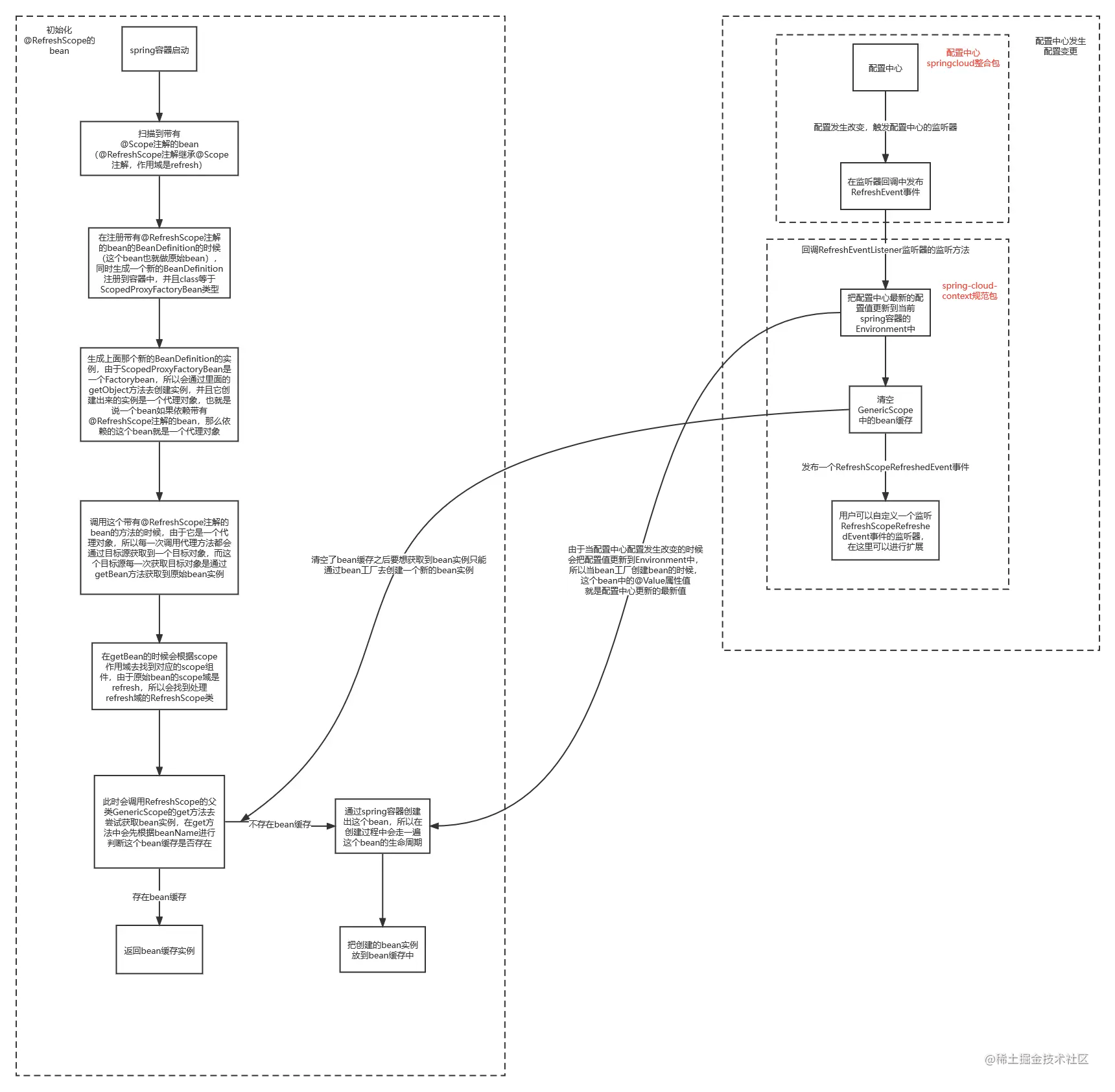
文件系统的意义
之前说的都是在进程在物理内存保存的数据,内存就像一个纸箱子,仅仅是一个暂存数据的地方,而且空间有限。如果我们想要进程结束之后,数据依然能够保存下来,就不能只保存在内存里,而是应该保存在外部存储中。
我们最常用的外部存储就是硬盘,数据是以文件的形式保存在硬盘上的。为了管理这些文件,我们在规划文件系统的时候,需要考虑如下几点。
文件系统的几个要点:
1、严格的组织形式。以单位进行存储,比如图书馆的书架分成很多小格子;
2、要有索引,实现快速查找;
3、要有缓存,实现热点文件的快速应用;
4、要有文件夹的形式,方便查询和管理。相当于给书分类;
相关命令:
1、格式化
所谓格式化,就是将一块盘使用命令组织成一定格式的文件系统的过程。比如硬盘或者U盘,要先格式化才能放放文件。
使用 Windows 的时候,咱们常格式化的格式为NTFS(New Technology File System)。在 Linux 下面,常用的是 ext3 或者 ext4。
当一个 Linux 系统插入了一块没有格式化的硬盘的时候,我们可以通过命令fdisk -l,查看格式化和没有格式化的分区。
我们可以通过命令mkfs.ext3或者mkfs.ext4进行格式化。
mkfs.ext4 /dev/vdc
执行完这个命令后,vdc会建立一个分区,格式化为ext4文件系统的格式。
格式化后的硬盘,需要挂在某个目录下面,才能作为普通的文件系统进行访问。
mount /dev/vdc1 /根目录/用户A目录/目录1
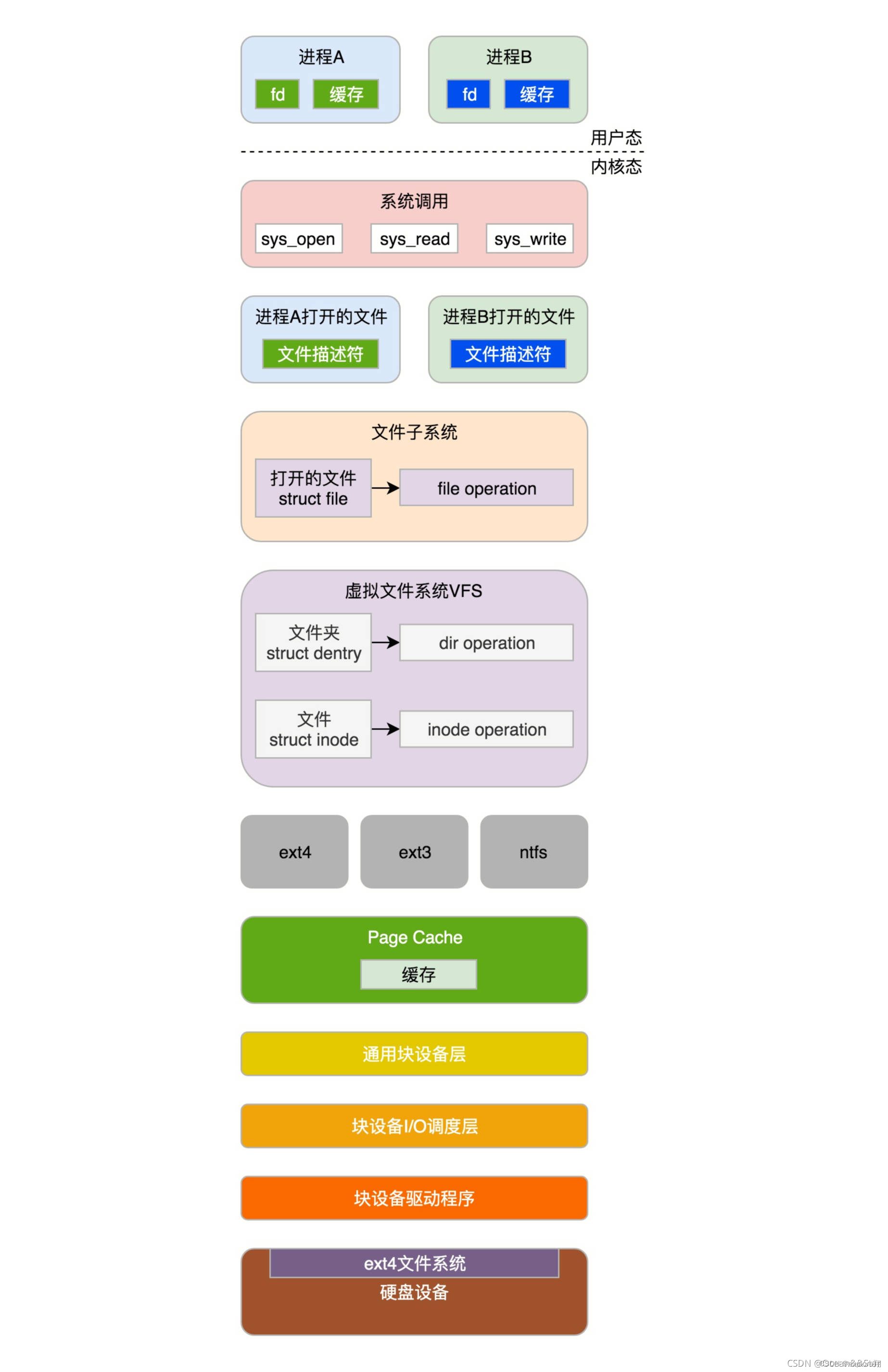
文件系统相关系统调用(open,rw,lseek,close)
在内核中,要有一整套的数据结构来表示打开的文件。在用户态,每个打开的文件都有一个文件描述符,可以通过个这种文件相关的系统调用,操作这个文件描述符
当使用系统调用open打开一个文件时,操作系统会创建一些数据结构来表示这个被打开的文件。为了能够找到这些数据结构,在进程中,我们会为这个打开的文件分配一个文件描述符fd。
硬盘文件系统
硬盘分为盘片,磁道,扇区,一个扇区512字节。硬盘存储单元是块,一块的大小是扇区大小的整数倍,默认是4K。
inode索引
