文章目录
- 为什么需要loki
- 为什么不是EFK?
- Loki是如何存储数据的?
- 底层的LSM tree
- B+ tree 和LSM tree的区别?
- Ref
- 参考链接
为什么需要loki
日志记录本质上是一个事件。大多数语言、应用程序框架或库都支持日志,表现形式可以是字符串这样原始的非结构化数据,也可以是JSON等半结构化数据。开发者可以通过日志来分析应用的执行状况,报错信息,分析性能…… 正因为日志极其灵活,生成非常容易,没有一个统一的结构,所以它的体量也是最大的。
对于单体应用,查看日志我们可以直接登上服务器,用head、tail、less、more等命令进行查看,也可以结合awk、sed、grep等文本处理工具进行简单的分析。但是分布式应用,面对部署在数十数百台机器的应用,亟需一个日志收集、处理、存储、查询的系统
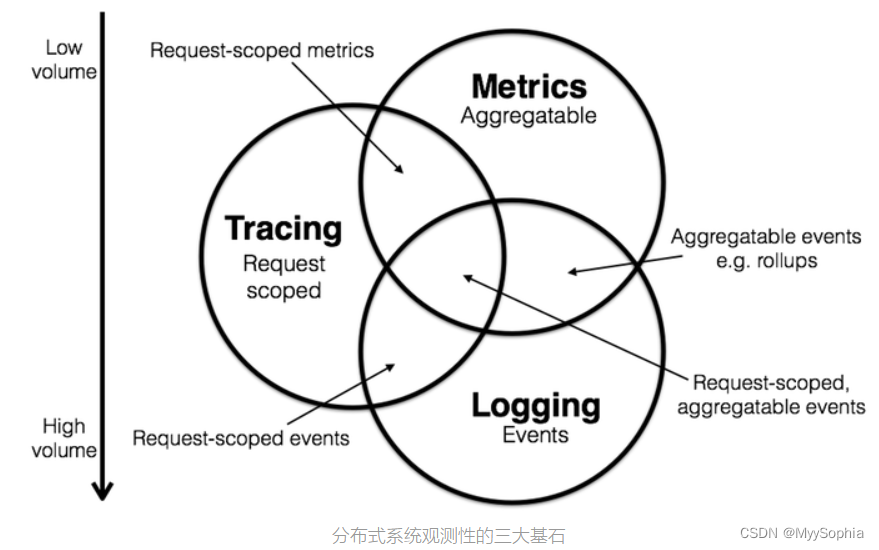
为什么不是EFK?
开源社区最早流行的是Elastic体系的ELK。Logstash负责收集,ElasticSearch负责索引与存储,Kibana负责查询与展示。ElasticSearch支持全文索引可以进行全文搜索,而且支持DocValue可以用于结构化数据的聚合分析。再加上MetricBeats提供了监控指标的收集,APM提供的链路收集,Elastic俨然已是一个集Logging、Metrics、Trace的大一统技术体系。这主要是因为早期的
Elastic野心很大,但是这也导致ElasticSearch并不专注在其中的一个领域。
1、使用全文索引受限于分词器,对于日志查询非常鸡肋(两个单词能搜索到,三个单词就搜索不到的现象也不少)。
2、而且索引阶段特别耗时,很多用户都无法忍受ElasticSearch索引不过来时抛出的EsReject。
3、另外,ElasticSearch除了用于全文搜索的倒排索引,还有store按行存储,在_source字段中存储JSON文档,docValue列式存储,对于不熟悉ElasticSearch的开发者来说,意味着存储体量翻了好几倍,ElasticSearch的高性能查询严重依赖于索引缓存,官方建议机器的内存得预留一半给操作系统进行文件缓存,这套吃内存的东西对普通的日志查询简直就是小题大做。
4、还有ElasticSearch在生产环境至少得部署三个节点,否则由于网络波动容易出现脑裂。
5、基于JVM的Logstash极其笨重,经常因为GC无响应导致日志延时,作为采集日志的agent有点喧宾夺主,为此Elastic专门用Go语言开发了轻量级的FileBeat日志采集工具。由FileBeat负责采集,Logstash负责解析处理。
目前K8s生态下以Fluentd和C语言编写的fluent-bit为主作为日志收集工具,Grafana开发的Loki负责存储。Loki去掉了全文索引,使用最原始的块存储,对时间和特定标签做索引,这和Metrics领域的Prometheus类似
Loki是如何存储数据的?
