前言
上一篇我们介绍了MobileNetV1,主要是将普通Conv转换为dw和pw,但是在dw中训练出来可能会很多0,也就是depthwise部分得到卷积核会废掉,即卷积核参数大部分为0,因为权重数量可能过少,再加上Relu激活函数的原因。
后来作者大大又做了修改,MobileNetV2使用了深度可分离卷积+先升维+倒残差+低维不使用ReLU的策略构建了比V1效果更好更轻量的网络。接下来我们就一起学习一下吧~
学习资料:
- 论文题目:《MobileNetV2: Inverted Residuals and Linear Bottlenecks》(《MobileNetV2:倒残差和线性瓶颈》)
- 原文地址:MobileNetV2: Inverted Residuals and Linear Bottlenecks | IEEE Conference Publication | IEEE Xplore
- 项目地址:GitHub - Randl/MobileNetV2-pytorch: Impementation of MobileNetV2 in pytorch
前期回顾:
【轻量化网络系列(1)】MobileNetV1论文超详细解读(翻译 +学习笔记+代码实现)
目录
前言
Abstract—摘要
一、Introduction—介绍
二、Related Work—相关工作
三、Preliminaries, discussion and intuition—准备、讨论和直觉
3.1 Depthwise Separable Convolutions—深度可分离卷积
3.2 Linear Bottlenecks—线性瓶颈层
3.3 Inverted residuals—反向残差
3.4 Information flow interpretation—信息流解释
四、Model Architecture—模型架构
五、Implementation Notes—实现细节说明
5.1 Memory efficient inference—高效推理内存
六、Experiments—实验
6.1 ImageNet Classification—ImageNet数据集分类
6.2 Object Detection—目标检测
6.3 Semantic Segmenta tion—语义分割
6.4 Ablation study—消融研究
七、Conclusions and future work—总结和未来工作
🌟代码实现
![]()
Abstract—摘要
翻译
在本文中,我们描述了一种新的移动架构MobileNetV2,该架构提高了移动模型在多个任务和多个基准数据集上以及在不同模型尺寸范围内的最佳性能。我们还描述了在我们称之为SSDLite的新框架中将这些移动模型应用于目标检测的有效方法。此外,我们还演示了如何通过DeepLabv3的简化形式,我们称之为Mobile DeepLabv3来构建移动语义分割模型。
MobileNetV2架构基于倒置的残差结构,其中快捷连接位于窄的瓶颈层之间。中间展开层使用轻量级的深度卷积作为非线性源来过滤特征。此外,我们发现为了保持表示能力,去除窄层中的非线性是非常重要的。我们证实了这可以提高性能并提供了产生此设计的直觉。
最后,我们的方法允许将输入/输出域与变换的表现力解耦,这为进一步分析提供了便利的框架。我们在ImageNet[1]分类,COCO目标检测[2],VOC图像分割[3]上评估了我们的性能。我们评估了在精度、通过乘加(MAdd)度量的操作次数,以及实际的延迟和参数的数量之间的权衡。
精读
本文主要工作
(1)本文提出了一种新的移动端架构MobileNet V2,在当前移动端模型中最优
(2)本文介绍了一种新框架:SSDLite,描述了如何通过SSDLite将这些移动模型应用于对象检测
(3)本文还演示了如何通过简化形式的DeepLabv3(称之为mobile DeepLabv3)构建移动端的语义分割模型
一、Introduction—介绍
翻译
神经网络已经彻底改变了机器智能的许多领域,使具有挑战性的图像识别任务获得了超过常人的准确性。然而,提高准确性的驱动力往往需要付出代价:现代先进网络需要超出许多移动和嵌入式应用能力之外的高计算资源。
本文介绍了一种专为移动和资源受限环境量身定制的新型神经网络架构。我们的网络通过显著减少所需操作和内存的数量,同时保持相同的精度推进了移动定制计算机视觉模型的最新水平。
我们的主要贡献是一个新的层模块:具有线性瓶颈的倒置残差。该模块将输入的低维压缩表示首先扩展到高维并用轻量级深度卷积进行过滤。随后用线性卷积将特征投影回低维表示。官方实现可作为[4]中TensorFlow-Slim模型库的一部分。
这个模块可以使用任何现代框架中的标准操作来高效地实现,并允许我们的模型使用标准基线沿多个性能点击败最先进的技术。此外,这种卷积模块特别适用于移动设计,因为它可以通过从不完全实现大型中间张量来显著减少推断过程中所需的内存占用。这减少了许多嵌入式硬件设计中对主存储器访问的需求,这些设计提供了少量高速软件控制缓存。
精读
本文主要贡献
- Inverted Residuals :倒残差结构
- Linear Bottlenecks:结构的最后一层采用线性层
该模块将低维压缩表示作为输入,首先将其扩展到高维,并使用轻型深度卷积进行过滤。特征随后通过线性卷积投影回低维表示。
该模块的优点
(1)该模块可以在任何现代框架中高性能实现。
(2)适合于移动设计。减少了许多嵌入式硬件设计中对主内存访问的需求,提供了少量非常快速的软件控制高速缓存。
二、Related Work—相关工作
翻译