inode就是对应的索引。主要包含两部分信息,
一个是元数据(比如文件权限、属主,属组,时间,大小),ls -l列出来就是这些信息;
“某个文件分成几块、每一块在哪里”,这些在 inode的 i_block 里面。
在ext2-3里面, i_block有15项。其中前 12 项直接保存了块的位置,也就是说,我们可以通过 i_block[0-11],直接得到保存文件内容的块,后面放的是间接块的位置,这就导致了,对于大文件来讲,我们要多次读取硬盘来能找到相应的块,这样访问速度就比较慢。
为了解决这个问题,ext4做了一定的改变。它引入了一个新的概念,叫做Extents比如,一个文件大小为128M,如果使用4K大小的块进行存储,需要32K个块。如果按照ext2或者ext3那样散着放,数量太大了。但是Extents可以用于存放连续的块,也就是说,我们可以把128M放在一个Extents里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了
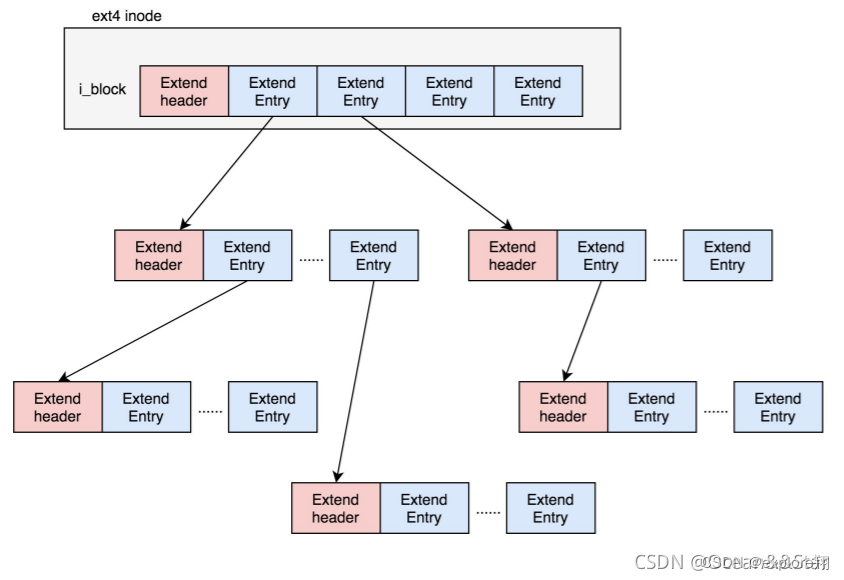
树的形式,每个节点都有一个头,ext4_extent_header 可以用来描述某个节点。包括节点的项数和类型;(节点大小12Btyes)
类型主要有叶子结点这一项会直接指向硬盘上的连续块的地址,我们称为数据节点 ext4_extent;
分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点 ext4_extent_idx。
inode位图和块位图
如果我要保存一个数据块,或者要保存一个inodee,我应该放在硬盘上的哪个位置呢?难道需要将所有的inode列表和块列表扫描一遍,找个空的地方随便放吗?
当然,这样效率太低了。所以在文件系统里面,我们专门弄了一个块来保存 inode 的位图。在这 4k 里面,每一位对应一个 inode。如果是 1,表示这个 inode 已经被用了;如果是 0,则表示没被用。同样,我们也弄了一个块保存 block 的位图。位图法大大减少了空间使用。比如redis的bitset也是位图结构,适合用于二值的类型。
至此综合一下:open函数调用链。
open 是一个系统调用,在内核里面会调用 sys_open
