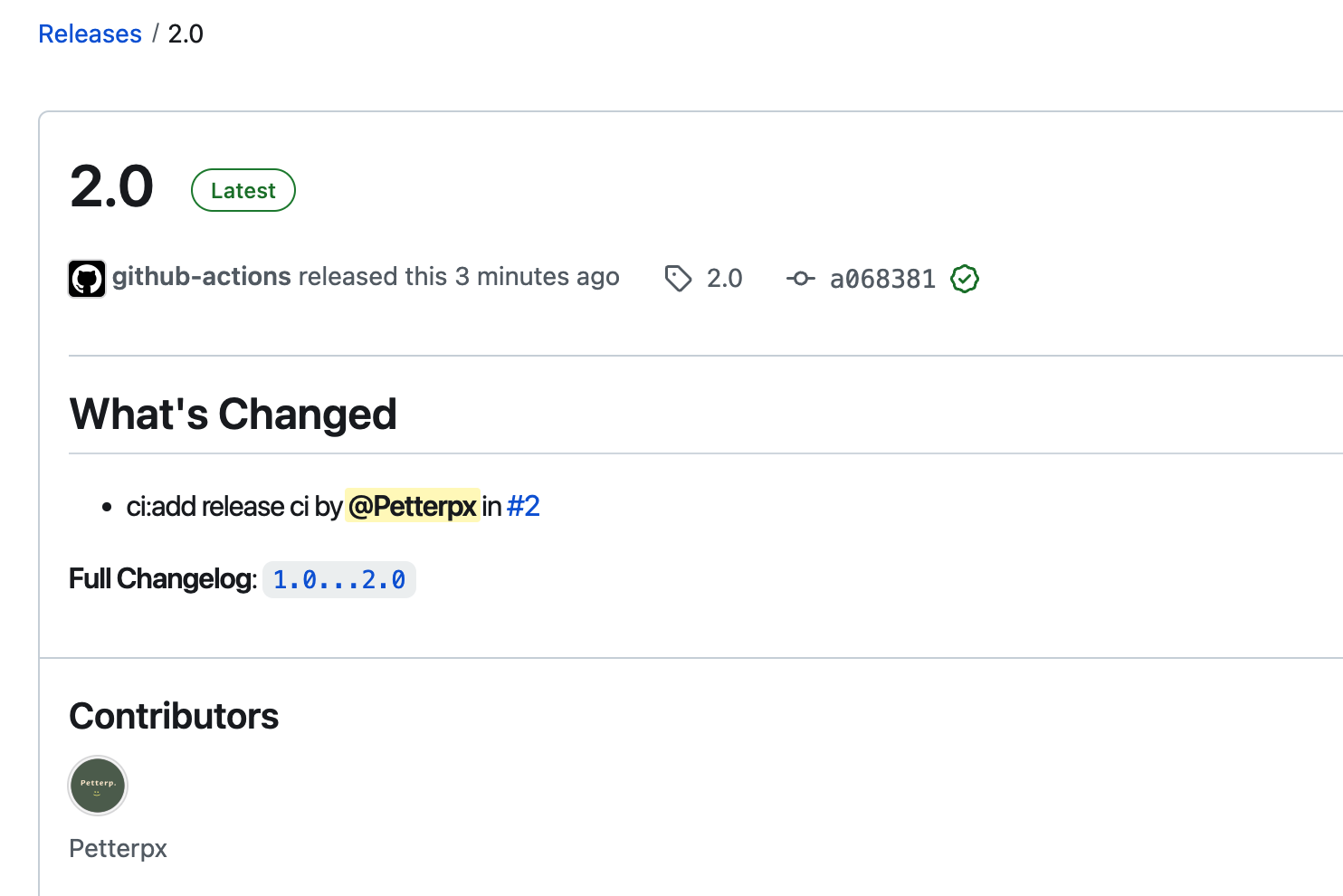
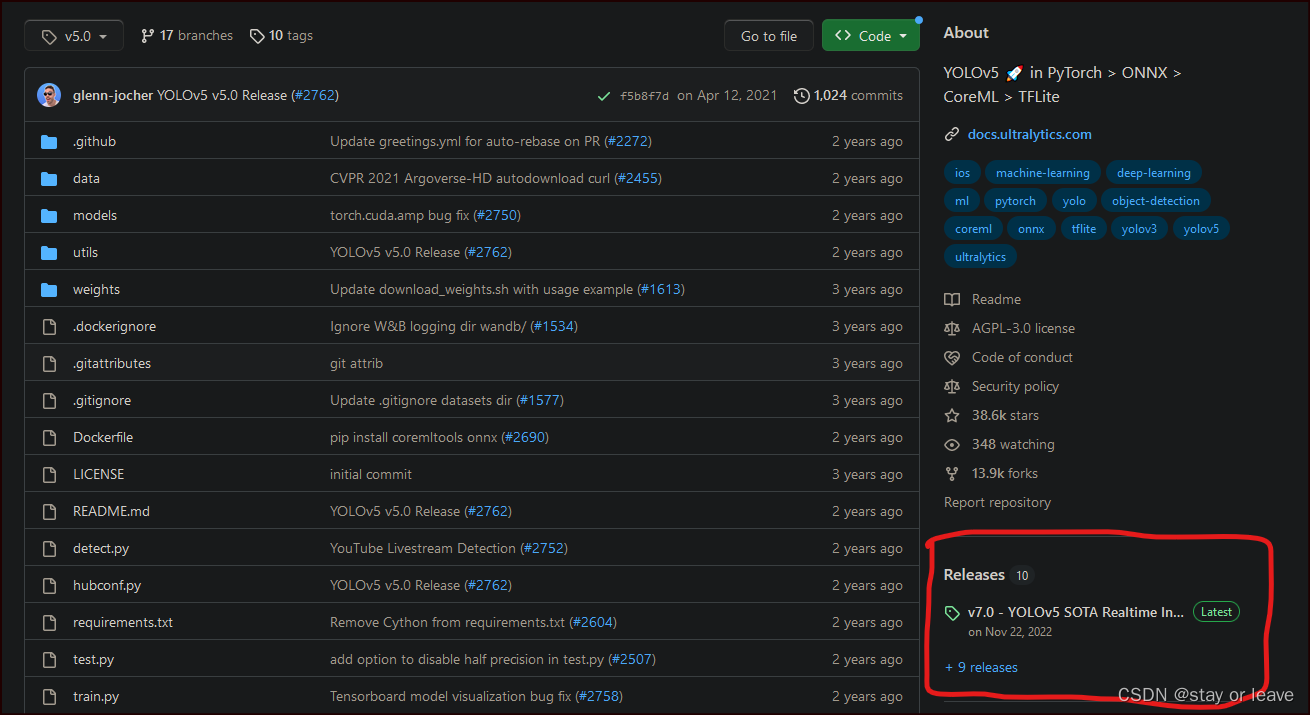
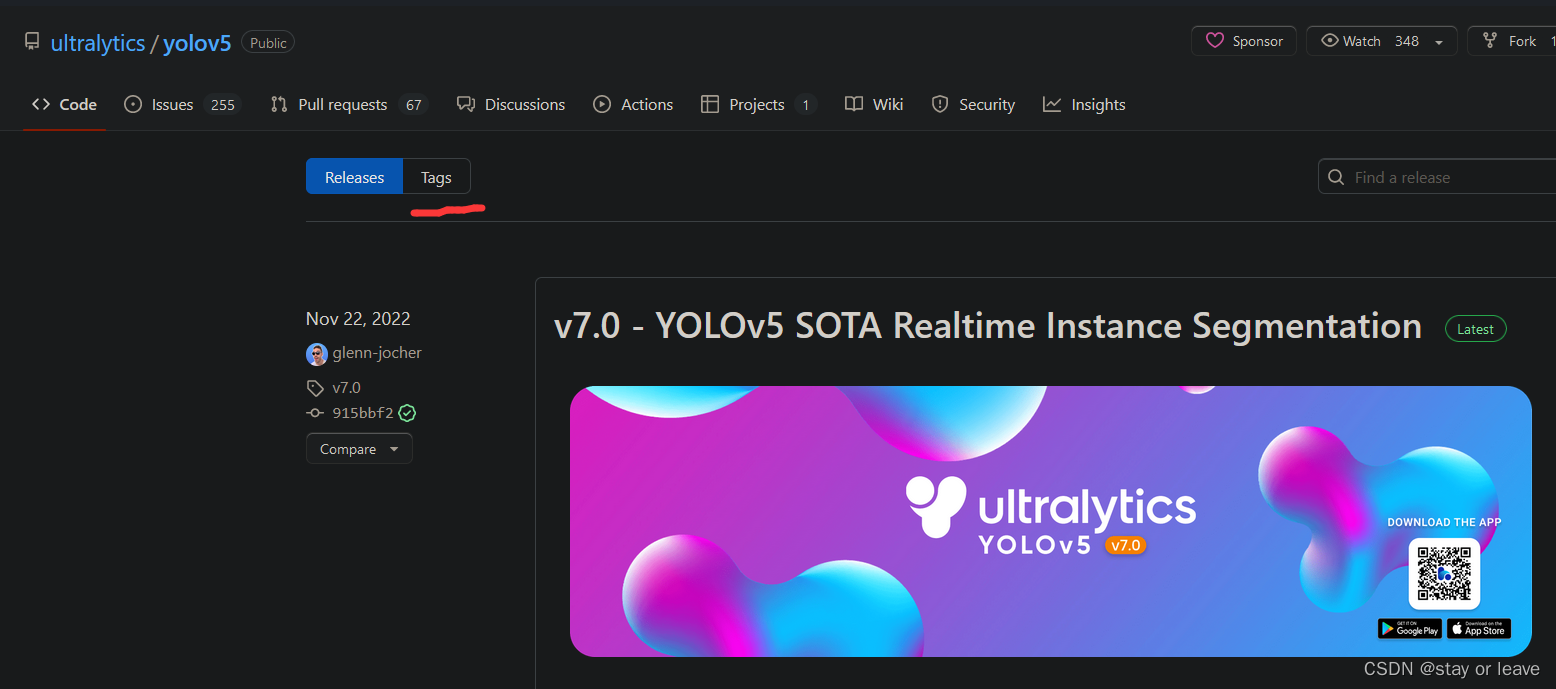
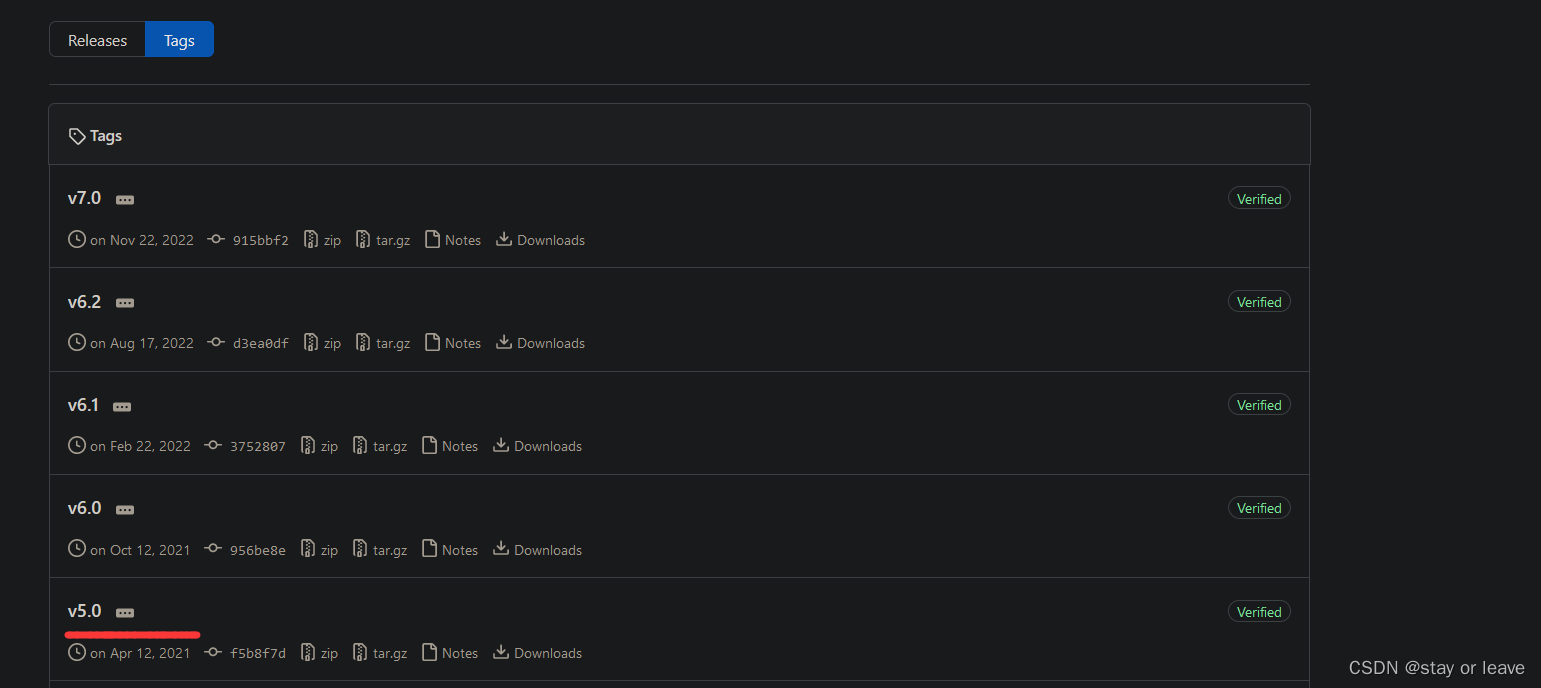
2、如果自动下载的网速较慢,可以去github上下载相应的权值,下载的方法是找到对应页面的release,操作如下图
(二)source,代码如下
