Recurrent Neural Network(RNN)
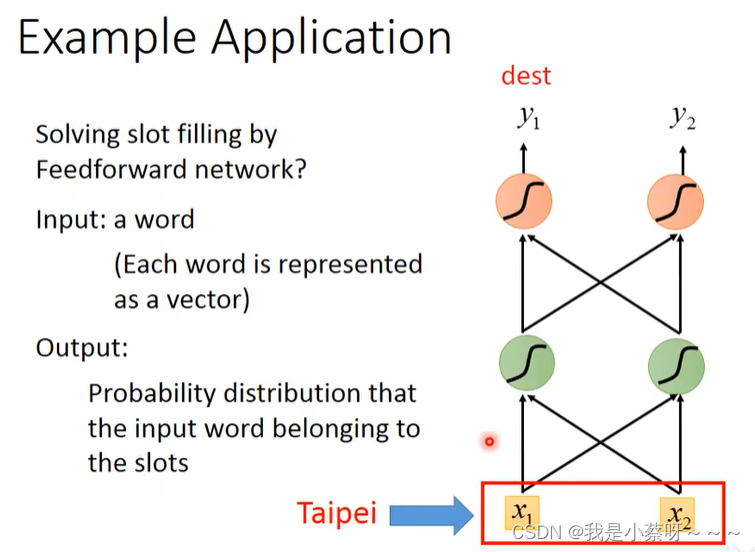
Example Application
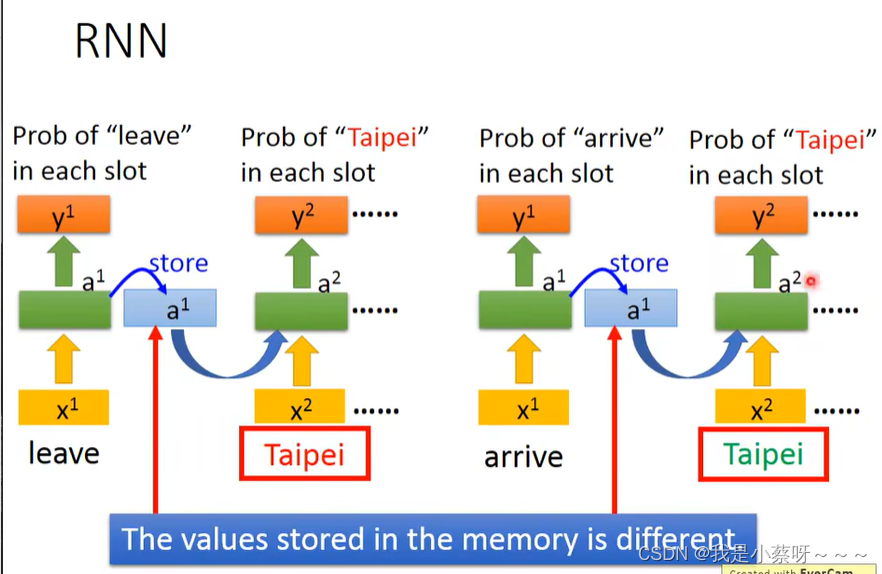
Slot Filling
智慧订票系统:
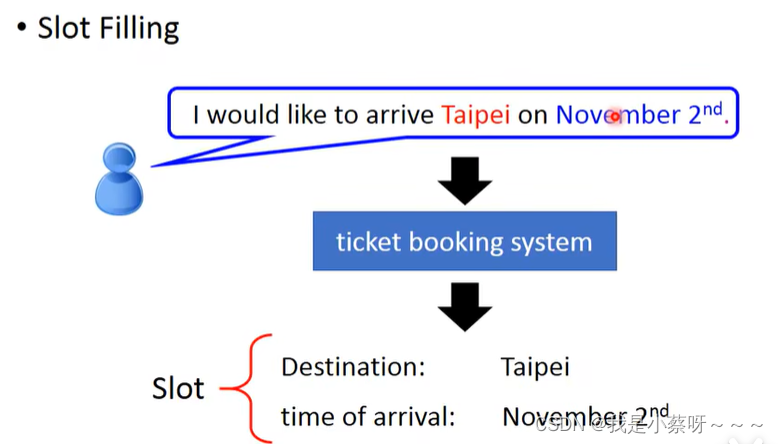

How to represent each word as a vector?


但是光这样,feedforward Network是无法solve这一问题的,因为他无法区别是leave Taipei还是arrive Taipei。
那我们就希望这个neuron network是有记忆的,即看到过arrive/leave这个词。
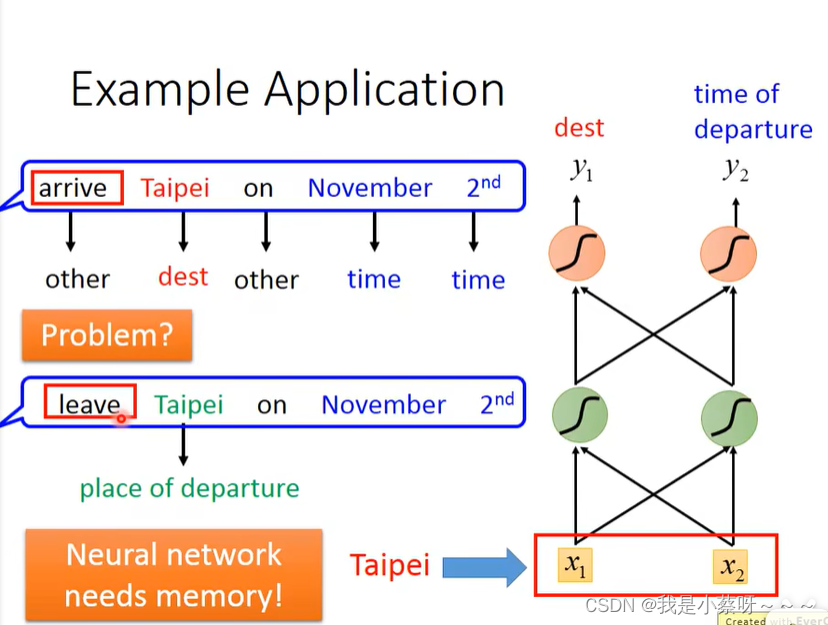
这种有记忆的network就叫做 recurrent neural network(rnn)

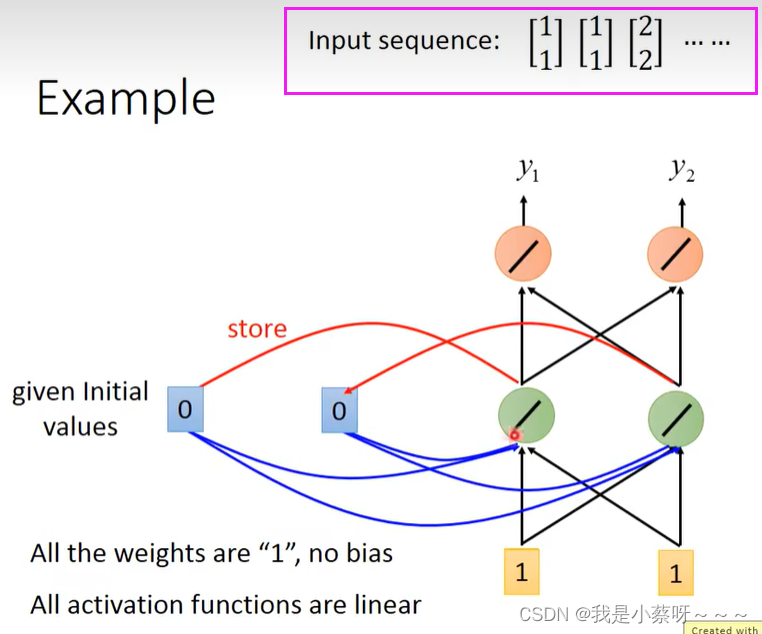
举例:
我们假设所有的w=1,没有bias;所有的激活函数都是线性的;
要给memory(每一个时间点都会被洗掉)一个初始值,我们假设给0