调整深层神经架构以在精确性和性能之间达到最佳平衡已成为过去几年研究活跃的一个领域。由许多团队进行的手动架构搜索和训练算法的改进,已经比早期的设计(如AlexNet[5],VGGNet [6],GoogLeNet[7]和ResNet[8])有了显著的改进。最近在算法架构探索方面取得了很多进展,包括超参数优化[9,10,11]、各种网络修剪方法[12,13,14,15,16,17]和连接学习[18,19]。 也有大量的工作致力于改变内部卷积块的连接结构如ShuffleNet[20]或引入稀疏性[21]和其他[22]。
最近,[23,24,25,26]开辟了了一个新的方向,将遗传算法和强化学习等优化方法带入架构搜索。然而,一个缺点是最终所得到的网络非常复杂。在本文中,我们追求的目标是发展了解神经网络如何运行的更好直觉,并使用它来指导最简单可能的网络设计。我们的方法应该被视为[23]中描述的方法和相关工作的补充。在这种情况下,我们的方法与[20,22]所采用的方法类似,并且可以进一步提高性能,同时可以一睹其内部的运行。我们的网络设计基于MobileNetV1[27]。它保留了其简单性,并且不需要任何特殊的运算符,同时显著提高了它的准确性,为移动应用实现了在多种图像分类和检测任务上的最新技术。
精读
以前的相关工作
- 调整深度神经架构以在准确性和性能之间取得最佳平衡
- 超参数优化以及各种网络修剪方法和连通性学习
- 改变内部卷积块的连接结构(ShuffleNet或引入稀疏性等)
本文的目标
开发关于神经网络如何操作的更好的直觉,并使用它来指导最简单的网络设计。
三、Preliminaries, discussion and intuition—准备、讨论和直觉
3.1 Depthwise Separable Convolutions—深度可分离卷积
翻译
深度可分卷积是许多高效神经网络架构的关键组成部分[27,28,20],我们在目前的工作中也使用它们。其基本思想是用分解版本替换完整的卷积运算符,将卷积拆分为两个单独的层。第一层称为深度卷积,它通过对每个输入通道应用单个卷积滤波器来执行轻量级滤波。第二层是1×1卷积,称为逐点卷积,它负责通过计算输入通道的线性组合来构建新特征。
标准卷积使用K∈R^k×k×di×dj维的输入张量Li,并对其应用卷积核K∈R^k×k×di×dj来产生hi×wi×dj维的输出张量Lj。标准卷积层的计算代价为hi⋅wi⋅di⋅dj⋅k⋅k。
深度可分卷积是标准卷积层的直接替换。经验上,它们几乎与常规卷积一样工作,但其成本为:
hi⋅wi⋅di(k2+dj) (1)
它是深度方向和1×1逐点卷积的总和。深度可分卷积与传统卷积层相比有效地减少了几乎k^2倍的计算量。MobileNetV2使用k=3(3×3的深度可分卷积),因此计算成本比标准卷积小88到99倍,但精度只有很小的降低[27]。
精读
这个在MobileNetV1(点这里复习一下)时我们就见过了:
- 第一层是深度卷积,它通过对每个输入通道应用单个卷积核来执行轻量级卷积。
- 第二层是逐点卷积,也就是1×1卷积,负责通过计算输入通道的线性组合来构建新特征。
虽然精读略有降低,但计算量比标准卷积低8到9倍。
3.2 Linear Bottlenecks—线性瓶颈层
翻译
考虑一个由n层Li组成的深度神经网络,每层都有一个hi×wi×di维的激活张量。在本节中,我们将讨论这些激活张量的基本属性,我们将把它们看作hi×wi个具有di维的“pixels”。非正式地,对于输入的一组真实图像,我们说层激活的集合(对于任何层Li)形成一个“感兴趣的流形”。长久以来,人们一直认为神经网络中的流形可以嵌入到低维子空间中。换句话说,当我们查看深层卷积层的所有单独的d通道像素时,在这些值中编码的信息实际上位于某个流形中,这反过来又可嵌入到低维子空间中。
乍一看,这样的实例可以通过简单地减少层的维度来捕获和利用,从而降低操作空间的维度。这已经被MobileNetV1[27]成功利用,通过宽度乘数参数在计算量和精度之间进行有效折衷,并且已经被合并到其他网络的高效模型设计中[20]。遵循这种直觉,宽度乘数方法允许降低激活空间的维度,直到感兴趣的流形横跨整个空间为止。然而,当我们回想到深度卷积神经网络实际上具有非线性的每个坐标变换(例如ReLU)时,这种直觉就会失败。 例如,在1维空间中的一行应用ReLU会产生一个ray,在Rn空间中,它通常会产生一个具有n个连接的分段线性曲线。
很容易看出,如果层变换ReLU(Bx)的结果具有非零的体积S,映射到内部S的点通常通过输入的线性变换B获得,因此表明与全维度输出相对应的输入空间的一部分受限于线性变换。换句话说,深层网络只在输出域的非零体积部分具有线性分类器的能力。我们将在补充材料中进行更正式的说明。
另一方面,当ReLU破坏通道时,它不可避免地会丢失该通道的信息。但是,如果我们有很多通道,并且激活流形中有一个结构,信息可能仍然保留在其它通道中。在补充材料中,我们说明,如果输入流形可以嵌入到激活空间的显著较低维子空间中,则ReLU变换将保留该信息,同时将所需的复杂性引入到可表达的函数集中。
总而言之,我们已经强调了两个特性,这些特性表明需要的感兴趣流行应该位于较高维激活空间的低维子空间中:
1.如果感兴趣的流形在ReLU转换后保持非零体积,则其对应于线性转换。
2.只有当输入流形位于输入空间的低维子空间时,ReLU才能保留有关输入流形的完整信息。
这两个深刻见解为我们提供了优化现有神经架构的经验提示:假设感兴趣流形是低维的,我们可以通过将线性瓶颈层插入到卷积模块中来捕获这一点。实验证据表明,使用线性层是至关重要的,因为它可以防止非线性破坏太多的信息。在第6节中,我们通过经验证明,在瓶颈中使用非线性层确实会使性能降低几个百分点,进一步证实了我们的假设。我们注意到[29]报告了非线性得到帮助的类似报告,其中非线性已从传统残差块的输入中移除,并导致CIFAR数据集的性能得到了改善。