先要根据路径找到文件夹。如果发现文件夹下面没有这个文件,同时又设置了 O_CREAT,就说明我们要在这个文件夹下面创建一个文件,那我们就需要一个新的 inode。调用 dir_inode,也就是文件夹的 inode 的 create 函数;这里面的一个重要逻辑是,从文件系统里面读取inode位图,然后找到下一个为0的inode,就是空闲的inode。
文件系统的格式
光有块和索引还不够。还得有文件夹的形式。为什么呢?
想想,如果一个块4K的位图,最多是410248个数据块,然后每个数据块是4K,再乘以410248.一共可以表示的大小只有128MB,现在很多文件都比这个大。
所以,我们先把这个结构称为一个块组。有 N 多的块组,就能够表示 N 大的文件。这样一个个块组,就基本构成了我们整个文件系统的结构。因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为块组描述符表。以及还有一个超级块记录所有的全局信息。
对于整个文件系统,别忘了咱们讲系统启动的时候说的。如果是一个启动盘,我们需要预留一块区域作为引导区,所以第一个块组的前面要留 1K,用于启动引导区。
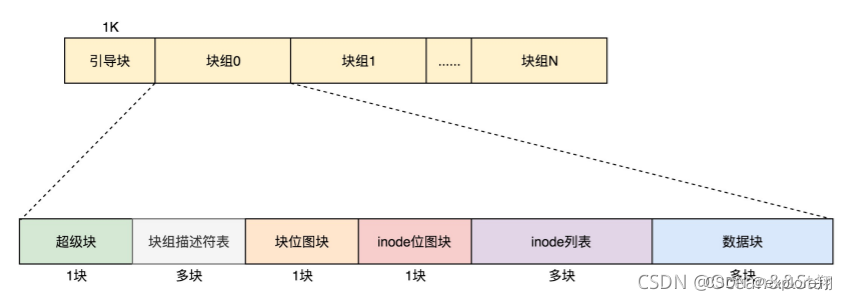
注意,**超级块和块组描述符表都是全局信息,而且这些数据很重要。**如果这些数据丢失了,整个文件系统都打不开了,这比一个文件的一个块损坏更严重。所以,这两部分我们都需要备份,但是采取不同的策略。
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。
对于超级块来讲,由于超级块不是很大,所以就算我们备份多了也没有太多问题。但是,对于块组描述符表来讲,如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大 128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M * 块组的总数目是整个文件系统的大小,就被限制住了。我们的改进的思路就是引入Meta Block Groups 特性。