接下来2被存到memory中

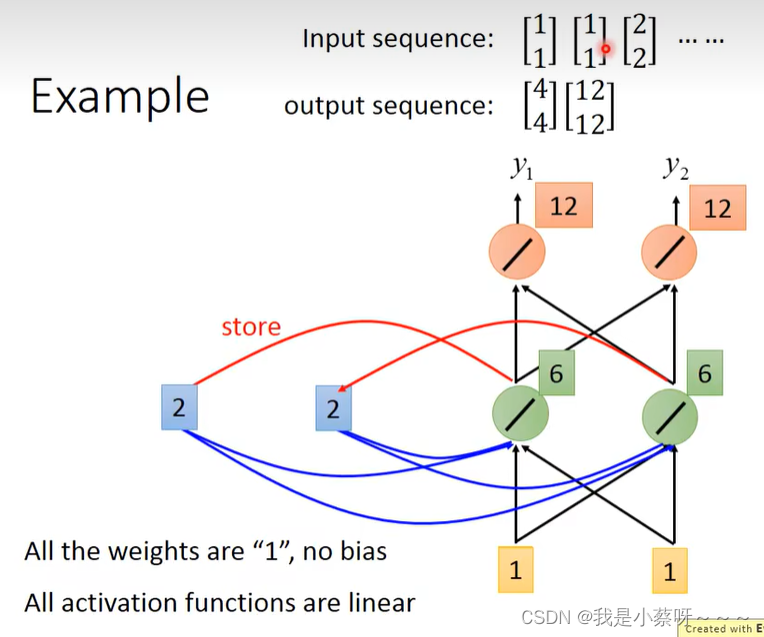
rnn会考虑input sequence的order


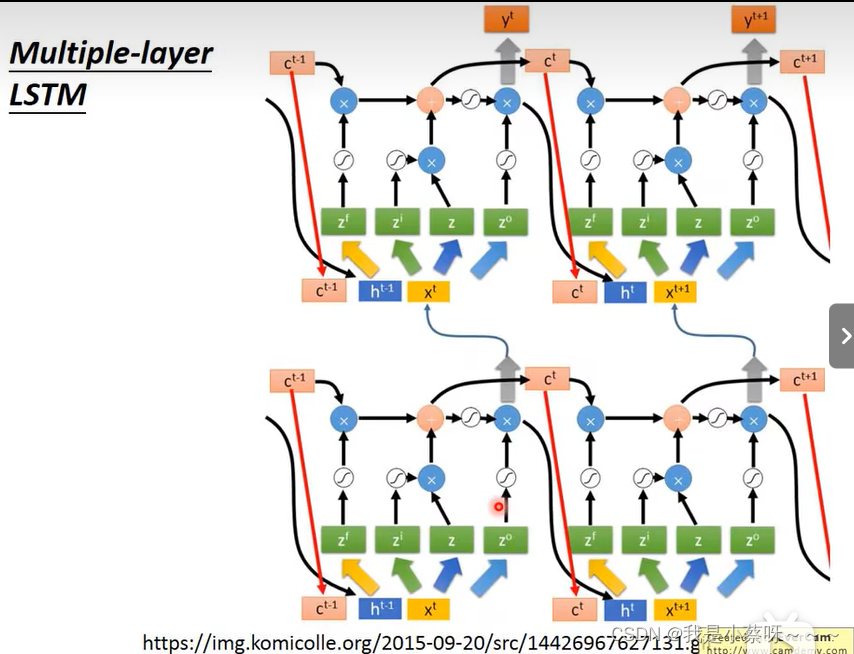
of course it can be deep…

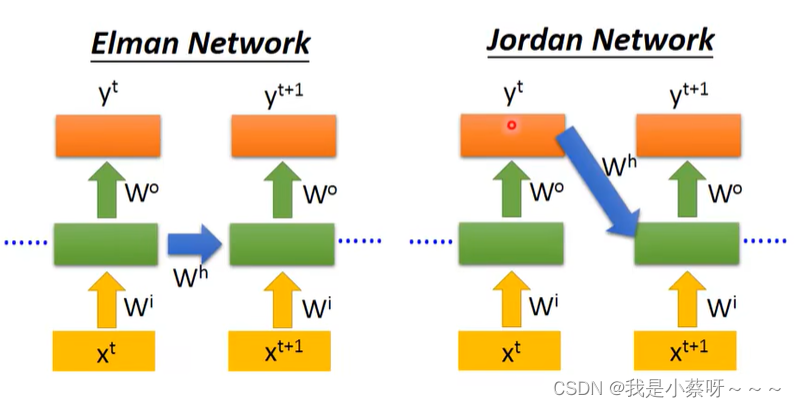
Elman Network & Jordan Network
Bidirectional RNN
同时train 一个正向的rnn和逆向的rnn


