大家好,我是带我去滑雪!
本期将尝试使用CIFAR-10 数据集搭建卷积神经网络,该数据集由 10 个类别的 60000 张 32x32 彩色图像组成,每个类别有 6000 张图像。

下面开始全过程搭建CNN识别彩色图片:
目录
(1)导入Keras内置Cifar-10数据集和相关模块
(2)显示训练集对应测试集中的前9张图片
(3)数据预处理:特征数据进行归一化、标签数据进行独立热编码
(4)定义模型
(5)编译模型、训练模型
(6)绘制训练集与验证集损失分数、准确度的趋势图
(7)评估模型与储存模型
(7)模型预测
(1)导入Keras内置Cifar-10数据集和相关模块
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dropout
from tensorflow.keras.utils import to_categorical(X_train, Y_train), (X_test, Y_test) = cifar10.load_data()
print("X_train.shape: ", X_train.shape)
print("Y_train.shape: ", Y_train.shape)
print("X_test.shape: ", X_test.shape)
print("Y_test.shape: ", Y_test.shape)输出结果:
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170498071/170498071 [==============================] - 2113s 12us/step X_train.shape: (50000, 32, 32, 3) Y_train.shape: (50000, 1) X_test.shape: (10000, 32, 32, 3) Y_test.shape: (10000, 1)
训练集中有50000张,测试集中有10000张。标签值对应的图片类别如下:
| 标签值 | 图片类别 | 标签值 | 图片类别 |
| 0 | 飞机 | 5 | 狗 |
| 1 | 汽车 | 6 | 青蛙 |
| 2 | 鸟 | 7 | 马 |
| 3 | 猫 | 8 | 船 |
| 4 | 鹿 | 9 | 卡车 |
(2)显示训练集对应测试集中的前9张图片
sub_plot= 330
for i in range(0, 9):
ax = plt.subplot(sub_plot+i+1)
ax.imshow(X_train[i], cmap="binary")
ax.set_title("Label: " + str(Y_train[i]))
ax.axis("off")
plt.subplots_adjust(hspace = .5)
plt.savefig("E:/工作/硕士/博客/博客34-深度学习之全过程搭建卷积神经网络(CNN)/squares1.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

(3)数据预处理:特征数据进行归一化、标签数据进行独立热编码
这里的特征数据选择归一化,而不是标准化的原因是数据是固定范围, 所以执行归一化, 从 0~255 转化为 0~1。
X_train = X_train.astype("float32") / 255
X_test = X_test.astype("float32") / 255
# One-hot编码
Y_train = to_categorical(Y_train)
Y_test = to_categorical(Y_test)
(4)定义模型
模型设定两个卷积层和池化层,三个Dropout层、一个平坦化层,两个全连接层。在卷积层中激活函数使用ReLU函数,第一和第二个Dropout层比例为0.25,第三个Dropout层比例为0.5,第一个全连接层激活函数使用ReLU函数,第二个全连接层激活函数使用softmax函数。kernel_size表示卷积核大小,padding表示补零为相同尺寸(填充),strides表示填充步幅。最大池化层里面的pool_size=(2, 2)表示缩小比例。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), padding="same",input_shape=X_train.shape[1:], activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=(3, 3), padding="same",activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(10, activation="softmax"))