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含 64 个块组,这样一个元块组中的块组描述符表最多 64 项。我们假设一共有 256 个块组,原来是一个整的块组描述符表,里面有 256 项,要备份就全备份,现在分成 4 个元块组,每个元块组里面的块组描述符表就只有 64 项了,这就小多了,而且四个元块组自己备份自己的。
目录的存储格式
其实目录本身也是个文件,也有 inode。inode 里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。在目录文件的块中,最简单的保存格式是列表,就是一项一项地将 ext4_dir_entry_2 列在哪里。
每一项都会保存这个目录的下一级的文件的文件名和对应的 inode,通过这个 inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和 inode。
按照列表一个个去找,太慢了,于是我们就添加了索引的模式。当然,首先出现的还是差不多的,第一项是“.”,表示当前目录;第二项是“…”,表示上一级目录,这两个不变。接下来就开始发生改变了。是一个 dx_root_info 的结构,其中最重要的成员变量是 indirect_levels,表示间接索引的层数。如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。
软链接和硬链接的存储格式
ln [参数] [源文件或目录][目标文件或目录]
ln -s 创建的是软链接,不带 -s 创建的是硬链接
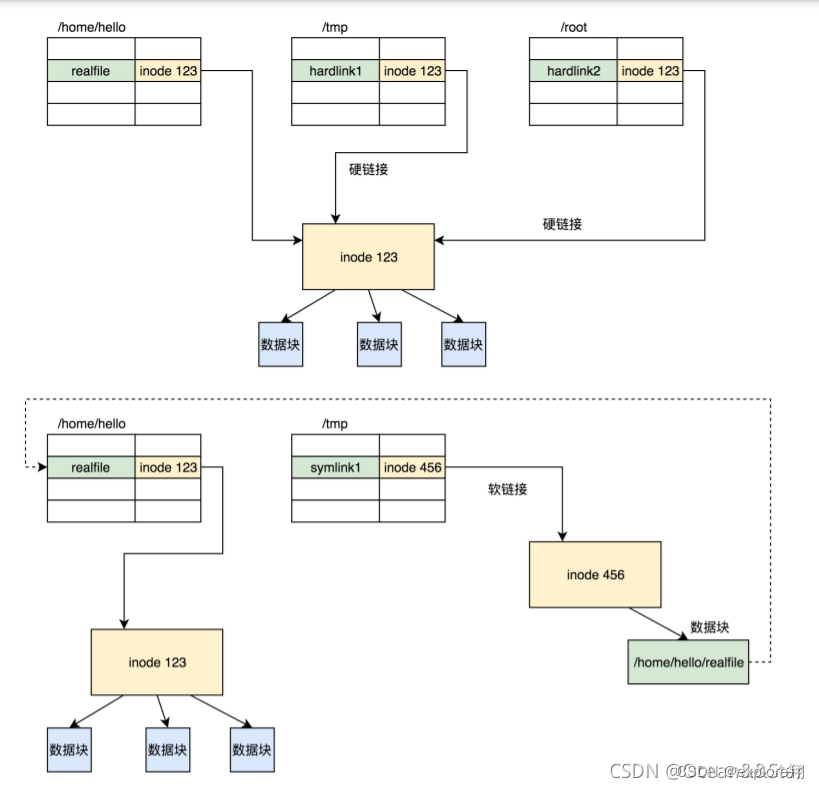
如图所示,硬链接与原始文件共用一个 inode 的,但是 inode 是不跨文件系统的,每个文件系统都有自己的 inode 列表,因而硬链接是没有办法跨文件系统的。
目录也不能创建硬链接,因为容易造成目录循环。
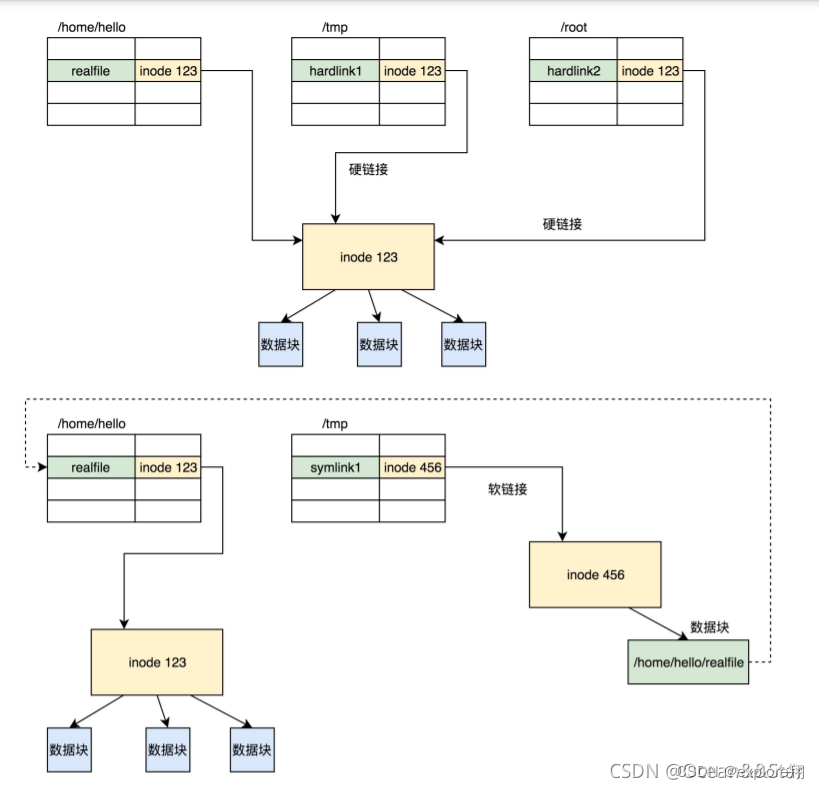
软链接不同,软链接相当于重新创建了一个文件,快捷方式相当于。这个文件也有独立的 inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
**
虚拟文件系统