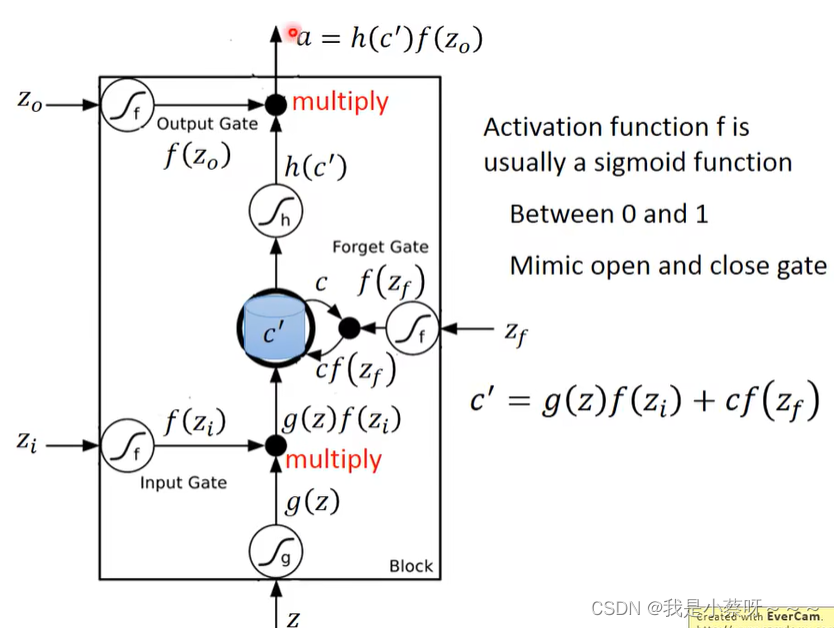
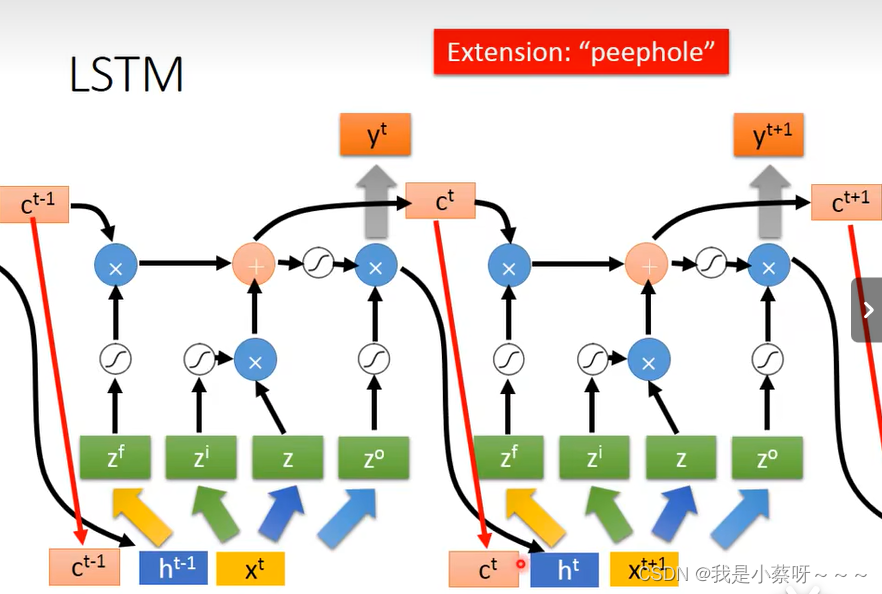
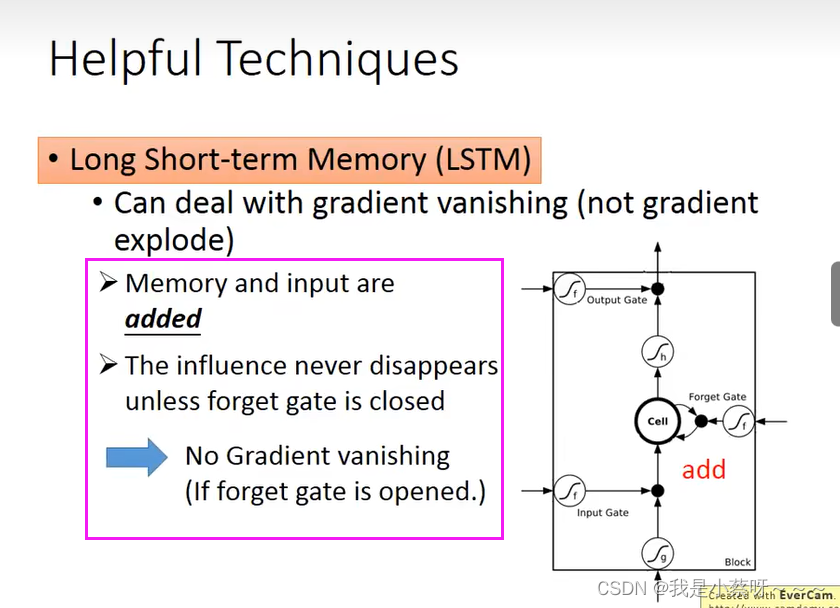
Long Short-term Memory(LSTM)
Input/Output/Forget Gate何时打开/关闭 是需要网络自己学的
LSTM有三个操控信号,一个输入信号
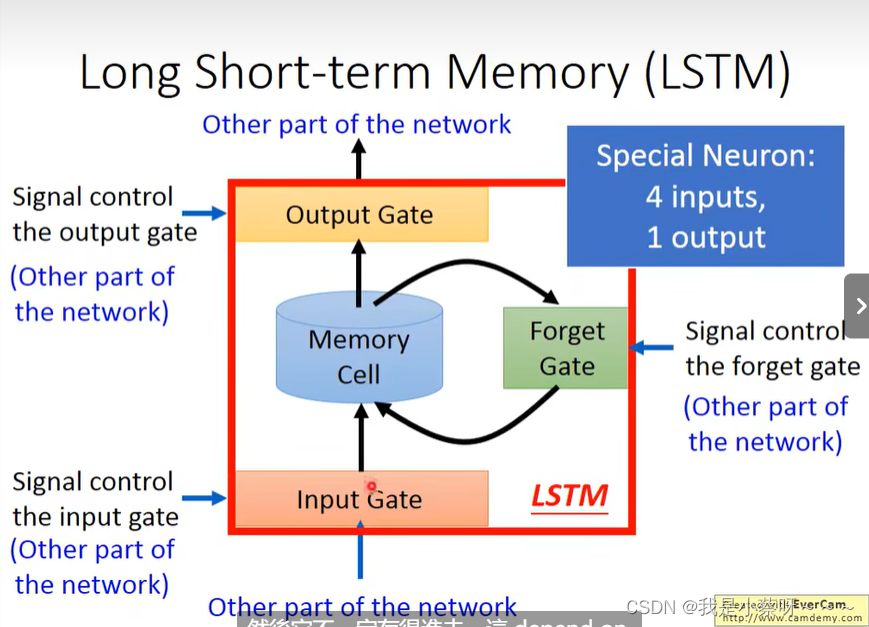
“-”为什么放在short-term之间,而不是long short之间?
因为他只是比较长的short term。是否遗忘取决于forget gate,关闭时代表遗忘。
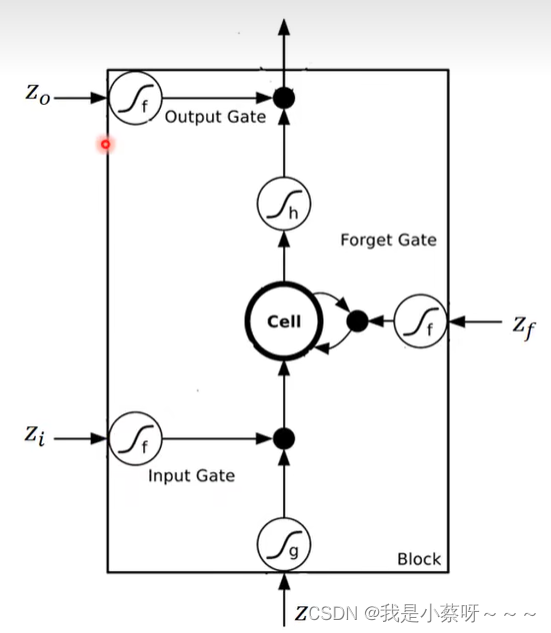
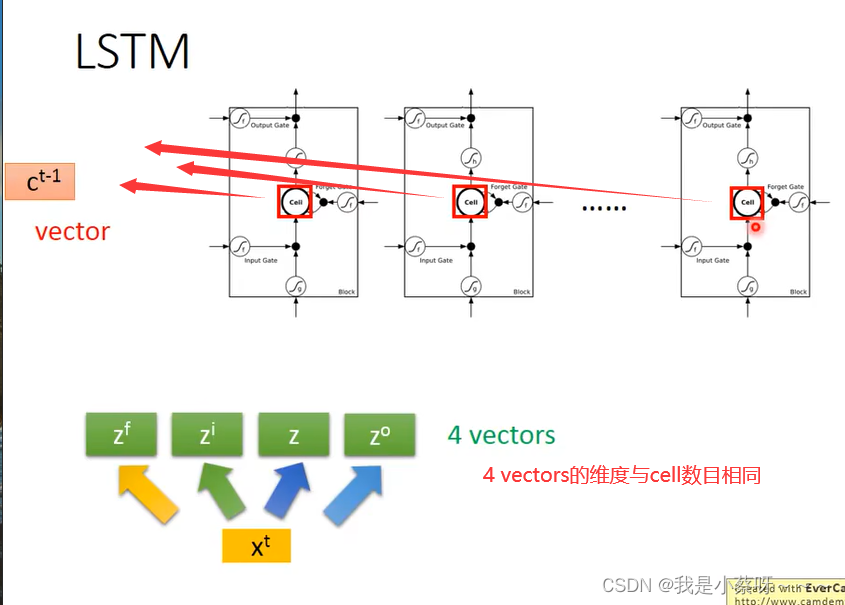
假设在四个z输入之前,cell中存了一个“c”


