@[TOC](9-《数据结构》
- 一、数组
- 1.稀疏数组
- 二、链表
- 三、队列
- 四、栈
- 五、树
- 5.1 完全二叉树
- 5.2 满二叉树:深度为k且有2^k-1个结点的二叉树称为满二叉树**
- 5.3 二叉排序树(二叉搜索树、二叉查找树)
- 5.4 平衡二叉树:
- 5.5 红黑树
- 六、堆
- 七、散列表(hash表)
- 八、图
- 1 启动优化
- 1.1.冷启动耗时统计?
- 1.2.TraceView和System Trace
- 1.3.优雅获取方法耗时
- 1.4.启动速度优化小技巧
- 1.5.启动优化之异步初始化
- 1.6.启动优化之异步初始化最优解—启动器
- 1.7.延迟初始化
- 1.8.其它方案
- 1.9.启动优化之模拟面试
- 2 布局优化
- 3 线程优化
- 3.1.线程调度原理
- 3.2.线程调度模型
- 3.3.线程使用准则:
- 4 网络优化
- 5 Apk瘦身—包体积优化
- 6 内存优化(非常重要)
- 6.1 Android 内存管理机制
- 6.2 Android的内存泄漏、内存溢出、内存抖动概念
- 6.3 如何避免OOM(内存泄漏优化)。
- 6.4 常用的内存检查工具。
- 7 电量优化
- 8.卡顿优化
- 9.稳定性优化
- 10.APP专项技术优化
- 1mvc/mvp/mvvm
- 2 常见设计模式
- 2.1.设计模式的六大原则:
- 2.2.单例模式
- 2.3.建造者模式
- 2.4.责任链模式
- 1.View的事件分发
- 2.Okhttp源码中的责任链模式
- 2.1 Inteceptor
- 2.2 Chain
- 2.5.观察者模式
- 1.各种控件的监听,如下:
- 2.Adapter的notifyDataSetChanged()方法
- 3. BroadcastReceiver
- 4.RxJava、RxAndroid、EventBus、otto等等,也是使用了观察者模式。
- 2.6.代理模式
- 2.7.策略模式
- 2.8.工厂模式
- 2.9.适配器模式
数据结构:计算机存储、组织数据的方式。相同特点的数据元素集合,不同数据结构在不同场景下有着不同的数据处理效率。
根据数据访问的特点,可分为线性数据结构和非线性数据结构。
线性结构:数组、链表、栈、队列等。
非线性结构:散列表、树、堆、图等。
一、数组
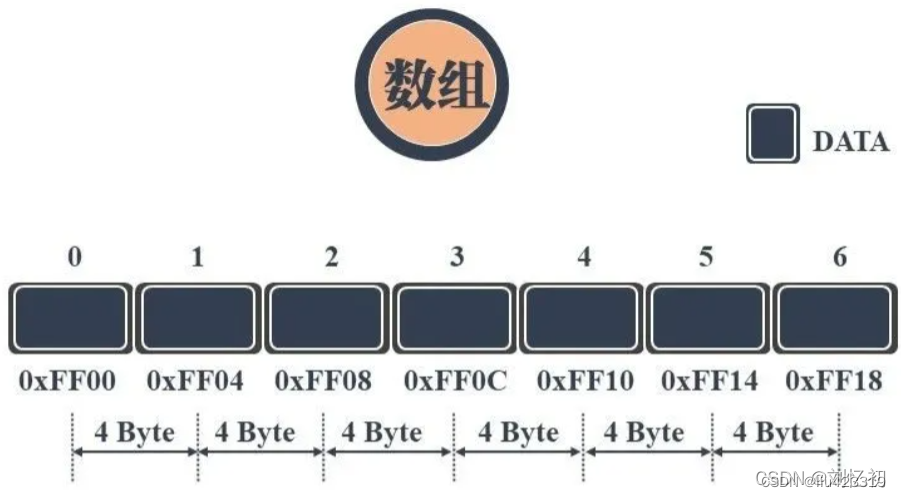
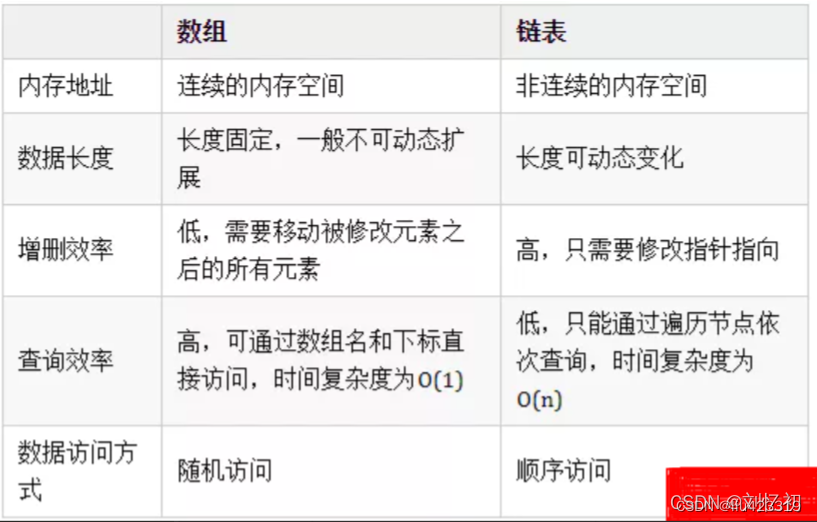
数组可以说是最基本最常见的数据结构,可通过数组名和下标进行数据的访问和更新。数组中元素的存储是按照先后顺序进行的,同时在内存中也是按照这个顺序进行连续存放。
数组相邻元素之间的内存地址的间隔一般就是数组数据类型的大小。
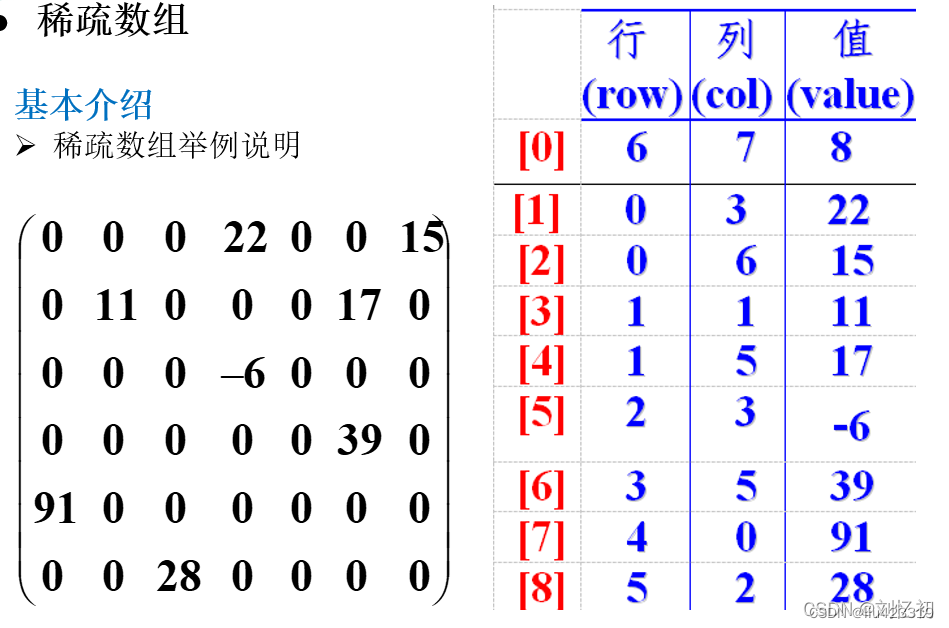
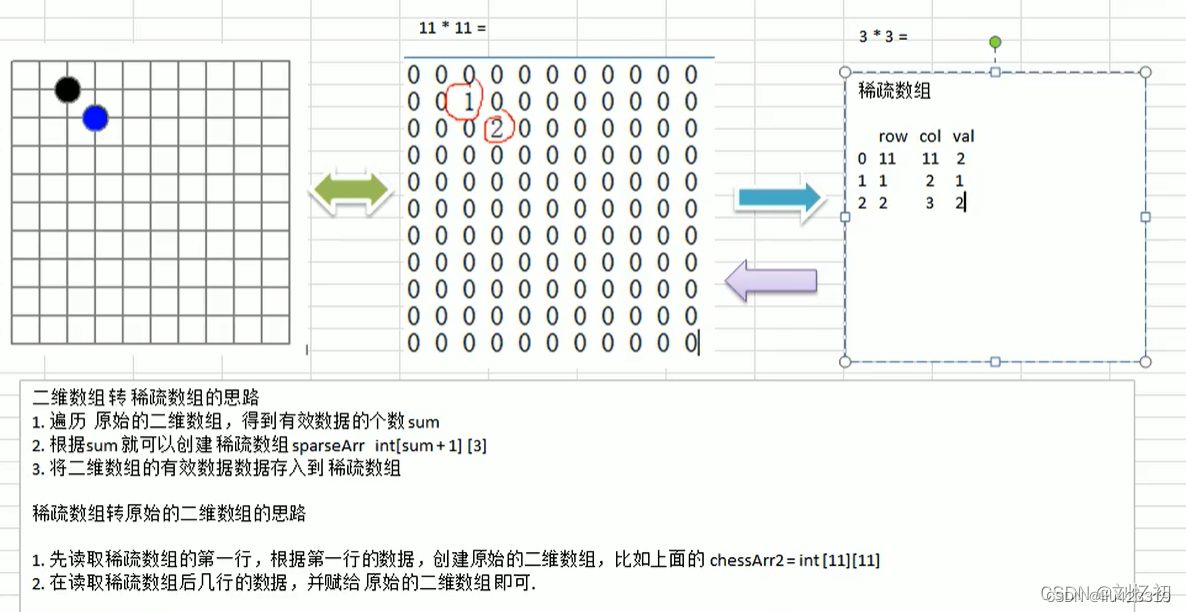
1.稀疏数组
概念:当一个数组中大部分元素为0,或者为同一值的数组时,可以使用稀疏数组来保存该数组。
-
稀疏数组的处理方式是:
-
记录数组一共有几行几列,有多少个不同值;把具有不同值的元素的行、列及值记录在一个小
规模的数组中,从而缩小程序的规模。
稀疏数组和二维数组互转的思路:
二、链表
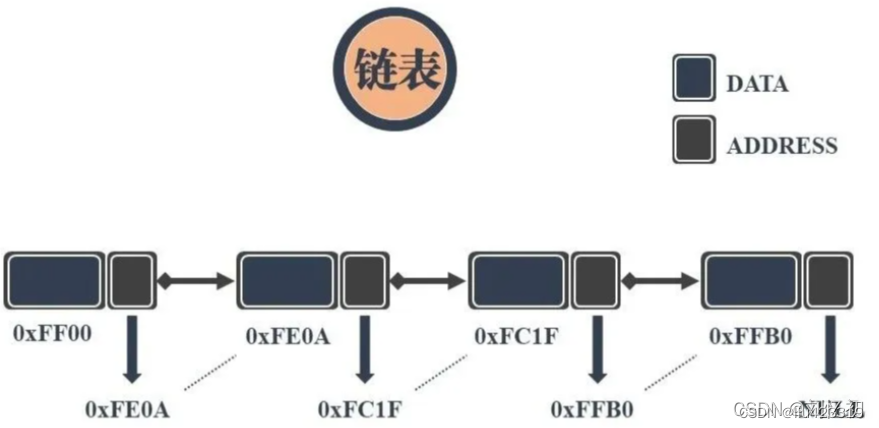
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比与线性数据表结构,操作复杂。
由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
链表相较于数组,除了数据域,还增加了指针域用于构建链式的存储数据。链表中每一个节点都包含此节点的数据和指向下一节点地址的指针。由于是通过指针进行下一个数据元素的查找和访问,使得链表的自由度更高。
这表现在对节点进行增加和删除时,只需要对上一节点的指针地址进行修改,而无需变动其它的节点。不过事物皆有两极,指针带来高自由度的同时,自然会牺牲数据查找的效率和多余空间的使用。
一般常见的是有头有尾的单链表,对指针域进行反向链接,还可以形成双向链表或者循环链表。
链表和数组对比:
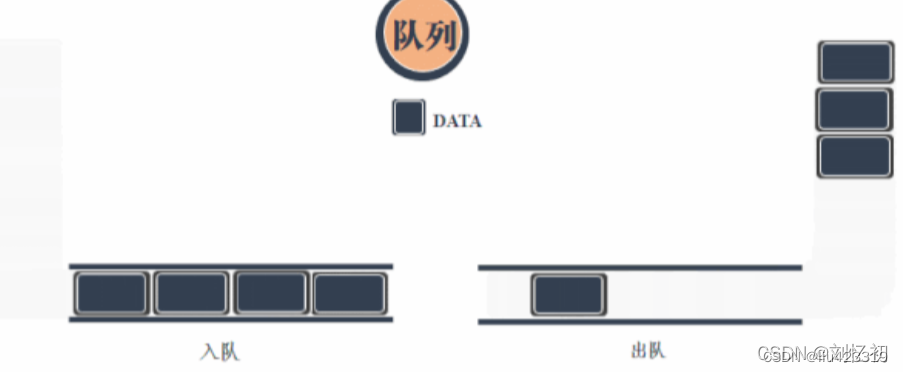
三、队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列是栈的兄弟结构,与栈的后进先出相对应,队列是一种先进先出的数据结构。顾名思义,队列的数据存储是如同排队一般,先存入的数据先被压出。常与栈一同配合,可发挥最大的实力。