**
由于linux可以支持多达数十种不同的文件系统,它们的实现各不相同,因此linux内核向用户空间提供了虚拟文件系统这个统一的接口,来对文件系统进行操作。它提供了常见的文件系统对象模型,比如inode、directory entry、mount等,以及操作这些对象的方法,比如inode operations、directory operations、file operations等。
open函数过程,再一次说一下:
要打开一个文件,首先要通过get_unused_fd_flags得到一个没有用的文件描述符。在每一个进程的task_struct中,有一个指针files,类型是files_struct。files_struct 里面最重要的是一个文件描述符列表。对于任何一个进程,默认情况下,文件描述符0表示stdin标准输入,文件描述符1表示stdout标准输出,文件描述符2表示stderr标准错误输出。另外,再打开的文件,都会从这个列表中找一个空闲位置分配给它。do_sys_open中调用do_filp_open,就是创建这个struct file结构,然后fd_install(fd, f);是将文件描述符和这个结构关联起来。
准备开始节点路径查找。如果缓存中没有找到,就需要真的到文件系统里面去找了,对于ext4来说,调用的是ext4_lookup,会到物理文件系统中找inode。
linux为了提高目录项对象的处理效率,设计与实现了目录项高速缓存dentry cache,简称dcache。它主要由两个数据结构组成:
哈希表dentry_hashtable:dcache中的所有dentry对象都通过d_hash执行链到相应的dentry哈希链表中
未使用的dentry对象链表s_dentry_lru:dentry对象通过其d_lru指针链入LRU链表中。LRU 的意思是最近最少使用。只要有它,就说明长时间不使用,就应该释放了。
do_last获取文件对应的inode对象,并且初始化file对象。vfs_open里面最终要做的事情是,调用f_op->open,也就是调用ext4_file_open。另外一件重要的事情是将打开文件的所有信息,填写到struct file这个结构里面。
总结一下:解封装-陷入内核系统调用-分配文件描述符和文件结构绑定-路径查找(目录项缓存)-找到后打开并填充文件信息-返回到用户态。(陷入内核需要把CPU上下文寄存到内核栈的ptg结构里,内核一系列调用都是内核栈进行的,返回时恢复)