如果选择不遗忘c(由f(zf)决定),则需要再加起来即c‘

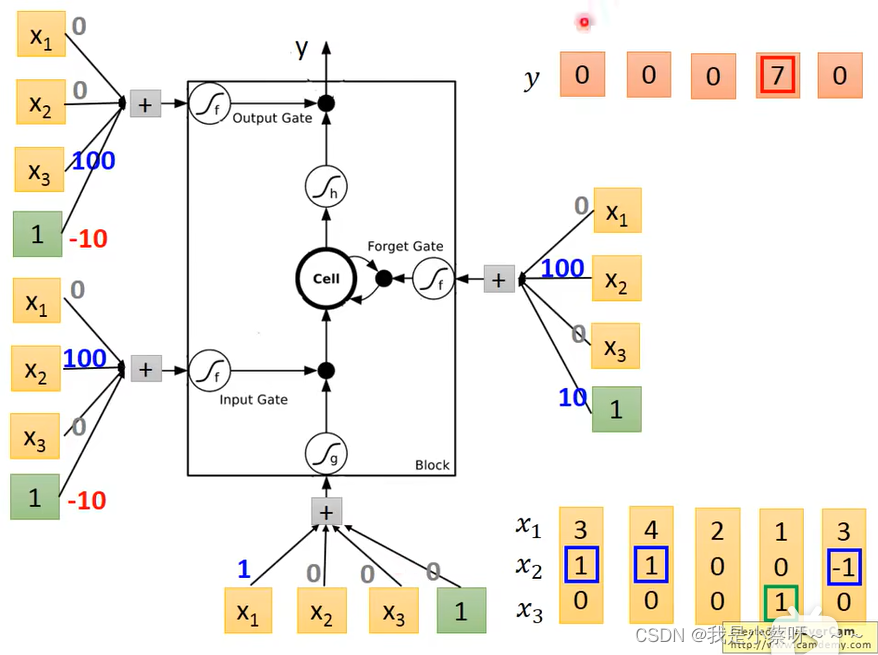
LSTM-Example


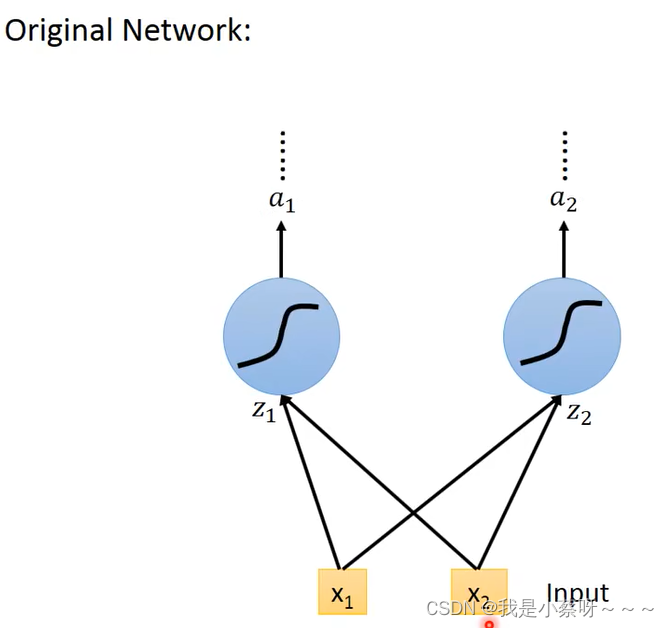
original network
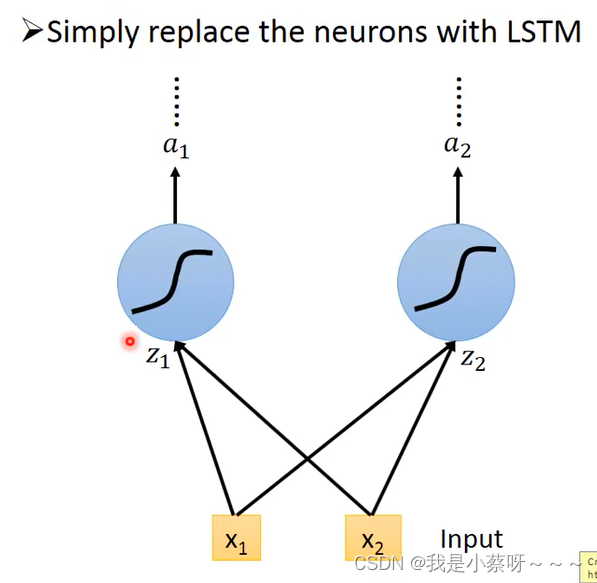
LSTM 直接将neurons替换成LSTM的cell即可




GRU是LSTM的simple版本,他只有两个gate,参数较少,所以比较不容易overfitting。simpleRNN指最原始的RNN,下图是目前标准的RNN。

Learning Target
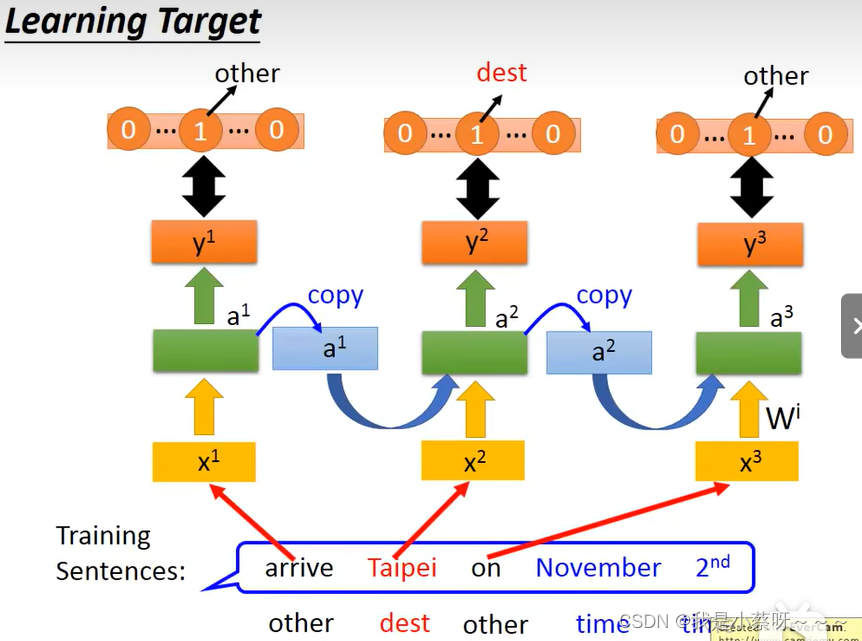
RNN 用 Gradient Descent是可以train的
Backpropagation through time(BPTT) 基于时间的反向传播算法。


Why?