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
1、default 装的是相对路径,支持文件夹,图片,视频,摄像头等格式。
(三)img-size
1、推理所用的尺寸,以像素为单位,较大的尺寸会有较高的精度和较慢的速度,较小的尺寸则相反。
2、注意并不是输入或者输出的尺寸。
(四)conf-thres
锚框内包含物体的置信度。
(五)iou-thres
1、如果IOU为0,则没有重复的框,如果IOU为1,则允许所有重复的框存在。
(六)device
1、后面的程序会自动推断。
(七)view-img
1、推断的过程中,实时地展示图片结果。
(八)save-txt
1、保存结果的标签值。
(九)save-conf
1、保存结果的置信度。
(十)nosave
1、不保存检测结果。
(十一)classes
1、只检测对应标签的物体。
(十二)agnostic-nms
1、未知
(十三)augment
1、检测增强,好处是增加置信度,坏处是可能给物体打错标签。
P7 P8主要讲解了train模式中的参数含义
训练YOLOv5模型(本地)(一)_哔哩哔哩_bilibili
训练YOLOv5模型(本地)(二)_哔哩哔哩_bilibili
P9讲解了在云端训练YOLOv5模型
云端GPU网址https://colab.research.google.com/
视频教程网址训练YOLOv5模型(云端GPU)_哔哩哔哩_bilibili
P10自制数据集及训练
视频教程自制数据集及训练_哔哩哔哩_bilibili
其实这些博主也是参照github项目的readme来做的,并且csdn很多博主也是参照github的issue来回来问题的,这就说明了学习要学源头的东西,而源头的东西大部分是英文的,所以搞技术的英文要好好锻炼。