对于本文的其余部分,我们将利用瓶颈卷积。我们将把输入瓶颈的大小与内部大小之间的比例作为扩展比。
精读
v1的做法以及不足
做法:引入α参数来做模型通道的缩减,相当于给模型“瘦身”,这样特征信息就能更集中在缩减后的通道中。
不足:但研究人员发现深度可分离卷积中有大量卷积核为0,即有很多卷积核没有参与实际计算。
v2的作者发现是ReLU激活函数的问题,认为 ReLU这个激活函数,在低维空间运算中会损失很多信息,而在高维空间中会保留较多有用信息 。
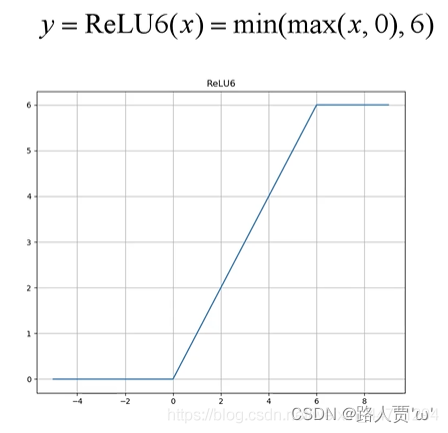
ReLU与维度的关系

ReLU会对维度较低的张量造成较大的信息损耗。
- 维度越低,损失信息越多。(如2和3已经没有螺旋的样子了)
- 维度越高,损失信息越少。(当原始输入维度数增加到15以后再加ReLU,基本不会丢失太多的信息,接近输入)
两个性质
(1)如果"manifold of interest"都为非零值,则经过ReLU相当于只做了一个线性变换,没有信息丢失
(2)维度足够多时,ReLU能够保留"manifold of interest"的完整信息
本文方法
论文针对这个问题在Bottleneck末尾使用Linear Bottleneck(即不使用ReLU激活,做了线性变换)来代替原本的非线性激活变换。具体到v2网络中就是将最后的Point-Wise卷积的ReLU6都换成线性函数。
实验证据表明,使用线性层至关重要,因为它可以防止非线性破坏太多的信息。
可分离卷积块的演化

- 2(a):标准卷积(一个大方块);
- 2(b):深度可分离卷积(=Depthwise convolution+Pointwise Convolution=薄片片+方块块);
- 2(c):linear bottleneck,(高维后)relu6-dw-relu6-pw,降维-升维-;
- 2(d):和图2(c)等效,(线性激活后)pw升维-relu6-dw-relu6-pw,降维-线性激活;
3.3 Inverted residuals—反向残差
翻译
瓶颈块与残差块类似,其中每个块包含一个输入,然后是几个瓶颈,然后是扩展[8]。然而,受直觉的启发,瓶颈实际上包含所有必要的信息,而扩展层只是伴随张量非线性变换的实现细节,我们直接在瓶颈之间使用快捷连接。图3提供了设计差异的示意图。插入快捷连接的动机与经典的残差连接类似:我们想要提高梯度在乘法层之间传播的能力。但是,倒置设计的内存效率要高得多(详见第5节),而且在我们的实验中效果稍好。

图3:残差块[8,30]和倒置残差之间的差异。对角阴影线层不使用非线性。我们用每个块的厚度来表明其相对数量的通道。注意经典残差是如何将通道数量较多的层连接起来的,而倒置残差则是连接瓶颈。最好通过颜色看。
瓶颈卷积的运行时间和参数计数基本实现结构如表1所示。对于大小为h×w的块,扩展因子为t,内核大小为k,具有d′维输入通道和d″维输出通道,所需的乘法加法总数为h⋅w⋅d′⋅t(d′+k2+d′′)。与(1)相比,这个表达式有一个额外项,因为实际上我们有一个额外的1×1卷积,但是我们的网络性质使我们能够利用更小的输入和输出维度。在表3中,我们比较了MobileNetV1,MobileNetV2和ShuffleNet之间每种分辨率所需的尺寸。

表1:瓶颈残差块从k转换为k′个通道,步长为s,扩展系数为t。
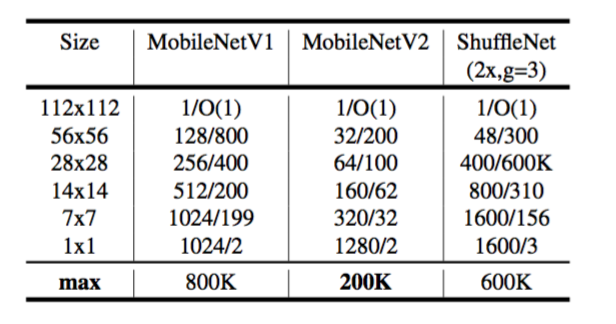
表3:不同架构中需要在每个空间分辨率上实现的最大通道数/内存(以Kb为单位)。我们假设激活使用16位浮点数。对于ShuffleNet,我们使用与MobileNetV1和MobileNetV2的性能相匹配的2x,g=3。对于MobileNetV2和ShuffleNet的第一层,我们可以采用第5节中描述的技巧来降低内存需求。尽管ShuffleNet在其它地方使用了瓶颈,但由于存在非瓶颈张量之间的快捷连接,因此非瓶颈张量仍然需要实现。
精读
引入问题
如果整个网络都是低维那么整体的运算速度就会很快,但会有信息丢失;如果提取足够多的特征的话,还是希望有高纬度通道来做这件事。
深度卷积本身没有改变通道的作用,比如本文前例中的深度可分离卷积的例子,在前一半的深度卷积操作中,输入通道数量就是输出通道数量。
本文的做法
MobileNetV2中首先在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,最后再压缩数据,让网络变小。

举个例子: 假设输入到Inverted Residual的输入为56×56×24,则先经过1×1的Conv进行升维,扩展因子 t 为6,维度变为144。然后经过3×3的DW卷积,维度不变。最后再使用1×1的Conv进行降维,维度变为24.
ResNet和MobileNetV2对比

- ResNet: 降维 (0.25倍)-->卷积-->再升维。
- MobileNetV2 : 先升维 (6倍)-->卷积-->再降维。
论文中的图示
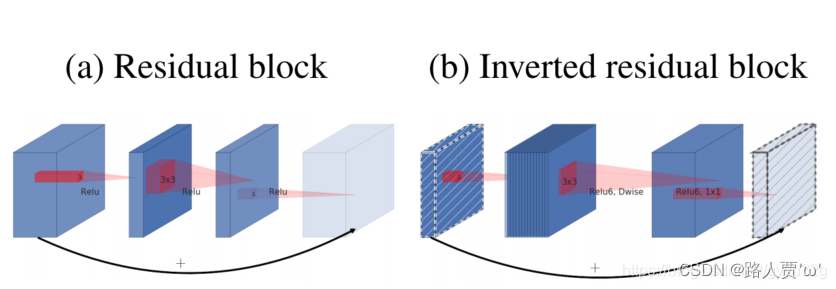
- (a)为residual block模块,短路连接线之间通道数是少的,呈“两边多,中间小”。
- (b)则是为了尽量使ReLU6能够更好与深度可分离卷积兼容,所以在短路连接线之间的通道数是最多的,而两边的通道则比中间小。呈“两边少,中间多”。所以作者称其为Inverted residual block。
3.4 Information flow interpretation—信息流解释
翻译
我们架构的一个有趣特性是它在构建块(瓶颈层)的输入/输出域与层转换之间提供了自然分离——这是一种将输入转换为输出的非线性函数。前者可以看作是网络在每一层的容量,而后者则是表现力。与常规和可分离的传统卷积块相比,其中表现力和容量都缠结在一起并且是输出层深度的函数。