如何解决?
Clipping. 裁剪,当梯度过大时候进行裁剪。
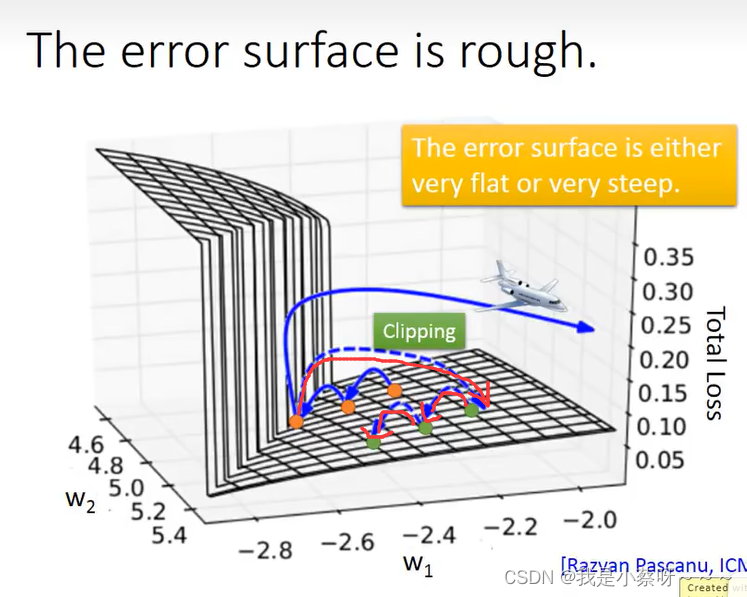
为什么rnn会有这种奇特的特性呢?
sigmoid function? no
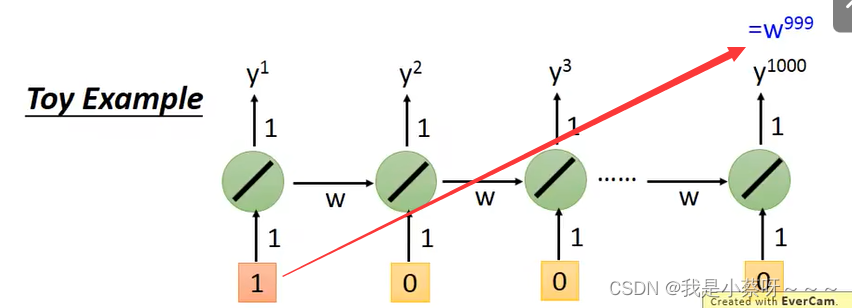

有什么样的技巧可以帮助我们解决这个问题呢?

可以让你的error surface不要那么崎岖, 在做LSTM时,你可以放心的把learning rate设置的特别小。
为什么我们要把RNN换成LSTM? LSTM可以handle gradient vanishing的问题。
为什么可以handle gradient vanishing的问题?
一旦你的weight,可以对memory的值发生影响时,这个影响会一直存在,除非forget gate关闭。不像rnn,其在每一个时间的会被forget掉。

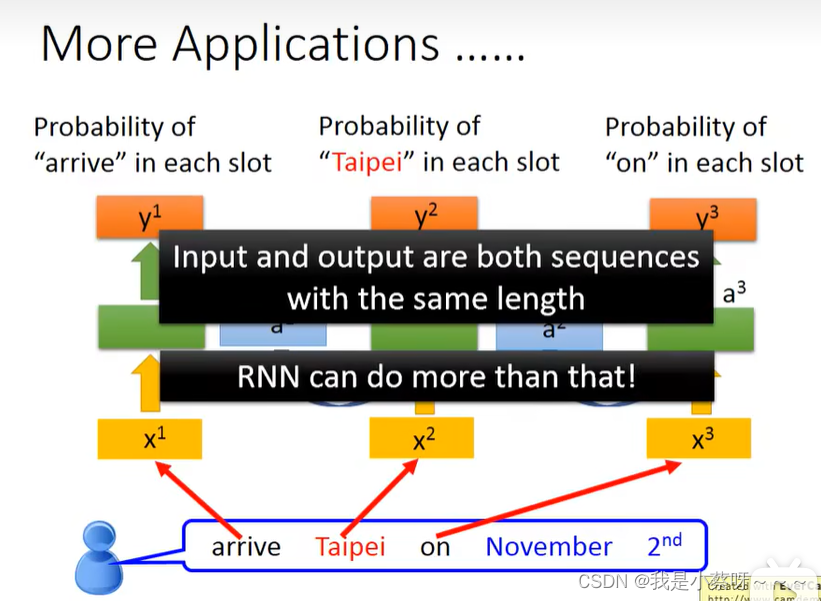
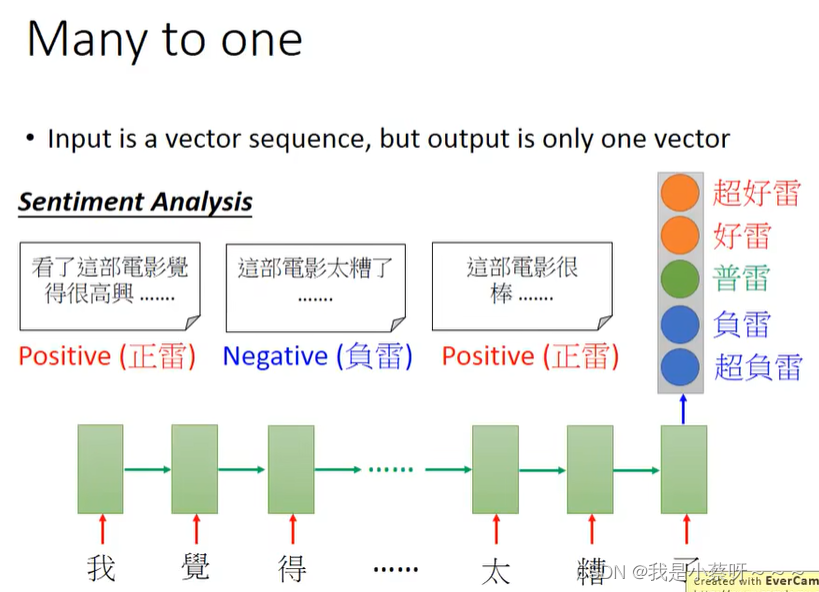
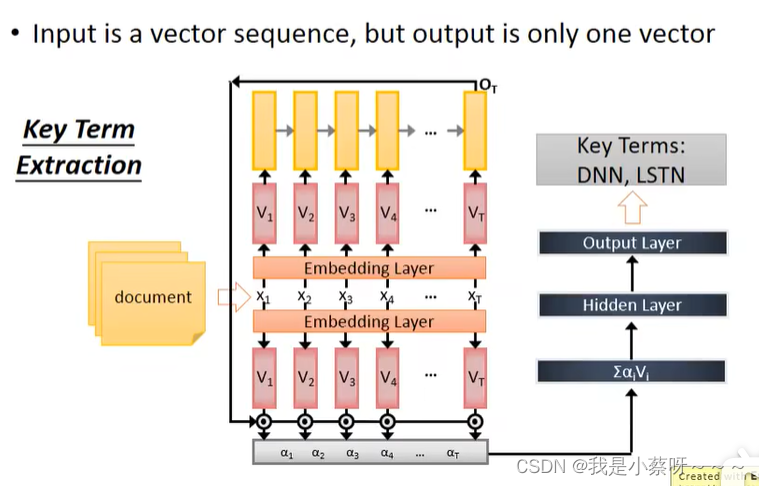
Application
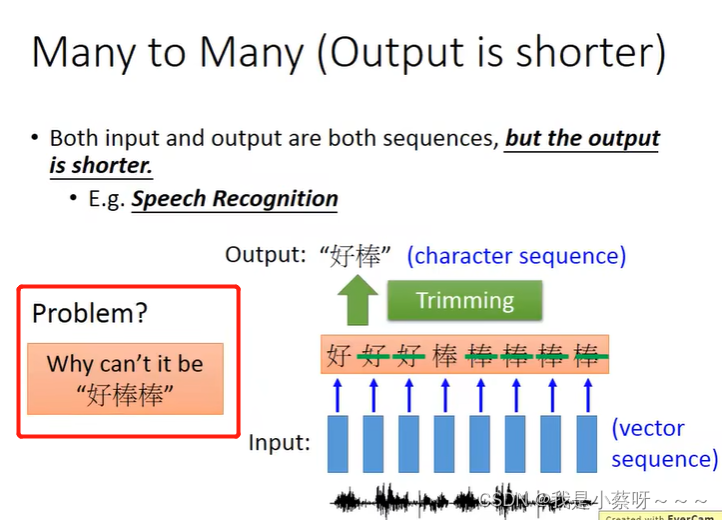
如何解决?
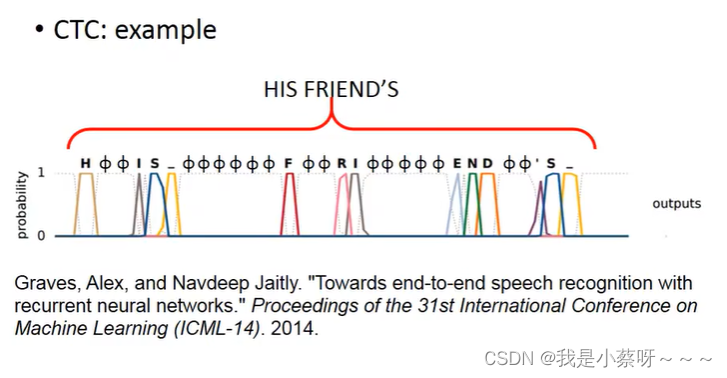
CTC