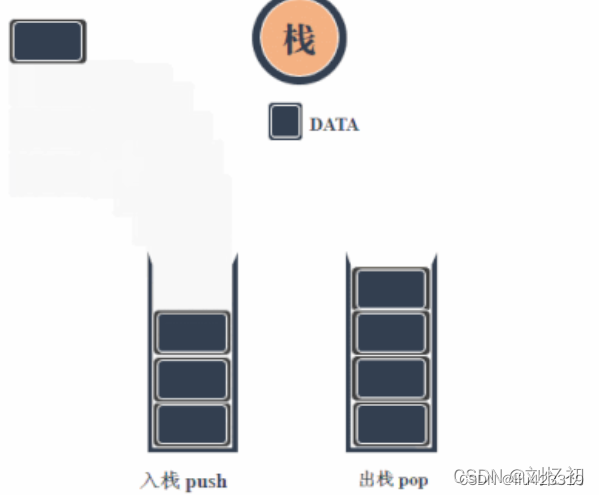
四、栈
后进先出,栈的常用操作包括入栈push和出栈pop,对应于数据的压入和压出。还有访问栈顶数据、判断栈是否为空和判断栈的大小等。
由于栈后进先出的特性,常可以作为数据操作的临时容器,对数据的顺序进行调控,与其它数据结构相结合可获得许多灵活的处理。
五、树
树(英语:tree)是一种抽象数据类型或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>0)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
1 ①每个节点有零个或多个子节点;
2 ②没有父节点的节点称为根节点;
3 ③每一个非根节点有且只有一个父节点;
4 ④除了根节点外,每个子节点可以分为多个不相交的子树;
5 树作为一种树状的数据结构,其数据节点之间的关系也如大树一样,将有限个节点根据不同层次关系进行排列,从而6 形成数据与数据之间的父子关系。常见的数的表示形式更接近“倒挂的树”,因为它将根朝上,叶朝下。
7 树的数据存储在结点中,每个结点有零个或者多个子结点。没有父结点的结点在最顶端,成为根节点;没有非根结点 有且只有一个父节点;每个非根节点又可以分为多个不相交的子树。
8 这意味着树是具备层次关系的,父子关系清晰,家庭血缘关系明朗;这也是树与图之间最主要的区别。
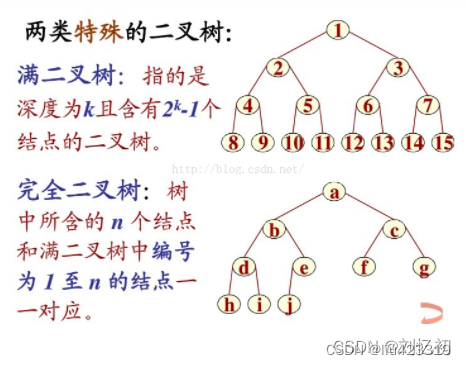
完全二叉树和满二叉树:
5.1 完全二叉树
概念:设二叉树的深度为h,则除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,
第 h 层所有的结点都连续集中在最左边
5.2 满二叉树:深度为k且有2^k-1个结点的二叉树称为满二叉树**
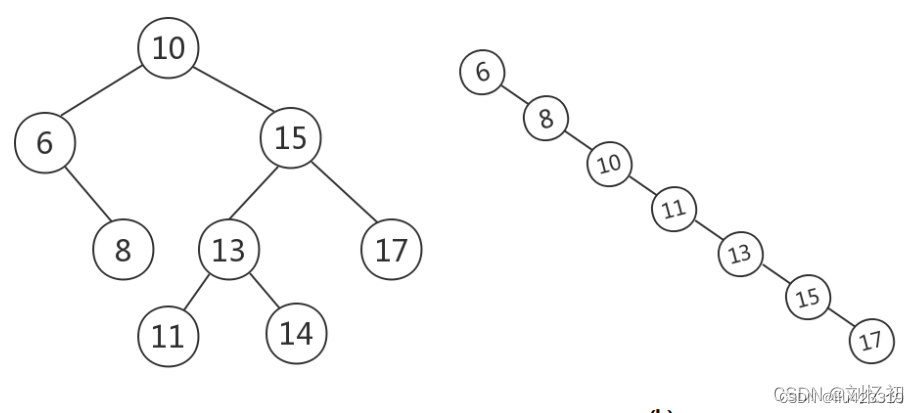
5.3 二叉排序树(二叉搜索树、二叉查找树)
什么是二叉查找树?
根节点的值大于其左子树中任意一个节点的值,小于其右节点中任意一节点的值,这一规则适用于二叉查找树中的每一个节点
树的高度:结点层次的最大值。
平衡因子:左子树高度 - 右子树高度。
二叉排序树意味着二叉树中的数据是排好序的,顺序为左结点<根节点<右结点,这表明二叉排序树的中序遍历结果是有序的。
二叉树的遍历方式:
先序遍历:先根节点->遍历左子树->遍历右子树
中序遍历:遍历左子树->根节点->遍历右子树
后序遍历:遍历左子树->遍历右子树->根节点
平衡二叉树的产生是为了解决二叉排序树在插入时发生线性排列的现象。由于二叉排序树本身为有序,当插入一个有序程度十分高的序列时,生成的二叉排序树会持续在某个方向的字数上插入数据,导致最终的二叉排序树会退化为链表,从而使得二叉树的查询和插入效率恶化。
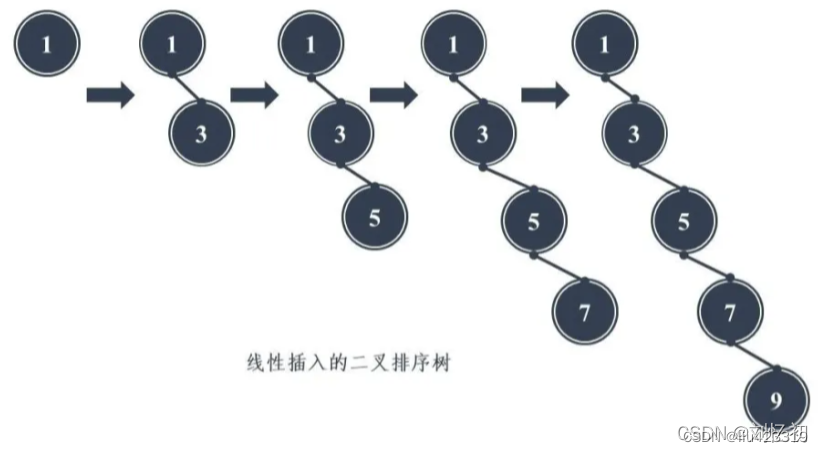
平衡二叉树的出现能够解决上述问题,但是在构造平衡二叉树时,却需要采用不同的调整方式,使得二叉树在插入数据后保持平衡。
主要的四种调整方式有LL(左旋)、RR(右旋)、LR(先左旋再右旋)、RL(先右旋再左旋)。LR和RL本质上只是LL和RR的组合。
在插入一个结点后应该沿搜索路径将路径上的结点平衡因子进行修改,当平衡因子大于1时,就需要进行平衡化处理。从发生不平衡的结点起,沿刚才回溯的路径取直接下两层的结点,如果这三个结点在一条直线上,则采用单旋转进行平衡化,如果这三个结点位于一条折线上,则采用双旋转进行平衡化。
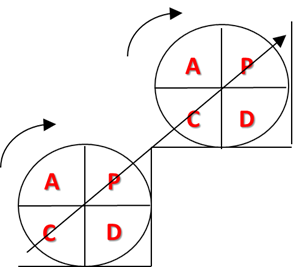
左旋:S为当前需要左旋的结点,E为当前结点的父节点。
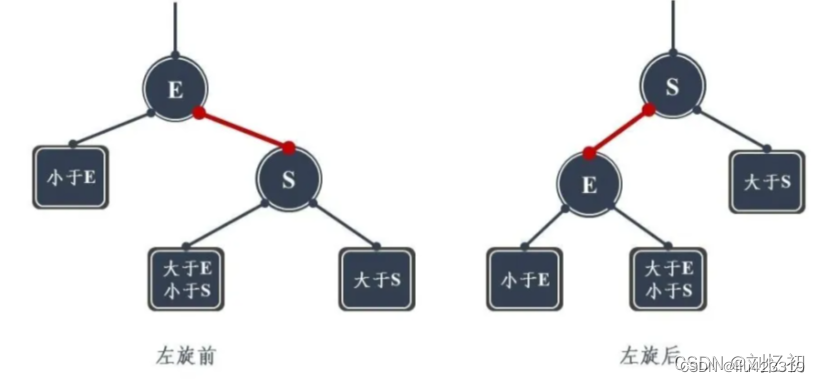
动图演示:
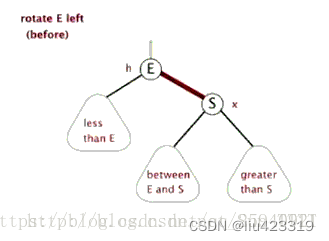
左旋的操作可以用一句话简单表示:将当前结点S的左孩子旋转为当前结点父结点E的右孩子,同时将父结点E旋转为当前结点S的左孩子
右旋:S为当前需要左旋的结点,E为当前结点的父节点。右单旋是左单旋的镜像旋转。
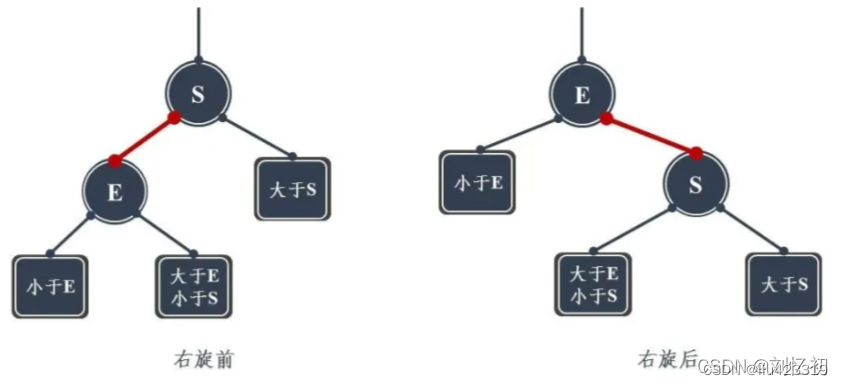
动图演示:
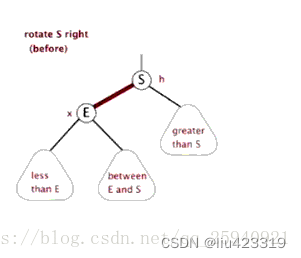
右旋的操作同样可以用一句话简单表示:将当前结点S的左孩子E的右孩子旋转为当前结点S的左孩子,同时将当前结点S旋转为左孩子E的右孩子。