特别是在我们的实例中,当内层深度为0时,由于快捷连接,基础卷积是恒等函数。当扩展比率小于1时,这是一个经典的残差卷积块[8,30]。但是,就我们的目的而言,我们表明扩大比率大于1是最有用的。
这种解释使我们能够独立于其容量研究网络的表现力,并且我们认为需要进一步探索这种分离,以便更好地理解网络性质。
精读
架构块的特点
它在构建块的输入/输出域(瓶颈层)和层转换之间提供了一种自然的分离,层转换是一种将输入转换为输出的非线性函数。
前者可以被视为网络在每一层的容量,而后者则被视为表现力。
传统卷积块的特点
在传统的卷积块中,表达能力和容量都纠结在一起,是输出层深度的函数。
四、Model Architecture—模型架构
翻译
现在我们详细描述我们的架构。正如前一节所讨论的那样,基本构件块是一个瓶颈深度可分离的残差卷积。该模块的详细结构如表1所示。MobileNetV2的架构包含具有32个滤波器的初始全卷积层,接着是表2中描述的19个残差瓶颈层。我们使用ReLU6作为非线性,因为用于低精度计算时它的鲁棒性[27]。我们总是使用现代网络中的标准核尺寸3×3,并在训练期间利用丢弃和批归一化。
除第一层外,我们在整个网络中使用恒定的扩展率。在我们的实验中,我们发现5到10之间的扩展速率导致几乎相同的性能曲线,较小的网络以较小的扩展速率更好,而较大的网络在较大扩展速率时具有稍微更好的性能。
对于我们所有的主要实验,我们使用扩展因子66来应用于输入张量的大小。例如,对于瓶颈层采用64通道的输入张量并产生具有128×128通道的张量,中间扩展层则具有64*6=384个通道。
和[27]一样,我们通过使用输入图像分辨率和宽度倍数作为可调超参数来调整我们的架构以适应不同的性能点,可以根据所需的精度/性能权衡来调整。我们的主要网络(宽度乘数1,224×224)的计算成本为3亿次乘法,并使用了340万个参数。我们研究了性能权衡,输入分辨率从96到224,宽度乘数从0.35到1.4。网络计算成本范围从7次乘法增加到585M MAdds,而模型大小在1.7M个参数和6.9M个参数之间变化。
一个较小的实现差异,[27]是对于小于1的乘数,我们将宽度乘数应用于除最后一个卷积层以外的所有层。这可以提高更小模型的性能。
精读
网络架构
表2:MobileNet V2实现架构。
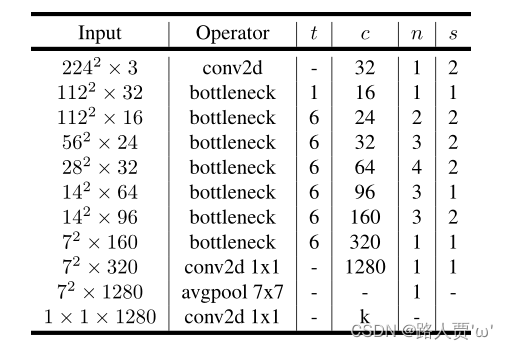
- t: 扩展因子(即升维倍数),一般与输入的通道数相乘;
- c: 输出通道数;
- n: 该层重复次数(比如重复4次,那么这4个相同操作的输出通道都是64);
- s: 步幅,注意,shortcut只在s=1时才使用;
- 卷积核大小均为3 * 3;
- 本文使用ReLU6作为非线性激活函数,训练过程使用dropout和batch normalization。
除了第一层,在整个网络中使用恒定的扩展因子t;
较小的网络用较小的扩展因子t表现更好;
较大的网络使用较大的扩展因子时表现更好。
Tradeoff hyper parameters—超参数的权衡
MobileNet v2同样使用MobileNet V1中的两个超参数,宽度系数α和分辨率系数ρ;
与MobileNet v1的不同是,对于小于1的乘数,本文将宽度系数α应用于除最后一个卷积层之外的所有层。这提高了较小模型的性能。
五、Implementation Notes—实现细节说明
5.1 Memory efficient inference—高效推理内存
翻译
倒置的残差颈层允许特定地内存有效的实现,这对于移动应用非常重要。使用TensorFlow[31]或Caffe[32]等标准高效的推断实现,构建了一个有向无环计算超图G,由表示操作的边和代表中间计算张量的节点组成。预定计算是为了最小化需要存储在内存中的张量总数。在最一般的情况下,它会搜索所有合理的计算顺序Σ(G),并选择最小化
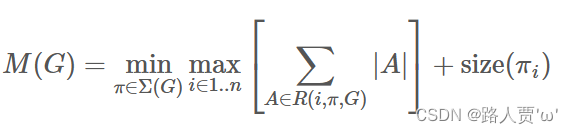
其中R(i, π, G)是连接到πi......πn任何节点的中间张量列表,|A|表示张量A的大小,size(i)是操作i期间内部存储所需的总内存量。
对于仅具有平凡并行结构(例如残差连接)的图,只有一个非平凡的可行计算顺序,因此可以简化计算图G推断所需的内存总量和界限:

或者重申,内存量只是在所有操作中组合输入和输出的最大总大小。在下文中我们将展示如果我们将瓶颈残差块视为单一操作(并将内部卷积视为一次性张量),则总内存量将由瓶颈张量的大小决定,而不是瓶颈的内部张量的大小(更大)。
精读
使用例如TensorFlow或Caffe 的推理的标准有效实现构建了有向非循环计算超图G,其包括表示操作的边和表示中间计算的张量的节点。
如果本文将瓶颈残差块视为单个操作(并将内卷积视为可任意处理的张量),则内存总量将由瓶颈张量的大小决定,而不是由瓶颈内部的张量(并且大得多)的大小决定。
Bottleneck Residual Block—残差瓶颈块
翻译
瓶颈残差块 图3b中所示的F(x)可以表示为三个运算符的组合F(x)=[A∘N∘B]x,其中A是线性变换A:Rs×s×k→Rs×s×n,N是一个非线性的每个通道的转换:N:Rs×s×n→Rs′×s′×n,B是输出域的线性转换:B:Rs′×s′×n→Rs′×s′×k′。
对于我们的网络N=ReLU6◦ dwise◦ ReLU6,但结果适用于任何的按通道转换。假设输入域的大小是|x|并且输出域的大小是|y|,那么计算F(X)所需的内存可以低至|s2k|+|s′2k′|+O(max(s2,s′2))。
该算法基于以下事实:内部张量I可以表示为t张量的连接,每个大小为n/t,则我们的函数可以表示为
F(x)=∑i=1t(Ai∘N∘Bi)(x)
