深度学习自然语言处理 原创
作者 | 鸽鸽
这段时间in-context learning真的很火,陈丹琦组最新的两篇文章都是ICL相关,今天我们拜读其中一篇:丹琦的硕士生、纽约大学准博士生Jane Pan的ACL小短文。
大佬的学生会做出怎样的科研示范呢?我们来瞧一瞧!有利于揭秘ICL的内部工作机制嗷~

论文:What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning
地址:https://arxiv.org/abs/2305.09731
代码:https://github.com/ princeton-nlp/WhatICLLearns
录取:Findings of ACL 2023
众所周知,上下文学习第一次在GPT-3的论文Language Models are Few-Shot Learners中提出,这种超能力意味着大模型能够仅从上下文中的例子“学习”执行任务而不进行任何参数更新。那么,上下文学习究竟在上下文“学到”了什么?
这个问题尚无定论,一派研究假设预训练期间LLMs就已经隐含地学习了下游应用所需的任务,而上下文演示只是提供信息、使模型识别所需任务而已。另一派则表示,Transformer-based模型可以执行隐式梯度下降以更新“内部模型”,并且上下文学习与显式微调之间具有相似性!这个脑洞有点神奇了!作者提供了相关研究,大家可以去论文的参考文献看看。
根据这两派的观点,这篇文章把ICL分解为任务识别(TR)和任务学习(TL)两个方面,观察ICL背后到底发生了什么。
先来一波严谨的定义
我们先理解下TR和TL这两个概念的定义。以下描述有点啰嗦,也可以不看,用一句话概括就是:
TR通过演示(demonstrations)来识别任务并应用预训练的先验知识,TL学习预训练中没有的新知识;TR不受输入-标签映射的影响,但TL要求提供正确的映射!
ICL的数学定义
LLM将输入-标签对演示 和测试输入 作为条件来预测标签 , 由演示 (demonstrations) 引出一个映射.
任务识别(TR)
任务识别(task recognition)表示模型仅通过观察输入分布 和标签分布 , 而不是提供 对的情况下,识别映射的能力。在不依赖于配对信息的情况下,LLM会将其预训练的先验信息应用于识别到的,即使提供错误的输入-标签映射。
看起来很抽象,我们举个例子。即使没有以明确的方式通过正确标签的演示来学习任务,甚至给出类似于“这部电影很棒,情感是负面的”的错误演示,模型在电影评论的情感分类这个任务上依然能表现良好,因为这个任务在预训练中很常见、很容易识别。
任务学习(TL)
任务学习(TL)指从演示(demonstrations)中学习新的输入-标签映射的能力。与TR不同,TL允许模型学习新的映射,因此正确的输入标签对至关重要。
难点是如何分解TR和TL
接下来看看作者如何分解这两种机制,搞定它这篇论文就get啦!
假设这两种机制在不同条件下发生,很显然,只识别不学习(TR)比学习新映射(TL)更容易。TR可以在小规模上发生,但只有TL会随着模型规模和演示次数的增加而显著改进。
那么如何将TR和TL分开观察呢?