5.4 平衡二叉树:
平衡二叉树又被称为AVL树,它是一棵二叉排序树,且具有以下性质:
- 可以是空树。
- 假如不是空树,它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
平衡之意,如天平,即两边的分量大约相同。
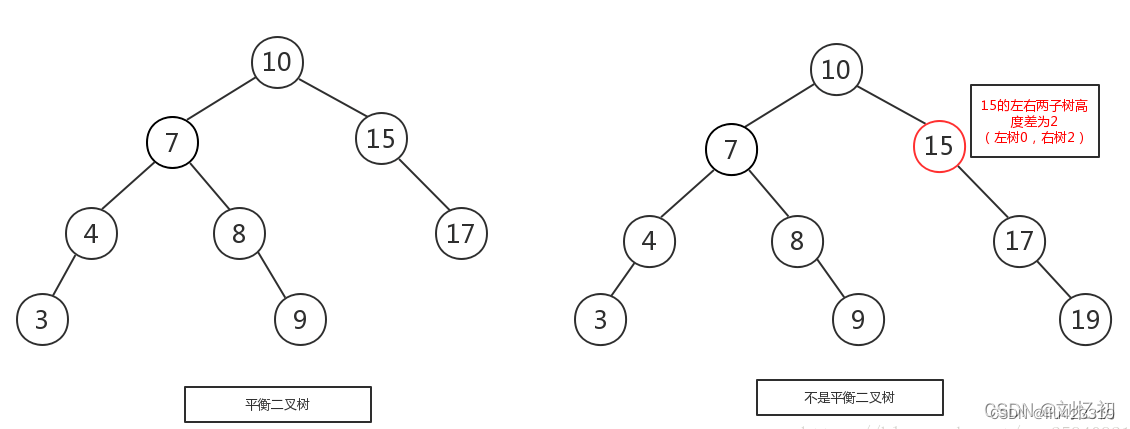
由此可以看出平衡二叉树是一棵高度平衡的二叉查找树。所以,要构建跟维系一棵平衡二叉树就比普通的二叉树要复杂的多。在构建一棵平衡二叉树的过程中,当有新的节点要插入时,检查是否因插入后而破坏了树的平衡,如果是,则需要做旋转去改变树的结构。
5.5 红黑树
平衡二叉树(AVL)为了追求高度平衡,需要通过平衡处理使得左右子树的高度差必须小于等于1。高度平衡带来的好处是能够提供更高的搜索效率,其最坏的查找时间复杂度都是O(logN)。但是由于需要维持这份高度平衡,所付出的代价就是当对树种结点进行插入和删除时,需要经过多次旋转实现复衡。这导致AVL的插入和删除效率并不高。
为了解决这样的问题,能不能找一种结构能够兼顾搜索和插入删除的效率呢?红黑树可以解决。
红黑树具有五个性质:
- 每个结点要么是红的要么是黑的。
- 根结点是黑的。
- 每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
- 如果一个结点是红的,那么它的两个子节点都是黑的。
- 任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
从性质5又可以推出:如果一个结点存在黑子结点,那么该结点肯定有两个子结点
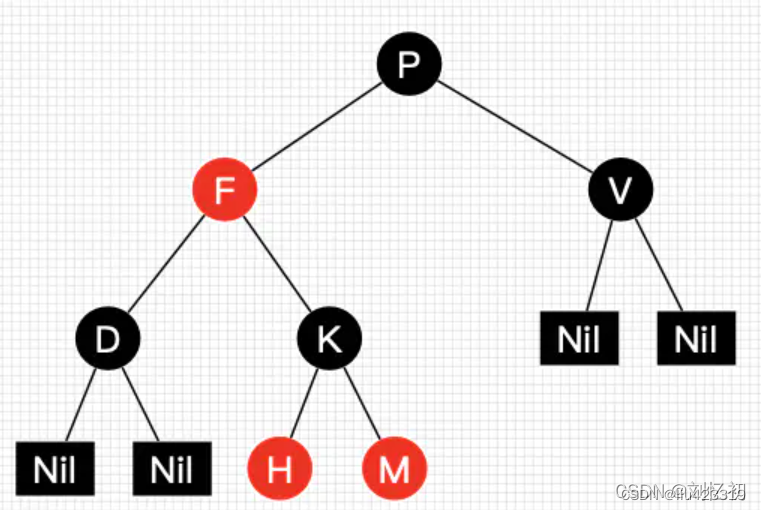
其中Nil为叶子结点,并且它是黑色的。(值得提醒注意的是,在Java中,叶子结点是为null的结点。)
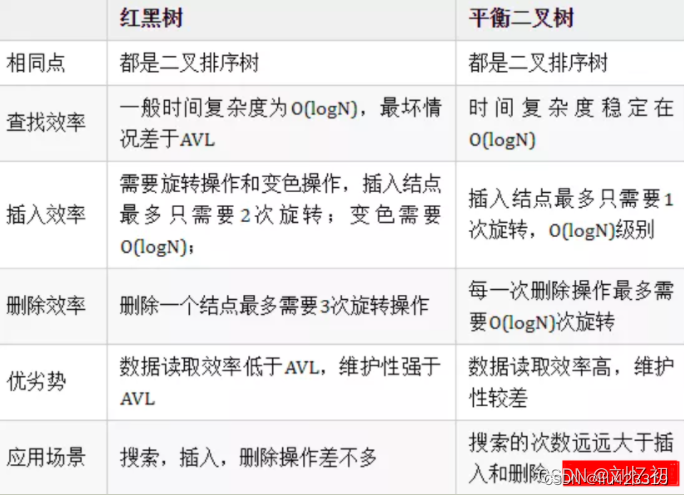
红黑树VS平衡二叉树
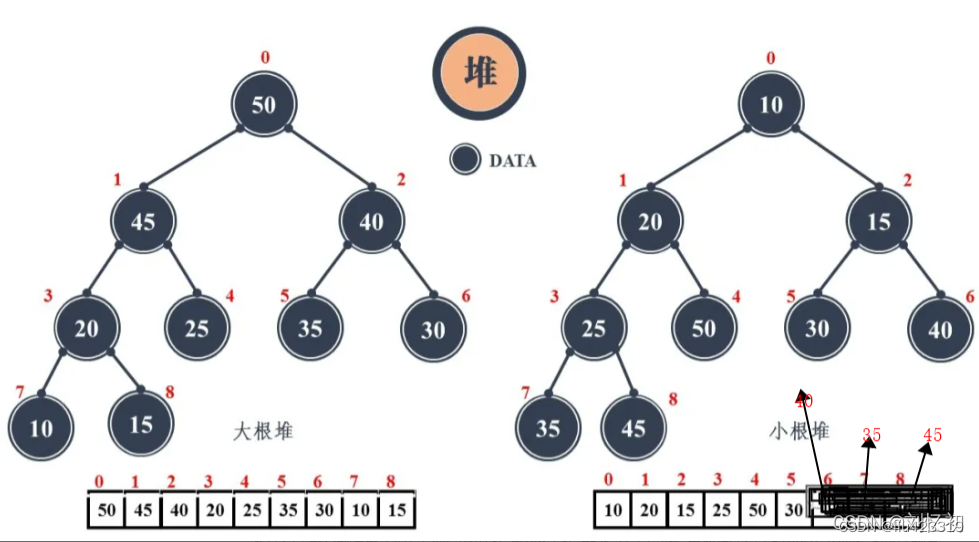
六、堆
堆就是用数组实现的二叉树,所有它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。
堆的常用方法:
- 构建优先队列
- 支持堆排序
- 快速找出一个集合中的最小值(或者最大值)
堆分为两种:最大堆和最小堆,两者的差别在于节点的排序方式。
在最大堆中,父节点的值比每一个子节点的值都要大。在最小堆中,父节点的值比每一个子节点的值都要小。这就是所谓的“堆属性”,并且这个属性对堆中的每一个节点都成立。
了解完二叉树,再来理解堆就不是什么难事了。堆通常是一个可以被看做一棵树的数组对象。堆的具体实现一般不通过指针域,而是通过构建一个一维数组与二叉树的父子结点进行对应,因此堆总是一颗完全二叉树。
对于任意一个父节点的序号n来说(这里n从0算),它的子节点的序号一定是2n+1,2n+2,因此可以直接用数组来表示一个堆。
不仅如此,堆还有一个性质:堆中某个节点的值总是不大于或不小于其父节点的值。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
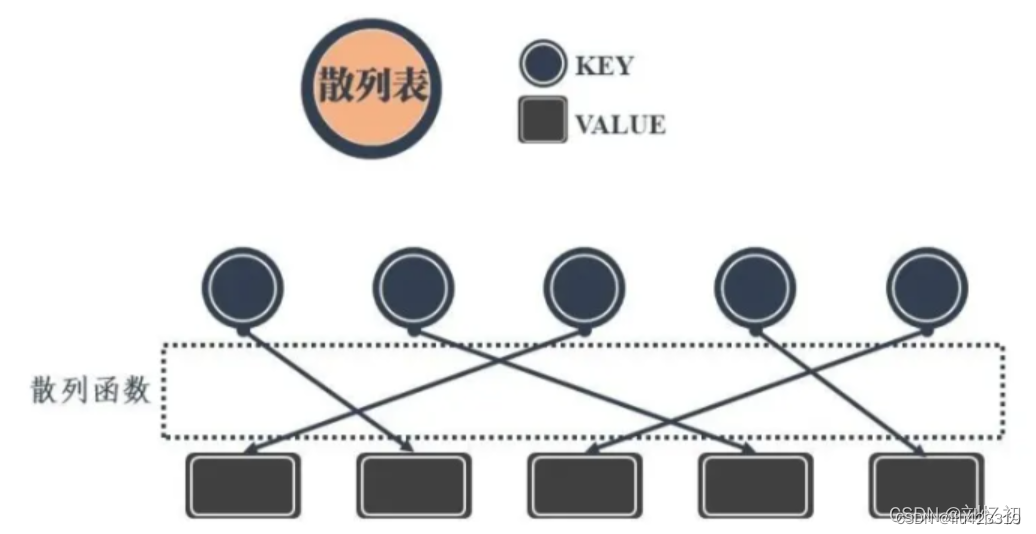
七、散列表(hash表)
散列表也叫哈希表,是一种通过键值对直接访问数据的机构。在初中,我们就学过一种能够将一个x值通过一个函数获得对应的一个y值的操作,叫做映射。散列表的实现原理正是映射的原理,通过设定的一个关键字和一个映射函数,就可以直接获得访问数据的地址,实现O(1)的数据访问效率。在映射的过程中,事先设定的函数就是一个映射表,也可以称作散列函数或者哈希函数。
八、图
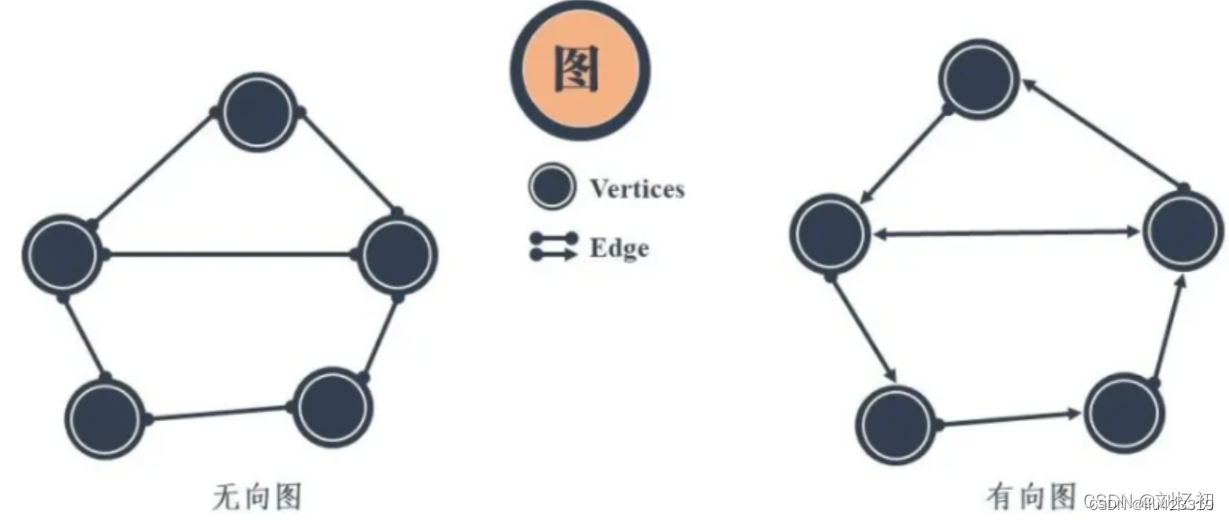
图相较于上文的几个结构可能接触的不多,但是在实际的应用场景中却经常出现。比方说交通中的线路图,常见的思维导图都可以看作是图的具体表现形式。
图结构一般包括顶点和边,顶点通常用圆圈来表示,边就是这些圆圈之间的连线。边还可以根据顶点之间的关系设置不同的权重,默认权重相同皆为1。此外根据边的方向性,还可将图分为有向图和无向图。
)
1 启动优化
冷启动:耗时最多,是启动优化的衡量标准。启动应用时,后台没有该应用的进程,系统会重新创建一个新的进程分配给该应用,这个启动方式就是冷启动。
热启动:应用从后台到前台
优化方向:主要针对冷启动,Application和Activity生命周期
1.1.冷启动耗时统计?