model.summary() #显示模型信息输出结果:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 32) 896 max_pooling2d (MaxPooling2D (None, 16, 16, 32) 0 ) dropout (Dropout) (None, 16, 16, 32) 0 conv2d_1 (Conv2D) (None, 16, 16, 64) 18496 max_pooling2d_1 (MaxPooling (None, 8, 8, 64) 0 2D) dropout_1 (Dropout) (None, 8, 8, 64) 0 flatten (Flatten) (None, 4096) 0 dense (Dense) (None, 512) 2097664 dropout_2 (Dropout) (None, 512) 0 dense_1 (Dense) (None, 10) 5130 ================================================================= Total params: 2,122,186 Trainable params: 2,122,186 Non-trainable params: 0 _________________________________________________________________
上面各神经层的参数计算:
第一个conv2d卷积层的输入层输出通道数为3,乘以滤波器的大小(3,3),再乘以滤波器数量32,再加上滤波器数的偏移量32,总数为3*(3*3)*32+32=896。
第二个卷积层是64个滤波器,滤波器的大小(3,3),乘以上一层的通道数32(即特征数),加上64个偏移量,总数为32*(3*3)*64+64=18496。
第一个全连接层,有512个神经元,而平坦层的输入为4096,偏移量为512个,故该层总参数个数为512*4096+512=2097664。
最后输出层的全连接层有10个神经元,该层参数总量为512*10+10=5130。
总参数共计896+18496+2097664+5130=2122186个。
(5)编译模型、训练模型
在编译模型中,损失函数为categorical_crossentropy,优化器为adam,评估标准为准确度(accuracy)。在训练模型中,验证集为训练集的20%,训练周期为30次,批次尺寸为128。
# 编译模型
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# 训练模型
history = model.fit(X_train, Y_train, validation_split=0.2, epochs=30, batch_size=128, verbose=2)输出结果:
313/313 - 29s - loss: 0.4474 - accuracy: 0.8385 - val_loss: 0.7614 - val_accuracy: 0.7583 - 29s/epoch - 92ms/step Epoch 23/30 313/313 - 29s - loss: 0.4372 - accuracy: 0.8422 - val_loss: 0.7723 - val_accuracy: 0.7557 - 29s/epoch - 93ms/step Epoch 24/30 313/313 - 29s - loss: 0.4292 - accuracy: 0.8477 - val_loss: 0.7678 - val_accuracy: 0.7592 - 29s/epoch - 94ms/step Epoch 25/30 313/313 - 30s - loss: 0.4226 - accuracy: 0.8493 - val_loss: 0.7862 - val_accuracy: 0.7569 - 30s/epoch - 97ms/step Epoch 26/30 313/313 - 30s - loss: 0.4174 - accuracy: 