总结:虚拟文件系统就是为不同的文件系统提高统一的接口,包括文件操作,inode操作,目录查找操作。
文件缓存
文件系统的读写,其实就是调用系统函数read和write。对于 read 来讲,里面调用 vfs_read->__vfs_read。对于 write 来讲,里面调用 vfs_write->__vfs_write。在 ext4 层调用的是 ext4_file_read_iter 和 ext4_file_write_iter。
缓存其实就是内存中的一块空间,因为内存比硬盘快得多,linux为了改进性能,有时候会选择不直接操作硬盘,而是将读写都在内存中,然后批量读取或者写入硬盘。一旦能够命中内存,读写效率就会大幅度提高
因此,根据是否使用内存作为缓存,我们可以把文件的IO操作分为两种类型。
第一种类型是缓存IO。
大部分文件系统的默认IO操作都是缓存IO。
对于读操作来讲,操作系统会先检查内核中的缓冲区有没有需要的数据。如果已经缓存了,那就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中
对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说,写操作就已经完成。至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令
第二种类型是直接IO。
如果在读的逻辑generic_file_read_iter 里面,发现设置了IOCB_DIRECT,则会调用address_space的direct_IO的函数,将数据直接读取硬盘。跨过了缓存层,直接到了文件系统的设备驱动层。由于文件系统是块文件,所以这个调用的是blockdev相关的函数。
我们主要学习缓存IO如何读写的。
缓存读:(预读+拷贝)
1generic_file_buffered_read函数。先找出page cache里面是否有缓存页。如果没有找到,不但读取这一页,还要进行预读;这需要在page_cache_sync_readahead函数中实现。预读完了以后,再试一把查找缓存页,应该能找到了;