1.系统提供的命令:(线下使用方面,不能带到线上;非严谨精确的时间)
1 | adb shell am start -S -W 包名/启动类的全限定名 //-S 表示重启当前应用
执行
1 C:\Android\Demo>adb shell am start -S -W com.example.moneyqian.demo/com.example.moneyqian.demo.MainActivity
2 Stopping: com.example.moneyqian.demo
3 Starting: Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] cmp=com.example.moneyqian.demo/.MainActivity }
4 Status: ok
5 Activity: com.example.moneyqian.demo/.MainActivity
6 ThisTime: 2247
7 TotalTime: 2247
8 WaitTime: 2278
9 Complete
————————————————
ThisTime : 最后一个Activity的启动耗时(例如从 LaunchActivity - >MainActivity「adb命令输入的Activity」 , 只统计 MainActivity 的启动耗时)
TotalTime : 所有activity的启动耗时(有几个Activity 就统计几个)
WaitTime : 应用进程的创建过程 + TotalTime (AMS启动activity的总耗时)
————————————————
版权声明:本文为CSDN博主「刘忆初」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_34512207/article/details/123110031
2.手动打点:(精确,可带到线上,推荐)
注意截止时间的选取
误区:onWIndowFocusChanged 首帧时间
正解:真实数据展示,Feed第一条展示
1.2.TraceView和System Trace
1.TraceView:
特点:
运行时开销严重
可能会带偏优化方向
TraceView使用方式
代码中添加:
1 Debug.startMethodTracing();
2 被检测的方法;
3 Debug.stopMethodTracing();
需要使用adb pull将生成的.trace文件导出到电脑,然后使用Android Studio的Profiler进行加载;
打开 Profiler -> CPU -> 点击 Record -> 点击 Stop -> 查看Profiler下方Top Down/Bottom Up 区域,以找出耗时的热点方法。
结合CPU Profiler 分析
使用 Profile 的 CPU 模块可以帮我们快速找到耗时的热点方法。
TraceView作用:主要做热点分析,用来得到以下两种数据:
单次执行最耗时的方法。
执行次数最多的方法。
2.System Trace:
集合android内核的数据,生成html报告
API18以上使用,推荐TraceCompat
轻量级,开销小
直观反应cpu利用率
cputime与walltime的区别
-cputime是代码消耗cpu的时间(重点指标,优化方向)
-walltime是代码执行的时间(举例:锁冲突可能导致walltime时间长很多)
作用:
主要用于分析绘制性能方面的问题。
分析系统关键方法和应用方法耗时。
1.3.优雅获取方法耗时
1.常规实现:侵入性强,工作量大
2.AOP方式:面向切面编程
- 针对同一类问题的统一处理,修改方便
- 无侵入添加代码

- 详细使用请百度,封装一个打印耗时点日志的辅助类
1.4.启动速度优化小技巧
启动白屏优化—>theme切换:感觉上的快,对实际启动速度无帮助
解决启动白屏问题
再启动app时展示一张静态图 ,实现方法是给splash页面设置theme主题 ,主题设置background背景图代替白屏页,展示完成背景图和splash之后,,在Mainactivity onCreat()之前把系统appTheme设置回来。
1.5.启动优化之异步初始化
核心思想:子线程分担主线程的任务,并行减少时间
Application中加入异步线程:把application中各种初始化操作分散到子线程中执行。
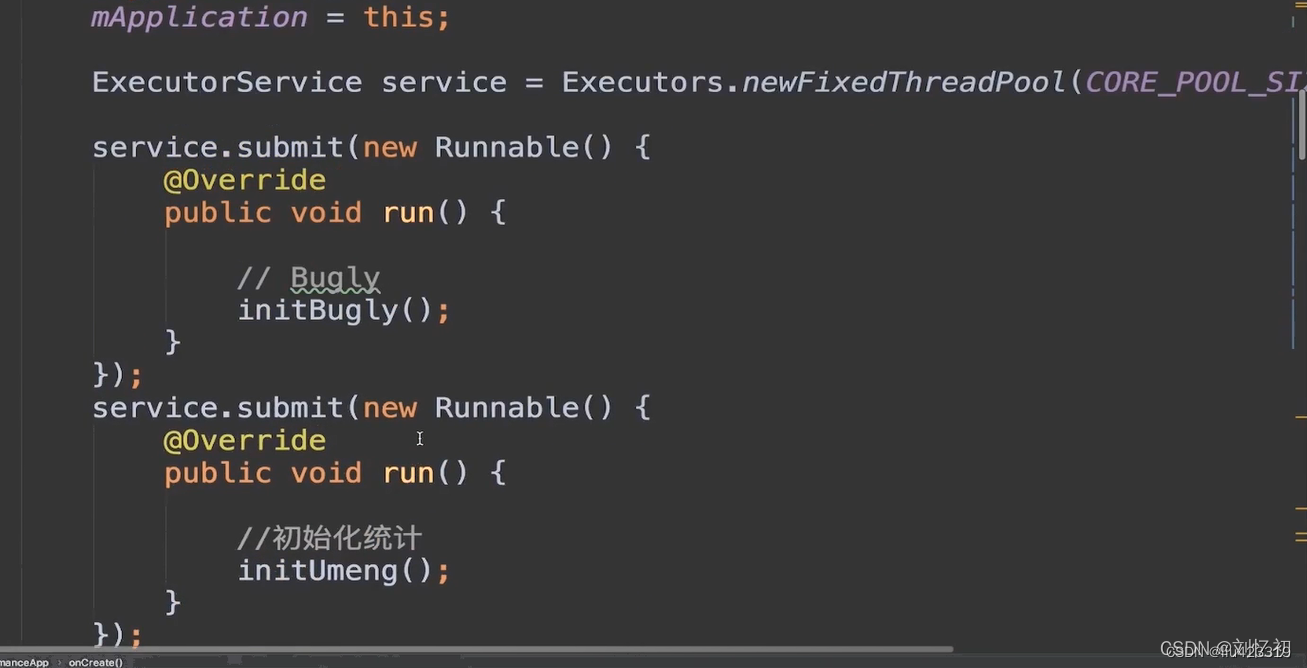
把各种初始化的操作,通过线程池,放到子线程中执行,这里创建线程池的核心线程数,参考的是asyncTask中的核心线程数量的设置。如果自己随便设置,可能超过CPU的核数或者低于CPU核数太多。
这样处理后,application的onCreate将会快很多,但是会出现一些问题,比如有些初始化操作在子线程中还没执行完,其它地方如splashActivity已经要开始使用该方法中的某些内容。就会报错。那么要么放弃把这个初始化方法放到子线程,要么参考下面的方案
解决方案:通过CountDownLatch,在application中创建一个CountDownLatch
1 //相当于自己加一个锁
2 private final CountDownLatch countDownLatch=new CountDownLatch(1);
3 ...
4 @Override
5 public void onCreate() {
6 ...
7 service.submit(new Runnable() {
8 @Override
9 public void run() {
10 initGeTui();
11 countDownLatch.countDown(); //CountDown满足一次
12 }
13 });
14
15 try {
16 countDownLatch.await(); //会检测执行次数是否满足
17 } catch (InterruptedException e) {
18 e.printStackTrace();
19 }
20 }
1.6.启动优化之异步初始化最优解—启动器
上面方案的缺点:
- 代码不够优雅,
- 如果多个异步初始化之间存在依赖关系,不好处理
- 维护成本高
启动器的核心思想:充分利用CPU多核,自动梳理任务顺序
启动器设计流程:
- 任务Task化,启动逻辑抽象成Task。
- 根据所有任务依赖关系排序生成一个有向无环图。
- 多线程按照排序后的优先级依次执行。
1.7.延迟初始化
结合IdleHandler,在空闲时执行
1.8.其它方案
提前加载SharedPreferences:
Multidex之前加载,利用此阶段CPU
启动阶段不启动子进程:
子进程会共享CPU资源,导致主进程CPU紧张
类加载优化:
提前异步类加载(使用的时候不用再加载)
启动阶段抑制GC
CPU锁频
1.9.启动优化之模拟面试
1.你做启动优化怎么做的?
分析现状,确认问题。–目前的启动流程已经非常复杂,主线程执行了太多的代码。
异步优化。–异步初始化–>启动器
延迟初始化。–有些代码可能不需要application中执行,可以在页面初始化后空闲时
2.是怎么异步的,异步遇到什么问题没有?
new thread 或者线程池
代码变得不够优雅,依赖关系不好处理—>启动器
3.启动优化,有哪些容易忽略的注意点?
cpu time和wall time的区别
注意延迟初始化的优化
介绍下黑科技
4.版本迭代导致的启动变慢有什么好的解决办法吗?
启动器
结合CI
监控完善
2 布局优化
工具:system trace
关注frames
正常:绿色原点,丢帧:黄色或红色
Alerts栏
工具:Layout Insepector
AndroidStudio自带工具,可查看视图层次结构
减少布局嵌套:层级嵌套过深的话,深度遍历各个节点会非常消耗时间,这也是布局优化余地最大的一个点了。使用约束布局 Constraintlayout减少嵌套 。
使用合适的布局:
简单布局 FrameLayout>LinearLayout>RelativeLayout;
复杂布局 RelativeLayout>LinearLayout>FrameLayout
如果用 RelativeLayout 可以避免布局嵌套的话是值得的。(LinearLayout在设置weight时,也会调用子View 2次 onMeasure)
使用 include 标签: 在布局文件中,标签可以指定插入一段布局文件到当前布局。这样的话既提高了布局复用,也减少了我们的代码书写。另外,merge标签可以和include的标签一起使用从而减少布局层级。
ViewStub 延时加载: 有些布局,比如网络出错的布局,没必要在所有时候都加载出来。使用 ViewStub 可以实现按需加载。ViewStub 本身没有宽高,加载起来几乎不消耗什么资源。当对他setVisibility(View.VISIBLE)的时候会调用它引用的真实布局填充到当前位置,从而实现了延时加载,节省了正常加载的时间。
避免过渡绘制:去掉多余的背景色,减少复杂shape的使用
ondraw中避免:创建大对象,耗时操作
3 线程优化
3.1.线程调度原理
- 任意时刻,只有一个线程占用CPU,处于运行状态
- 多线程并发,轮流获取CPU使用权
- JVM 负责线程的调度:按照特定的机制分配CPU使用权
3.2.线程调度模型
分时调度模型:让所有线程轮流获取 CPU 的使用权,而且均分每个线程占用 CPU 的时间片,这种方式非常公平
抢占式调度模型:让优先级高的线程优先获取到 CPU 的使用权,如果在可运行池当中的线程优先级都一样,那就随机选取一个(JVM使用这种)
3.3.线程使用准则:
- 严禁直接使用new Thread
- 提供基础线程池供各个业务线使用;避免各个业务线各自维护一套线程池,导致线程数过多。
- 根据任务类型选择合适的异步方式
优先级低,长时间执行,HandlerThread
定时任务,线程池 - 创建线程必须命名;方便定位线程归属,运行时通过Thread.currentThread().setName修改名字
- 关键异步任务监控;AOP方式做监控
- 重视优先级设置;Process.setThreadPriority(),可以多次设置
如何锁定线程创建者:
项目变大之后收敛线程;项目源码、三方库、arr中都有线程的创建
分析:
创建线程的位置获取堆栈,
所有的异步方式,都会走到new thread
怎么在项目中对线程进行优化
线程收敛
统一线程池:任务区分
监控重要异步任务
线程的创建和销毁会带来比较大的性能开销。因此线程优化也很有必要。查看项目中是否存在随意 new thread,线程缺乏管理的情况。使用 AsyncTask 或者线程池对线程进行管理,可以提升 APP 的性能。另外,我比较推荐使用 Rxjava 来实现异步操作,既方便又优雅。
4 网络优化
-
连接复用:节省连接建立时间,如开启 keep-alive。于Android来说默认情况下HttpURLConnection和HttpClient都开启了keep-alive。
-
请求合并:即将多个请求合并为一个进行请求,比较常见的就是网页中的CSS Image Sprites。同一个页面数据尽量放到一个接口中去处理。
-
减少请求数据的大小:对于post请求,body可以做gzip压缩的,header也可以做数据压缩(不过只支持http 2.0)。 返回数据的body也可以做gzip压缩,body数据体积可以缩小到原来的30%左右(也可以考虑压缩返回的json数据的key数据的体积,尤其是针对返回数据格式变化不大的情况,支付宝聊天返回的数据用到了)。
-
根据用户的当前的网络质量来判断下载什么质量的图片(电商用的比较多)。
-
使用HttpDNS优化DNS:DNS存在解析慢和DNS劫持等问题,DNS 不仅支持 UDP,它还支持 TCP,但是大部分标准的 DNS 都是基于 UDP 与 DNS 服务器的 53 端口进行交互。HTTPDNS 则不同,顾名思义它是利用 HTTP 协议与 DNS 服务器的 80 端口进行交互。不走传统的 DNS 解析,从而绕过运营商的 LocalDNS 服务器,有效的防止了域名劫持,提高域名解析的效率。
-
大量数据的加载采用分页的方式;上传图片时,在必要的时候压缩图片。
网络优化工具:Network Profiler
1.显示实时网络波动:发送、接收数据及连接数
2.需要启动高级分析
3.只支持HttpURLConnection和OkHttp库
抓包工具:Charles(使用java开发的)
断点功能
Map Local
弱网环境模拟
NetWorkStatsManager
获取线上使用的流量情况
前后台流量获取方案
在网络方面你做了哪些监控,建立了哪些指标?