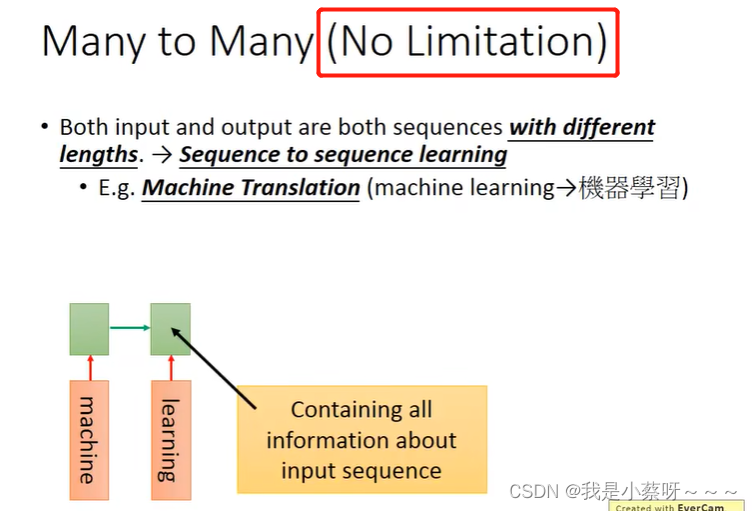


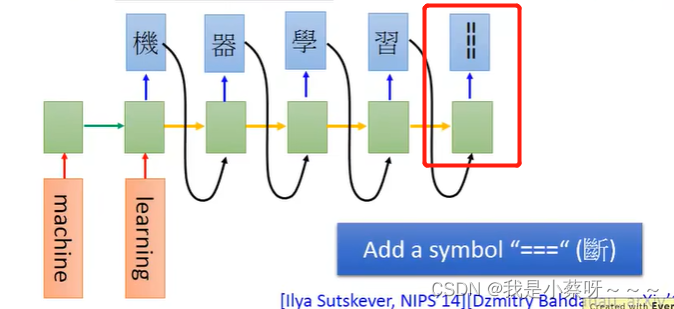
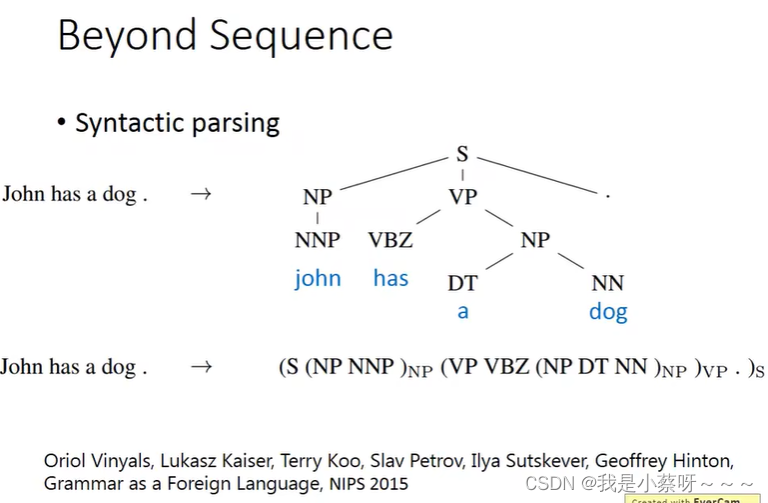
句法解析
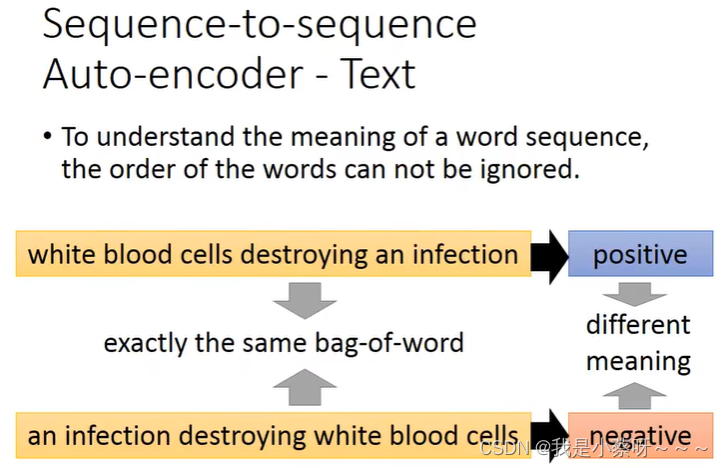