0.8492 - val_loss: 0.7757 - val_accuracy: 0.7571 - 30s/epoch - 94ms/step Epoch 27/30 313/313 - 29s - loss: 0.4041 - accuracy: 0.8559 - val_loss: 0.7743 - val_accuracy: 0.7591 - 29s/epoch - 94ms/step Epoch 28/30 313/313 - 31s - loss: 0.3896 - accuracy: 0.8595 - val_loss: 0.8050 - val_accuracy: 0.7561 - 31s/epoch - 98ms/step Epoch 29/30 313/313 - 28s - loss: 0.3856 - accuracy: 0.8602 - val_loss: 0.7823 - val_accuracy: 0.7581 - 28s/epoch - 91ms/step Epoch 30/30 313/313 - 28s - loss: 0.3784 - accuracy: 0.8633 - val_loss: 0.8150 - val_accuracy: 0.7506 - 28s/epoch - 91ms/step
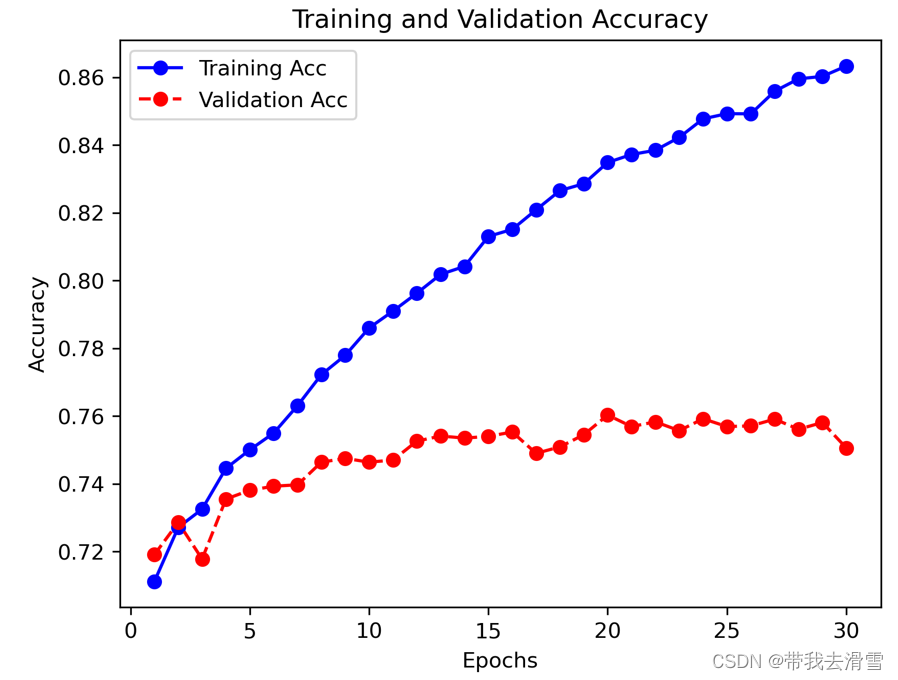
(6)绘制训练集与验证集损失分数、准确度的趋势图
# 显示训练和验证损失分数趋势图
loss = history.history["loss"]
epochs = range(1, len(loss)+1)
val_loss = history.history["val_loss"]
plt.plot(epochs, loss, "bo-", label="Training Loss")
plt.plot(epochs, val_loss, "ro--", label="Validation Loss")
plt.title("Training and Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.savefig("E:/工作/硕士/博客/博客34-深度学习之全过程搭建卷积神经网络(CNN)/squares2.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
# 显示训练和验证准确度趋势图
acc = history.history["accuracy"]
epochs = range(1, len(acc)+1)
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "bo-", label="Training Acc")
plt.plot(epochs, val_acc, "ro--", label="Validation Acc")
plt.title("Training and Validation Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.savefig("E:/工作/硕士/博客/博客34-深度学习之全过程搭建卷积神经网络(CNN)/squares3.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

(7)评估模型与储存模型
print("\n在训练集和测试集上,模型评估中 ...")
loss, accuracy = model.evaluate(X_train, Y_train)
print("训练数据集的准确度 = {:.2f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, Y_test)
print("测试数据集的准确度 = {:.2f}".format(accuracy))输出结果:
在训练集和测试集上,模型评估中 ... 1563/1563 [==============================] - 11s 7ms/step - loss: 0.2559 - accuracy: 0.9352 训练数据集的准确度 = 0.94 313/313 [==============================] - 2s 7ms/step - loss: 0.8194 - accuracy: 0.7467 测试数据集的准确度 = 0.75