初期没有做,开发都是连着wifi,没有注意到这个问题。用户量增多后,收到用户的反馈。
补上网络方面的监控:
质量:请求成功率,每步耗时,状态码
流量:精确统计、前后台流量消耗
如何有效的降低用户流量消耗?
数据:缓存、增量更新
上传:压缩
图片:缩略图、webp
用户反馈消耗流量多这种问题怎么查?
精准流量获取能力
所有请求大小及次数的监控
主动预警能力
5 Apk瘦身—包体积优化
Apk 组成结构:
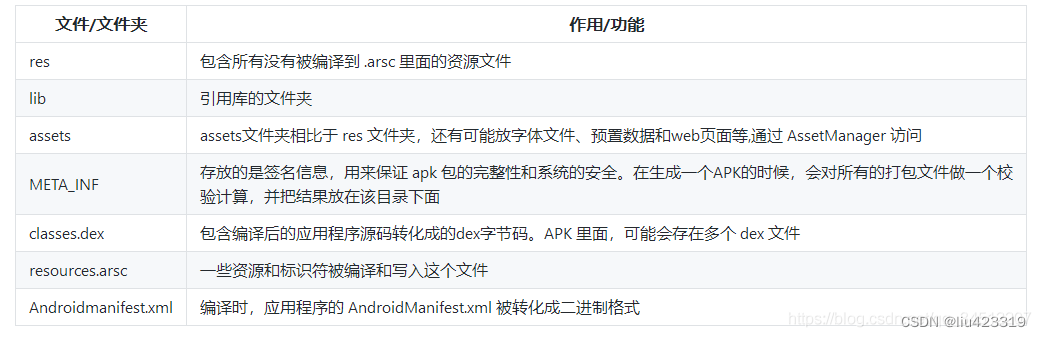
1.三方库处理:
- 统一三方库,不要重复
- 根据需求选择更小的库
- 仅引入所需的部分代码:Fresco的webp支持;smartrefreshlayout也有类似的功能剥离。
2.资源优化
图片只保留一份,如xhdpi
android自带的功能:移除无用资源
jpg/png转webp
优先考虑能否用 shape 代码、.9 、svg、VectorDrawable 类来替换传统的图片
避免使用帧动画,可使用 Lottie 动画库
3.代码优化
启用混淆以移除无用代码(minifyEnabled true )
开启代码压缩( minifyEnabled true //打开代码压缩)
剔除 R 文件
用注解替代枚举
4.arsc文件优化
移除未使用的备用资源来优化 .arsc 文件
1 android {
2 defaultConfig {
3 ...
4 resConfigs "zh", "zh_CN", "zh_HK", "en"
5 }
6 }
5.so库打包优化(此种优化效果非常明显)
so是Android上的动态链接库,七种不同类型的CPU架构:armeabi、armeabi-v7a、arm64-v8a、x86
、x86_64、MIPS、MIPS64。arm 系列是绝大多数手机上使用的,x86 主要是运用在平板上。
优化方式一:移出非主流的so库,只提供对主流架构的支持,一般选择armeabi-v7a。
android {
1 defaultConfig {
2 ...
3 ndk {
4 abiFilters "armeabi-v7a"
5 }
6 }
7}
这种方案相对来说比较暴力。
优化方案二(更优方案)
完美支持所有设备类型代价太大。都放在armeabi目录,根据CPU类型加载对应架构so。
其它方案:
- so动态下载
- 插件化
6 内存优化(非常重要)
首先需要了解ava 内存回收机制——GC机制,Java 对象引用方式 —— 强引用、软引用、弱引用和虚引用。
基础知识:
6.1 Android 内存管理机制
1.针对进程的内存策略
进程的内存分配策略为:由 ActivityManagerService 集中管理所有进程的内存分配。
进程的内存回收策略为:首先Application Framework 决定回收的类型,当进程的内存空间紧张时会按照进程优先级由低到高的顺序自动回收进程及内存。
Android将进程分为5个优先级,具体如下:
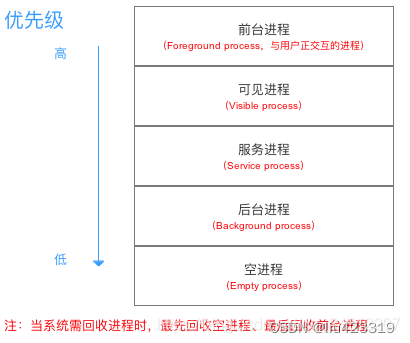
真正执行回收进程的操作的是 Linux 内核。
梳理一下整体流程:
-
ActivityManagerService 对所有进程进行评分。
-
更新评分到 Linux 内核。
-
由 Linux 内核完成真正的内存回收。
2.针对对象、变量的内存策略
Android的对于对象、变量的内存策略同 Java
内存管理 = 对象 / 变量的内存分配 + 内存释放
-
内存分配策略
对象,变量的内存分配有系统负责,共有三种:静态分配、栈式分配、堆式分配,分别面向静态变量,动态变量和对象实例。 -
内存释放策略
对象,变量的内存释放由Java的垃圾回收器GC负责。
内存分配注意:(非常重要)
-
成员变量全部存储在堆中(包括基本数据类型,引用及引用的对象实体)—因为他们属于类,类对象最终还是要被new出来的。
-
局部变量的基本数据类型和引用存储于栈当中,引用的对象实体存储在堆中。—–因为他们属于方法当中的变量,生命周期会随着方法一起结束。
1 public class Sample {
2 // 该类的实例对象的成员变量s1、mSample1及指向的对象都存放在堆内存中
3 int s1 = 0;
4 Sample mSample1 = new Sample();
5
6 // 方法中的局部变量s2、mSample2存放在 栈内存
7 // 变量mSample2所指向的对象实例存放在 堆内存
8 public void method() {
9 int s2 = 0;
10 Sample mSample2 = new Sample();
11 }
12}
13 // 变量mSample3的引用存放在栈内存中
14 // 变量mSample3所指向的对象实例存放在堆内存
15 // 该实例的成员变量s1、mSample1也存放在堆内存中
16 Sample mSample3 = new Sample();
17
6.2 Android的内存泄漏、内存溢出、内存抖动概念
1.内存泄露
即 ML (Memory Leak),指 程序在申请内存后,当该内存不需再使用但却无法被释放,归还给 程序的现象。对应用程序的影响:容易使得应用程序发生内存溢出,即OOM(out of Memory)
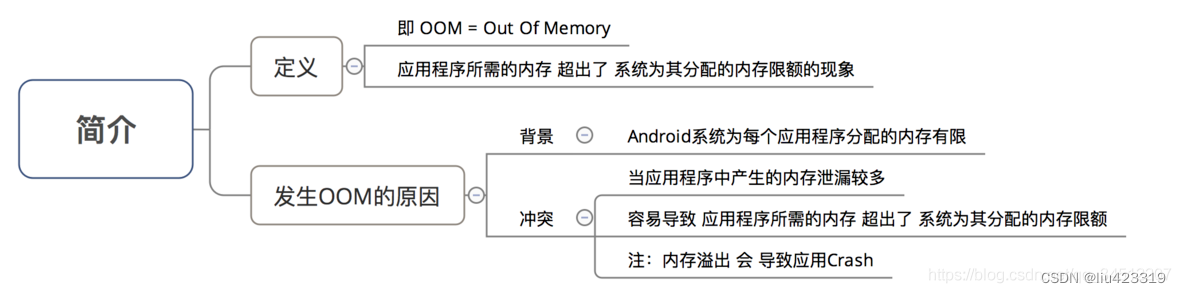
发生内存泄露的本质原因:
本质原因:持有引用者的生命周期>被引用者的生命周期
解释:本该回收的对象(该对象已经不再被使用),由于某些原因(如被另一个正在使用的对象引用)不能被回收。
2.内存抖动

优化方案
尽量避免频繁创建大量、临时的小对象
6.3 如何避免OOM(内存泄漏优化)。
1.减小对象的内存占用
1)使用更加轻量的数据结构
例如,我们可以考虑使用ArrayMap/SparseArray而不是HashMap等传统数据结构,下图演示了HashMap的简要工作原理,相比起Android系统专门为移动操作系统编写的ArrayMap容器,在大多数情况下,都显示效率低下,更占内存。通常的HashMap的实现方式更加消耗内存,因为它需要一个额外的实例对象来记录Mapping操作。另外,SparseArray更加高效在于他们避免了对key与value的autobox自动装箱,并且避免了装箱后的解箱。
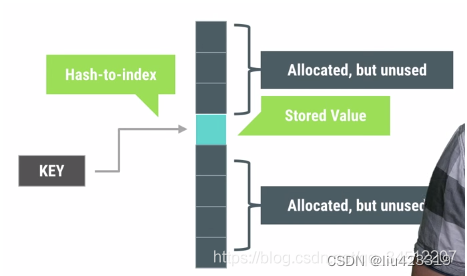
可以参考 Android性能优化典范 - 第3季
2)避免在Android里面使用Enum
3)减小Bitmap对象的内存占用
Bitmap是一个极容易消耗内存的大胖子,减小创建出来的Bitmap的内存占用是很重要的,通常来说有下面2个措施:
inSampleSize:缩放比例,在把图片载入内存之前,我们需要先计算出一个合适的缩放比例,避免不必要的大图载入。
decode format:解码格式,选择ARGB_8888/RBG_565/ARGB_4444/ALPHA_8,存在很大差异。
4)使用更小的图片
在设计给到资源图片的时候,我们需要特别留意这张图片是否存在可以压缩的空间,是否可以使用一张更小的图片。尽量使用更小的图片不仅仅可以减少内存的使用,还可以避免出现大量的InflationException。
2.内存对象的重复利用
1)复用系统自带的资源
Android系统本身内置了很多的资源,例如字符串/颜色/图片/动画/样式以及简单布局等等,这些资源都可以在应用程序中直接引用。这样做不仅仅可以减少应用程序的自身负重,减小APK的大小,另外还可以一定程度上减少内存的开销,复用性更好。但是也有必要留意Android系统的版本差异性,对那些不同系统版本上表现存在很大差异,不符合需求的情况,还是需要应用程序自身内置进去。
2)注意在ListView/GridView等出现大量重复子组件的视图里面对ConvertView的复用
3)Bitmap对象的复用
在ListView与GridView等显示大量图片的控件里面需要使用LRU的机制来缓存处理好的Bitmap。
4)避免在onDraw方法里面执行对象的创建
类似onDraw等频繁调用的方法,一定需要注意避免在这里做创建对象的操作,因为他会迅速增加内存的使用,而且很容易引起频繁的gc,甚至是内存抖动。
5)StringBuilder
在有些时候,代码中会需要使用到大量的字符串拼接的操作,这种时候有必要考虑使用StringBuilder来替代频繁的“+”。
3.避免对象的内存泄露
内存对象的泄漏,会导致一些不再使用的对象无法及时释放,这样一方面占用了宝贵的内存空间,很容易导致后续需要分配内存的时候,空闲空间不足而出现OOM。显然,这还使得每级Generation的内存区域可用空间变小,gc就会更容易被触发,容易出现内存抖动,从而引起性能问题。(LeakCanary开源控件,可以很好的帮助我们发现内存泄露的情况)
1)注意Activity的泄漏
通常来说,Activity的泄漏是内存泄漏里面最严重的问题,它占用的内存多,影响面广,我们需要特别注意以下两种情况导致的Activity泄漏:
内部类引用导致Activity的泄漏:非静态(匿名)内部类会默认持有外部类引用。
-
Handler导致的Activity泄漏(最经典的场景),如果Handler中有延迟的任务或者是等待执行的任务队列过长,都有可能因为Handler继续执行而导致Activity发生泄漏。此时的引用关系链是Looper -> MessageQueue -> Message -> Handler -> Activity。为了解决这个问题,可以在UI退出之前,执行remove Handler消息队列中的消息与runnable对象(removeCallbacksAndMessages(null)–同时清空消息队列 ,结束Handler生命周期)。或者是使用Static + WeakReference的方式来达到断开Handler与Activity之间存在引用关系的目的。为了保证Handler中消息队列中的所有消息都能被执行,此处推荐使用 静态内部类 + 弱引用的方式。
-
线程造成的内存泄漏
在 Activity 内定义了一个匿名的 AsyncTask 对象,就有可能发生内存泄漏。如果 Activity 被销毁之后 AsyncTask 仍然在执行,那就会阻止垃圾回收器回收Activity 对象,进而导致内存泄漏,直到执行结束才能回收 Activity。
同样的,使用 Thread 和 TimerTask 也可能导致 Activity 泄漏。只要它们是通过匿名类创建的,尽管它们在单独的线程被执行,它们也会持有对 Activity 的强引用,进而导致内存泄漏。
总结:
内部类引起的泄漏不仅仅会发生在Activity上,其他任何内部类出现的地方,都需要特别留意!我们可以考虑尽量使用static类型的内部类,同时使用WeakReference的机制来避免因为互相引用而出现的泄露。