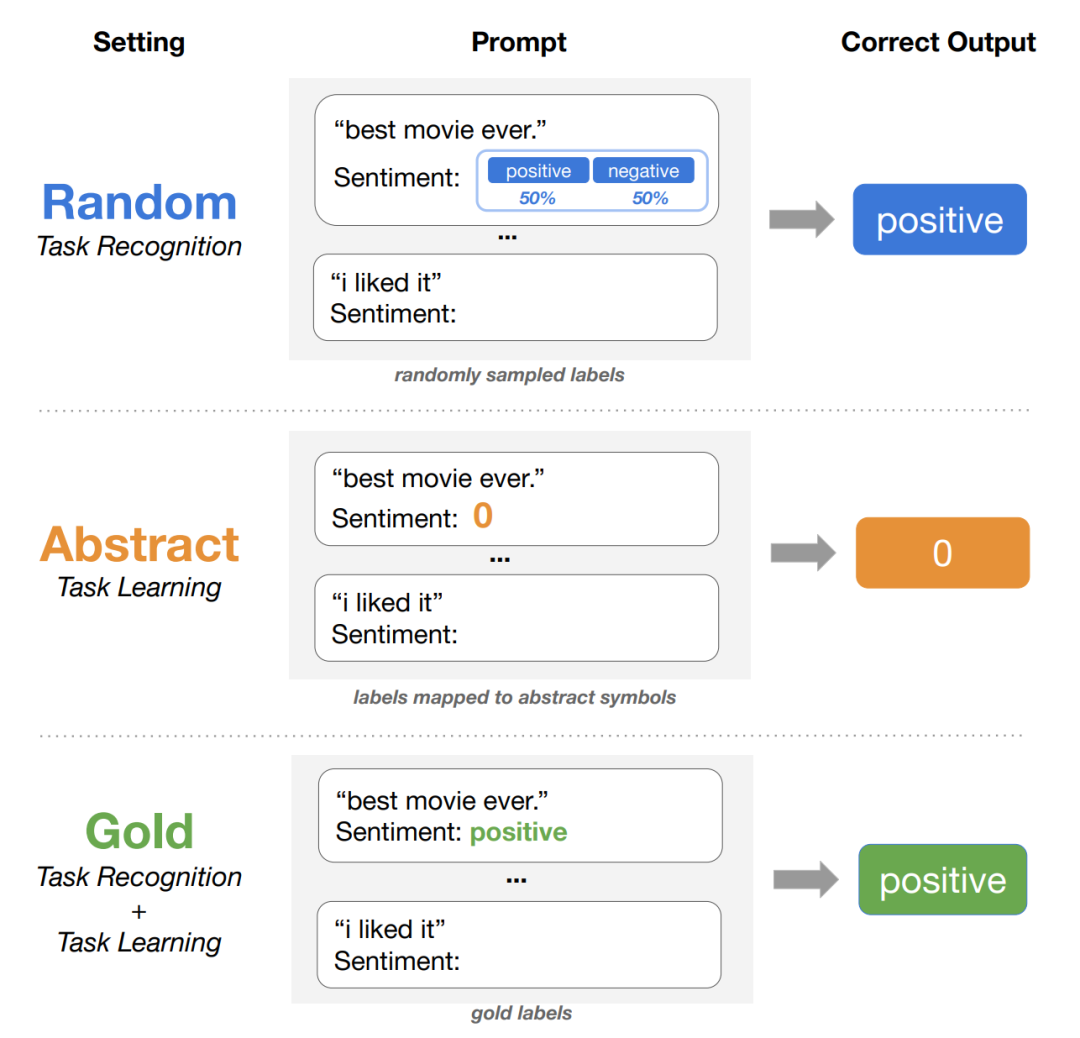
作者巧妙地使用了标签空间操作来分离TR和TL,包括三种不同的设置:
GOLD:使用自然提示和黄金的输入-标签对的标准ICL设置。这种设置同时反映TR和TL。
RANDOM:使用与GOLD相同的自然提示,从标签空间中均匀随机采样演示标签。这种设置只反映TR机制。
ABSTRACT:使用最小提示(提供没有任务信息的提示)和没有明确语义含义的字符(例如数字、字母和随机符号)作为每个类的标签,不泄漏任何任务特定的信息。这种设置只反映TL机制。
作者在4种类型的16个分类数据集上进行实验,包括情感分析、毒性检测、自然语言推理/复述检测和主题/立场分类等分类任务;使用三个最先进的LLM系列,包括GPT 3,LLaMA和OPT.