(7)模型预测
# 计算分类的预测值
print("\nPredicting ...")
predict=model.predict(X_test)
Y_pred=np.argmax(predict,axis=1)
#重新加载Y_test
(X_train, Y_train), (X_test, Y_test) = cifar10.load_data()
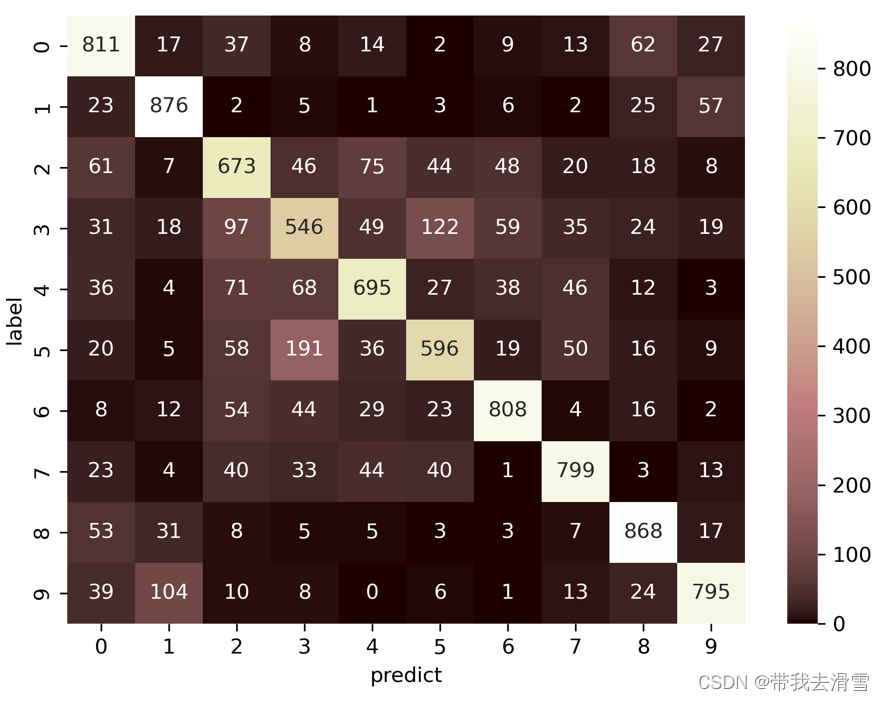
#计算混淆矩阵
#显示混淆矩阵
tb = pd.crosstab(Y_test.astype(int).flatten(),
Y_pred.astype(int),
rownames=["label"], colnames=["predict"])
print(tb)输出结果:
Predicting ... 313/313 [==============================] - 2s 7ms/step predict 0 1 2 3 4 5 6 7 8 9 label 0 811 17 37 8 14 2 9 13 62 27 1 23 876 2 5 1 3 6 2 25 57 2 61 7 673 46 75 44 48 20 18 8 3 31 18 97 546 49 122 59 35 24 19 4 36 4 71 68 695 27 38 46 12 3 5 20 5 58 191 36 596 19 50 16 9 6 8 12 54 44 29 23 808 4 16 2 7 23 4 40 33 44 40 1 799 3 13 8 53 31 8 5 5 3 3 7 868 17 9 39 104 10 8 0 6 1 13 24 795#使用热力图显示混淆矩阵
import seaborn as sns
sns.heatmap(tb,cmap='pink',fmt='.20g',annot=True)
plt.tight_layout()
plt.savefig("E:/工作/硕士/博客/博客34-深度学习之全过程搭建卷积神经网络(CNN)/squares4.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
#查看预测概率
#重新归一化
X_train = X_train.astype("float32") / 255
X_test = X_test.astype("float32") / 255
#选第10张图片
i = 10
img = X_test[i]
# 将图片转换成 4D 张量
X_test_img = img.reshape(1, 32, 32, 3).astype("float32")
# 绘出图表的预测结果
plt.figure()
plt.subplot(1,2,1)
plt.title("Example of Image:" + str(Y_test[i]))
plt.imshow(img, cmap="binary")
plt.axis("off")
plt.savefig("E:/工作/硕士/博客/博客34-深度学习之全过程搭建卷积神经网络(CNN)/squares5.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
#预测结果的概率
print("Predicting ...")
probs = model.predict(X_test_img, batch_size=1)
plt.subplot(1,2,2)
plt.title("Probabilities for Each Image Class")
plt.bar(np.arange(10), probs.reshape(10), align="center")
plt.xticks(np.arange(10),np.arange(10).astype(str))plt.savefig("E:/工作/硕士/博客/博客34-深度学习之全过程搭建卷积神经网络(CNN)/squares6.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

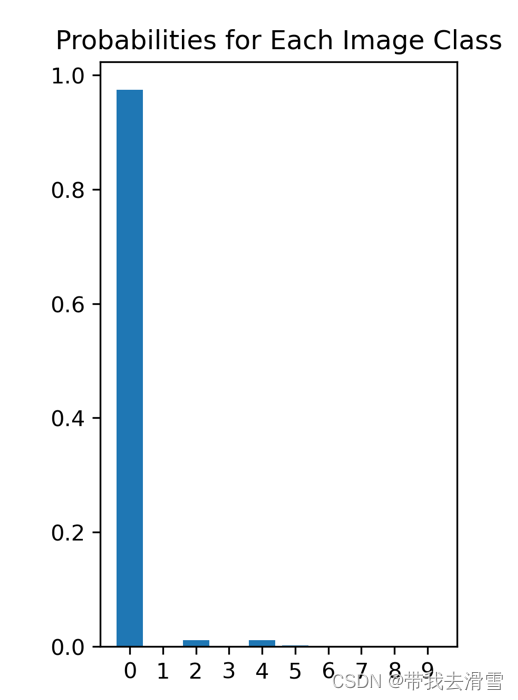
第一个图为原始图像,第二图为各个类别的预测概率,经过预测90%以上的概率认为图像为第0类即为一个飞机。
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!