Loki是一个分布式日志聚合系统,它使用类似于Prometheus的标签查询语言来查询和过滤日志数据。Loki的数据存储方式与传统的日志存储方式不同,它使用了一种称为“无索引”的方式来存储数据。
在Loki中,日志数据被存储在称为“块”的文件中。每个块包含一定数量的日志条目,通常是几千到几万条。的大小可以配置,通常在几百MB到几GB之间。
Loki使用了一种称为“切片”的方式来组织块。每个切片包含一定数量的块,通常是几百到几千个。切片的大小也可以配置,通常在几GB到几十GB之间。
Loki使用一种称为“标签索引”的方式来查询和过滤日志数据。标签索引是一种基于标签的元数据存储方式它允许Loki快速地定位包含特定标签值的日志数据。
当Loki接收到新的日志数据时,它会数据写入一个新的块中。如果块已经达到了配置的大小限制,Loki会将块写入一个新的切片中。如果切片已经达到了配置的大小限制,Loki会将切片写入磁盘,并创建一个新的切片。
由于Loki使用了无索引的方式来存储数据,因此它可以快速地写入和查询大量的日志数据。同时,由于Loki使用了标签索引的方式来查询和过滤数据,因此它可以快速地定位包含特定标签值的日志数据。
底层的LSM tree
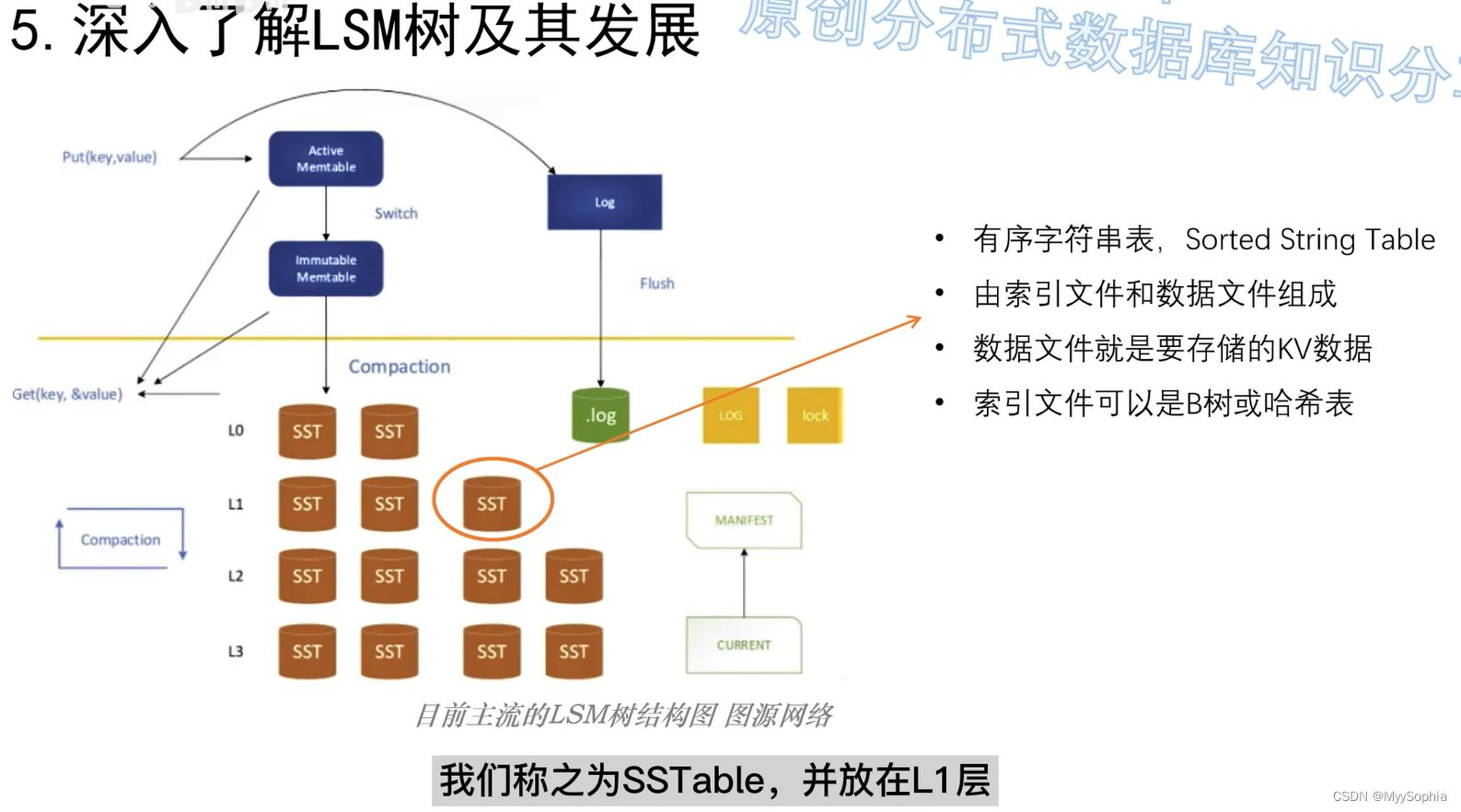
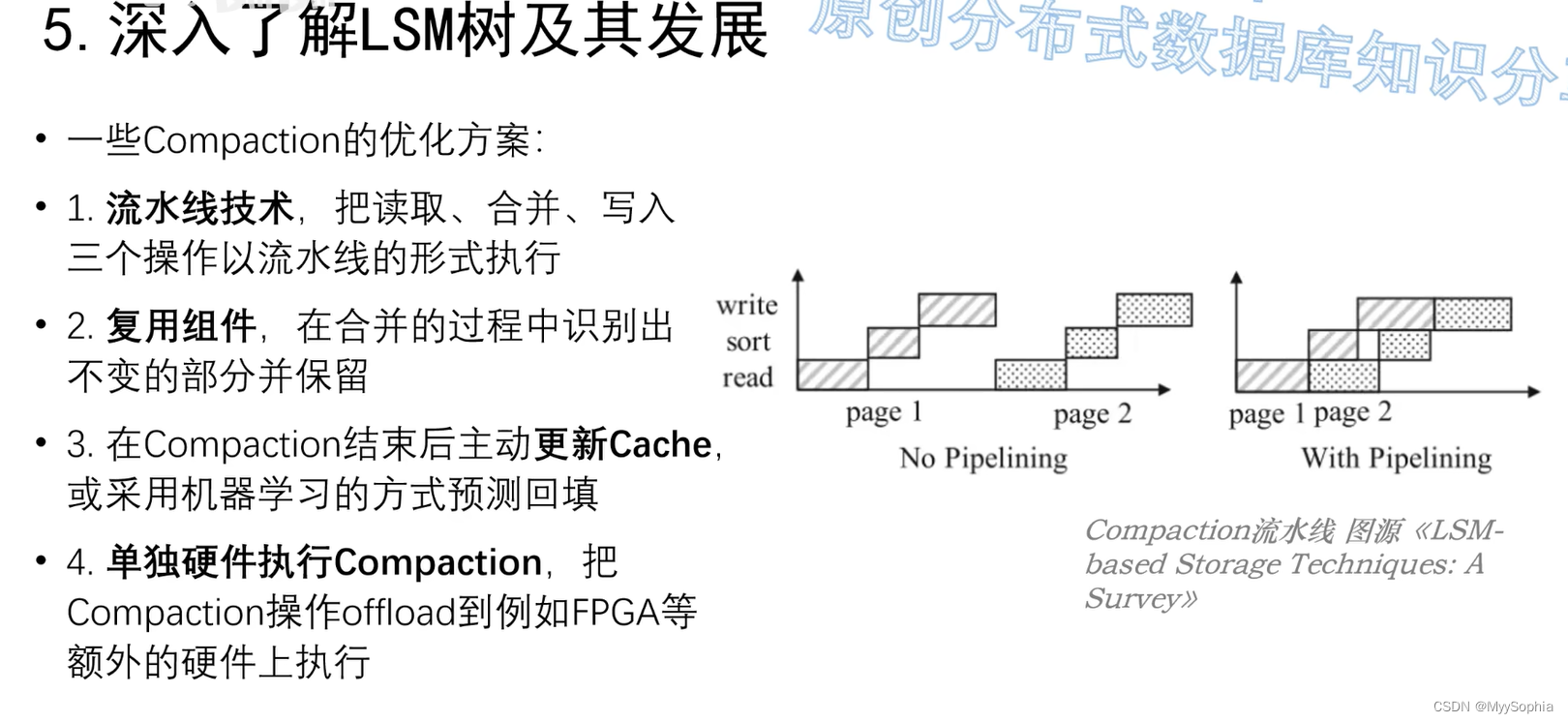
B+ tree 和LSM tree的区别?
B+ tree作为关系型数据库的存储引擎的首选数据结构是为何呢?
LSM 又是在什么情况下出现的呢?
存储和网络的发展
B+树和LSM树都是常用的数据结构,用于在磁盘上存储和管理大量的数据。它们的主要区别在于它的设计目标和适用场景。