如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用page_cache_async_readahead 发起一个异步预读。
最后,copy_page_to_iter 会将内容从内核缓存页拷贝到用户内存空间
缓存写:麻烦一点
1、 generic_perform_write 这个函数里面,是一个while循环。我们需要找出这次写入影响的所有的页,然后依次写入。 对于每一个循环,主要做四件事情:
第一步,对于ext4来讲,调用的是ext4_write_begin。(主要做一些日志相关的工作,是为了防止突然断电的时候数据丢失,order模式。这种模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式)
第二步,调用iov_iter_copy_from_user_atomic。先将分配好的页面调用kmap_atomic 映射到内核里面的一个虚拟地址,然后将用户态的数据拷贝到内核态的页面的虚拟地址中,调用kunmap_atomic 把内核里面的元素删除。(前面说过内存映射到文件,也需要kmap_atomic 建立内存到文件的关联)
第三步 调用 ext4_write_end 完成写入。可以看出,其实所谓的完成写入,并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页。
但是这里会有一个问题,数据很危险,一旦宕机就没有了,所以需要一种机制,将写入的页面真正写到硬盘中,我们称为回写(Write Back)。
第四步,调用 balance_dirty_pages_ratelimited,是回写脏页的一个很好的时机。如果脏页超过一定数目就回写。
另外还有几种场景也会触发回写:用户主动调用 sync;当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;脏页已经更新了较长时间,时间上超过了timer,需要及时回写。
总结:写缓存几个步骤:第一先做一些日志相关的工作;第二 kmap_atomic 映射到内核里面的一个虚拟地址。把用户数据写到内核的页面;第三完成写入标记脏页,第四回写落盘。
(注意文件缓存是在内核空间的。读缓存需要把数据从内核拷贝到用户空间,写缓存是把用户数据写到内核的page cache中)