通过累加和,我们只需要将一个大小为n/t的中间块始终保留在内存中。使用n=t,我们最终只需要保留中间表示的单个通道。使我们能够使用这一技巧的两个约束是(a)内部变换(包括非线性和深度)是每个通道的事实,以及(b)连续的非按通道运算符具有显著的输入输出大小比。对于大多数传统的神经网络,这种技巧不会产生显著的改善。
我们注意到,使用t路分割计算F(X)所需的乘加运算符的数目是独立于t的,但在现有实现中,我们发现由于增加的缓存未命中,用几个较小的矩阵乘法替换一个矩阵乘法会很损坏运行时的性能 。我们发现这种方法最有用,t是22和55之间的一个小常数。它显著降低了内存需求,但仍然可以利用深度学习框架提供的高度优化的矩阵乘法和卷积算子来获得的大部分效率。如果特殊的框架级优化可能导致进一步的运行时改进,这个方法还有待观察。
精读
残差块和逆残差的区别
对角线阴影层不使用非线性。本文用每个块的厚度来表示它的相对通道数。请注意经典残差如何连接具有大量通道的层,而反向残差如何连接瓶颈。
本文用到的原理
内部张量τ可以表示为t个张量的串联,每个张量的大小为n/t。函数可以表示为:

本文使用方法
本文通过累加总和,只需要在内存中一直保存一个大小为n/t的中间块。使用n = t,最终必须始终只保留中间表示的单个通道。
该方法的两个约束:
(a)内部变换(包括非线性和深度方向)是每通道的
(b)连续的非每通道操作符具有输入大小与输出的显著比率
六、Experiments—实验
文章从classification、detection、segmentation三个应用方面测试了该模型的效果。
6.1 ImageNet Classification—ImageNet数据集分类
翻译
训练设置我们使用TensorFlow[31]训练我们的模型。我们使用标准的RMSPropOptimizer,将衰减和动量都设置为0.9。我们在每层之后使用批标准化,并将标准权重衰减设置为0.00004。遵循MobileNetV1 [27]的设置,我们使用初始学习率为0.045,学习率的衰减比率为每个迭代周期衰减0.98。我们使用16个GPU异步,批大小为96。
结果我们将我们的网络与MobileNetV1,ShuffleNet和NASNet-A模型进行了比较。表4列出了一些选定模型的统计数据,完整的性能图如图5所示。
精读
训练参数设置
- 框架: TensorFlow
- 优化器: RMSPropOptimizer
- 衰变和动量: 0.9
- 标准重量衰减: 0.00004
- 初始学习率: 0.045
- 每个时期的学习率衰减率: 0.98
- 线程数量: 16个
- 批量大小: 96
将本文的网络与MobileNetV1、ShuffleNet和NASNet-A模型进行了比较
表4显示了一些选定模型的统计数据

图5显示了完整的性能图
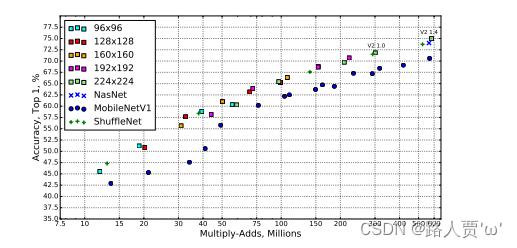
结论:MobileNetV2比MobileNetV1性能提高很多。和ShuffleNet和NASNet-A相比虽然参数量和计算量有增加但精读有提升
6.2 Object Detection—目标检测
翻译
我们评估和比较了MobileNetV2和MobileNetV1的性能,MobileNetV1使用COCO数据集[2]上Single Shot Detector(SSD)[34]的修改版本作为目标检测的特征提取器[33]。我们还将YOLOv2[35]和原始SSD(以VGG-16[6]为基础网络)作为基准进行比较。由于我们专注于移动/实时模型,因此我们不会比较Faster-RCNN[36]和RFCN[37]等其它架构的性能。
SSDLite 在本文中,我们将介绍常规SSD的移动友好型变种。我们在SSD预测层中用可分离卷积(深度方向后接1×11×1投影)替换所有常规卷积。这种设计符合MobileNets的整体设计,并且在计算上效率更高。我们称之为修改版本的SSDLite。与常规SSD相比,SSDLite显著降低了参数计数和计算成本。
对于MobileNetV1,我们按照[33]中的设置进行。对于MobileNetV2,SSDLite的第一层被附加到层15的扩展(输出步长为16)。SSDLite层的第二层和其余层连接在最后一层的顶部(输出步长为32)。此设置与MobileNetV1一致,因为所有层都附加到相同输出步长的特征图上。
MobileNet模型都经过了开源TensorFlow目标检测API的训练和评估[38]。 两个模型的输入分辨率为320×320。我们进行了基准测试并比较了mAP(COCO挑战度量标准),参数数量和Multiply-Adds数量。结果如表6所示。MobileNetV2 SSDLite不仅是最高效的模型,而且也是三者中最准确的模型。值得注意的是,MobileNetV2 SSDLite效率高20倍,模型要小10倍,但仍优于COCO数据集上的YOLOv2。
精读
训练参数设置
数据集:COCO数据集
SSDLite设置
在SSD预测层中,将所有规则卷积替换为可分离卷积(深度为1×1投影)
表5显示了SSD和SSDLite的对比结果
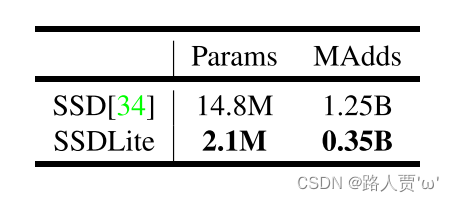
结论:与常规SSD相比,SSDLite显著减少了参数计数和计算成本。
6.3 Semantic Segmenta tion—语义分割
翻译
