前言
同样是一个 很常用的 glibc 库函数
不管是 用户业务代码 还是 很多类库的代码, 基本上都会用到 内存数据的设置
不过 我们这里是从 具体的实现 来看一下
它的实现 主要是使用 汇编 来进行实现的, 因此 理解需要一定的基础
测试用例
就是简单的使用了一下 memcpy, memset, memcmp
#include "stdio.h"
int main(int argc, char** argv) {
int x = 2;
int y = 3;
int z = x + y;
void *p1 = malloc(20);
void *p2 = malloc(20);
void *p3 = malloc(20);
printf("p1 : 0x%x\n", p1);
printf("p2 : 0x%x\n", p2);
printf("p3 : 0x%x\n", p3);
memset(p1, 'a', 12);
memcpy(p2, p1, 17);
int p1CmpResult = memcmp(p1, p2);
printf(" x + y = %d, p1CmpResult = %d\n ", z, p1CmpResult);
}
memset 的实现
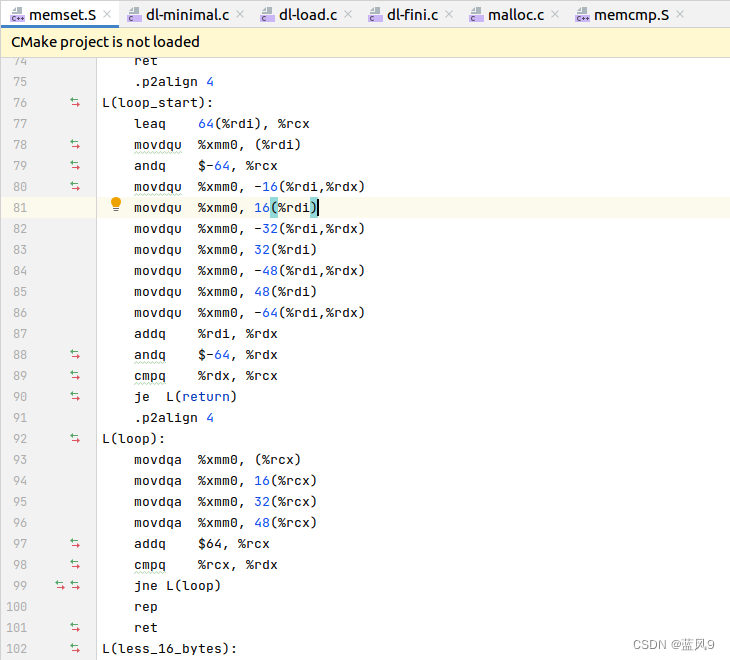
分为几个部分, 对于 大于64字节的空间的处理, 对于小于 16 字节的处理, 对于 16 - 64 字节的处理
如下截图为对于 16 - 64 字节的处理[jbe less_16_bytes 之后的部分], 以 16 字节为单位设置的 [start, start+16), [end-16, end) 的字节的数据 为目标字节
如果是 16-32 字节, 这里会覆盖这所有的字节的数据, 如果是 32-64 字节, 则覆盖的是头16字节 和 尾16字节, 中间一部分数据 还需要处理
如果长度在 32-64 字节, 则处理 [start+16, start+32), [end-32, end-16) 的数据, 这里的处理将 头尾16字节之外的其他的字节 都覆盖到了

对于超过了 64 字节的数据, 和上面 32-64 字节的处理一致
先处理 [start, start+64), [end-64, end) 的数据
然后长度大于 64, 再循环 以 64 字节为单位, 处理中间的数据, 直到到达 待处理数据末尾
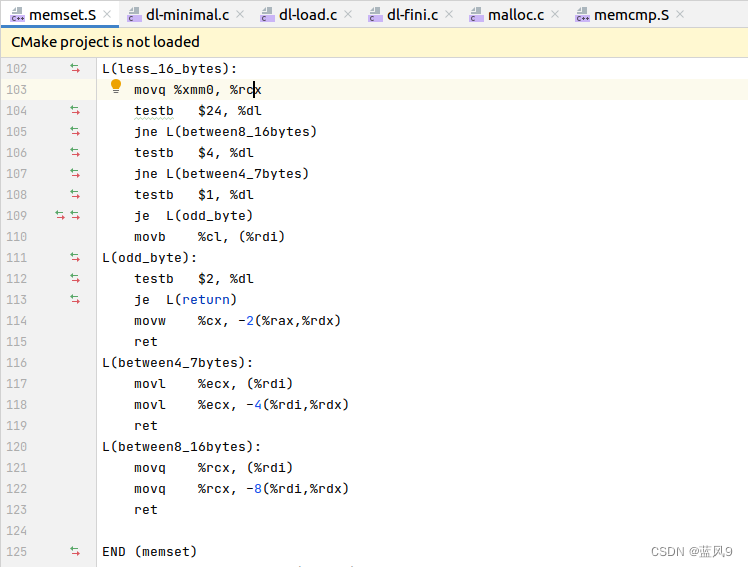
对于小于 16 字节的数据, 分为 8-16 字节处理, 4-7字节处理, 0-3字节处理
对于 8-16 字节, 以 8 为单位, 对 [start, start+8), [end-8, end) 进行处理, 无论长度为多少 覆盖的都是 [start, end)
对于 4-7 字节, 以 4 为单位, 对 [start, start+4), [end-4, end) 进行处理, 无论长度为多少 覆盖的都是 [start, end)
对于 1-3 字节, 如果是1字节, 拷贝1字节之后, 走 "testb $2, %dl" 之后就 return 了, 如果是两字节, 走 "testb $2, %dl" 之后 拷贝两字节就 return 了, 如果是三字节, 拷贝1字节之后, "testb $2, %dl" 之后又拷贝了两字节, 然后 return 了
完