2)考虑使用Application Context而不是Activity Context
对于大部分非必须使用Activity Context的情况(Dialog的Context就必须是Activity Context),我们都可以考虑使用Application Context而不是Activity的Context,这样可以避免不经意的Activity泄露。(Activity Context被传递到其他实例中,这可能导致Activity自身被引用而发生泄漏)
3)注意临时Bitmap对象的及时回收
4)注意监听器的注销
在Android程序里面存在很多需要register与unregister的监听器,我们需要确保在合适的时候及时unregister那些监听器。自己手动add的listener,需要记得及时remove这个listener。
5)注意WebView的泄漏
Android中的WebView存在很大的兼容性问题,不仅仅是Android系统版本的不同对WebView产生很大的差异,另外不同的厂商出货的ROM里面WebView也存在着很大的差异。更严重的是标准的WebView存在内存泄露的问题,看这里WebView causes memory leak - leaks the parent Activity。所以通常根治这个问题的办法是为WebView开启另外一个进程,通过AIDL与主进程进行通信,WebView所在的进程可以根据业务的需要选择合适的时机进行销毁,从而达到内存的完整释放。
6)注意Cursor对象是否及时关闭
在程序中我们经常会进行查询数据库的操作,但时常会存在不小心使用Cursor之后没有及时关闭的情况。这些Cursor的泄露,反复多次出现的话会对内存管理产生很大的负面影响,我们需要谨记对Cursor对象的及时关闭。
6.4 常用的内存检查工具。
(1)Memory Monitor 工具:
它是Android Studio自带的一个内存监视工具,它可以很好地帮助我们进行内存实时分析。通过点击Android Studio右下角的Memory Monitor标签,打开工具可以看见较浅蓝色代表free的内存,而深色的部分代表使用的内存从内存变换的走势图变换,可以判断关于内存的使用状态,例如当内存持续增高时,可能发生内存泄漏;当内存突然减少时,可能发生GC等,如下图所示。
(2)LeakCanary工具:
LeakCanary是Square公司基于MAT开发的一款监控Android内存泄漏的开源框架。其工作的原理是: 监测机制利用了Java的WeakReference和ReferenceQueue,通过将Activity包装到WeakReference中,被WeakReference包装过的Activity对象如果被回收,该WeakReference引用会被放到ReferenceQueue中,通过监测ReferenceQueue里面的内容就能检查到Activity是否能够被回收(在ReferenceQueue中说明可以被回收,不存在泄漏;否则,可能存在泄漏,LeakCanary是执行一遍GC,若还未在ReferenceQueue中,就会认定为泄漏)。
如果Activity被认定为泄露了,就抓取内存dump文件(Debug.dumpHprofData);之后通过HeapAnalyzerService.runAnalysis进行分析内存文件分析;接着通过HeapAnalyzer (checkForLeak—findLeakingReference—findLeakTrace)来进行内存泄漏分析。最后通过DisplayLeakService进行内存泄漏的展示。
(3)Android Lint 工具:
Android Lint Tool 是Android Sutido种集成的一个Android代码提示工具,它可以给你布局、代码提供非常强大的帮助。硬编码会提示以级别警告,例如:在布局文件中写了三层冗余的LinearLayout布局、直接在TextView中写要显示的文字、字体大小使用dp而不是sp为单位,就会在编辑器右边看到提示。
7 电量优化
电量重视度不够:开发中长时间连着手机,难以感知到电量变化
电量消耗线上难以量化
如何解决问题:
1、找特定场景专项测试:比如进入详情页操作一段时间,再看电量变化。
2、注册电量相关的广播:ACTION_BATTERY_CHANGED
1 IntentFilter intentFilter = new IntentFilter(Intent.ACTION_BATTERY_CHANGED);
2 mBatteryLowReceiver = new BatteryLowReceiver();
3 registerReceiver(mBatteryLowReceiver,intentFilter);
- 价值不大 针对手机整体的耗电量,而非特定的APP
- 实时性差,精度较低,被动通知。
Battery Historian(电量使用记录分析工具)
Battery Historian是Android 5.0开始引入的新API。通过下面的指令,可以得到设备上的电量消耗信息。
特点:
- 功能强大,推荐使用;
- 可视化展示指标:耗电比例、执行时间、次数;
- 只适合线下使用
使用步骤:
- 安卓Docker
- 执行命令 docker run -p :9999 gcr.io/android-battery-historian/stable:3.0 --port 9999,完成Battery Historian的安装
- 电量重置:adb shell dumpsys batterystats --reset
- 到出电量信息:adb bugreport bugreport.zip(过程可能会有点慢)
- 打开http://localhost:9999,上传bugreport文件即可进行分析
面试问题模拟
1.怎么做电量测试?
电量相关的测试相对难做一些,因为app在具体用户的耗电量无法统计,每个设备的硬件不一样,相关的功耗也不一样,且功耗值只能在线下拿到。只能尽可能监控来判断
分场景逐个击破:按照app功能进行针对性的专项测试,利用手机设置里面的电量消耗功能作为判断的依据,操作某个功能一段时间之后,看耗电量,直观,但精确性不行
Battery Historian : google推出的Android系统电量分析工具,5.0以后可用。拿到的电量信息精确也丰富很多。可以获取到详细的耗电组件:GPS、weakLock、蓝牙等的工作时间及耗电量。 可以比对优化前及优化后的电量信息。
但是这个工具只能在线下使用,因此需要线下测试后增加一些线上监控,比如耗电组件的使用次数,调用堆栈以及访问时间, 如果有用户在线上反馈,就可以通过这些信息来判断用户是否有耗电的操作。
2.有哪些有效的电量优化手段?
因为不能精确的统计线上电量消耗,因此需要尽可能线下优化好电量。
界面相关
离开界面后停止相关活动
耗电操作判断前台后台,如果后台就不操作(如动画,onresume中start onpause中cancel)
网络相关:
控制网络请求时机和次数;将可以延迟的网络请求批量发送
网络数据传输前进行数据压缩,减少时间,还能节约流量
禁止使用轮训方式做业务操作
不需要实时性的任务在连接wifi后在执行(wifi网络传输的电量消耗要比移动网络少很多)
定位相关(传感器相关)
根据场景谨慎选择定位模式
考虑网络定位代替GPS
使用后务必及时关闭,减少更新频率
WakeLock 相关
注意成对出现:acquire和release
使用带参数的acquire来设置超时时间,避免异常情况导致WakeLock无法释放
finally确保一定会被释放
JobScheduler
8.卡顿优化
9.稳定性优化
10.APP专项技术优化
7-《设计模式》
- 一、数组
- 1.稀疏数组
- 二、链表
- 三、队列
- 四、栈
- 五、树
- 5.1 完全二叉树
- 5.2 满二叉树:深度为k且有2^k-1个结点的二叉树称为满二叉树**
- 5.3 二叉排序树(二叉搜索树、二叉查找树)
- 5.4 平衡二叉树:
- 5.5 红黑树
- 六、堆
- 七、散列表(hash表)
- 八、图
- 1 启动优化
- 1.1.冷启动耗时统计?
- 1.2.TraceView和System Trace
- 1.3.优雅获取方法耗时
- 1.4.启动速度优化小技巧
- 1.5.启动优化之异步初始化
- 1.6.启动优化之异步初始化最优解—启动器
- 1.7.延迟初始化
- 1.8.其它方案
- 1.9.启动优化之模拟面试
- 2 布局优化
- 3 线程优化
- 3.1.线程调度原理
- 3.2.线程调度模型
- 3.3.线程使用准则:
- 4 网络优化
- 5 Apk瘦身—包体积优化
- 6 内存优化(非常重要)
- 6.1 Android 内存管理机制
- 6.2 Android的内存泄漏、内存溢出、内存抖动概念
- 6.3 如何避免OOM(内存泄漏优化)。
- 6.4 常用的内存检查工具。
- 7 电量优化
- 8.卡顿优化
- 9.稳定性优化
- 10.APP专项技术优化
- 1mvc/mvp/mvvm
- 2 常见设计模式
- 2.1.设计模式的六大原则:
- 2.2.单例模式
- 2.3.建造者模式
- 2.4.责任链模式
- 1.View的事件分发
- 2.Okhttp源码中的责任链模式
- 2.1 Inteceptor
- 2.2 Chain
- 2.5.观察者模式
- 1.各种控件的监听,如下:
- 2.Adapter的notifyDataSetChanged()方法
- 3. BroadcastReceiver
- 4.RxJava、RxAndroid、EventBus、otto等等,也是使用了观察者模式。
- 2.6.代理模式
- 2.7.策略模式
- 2.8.工厂模式
- 2.9.适配器模式
1mvc/mvp/mvvm
MVC:Model-View-Controller,是一种分层解偶的框架,Model层提供本地数据和网络请求,View层处理视图,Controller处理逻辑,存在问题是Controller层和View层的划分不明显,Model层和View层的存在耦合。
MVP:Model-View-Presenter,是对MVC的升级,Model层和View层与MVC的意思一致,但Model层和View层不再存在耦合,而是通过Presenter层这个桥梁进行交流。
MVVM:Model-View-ViewModel,不同于上面的两个框架,ViewModel持有数据状态,当数据状态改变的时候,会自动通知View层进行更新。
MVC和MVP的区别是什么?
MVP是MVC的进一步解耦,简单来讲,在MVC中,View层既可以和Controller层交互,又可以和Model层交互;而在MVP中,View层只能和Presenter层交互,Model层也只能和Presenter层交互,减少了View层和Model层的耦合,更容易定位错误的来源。
MVVM和MVP的最大区别在哪?