在本节中,我们使用MobileNetV1和MobileNetV2模型作为特征提取器与DeepLabv3[39]在移动语义分割任务上进行比较。DeepLabv3采用了空洞卷积[40,41,42],这是一种显式控制计算特征映射分辨率的强大工具,并构建了五个平行头部,包括(a)包含三个具有不同空洞率的3×3卷积的Atrous Spatial Pyramid Pooling模块(ASPP)[43],(b)1×1卷积头部,以及(c)图像级特征[44]。我们用输出步长来表示输入图像空间分辨率与最终输出分辨率的比值,该分辨率通过适当地应用空洞卷积来控制。对于语义分割,我们通常使用输出stride=16或88来获取更密集的特征映射。我们在PASCAL VOC 2012数据集[3]上进行了实验,使用[45]中的额外标注图像和评估指标mIOU。
为了构建移动模型,我们尝试了三种设计变体:(1)不同的特征提取器,(2)简化DeepLabv3头部以加快计算速度,以及(3)提高性能的不同推断策略。我们的结果总结在表7中。我们已经观察到:(a)包括多尺度输入和添加左右翻转图像的推断策略显著增加了MAdds,因此不适合于在设备上应用,(b)使用输出步长16比使用输出步长8更有效率,(c)MobileNetV1已经是一个强大的特征提取器,并且只需要比ResNet-101少约4.9-5.7倍的MAdd[8](例如,mIOU:78.56与82.70和MAdds:941.9B vs 4870.6B),(d)在MobileNetV2的倒数第二个特征映射的顶部构建DeepLabv3头部比在原始的最后一个特征映射上更高效,因为倒数第二个特征映射包含320个通道而不是1280个通道,这样我们就可以达到类似的性能,但是要比MobileNetV1的通道少2.5倍,(e)DeepLabv3头部的计算成本很高,移除ASPP模块会显著减少MAdd并且只会稍微降低性能。在表7末尾,我们鉴定了一个设备上的潜在候选应用(粗体),该应用可以达到75.32%mIOU并且只需要2.75B MAdds。
精读
将MobileNetv1,v2作为DeepLabv3中的特征提取网络,随后经过ASPP融合多尺度语义信息以及解码网络用于语义分割
训练参数设置
数据集:PASCAL VOC 2012
三种变体
(1)不同的特征提取器
(2)简化DeepLabv3头部以加快计算速度
(3)不同的推理策略以提高性能
三种变体结果总结
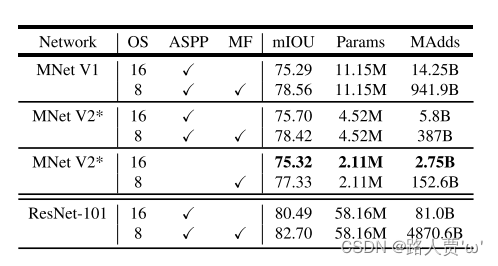
结论
(1)多尺度输入和添加左右翻转图像,增加了计算力,并不适用
(2)使用输出步幅=16比输出步幅=8更有效
(3)MobileNetV2只需要大约4.9− MAdds,比ResNet-101少5.7倍
(4)MobileNetV2的第二个最后一层功能图上构建DeepLabv3比在原始的最后一层功能图上更有效
(5)DeepLabv3磁头的计算成本很高,移除ASPP模块可以显著降低MADD,而性能只会略有下降。
6.4 Ablation study—消融研究
翻译
倒置残差连接。残差连接的重要性已被广泛研究[8,30,46]。本文报告的新结果是连接瓶颈的快捷连接性能优于连接扩展层的的快捷连接(请参见图6b以供比较)。
线性瓶颈的重要性。线性瓶颈模型的严格来说比非线性模型要弱一些,因为激活总是可以在线性状态下进行,并对偏差和缩放进行适当的修改。然而,我们在图6a中展示的实验表明,线性瓶颈改善了性能,为非线性破坏低维空间中的信息提供了支持。
精读
Inverted residual connections—反向残差连接
图7(b)比较了快捷连接瓶颈层和扩展层以及不使用残差连接

结论:快捷方式连接瓶颈的性能优于连接扩展层的快捷方式
Importance of linear bottlenecks—线性瓶颈的重要性
线性瓶颈模型比非线性模型更弱,因为激活总是在线性范围内运行,并对偏差和比例做出适当的改变。然而,如图6a所示的实验表明,线性瓶颈提高了性能,提供了非线性破坏低维空间信息的支持。
七、Conclusions and future work—总结和未来工作
翻译
我们描述了一个非常简单的网络架构,使我们能够构建一系列高效的移动模型。我们的基本构建单元具有多种特性,使其特别适用于移动应用。它允许非常有效的内存推断,并依赖利用所有神经框架中的标准操作。
对于ImageNet数据集,我们的架构改善了许多性能点的最新技术水平。对于目标检测任务,我们的网络在精度和模型复杂度方面都优于COCO数据集上的最新实时检测器。值得注意的是,我们的架构与SSDLite检测模块相比,计算量少20倍,参数比YOLOv2少10倍。
理论上:所提出的卷积块具有独特的属性,允许将网络表现力(由扩展层编码)与其容量(由瓶颈输入编码)分开。探索这个是未来研究的重要方向。
精读
① 提出一个更轻量的网络,准确率高。
② 作者提出的这种改进模型效率的思路非常实用,如深度可分离卷积。这些思路可以用于改进当前表现好但是计算复杂的模型。
🌟代码实现
import torch
from torch import nn
import torch.nn.functional as F
from torchsummary import summary
# ------------------------------------------------------#
# 这个函数的目的是确保Channel个数能被8整除。
# 很多嵌入式设备做优化时都采用这个准则
# ------------------------------------------------------#
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
# int(v + divisor / 2) // divisor * divisor:四舍五入到8
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# -------------------------------------------------------------#
