创建一个Scrapy框架的爬虫程序
安装Scrapy库,直接通过pycharm搜索Scrapy进行安装即可
在终端执行 scrapy startproject 项目名
scrapy startproject Learn
示例
即可创建名为Learn的Scrapy程序,成功创建项目后,会已项目名称创建一个文件夹,该文件夹下才是真正的程序文件,如图
项目目录
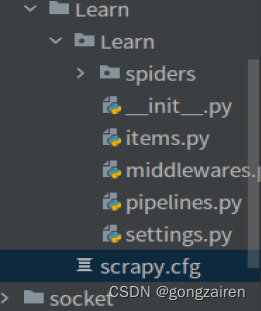 、
、
结构讲解
spiders:放的是爬虫源文件,需要将爬虫的程序写在该目录下
items:放的是爬虫生成的item对象,相当于暂时存放所解析后的数据类
pipelines:管道处理传进来item类的持久化保存操作
settings.py:放的是项目的配置文件
创建爬虫源文件
首先需要切换到spiders或项目目录下 cd spider 或者 cd learn
scrapy genspider 爬虫文件名 指定的url
示例
scrapy genspider first www.baidu.com
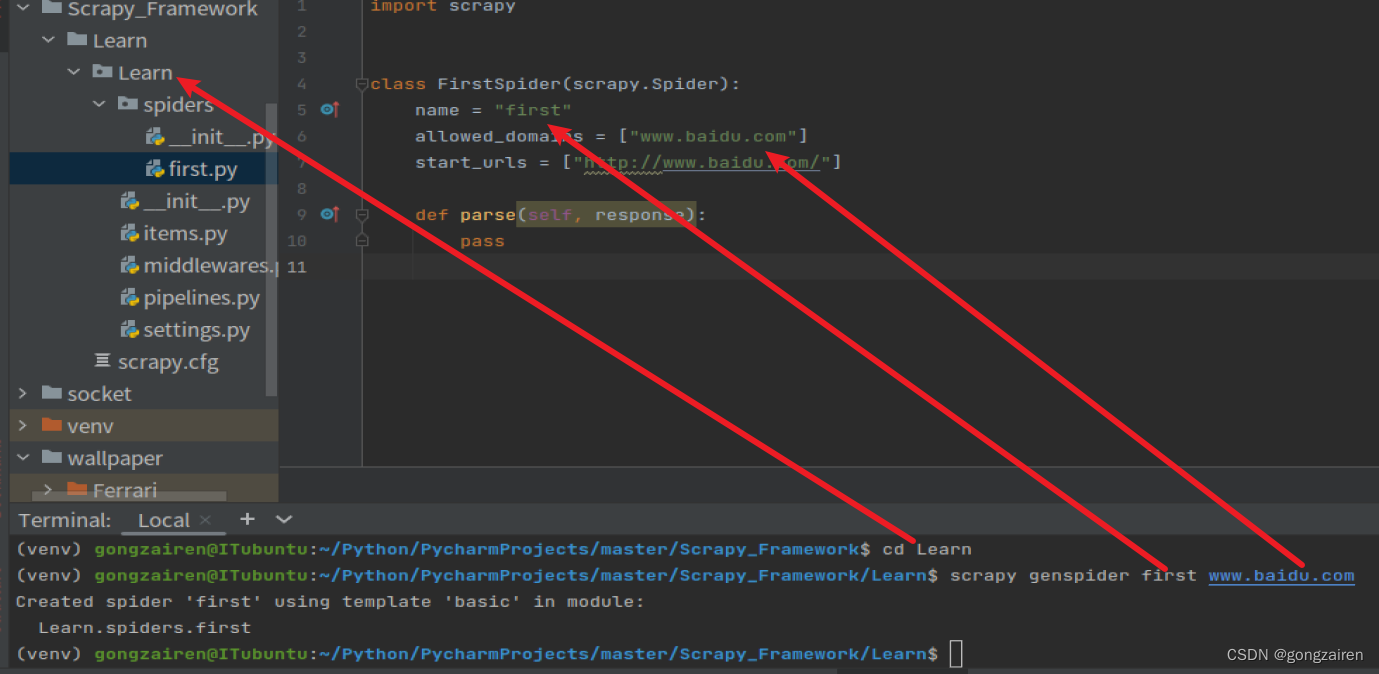
参数介绍
name:爬虫的名称,也是该爬虫的唯一标识
allowed_domains:允许访问的域名范围,一般都不使用这种方式,因为有一些请求下载的url并不是属于指定的域名
start_urls:存放需要访问的url地址,scrapy会根据这里面的url发送请求
函数 parse:存放的是scarpy发送请求后的响应对象,start_urls里面有多少个地址就会执行多少次parse函数就会多少个响应对象
运行项目
首先在settings.py 中把【ROBOTSTXT_BOEY=False】,因为开启此协议基本上就无法抓取数据
在settings.py 中设置对应的User-agent
可以在settings.py 中设置 【LOG_LEVEL="ERROR"】,运行项目时显示错误日志,过滤其他日志
日志级别从低到高排序:DEBUG、INFO、WARNING、ERROR、CRITICAL,设置的级别能够显示当前级别及以上的信息