MVP中的每个方法都需要你去主动调用,它其实是被动的,而MVVM中有数据驱动这个概念,当你的持有的数据状态发生变更的时候,你的View你可以监听到这个变化,从而主动去更新,这其实是主动的。
严格来说这三种都不是设计模式,只能算是框架,或者一种思想。每种模式也没有严格定义,不同的人有不同的理解
2 常见设计模式
2.1.设计模式的六大原则:
- 单一原则:一个类或者一个方法只负责一项职责,尽量做到类的只有一个行为原因引起变化;
- 里氏替换原则:子类可以扩展父类的功能,但不能改变原有父类的功能;
- 依赖倒置原则:上层模块不应该依赖下层模块,两者应依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象;
- 接口隔离原则:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上面
- 迪米特原则:最少知道原则,尽量降低类与类之间的耦合;每个类尽量减少对其他类的依赖,减少对外暴露方法,使得功能模块独立,低耦合
- 开闭原则:对于扩展是开放的,对于修改是封闭的
总结:
单一职责原则告诉我们实现类要职责单一;
里氏替换原则告诉我们不要破坏继承体系;
依赖倒置原则告诉我们要面向接口编程;
接口隔离原则告诉我们在设计接口的时候要精简单一;
迪米特法则告诉我们要降低耦合;
而开闭原则是总纲,他告诉我们要对扩展开放,对修改关闭。
2.2.单例模式
关键点:某个类只能有一个实例,提供一个全局的访问点。
恶汉式:
public class SingleInstance {
//有一个静态属性instance,在JVM虚拟机装载类信息的时候,会new SingleInstance()对其进行初始化。
//线程安全,但是没有延迟加载,浪费资源
private SingleInstance() {}//构造函数私有化
private final static SingleInstance instance=new SingleInstance();
public static SingleInstance getInstance() {
return instance;
}
}
懒汉式
public class SingleInstance {
private SingleInstance() {}
private static SingleInstance instance;
public static SingleInstance getInstance() {
//假如2个线程同时进入if 语句,会创建两个对象,线程不安全.
if (instance==null){
instance=new SingleInstance();
}
return instance;
}
}
改进:
public class SingleInstance {
private SingleInstance() {}
private static SingleInstance instance;
public static synchronized SingleInstance getInstance() {
if (instance==null){
instance=new SingleInstance();
}
return instance;
}
}
//或者
public class SingleInstance {
private SingleInstance() {}
private static SingleInstance instance;
public static SingleInstance getInstance() {
synchronized(SingleInstance.class){
if (instance==null){
instance=new SingleInstance();
}
}
return instance;
}
}
synchronized 是比较耗费性能的,我们每次调用这个 getInstance()方法的时候,都会进入 synchronized 包裹的代码块内,即使这个时候单例对象已经生成,不再需要创建对象也会进入 synchronized 内部,造成不必要的同步开销。
双重锁定(DCL模式)(重要)
public class SingleInstance {
private SingleInstance() {}
private static SingleInstance instance;
public static SingleInstance getInstance() {
if (instance==null){
synchronized(SingleInstance.class){
if (instance==null){
instance=new SingleInstance();
}
}
}
return instance;
}
}
看起来已经能够实现懒加载和线程安全了,但是还存在一个问题,那就是没有考虑到 JVM 编译器的指令重排序.
DCL模式会有什么问题?
对象生成实例的过程中,大概会经过以下过程:
- 1.为对象分配内存空间。
- 2.初始化对象中的成员变量。
- 3.将对象指向分配的内存空间(此时对象就不为null)。
由于Jvm会优化指令顺序,也就是说2和3的顺序是不能保证的。在多线程高并发的情况下,当一个线程完成了1、3过程后,当前线程的时间片已用完,这个时候会切换到另一个线程,另一个线程调用这个单例,会使用这个还没初始化完成的实例。
解决方法是使用volatile关键字:
优化后的DCL模式(非常重要)
public class SingleInstance {
private static volatile SingleInstance instance;//volatile 可以禁止指令重排序
private SingleInstance() {}
public static SingleInstance getInstance() {
if(instance == null) {
synchronized (SingleInstance.class) {
if(instance == null) {
instance = new SingleInstance();
}
}
}
return instance;
}
}
上面的分析,会发现懒加载和线程安全是我们自己通过加锁和 volatile 关键字实现的,那么有没有让 JVM 帮我们实现线程安全和懒加载呢?
静态内部类单例(非常重要)
public class SingleInstance {
private SingleInstance() {}
public static SingleInstance getInstance() {
return SingleHolder.instance;
}
private static class SingleHolder{
//静态初始化器,由JVM来保证线程安全
private static final SingleInstance instance = new SingleInstance();
}
}
首先在 JVM 进行类加载的时候,只是加载了 SingleInstance 类,并不会去执行其中的静态方法,也不会去加载 SingleInstance 内的静态内部类 SingleHolder。所以也就是并不会在初次类加载的时候创建单例对象。
在我们使用getInstance()的时候,我们使用 SingleHolder的静态属性,这个时候会对 SingleHolder 这个静态内部类进行加载,这个时候,就回到了第一种写法 饿汉式中的原理,在类加载的初始化阶段,会对创建单例对象,并且赋值给 INSTANCE 属性。同样,这些操作是发生在类加载阶段的,由 JVM 保证了线程安全,并且是在使用的时候进行加载的,也实现了懒加载。
缺点就是:初始化的时候没法传值给单例类。这个时候就可以使用上面优化后的DCL模式。
枚举单例
public enum SingletonEnum {
INSTANCE
}
// 获取单例对象
SingletonEnum .INSTANCE// 假如枚举类中有一个方法 getString(),就可以这样调用
SingletonEnum .INSTANCE.getString()
缺点:
不能懒加载
运行时占用内存比非枚举的大很多
2.3.建造者模式
关键点:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示,适用于初始化的对象比较复杂且参数较多的情况。
当一个类的构造函数参数个数超过4个,而且这些参数有些是可选的参数,考虑使用构造者模式。
Retrofit 和 OkHttp 等开源库,大多都是采用的构造者模式去实现的。
如何实现:假设要创建一个Computer对象:
- 1.在Computer中创建一个静态内部类Builder,然后将Computer中的参数都复制到Builder类中。
- 2.在Computer中创建一个private的构造函数,参数为Builder类型
- 3.在Builder中创建一个public的构造方法,参数为Computer中必填的那些参数,cpu和ram。
- 4在Builder中创建设置方法,对Computer中那些可选参数进行赋值,返回值为Builder类型的实例
- 5在Builder中创建一个build()方法,在其中构建Computer的实例并返回
public class Computer {
private final String cpu;//必须
private final String ram;//必须
private final int usbCount;//可选
private final String keyboard;//可选
private final String display;//可选
private Computer(Builder builder){
this.cpu=builder.cpu;
this.ram=builder.ram;
this.usbCount=builder.usbCount;
this.keyboard=builder.keyboard;
this.display=builder.display;
}
public static class Builder{
private String cpu;//必须
private String ram;//必须
private int usbCount;//可选
private String keyboard;//可选
private String display;//可选
public Builder(String cup,String ram){
this.cpu=cup;
this.ram=ram;
}
public Builder setUsbCount(int usbCount) {
this.usbCount = usbCount;
return this;
}
public Builder setKeyboard(String keyboard) {
this.keyboard = keyboard;
return this;
}
public Builder setDisplay(String display) {
this.display = display;
return this;
}
public Computer build(){
return new Computer(this);
}
}
//省略getter方法
}
使用:
Computer computer=new Computer.Builder("因特尔","三星")
.setDisplay("三星24寸")
.setKeyboard("罗技")
.setUsbCount(2)
.build();
2.4.责任链模式
关键点:将请求的发送者和接收者解耦,使的多个对象都有处理这个请求的机会。
举例:
1.View的事件分发
- a). 事件收集之后最先传递给 Activity, 然后依次向下传递,大致如下:
Activity -> PhoneWindow -> DecorView -> ViewGroup -> ... -> View
- b). 如果没有任何View消费掉事件,那么这个事件会按照反方向回传,最终传回给Activity,如果最后 Activity 也没有处理,本次事件才会被抛弃:
Activity <- PhoneWindow <- DecorView <- ViewGroup <- ... <- View
这是一个非常经典的责任链模式,如果我能处理就拦截下来自己干,如果自己不能处理或者不确定就交给责任链中下一个对象。
2.Okhttp源码中的责任链模式
OkHttp 的拦截器就是基于责任链模式,每个节点有自己的职责,同时可以选择是否把任务传递给下一个环节
2.1 Inteceptor
主要方法 Intercept。会传递一个 Chain 对象过来,可以在 Chain 在执行 proceed 的前后添加代码。
2.2 Chain
主要方法 proceed。OkHttp 的唯一实现类是 RealInterceptorChain。内部维护了所有要执行的拦截器列表,在 proceed 内部会唤醒下一个 Interceptor ,调用 intercept 来进行下一步:
public Response proceed(Request request, StreamAllocation streamAllocation, HttpStream httpStream,
Connection connection) throws IOException {
...
RealInterceptorChain next = new RealInterceptorChain(
interceptors, streamAllocation, httpStream, connection, index + 1, request);
Interceptor interceptor = interceptors.get(index);
Response response = interceptor.intercept(next);
...