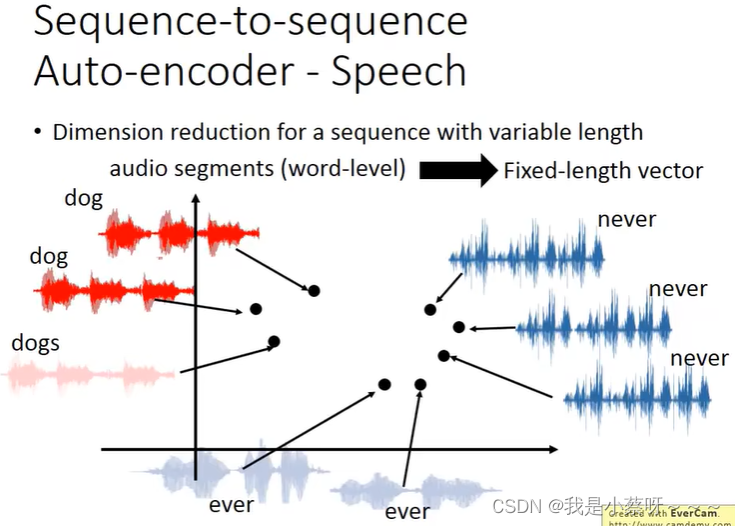

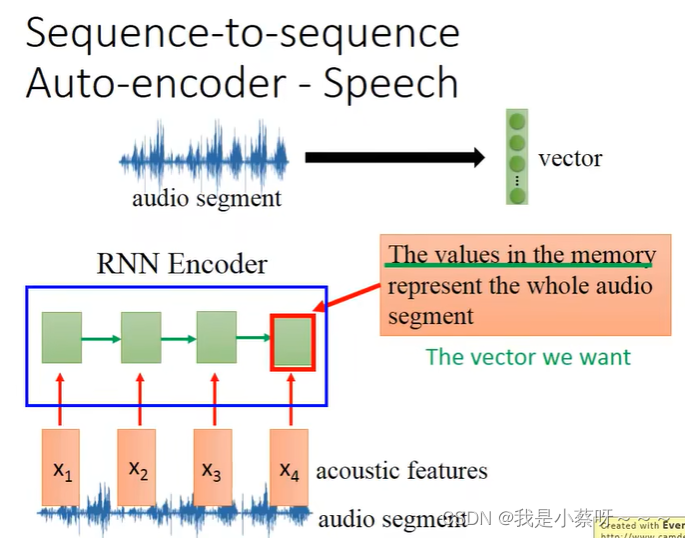
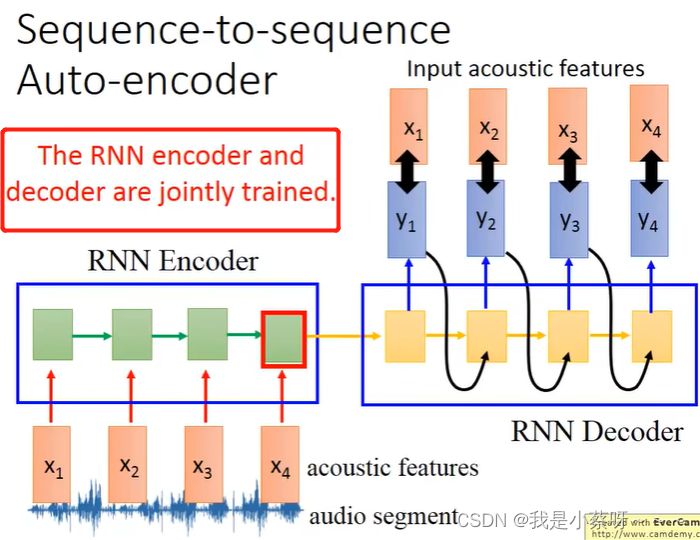
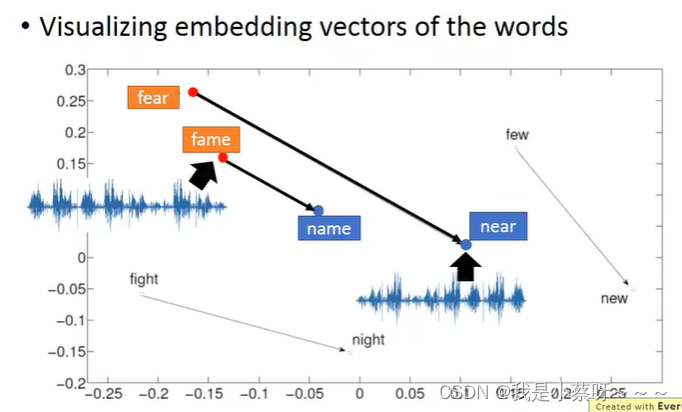
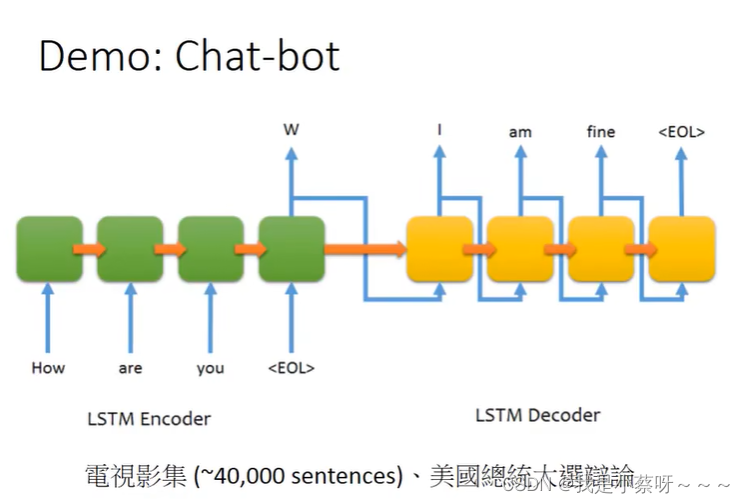
Attention-based Model
可以想成RNN的进阶版本




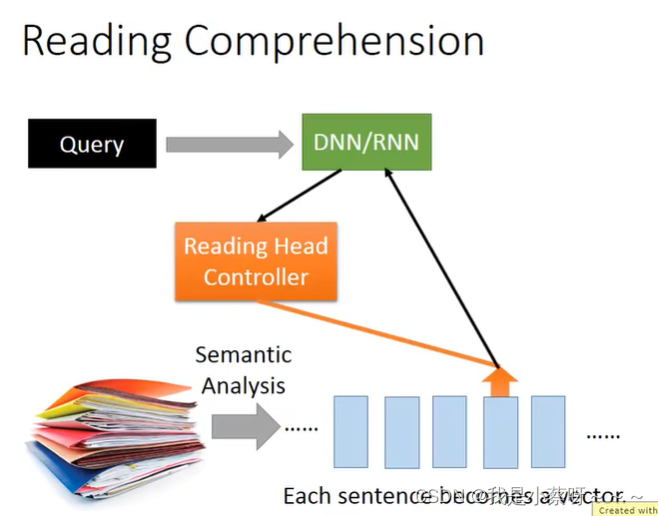
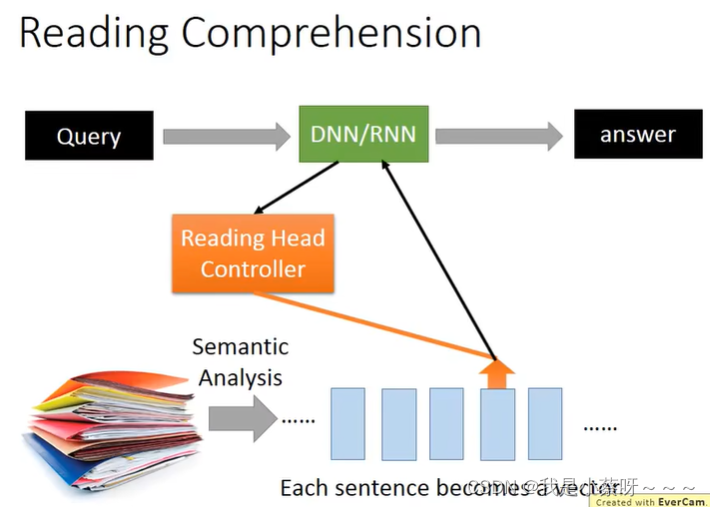
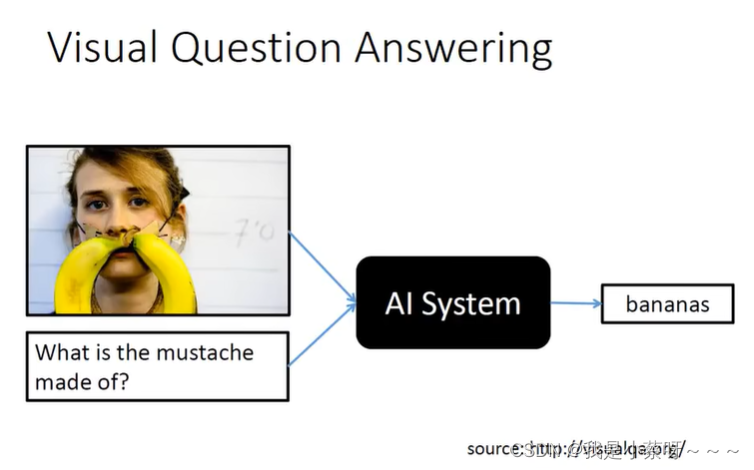