scrapy crawl 爬虫名字
示例
scrapy crawl first

数据解析
可以直接使用response.xpath进行html的结构解析,其返回的也是一个列表,与etree包中的xpath不同是其列表里面装的是selector对象,需要再次进行抽取转换,使用.extract()方法即可转化,如果是列表进行extract,其会将列表中的每个selector对象进行转化
持久化存储数据
使用管道进行存储
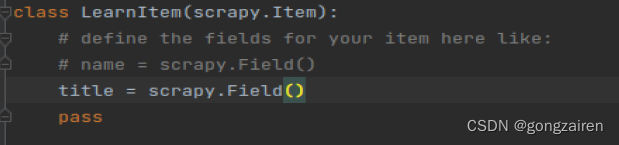
1.编写items里面的类,定义item的属性
需要多少个保存的数据,就创建多少个属性
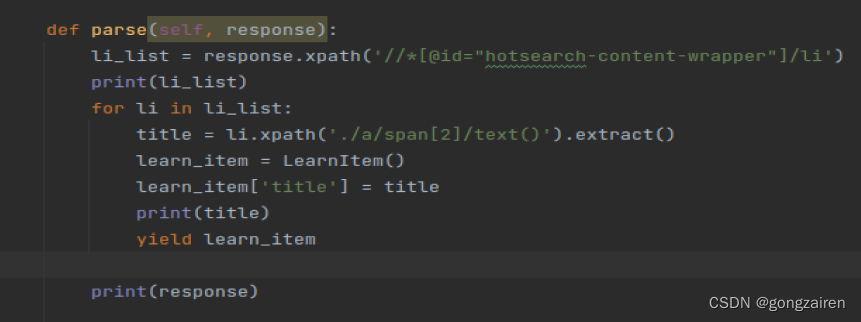
2.在数据解析时创建实例化对象
每一次yield都会调用pipelines里面的process_item方法
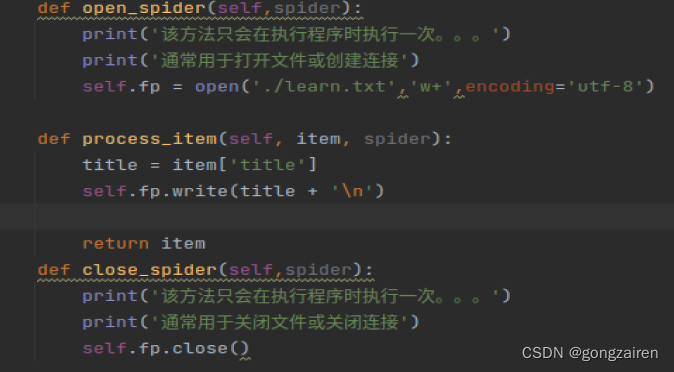
3.编写process_item方法
4.在settings中开启管道
把ITEM_PIPELINES的注释给取消,后面数字代表优先级,数字越小,表示优先级越高,就会越先被执行
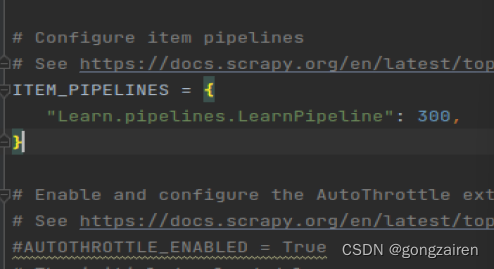
process_item方法中的return item 会把item传递给下一个优先级的管道类(比当前管道类低一级的pipeitem),通常一个管道类对应一种存储载体
scrapy五大核心件
引擎、spider、管道、下载器、调度器
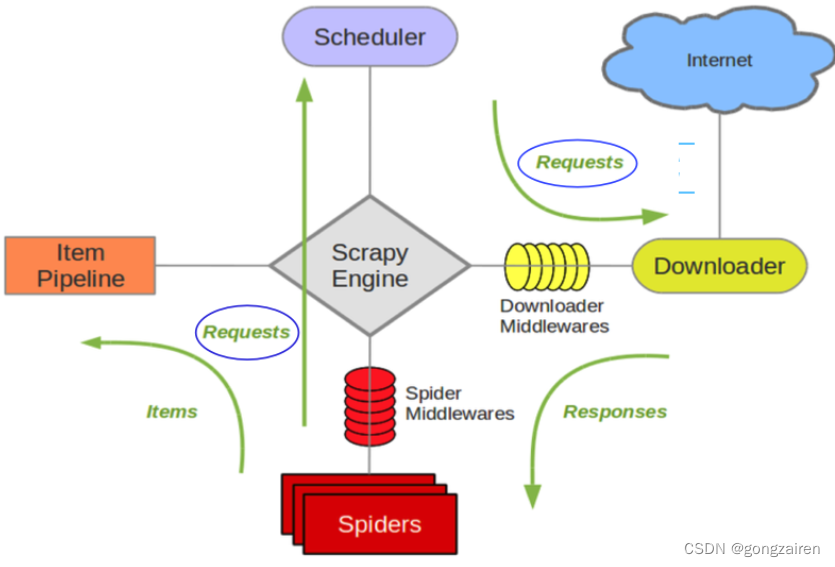
引擎:对于程序的事务处理,根据不同的信息流来执行对应的模块,所有数据流都要经过引擎处理
spider:封装url对象,解析response,传递item
调度器:接受url对象后进行封装request请求
下载器:接受request请求,向网络发送请求,即获取网页数据,返回response
管道:保存数据,可以使用多种方式进行数据的存储,如文件、数据库等