return response;
}
可以看到,RealInterceptorChain的process方法中,会生成一个RealInterceptorChain对象,且注意到index+1,即生成下一个Chain对象,并且同时获取拦截器集合里的下一个拦截器,调用它的intercept,将下一个Chain(next)作为参数传给他去处理,回顾到刚才上面说的,拦截器的interpect里面调用了chain的process,也就是说,每一个拦截器都会持有下一个拦截器的chain对象,并通过chain的process方法,触发RealInterceptorChain里的index下标再+1,从而串联起整个拦截链。
2.5.观察者模式
关键点:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。(被观察者可以添加一堆观察者,被观察着发生变化,观察者做出响应)
Android中我们遇到的最常用的观察者模式
1.各种控件的监听,如下:
//注册观察者
button.setOnClickListener(new View.OnClickListener() {
//观察者实现
@Override
public void onClick(View arg0) {
Log.d("test", "Click button ");
}
});
button就是被观察者;new出来的View.OnClickListenerd对象就是具体的观察者。在这里OnClickListener是个接口,也就是抽象观察者;通过setOnClickListener把观察者注册到被观察者中。
一旦button捕获的点击事件就会通过回调注册的OnClickListener观察者的onClick方法会来通知观察者。
2.Adapter的notifyDataSetChanged()方法
当我们使用ListView时,需要更新数据时我们就会调用Adapter的notifyDataSetChanged()方法,那么我们来看看notifyDataSetChanged()的实现原理,这个方法是定义在BaseAdaper中,具体代码如下:
public abstract class BaseAdapter implements ListAdapter, SpinnerAdapter {
//数据集被观察者
private final DataSetObservable mDataSetObservable = new DataSetObservable();
//注册观察者
public void registerDataSetObserver(DataSetObserver observer) {
mDataSetObservable.registerObserver(observer);
}
//注销观察者
public void unregisterDataSetObserver(DataSetObserver observer) {
mDataSetObservable.unregisterObserver(observer);
}
//数据集改变时,通知所有观察者
public void notifyDataSetChanged() {
mDataSetObservable.notifyChanged();
}
}
//其他代码略
上面的代码可以看出BaseAdapter实际上就是使用了观察者模式,BaseAdapter就是具体的被观察者。接下来看看 mDataSetObservable.notifyChanged()的实现:
//数据集被观察者
public class DataSetObservable extends Observable<DataSetObserver> {
public void notifyChanged() {
synchronized(mObservers) {
//遍历所有观察者,并调用他们的onChanged()方法
for (int i = mObservers.size() - 1; i >= 0; i--) {
mObservers.get(i).onChanged();
}
}
}
//其他代码略
}
AdapterDataSetObserver类中的onChanged()方法没看出啥,继续看他父类的onChanged()方法:
class AdapterDataSetObserver extends DataSetObserver {
private Parcelable mInstanceState = null;
//观察者的核心实现
@Override
public void onChanged() {
mDataChanged = true;
mOldItemCount = mItemCount;
mItemCount = getAdapter().getCount();//获取Adapter中的数据的数量
if (AdapterView.this.getAdapter().hasStableIds() && mInstanceState != null
&& mOldItemCount == 0 && mItemCount > 0) {
AdapterView.this.onRestoreInstanceState(mInstanceState);
mInstanceState = null;
} else {
rememberSyncState();
}
checkFocus();
//重新布局
requestLayout();
}
//其他代码略
}
最终就是在AdapterDataSetObserver这个类里面的**onChanged()**方法中实现了布局的更新。
简单总结:
当ListView的数据发生变化时,我们调用Adapter的notifyDataSetChanged()方法,这个方法又会调用所有观察者(AdapterDataSetObserver)的onChanged()方法,onChanged()方法又会调requestLayout()方法来重新进行布局。
3. BroadcastReceiver
4.RxJava、RxAndroid、EventBus、otto等等,也是使用了观察者模式。
2.6.代理模式
为其他的对象提供一种代理以控制对这个对象的访问。适用于当无法或不想直接访问某个对象时通过一个代理对象来间接访问,为了保证客户端使用的透明性,委托对象与代理对象需要实现相同的接口。
静态代理:
静态代理很好理解就是我们需要编写一个代理类。实现我们需要代理的所有方法。所以称之为静态代理。
动态代理:
在java的动态代理机制中,有两个重要的类或接口
一个是 InvocationHandler(Interface),另一个则是Proxy(Class),这一个类和接口是实现我们动态代理所必须用到的
Proxy这个类的 newProxyInstance 这个方法:
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
oader:一个ClassLoader对象,定义了由哪个ClassLoader对象来对生成的代理对象进行加载
interfaces:一个Interface对象的数组,表示的是我将要给我需要代理的对象提供一组什么接口,如果我提供了一组接口给它,那么这个代理对象就宣称实现了该接口(多态),这样我就能调用这组接口中的方法了
一个InvocationHandler对象,表示的是当我这个动态代理对象在调用方法的时候,会关联到哪一个InvocationHandler对象上。
InvocationHandler:
public interface InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
}
proxy:指代生成的代理对象;
method:指代的是我们所要调用真实对象的某个方法的Method对象;
args:指代的是调用真实对象某个方法时接受的参数;
每一个代理实例类的InvocationHandler 都要实现InvocationHandler这个接口。并且每个代理类的实例都关联到了一个handler,当我们通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由InvocationHandler这个接口的invoke 方法来进行调用
示例:
// 定义相关接口
public interface BaseInterface {
void doSomething();
}
// 接口的相关实现类
public class BaseImpl implements BaseInterface {
@Override
public void doSomething() {
System.out.println("doSomething");
}
}
public static void main(String args[]) {
BaseImpl base = new BaseImpl();
// Proxy 动态代理实现
BaseInterface proxyInstance = (BaseInterface) Proxy.newProxyInstance(base.getClass().getClassLoader(), base.getClass().getInterfaces(), new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals("doSomething")) {
method.invoke(base, args);
System.out.println("do more");
}
return null;
}
});
proxyInstance.doSomething();
}
2.7.策略模式
关键点:定义了一系列的算法,并封装起来,提供针对同一类型问题的多种处理方式。
应用场景
同一个问题具有不同算法时,即仅仅是具体的实现细节不同时,如各种排序算法等等。
对客户隐藏具体策略(算法)的实现细节,彼此完全独立;提高算法的保密性与安全性。
一个类拥有很多行为,而又需要使用if-else或者switch语句来选择具体行为时。使用策略模式把这些行为独立到具体的策略类中,可以避免多重选择的结构。
Android中的源码分析:用的ListView时都需要设置一个Adapter,而这个Adapter根据我们实际的需求可以用ArrayAdapter、SimpleAdapter等等,这里就运用到策略模式。
listView = (ListView)findViewById(R.id.list_view);
//使用ArrayAdapter
listView.setAdapter(new ArrayAdapter<String>(this,R.id.item,
new String[] {"one","two"}));
//使用BaseAdapter
listView.setAdapter(new BaseAdapter() {
@Override
public int getCount() {
return 0;
}
@Override
public Object getItem(int position) {
return null;
}
.....
});
相关源码:
public class ListView extends AbsListView {//相当于环境类
@Override
public void setAdapter(ListAdapter adapter) {//设置策略,即adapter
//其他代码略
}
}
public interface ListAdapter extends Adapter {//抽象策略接口
}
//具体策略类BaseAdapter,实现ListAdapter接口
public abstract class BaseAdapter implements ListAdapter, SpinnerAdapter {
}
//具体策略类ArrayAdapter,继承BaseAdapter,即实现ListAdapter接口
public class ArrayAdapter<T> extends BaseAdapter implements Filterable, ThemedSpinnerAdapter {
}
通过设置不同的Adapter(即不同的策略),我们就可以写出符合我们需求的ListView布局。
另外,动画中的插值器(ValueAnimator 的 setInterpolator 方法)也是有运用到策略模式。
2.8.工厂模式
工厂模式分为三种 :简单工厂模式 、工厂方法模式 、抽象工厂模式 。
简单工厂模式:
//抽象产品类
public abstract class Product {
public abstract void show();
}
//具体产品类A
public class ProductA extends Product {
@Override
public void show() {
System.out.println("product A");
}
}
//具体产品类B
public class ProductB extends Product {
@Override
public void show() {
System.out.println("product B");
}
}
//具体产品类A
public class ProductA extends Product {
@Override
public void show() {
System.out.println("product A");
}
}
//具体产品类B
public class ProductB extends Product {
@Override
public void show() {
System.out.println("product B");
}
}
//创建工厂类,创建具体的产品:
public class Factory {
public static Product create(String productName) {
Product product = null;
//通过switch语句控制生产哪种商品
switch (productName) {
case "A":
product = new ProductA();
break;
case "B":
product = new ProductB();
break;
}
return product;
}
}
public void test() {
Factory.create("A").show();//生产ProductA
Factory.create("B").show();//生产ProductB
try {
Factory.create("C").show();//生产ProductC
} catch (NullPointerException e) {
System.out.println("没有ProductC");//没有ProductC,会报错
}
}
缺点
-
1.违背开放封闭原则,若需添加新产品则必须修改工厂类逻辑,会造成工厂逻辑过于复杂。
-
2.简单工厂模式使用了静态工厂方法,因此静态方法不能被继承和重写。
-
3.工厂类包含了所有实例(产品)的创建逻辑,若工厂类出错,则会造成整个系统都会会受到影响。
工厂方法模式与简单工厂模式比较 -
1.工厂方法模式有抽象工厂类,简单工厂模式没有抽象工厂类且其工厂类的工厂方法是静态的。
-
2.工厂方法模式新增产品时只需新建一个工厂类即可,符合开放封闭原则;而简单工厂模式需要直接修改工厂类,违反了开放封闭原则。
工厂方法模式
创建抽象产品类,定义公共接口:
//抽象产品类
public abstract class Product {
public abstract void show();
}
创建具体产品类,继承Product类:
//具体产品类A
public class ProductA extends Product {
@Override
public void show() {
System.out.println("product A");
}
}
//具体产品类B
public class ProductB extends Product {
@Override
public void show() {
System.out.println("product B");
}
}
创建抽象工厂类,定义公共接口:
//抽象工厂类
public abstract class Factory {
public abstract Product create();
}
创建具体工厂类,继承抽象工厂类,实现创建具体的产品:
//具体工厂类A
public class FactoryA extends Factory {
@Override
public Product create() {
return new ProductA();//创建ProductA
}
}
//具体工厂类B
public class FactoryB extends Factory {
@Override
public Product create() {
return new ProductB();//创建ProductB
}
}
public void test() {
//产品A
Factory factoryA = new FactoryA();
Product productA = factoryA.create();
productA.show();
//产品B
Factory factoryB = new FactoryB();
Product productB = factoryB.create();
productB.show();
}
应用场景
生成复杂对象时,无需知道具体类名,只需知道相应的工厂方法即可。
优点
符合开放封闭原则。新增产品时,只需增加相应的具体产品类和相应的工厂子类即可。
符合单一职责原则。每个具体工厂类只负责创建对应的产品。
Android中的ThreadFactory就是使用了工厂方法模式来生成线程的,线程就是ThreadFactory的产品。
ThreadFactory相关源码分析
//抽象产品:Runnable
public interface Runnable {
public abstract void run();
}
//具体产品:Thread
public class Thread implements Runnable {
//构造方法
public Thread(Runnable target, String name) {
init(null, target, name, 0);
}
@Override
//实现抽象产品的抽象方法
public void run() {
if (target != null) {
target.run();
}
}
//其他代码略
}
//抽象工厂:ThreadFactory
public interface ThreadFactory {
Thread newThread(Runnable r);
}
//具体工厂:AsyncTask中的实现
private static final ThreadFactory sThreadFactory = new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
//实现抽象工厂的抽象方法
public Thread newThread(Runnable r) {
return new Thread(r, "AsyncTask #" + mCount.getAndIncrement());//返回Thread这个产品
}
};
通过ThreadFactory,我们可以创建出不同的Thread来。
同样,我们可以创建另外类似的工厂,生产某种专门的线程,非常容易扩展。
抽象工厂模式
创建抽象产品类
//抽象产品类-- CPU
public abstract class CPU {
public abstract void showCPU();
}
//抽象产品类-- 内存
public abstract class Memory {
public abstract void showMemory();
}
//抽象产品类-- 硬盘
public abstract class HD {
public abstract void showHD();
}
创建具体产品类
//具体产品类-- Intet CPU
public class IntelCPU extends CPU {
@Override
public void showCPU() {
System.out.println("Intet CPU");
}
}
//具体产品类-- AMD CPU
public class AmdCPU extends CPU {
@Override
public void showCPU() {
System.out.println("AMD CPU");
}
}
//具体产品类-- 三星 内存
public class SamsungMemory extends Memory {
@Override
public void showMemory() {
System.out.println("三星 内存");
}
}
//具体产品类-- 金士顿 内存
public class KingstonMemory extends Memory {
@Override
public void showMemory() {
System.out.println("金士顿 内存");
}
}
//具体产品类-- 希捷 硬盘
public class SeagateHD extends HD {
@Override
public void showHD() {
System.out.println("希捷 硬盘");
}
}
//具体产品类-- 西部数据 硬盘
public class WdHD extends HD {
@Override
public void showHD() {
System.out.println("西部数据 硬盘");
}
}
创建抽象工厂类:定义工厂中用来创建不同产品的方法:
//抽象工厂类,电脑工厂类
public abstract class ComputerFactory {
public abstract CPU createCPU();
public abstract Memory createMemory();
public abstract HD createHD();
}
public void test() {
System.out.println("--------------------生产联想电脑-----------------------");
ComputerFactory lenovoComputerFactory = new LenovoComputerFactory();
lenovoComputerFactory.createCPU().showCPU();
lenovoComputerFactory.createMemory().showMemory();
lenovoComputerFactory.createHD().showHD();
System.out.println("--------------------生产华硕电脑-----------------------");
ComputerFactory asusComputerFactory = new AsusComputerFactory();
asusComputerFactory.createCPU().showCPU();
asusComputerFactory.createMemory().showMemory();
asusComputerFactory.createHD().showHD();
System.out.println("--------------------生产惠普电脑-----------------------");
ComputerFactory hpComputerFactory = new HpComputerFactory();
hpComputerFactory.createCPU().showCPU();
hpComputerFactory.createMemory().showMemory();
hpComputerFactory.createHD().showHD();
}
--------------------生产联想电脑-----------------------
Intet CPU
三星 内存
希捷 硬盘
--------------------生产华硕电脑-----------------------
AMD CPU
金士顿 内存
西部数据 硬盘
--------------------生产惠普电脑-----------------------
Intet CPU
金士顿 内存
西部数据 硬盘
应用场景
生产多个产品组合的对象时。
优点
代码解耦,创建实例的工作与使用实例的工作分开,使用者不必关心类对象如何创建。
缺点
如果增加新的产品,则修改抽象工厂和所有的具体工厂,违反了开放封闭原则
工厂方法模式与抽象工厂模式比较
在工厂方法模式中具体工厂负责生产具体的产品,每一个具体工厂对应一种具体产品,工厂方法具有唯一性。
抽象工厂模式则可以提供多个产品对象,而不是单一的产品对象。





![[组合数学] 排列组合](https://img-blog.csdnimg.cn/d90a375b08144ba18b660c491d036e2c.png)