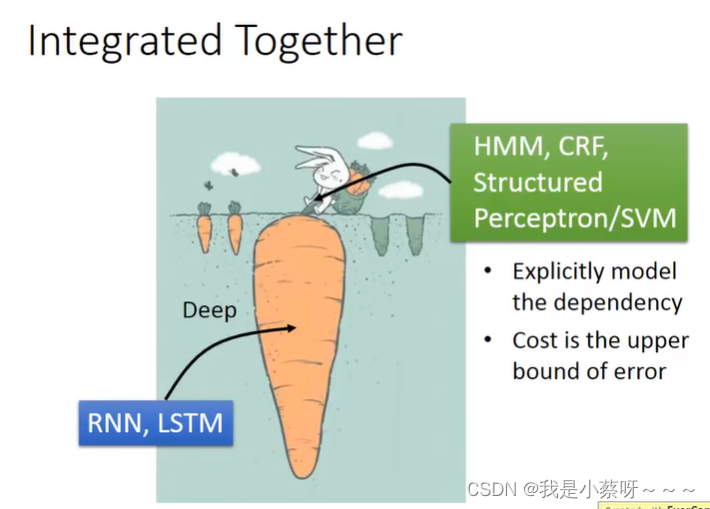
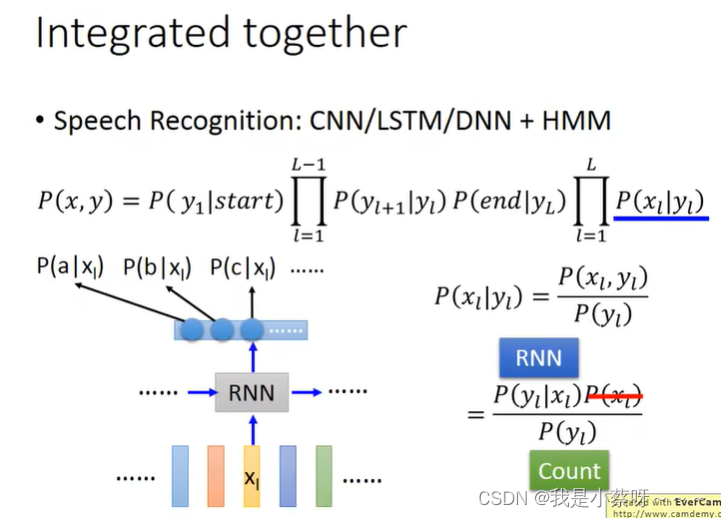
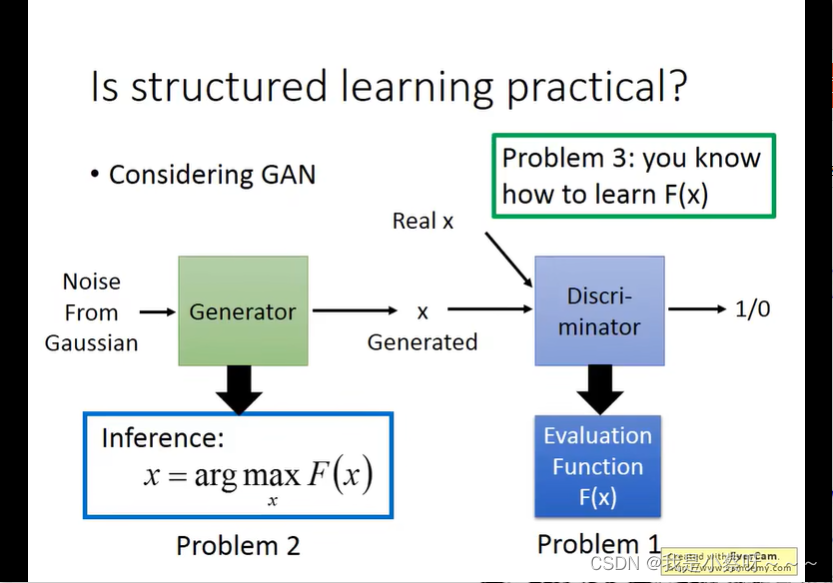
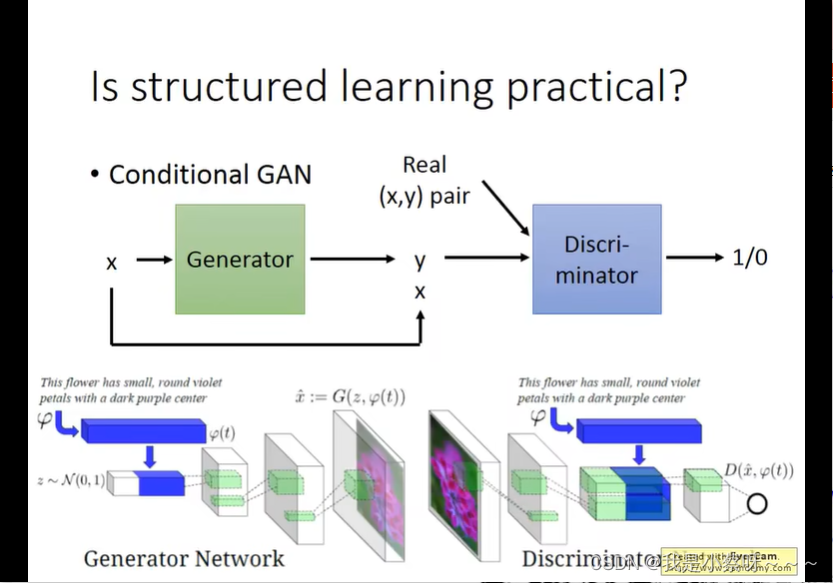
Deep&Structured



![[附源码]Python计算机毕业设计SSM康健医药公司进销存管理系统(程序+LW)](https://img-blog.csdnimg.cn/27f9176cb77e4c008a47b19f60317a96.png)
![[附源码]Python计算机毕业设计SSM酒店入住管理系统(程序+LW)](https://img-blog.csdnimg.cn/012b4464474345be87030f49f61a1ac2.png)