# Conv+BN+ReLU经常会用到,组在一起
# 参数顺序:输入通道数,输出通道数...
# 最后的groups参数:groups=1时,普通卷积;
# groups=输入通道数in_planes时,DW卷积=深度可分离卷积
# pytorch官方继承自nn.sequential,想用它的预训练权重,就得听它的
# -------------------------------------------------------------#
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
# 不使用偏置bias,因为使用了BN层,此时偏置不起作用了
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU6(inplace=True)
)
# ------------------------------------------------------#
# InvertedResidual,先变胖后变瘦
# 参数顺序:输入通道数,输出通道数,步长,变胖倍数(扩展因子)
# ------------------------------------------------------#
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
# 所谓的隐藏维度,其实就是输入通道数*变胖倍数
hidden_dim = int(round(inp * expand_ratio))
# 只有同时满足两个条件时,才使用短连接
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
# 如果扩展因子等于1,就没有第一个1x1的卷积层
if expand_ratio != 1:
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1)) # pointwise
layers.extend([
# 3x3 depthwise conv,因为使用了groups=hidden_dim
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
# MobileNetV2是一个类,继承自nn.module这个父类
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
"""
MobileNet V2 main class
Args:
num_classes (int): Number of classes
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
inverted_residual_setting: Network structure
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
Set to 1 to turn off rounding
"""
super(MobileNetV2, self).__init__()
block = InvertedResidual
# 保证通道数是 8 的倍数,原因是:适配于硬件优化加速
input_channel = _make_divisible(32 * width_mult, round_nearest)
last_channel = _make_divisible(1280 * width_mult, round_nearest)
if inverted_residual_setting is None:
# t表示扩展因子(变胖倍数);c是通道数;n是block重复几次;
# s:stride步长,只针对第一层,其它s都等于1
inverted_residual_setting = [
# t, c, n, s
# 208,208,32 -> 208,208,16
[1, 16, 1, 1],
# 208,208,16 -> 104,104,24
[6, 24, 2, 2],
# 104,104,24 -> 52,52,32
[6, 32, 3, 2],
# 52,52,32 -> 26,26,64
[6, 64, 4, 2],
# 26,26,64 -> 26,26,96
[6, 96, 3, 1],
# 26,26,96 -> 13,13,160
[6, 160, 3, 2],
# 13,13,160 -> 13,13,320
[6, 320, 1, 1],
]
# only check the first element, assuming user knows t,c,n,s are required
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
# conv1 layer
# 416,416,3 -> 208,208,32
features = [ConvBNReLU(3, input_channel, stride=2)]
# building inverted residual blocks
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
# -----------------------------------#
# s为1或者2 只针对重复了n次的bottleneck 的第一个bottleneck,
# 重复n次的剩下几个bottleneck中s均为1。
# -----------------------------------#
stride = s if i == 0 else 1
# 这个block就是上面那个InvertedResidual函数
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
# 这一层的输出通道数作为下一层的输入通道数
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, kernel_size=1))
# *features表示位置信息,将特征层利用nn.Sequential打包成一个整体
self.features = nn.Sequential(*features)
# building classifier
# 自适应平均池化下采样层,输出矩阵高和宽均为1
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes),
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # 正太分布
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1) # 展平处理
x = self.classifier(x)
return x
def mobilenet_v2(num_classes: int = 1000):
model = MobileNetV2(num_classes=num_classes)
return model
if __name__ == '__main__':
net = MobileNetV2().cuda()
summary(net, (3, 224, 224))网络结构打印如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
ReLU6-3 [-1, 32, 112, 112] 0
Conv2d-4 [-1, 32, 112, 112] 288
BatchNorm2d-5 [-1, 32, 112, 112] 64
ReLU6-6 [-1, 32, 112, 112] 0
Conv2d-7 [-1, 16, 112, 112] 512
BatchNorm2d-8 [-1, 16, 112, 112] 32
InvertedResidual-9 [-1, 16, 112, 112] 0
Conv2d-10 [-1, 96, 112, 112] 1,536
BatchNorm2d-11 [-1, 96, 112, 112] 192
ReLU6-12 [-1, 96, 112, 112] 0
Conv2d-13 [-1, 96, 56, 56] 864
BatchNorm2d-14 [-1, 96, 56, 56] 192
ReLU6-15 [-1, 96, 56, 56] 0
Conv2d-16 [-1, 24, 56, 56] 2,304
BatchNorm2d-17 [-1, 24, 56, 56] 48
InvertedResidual-18 [-1, 24, 56, 56] 0
Conv2d-19 [-1, 144, 56, 56] 3,456
BatchNorm2d-20 [-1, 144, 56, 56] 288
ReLU6-21 [-1, 144, 56, 56] 0
Conv2d-22 [-1, 144, 56, 56] 1,296
BatchNorm2d-23 [-1, 144, 56, 56] 288
ReLU6-24 [-1, 144, 56, 56] 0
Conv2d-25 [-1, 24, 56, 56] 3,456
BatchNorm2d-26 [-1, 24, 56, 56] 48
InvertedResidual-27 [-1, 24, 56, 56] 0
Conv2d-28 [-1, 144, 56, 56] 3,456
BatchNorm2d-29 [-1, 144, 56, 56] 288
ReLU6-30 [-1, 144, 56, 56] 0
Conv2d-31 [-1, 144, 28, 28] 1,296
BatchNorm2d-32 [-1, 144, 28, 28] 288
ReLU6-33 [-1, 144, 28, 28] 0
Conv2d-34 [-1, 32, 28, 28] 4,608
BatchNorm2d-35 [-1, 32, 28, 28] 64
InvertedResidual-36 [-1, 32, 28, 28] 0
Conv2d-37 [-1, 192, 28, 28] 6,144
BatchNorm2d-38 [-1, 192, 28, 28] 384
ReLU6-39 [-1, 192, 28, 28] 0
Conv2d-40 [-1, 192, 28, 28] 1,728
BatchNorm2d-41 [-1, 192, 28, 28] 384