B+树是一种平衡树,它的设计目标是在磁盘上高效地存储和查询数据。B+树的节点通常比较大,可以存储多个键值对,而且它的叶子节点形成了一个有序链表,可以支持范围查询。B+树的查询和插入操作的时间复杂度都是O(log n),其中n是数据的大小。
LSM树(Log-Structured Merge Tree)是一种基于日志的数据结构,它的设计目标是在磁盘上高效地存储和更新数据。LSM树将数据分为内存和磁盘两部分,内存部分使用一个类似于B+树的数据结构来存储数据,而磁盘部分则使用一系列有序的日志文件来存储数据。当内存部分满了之后,LSM树会将数据写入磁盘中的一个新的日志文件中。当磁盘中的日志文件数量达到一定阈值时,LSM树会将它们合并成一个新的文件。LSM树的查询和插入操作的时间复杂度都是O(log n),其中n是数据的大小。
B+树和LSM树的主要区别在于们的写入性能和空间利用率。
- B+树的写入性能比较好,因为它可以直接在磁盘上进行原更新。
- LSM树的写入性能比较差,因为它需要将数据写入内存和磁盘中的日志文件中。
- LSM树的空间利用率比较好,因为它可以将多个小的日志文件合并成一个大的文件,从而减少磁盘空间的浪费。
- B树的空间利用率比较差,因为它的节点通常比较大,而且它的叶子节点形成了一个有序链表会占用额外的空间。
因此,B+树适用于需要高效查询和范围查询的场景,而LSM树适用于需要高效写入和空间利用率的场景。 这也是为何loki存储占用空间少.
Ref

参考链接
https://www.bilibili.com/video/BV1oP4y1d7Jg/?spm_id_from=333.999.0.0
https://blog.hufeifei.cn/2021/09/Distribution/grafana/index.html