结果如何呢
总体趋势上,GOLD在所有模型族和演示数量方面始终表现最好,这是因为GOLD设置为模型提供了所有信息;RANDOM曲线不会随着模型大小或演示数量而增加,保持基本平稳;在模型尺寸较小或演示数量较少时(K = 8),RANDOM和GOLD之间差距非常微小。也就是说,从上下文示例中识别任务(TR)并不会随着模型大小或示例数量的增加而急剧扩展。
相比之下,任务学习(TL)受规模的影响,并且随着更多演示而进一步改善。ABSTRACT曲线的斜率随着模型大小和演示数量的增加而越来越陡峭;对于小模型或小的演示数量,ABSTRACT表现大致相同,且大多数情况下表现不如RANDOM,但ABSTRACT在最大模型和演示数量时表现明显优于RANDOM、甚至能匹配GOLD的表现。
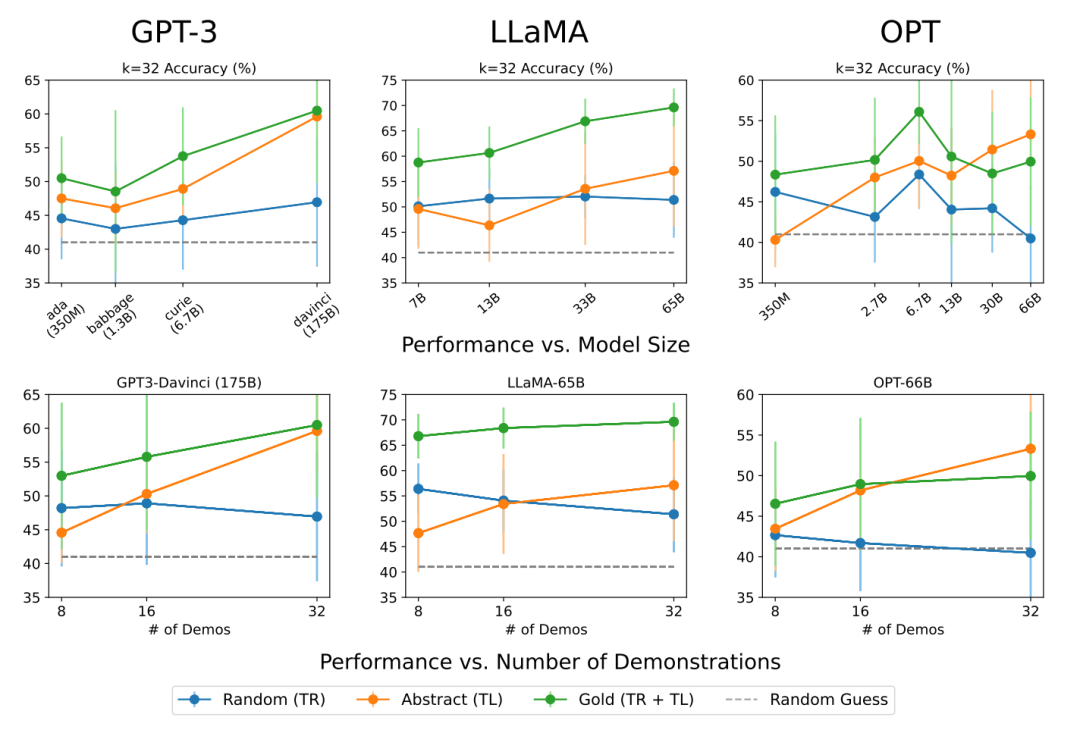
并且任务难度会影响任务学习的趋势,对于情感分析这类的简单任务,ABSTRACT随着规模和示例数量的增加呈更好的趋势;而自然语言推理(NLI)这类复杂任务的ABSTRACT曲线更平缓,表明模型更依赖于自然提示和预训练先验来解决这些任务。
总结
这篇论文独创地将ICL分成任务识别和任务学习这两种机制,并且证明两者发生的条件不同。小模型就有较好的任务识别的能力,但是大模型独具任务学习的新兴能力、并且可以利用更多演示来提高性能。
果然,学习能力还是要在大模型中涌现!
进NLP群—>加入NLP交流群