ReLU6-42 [-1, 192, 28, 28] 0
Conv2d-43 [-1, 32, 28, 28] 6,144
BatchNorm2d-44 [-1, 32, 28, 28] 64
InvertedResidual-45 [-1, 32, 28, 28] 0
Conv2d-46 [-1, 192, 28, 28] 6,144
BatchNorm2d-47 [-1, 192, 28, 28] 384
ReLU6-48 [-1, 192, 28, 28] 0
Conv2d-49 [-1, 192, 28, 28] 1,728
BatchNorm2d-50 [-1, 192, 28, 28] 384
ReLU6-51 [-1, 192, 28, 28] 0
Conv2d-52 [-1, 32, 28, 28] 6,144
BatchNorm2d-53 [-1, 32, 28, 28] 64
InvertedResidual-54 [-1, 32, 28, 28] 0
Conv2d-55 [-1, 192, 28, 28] 6,144
BatchNorm2d-56 [-1, 192, 28, 28] 384
ReLU6-57 [-1, 192, 28, 28] 0
Conv2d-58 [-1, 192, 14, 14] 1,728
BatchNorm2d-59 [-1, 192, 14, 14] 384
ReLU6-60 [-1, 192, 14, 14] 0
Conv2d-61 [-1, 64, 14, 14] 12,288
BatchNorm2d-62 [-1, 64, 14, 14] 128
InvertedResidual-63 [-1, 64, 14, 14] 0
Conv2d-64 [-1, 384, 14, 14] 24,576
BatchNorm2d-65 [-1, 384, 14, 14] 768
ReLU6-66 [-1, 384, 14, 14] 0
Conv2d-67 [-1, 384, 14, 14] 3,456
BatchNorm2d-68 [-1, 384, 14, 14] 768
ReLU6-69 [-1, 384, 14, 14] 0
Conv2d-70 [-1, 64, 14, 14] 24,576
BatchNorm2d-71 [-1, 64, 14, 14] 128
InvertedResidual-72 [-1, 64, 14, 14] 0
Conv2d-73 [-1, 384, 14, 14] 24,576
BatchNorm2d-74 [-1, 384, 14, 14] 768
ReLU6-75 [-1, 384, 14, 14] 0
Conv2d-76 [-1, 384, 14, 14] 3,456
BatchNorm2d-77 [-1, 384, 14, 14] 768
ReLU6-78 [-1, 384, 14, 14] 0
Conv2d-79 [-1, 64, 14, 14] 24,576
BatchNorm2d-80 [-1, 64, 14, 14] 128
InvertedResidual-81 [-1, 64, 14, 14] 0
Conv2d-82 [-1, 384, 14, 14] 24,576
BatchNorm2d-83 [-1, 384, 14, 14] 768
ReLU6-84 [-1, 384, 14, 14] 0
Conv2d-85 [-1, 384, 14, 14] 3,456
BatchNorm2d-86 [-1, 384, 14, 14] 768
ReLU6-87 [-1, 384, 14, 14] 0
Conv2d-88 [-1, 64, 14, 14] 24,576
BatchNorm2d-89 [-1, 64, 14, 14] 128
InvertedResidual-90 [-1, 64, 14, 14] 0
Conv2d-91 [-1, 384, 14, 14] 24,576
BatchNorm2d-92 [-1, 384, 14, 14] 768
ReLU6-93 [-1, 384, 14, 14] 0
Conv2d-94 [-1, 384, 14, 14] 3,456
BatchNorm2d-95 [-1, 384, 14, 14] 768
ReLU6-96 [-1, 384, 14, 14] 0
Conv2d-97 [-1, 96, 14, 14] 36,864
BatchNorm2d-98 [-1, 96, 14, 14] 192
InvertedResidual-99 [-1, 96, 14, 14] 0
Conv2d-100 [-1, 576, 14, 14] 55,296
BatchNorm2d-101 [-1, 576, 14, 14] 1,152
ReLU6-102 [-1, 576, 14, 14] 0
Conv2d-103 [-1, 576, 14, 14] 5,184
BatchNorm2d-104 [-1, 576, 14, 14] 1,152
ReLU6-105 [-1, 576, 14, 14] 0
Conv2d-106 [-1, 96, 14, 14] 55,296
BatchNorm2d-107 [-1, 96, 14, 14] 192
InvertedResidual-108 [-1, 96, 14, 14] 0
Conv2d-109 [-1, 576, 14, 14] 55,296
BatchNorm2d-110 [-1, 576, 14, 14] 1,152
ReLU6-111 [-1, 576, 14, 14] 0
Conv2d-112 [-1, 576, 14, 14] 5,184
BatchNorm2d-113 [-1, 576, 14, 14] 1,152
ReLU6-114 [-1, 576, 14, 14] 0
Conv2d-115 [-1, 96, 14, 14] 55,296
BatchNorm2d-116 [-1, 96, 14, 14] 192
InvertedResidual-117 [-1, 96, 14, 14] 0
Conv2d-118 [-1, 576, 14, 14] 55,296
BatchNorm2d-119 [-1, 576, 14, 14] 1,152
ReLU6-120 [-1, 576, 14, 14] 0
Conv2d-121 [-1, 576, 7, 7] 5,184
BatchNorm2d-122 [-1, 576, 7, 7] 1,152
ReLU6-123 [-1, 576, 7, 7] 0
Conv2d-124 [-1, 160, 7, 7] 92,160
BatchNorm2d-125 [-1, 160, 7, 7] 320
InvertedResidual-126 [-1, 160, 7, 7] 0
Conv2d-127 [-1, 960, 7, 7] 153,600
BatchNorm2d-128 [-1, 960, 7, 7] 1,920
ReLU6-129 [-1, 960, 7, 7] 0
Conv2d-130 [-1, 960, 7, 7] 8,640
BatchNorm2d-131 [-1, 960, 7, 7] 1,920
ReLU6-132 [-1, 960, 7, 7] 0
Conv2d-133 [-1, 160, 7, 7] 153,600
BatchNorm2d-134 [-1, 160, 7, 7] 320
InvertedResidual-135 [-1, 160, 7, 7] 0
Conv2d-136 [-1, 960, 7, 7] 153,600
BatchNorm2d-137 [-1, 960, 7, 7] 1,920
ReLU6-138 [-1, 960, 7, 7] 0
Conv2d-139 [-1, 960, 7, 7] 8,640
BatchNorm2d-140 [-1, 960, 7, 7] 1,920
ReLU6-141 [-1, 960, 7, 7] 0
Conv2d-142 [-1, 160, 7, 7] 153,600
BatchNorm2d-143 [-1, 160, 7, 7] 320
InvertedResidual-144 [-1, 160, 7, 7] 0
Conv2d-145 [-1, 960, 7, 7] 153,600
BatchNorm2d-146 [-1, 960, 7, 7] 1,920
ReLU6-147 [-1, 960, 7, 7] 0
Conv2d-148 [-1, 960, 7, 7] 8,640
BatchNorm2d-149 [-1, 960, 7, 7] 1,920
ReLU6-150 [-1, 960, 7, 7] 0
Conv2d-151 [-1, 320, 7, 7] 307,200
BatchNorm2d-152 [-1, 320, 7, 7] 640
InvertedResidual-153 [-1, 320, 7, 7] 0
Conv2d-154 [-1, 1280, 7, 7] 409,600
BatchNorm2d-155 [-1, 1280, 7, 7] 2,560
ReLU6-156 [-1, 1280, 7, 7] 0
AdaptiveAvgPool2d-157 [-1, 1280, 1, 1] 0
Dropout-158 [-1, 1280] 0
Linear-159 [-1, 1000] 1,281,000
================================================================
Total params: 3,504,872
Trainable params: 3,504,872
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 152.88
Params size (MB): 13.37
Estimated Total Size (MB): 166.82
----------------------------------------------------------------
Process finished with exit code 0





![[深度好文]10张图带你轻松理解关系型数据库系统的工作原理](https://img-blog.csdnimg.cn/img_convert/4653f1d568937685ea5f45c290949cac.jpeg)