Sharding-JDBC分库分表
一 分库分表概述
分库分表,就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分为若干数据表组成,使得单一数据库,单一数据表的数据量变小,从而达到提升数据库性能的目的。
1.垂直分表
将一个表,按照字段分成多个表,每个表存储其中一部分字段,这种分表方式,称之为垂直分表。
一般情况下,垂直分表时,可以按照字段的使用评率高低来进行划分。
它所带来的优点是:
- 避免了IO争抢并减少锁表的几率,在查看部分数据时,与另一部分不常用的数据互不影响。
- 提升热门数据的操作效率,高效率数据不会被低效率数据所拖累。
大字段IO的效率低,第一是因为数据库本身数据量大,需要更长的读取时间。第二是跨页,页是数据库存储单位,很多查找和定位操作都是以页为单位,单页内的数据行数据越多,数据库整体性能较好,而大字段占用空间大,单页内存储数据行数少,因此IO效率低。第三是数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存中可以加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库的性能
2.垂直分库
垂直分库是指,按照业务将表进行划分,分布到不同的数据库上,每个库都可以放到不同的服务器上,它的核心理念是专库专用。
它所带来的优点是:
- 解决业务层面的耦合,业务清晰
- 能对不同的业务数据进行分级管理,维护,监控,扩展等
- 高并发场景下,垂直分库在一定程度上能够提升IO、数据库连接数、降低单机硬件资源的消耗。
垂直分库通过将业务分类,然后分布在不同的数据库,并且可以将这些数据库部署在不同的服务器上,从而达到多个服务器共同分担压力的效果,但是依然没有解决单表数据量过大的问题。
简单来说,垂直分库并不是为了解决单表数据量过大的问题
3.水平分库
水平分库,是把同一个数据表中的数据,按照一定的规则拆分到不同的数据库中,每个数据库都可以放在不同的服务器上。
当一个应用难以再以粒度垂直切分,或切分后数据量行数巨大,存在单库读写,性能存储瓶颈,这时候就需要进行水平分库了。经过水平切分的优化,往往能解决单库存储量及性能瓶颈,单由于同一个表被划分到不同的数据库,需要额外进行数据库操作的路由,因此大大提升了系统复杂度。
它所带来的提升是:
- 解决了单库大数据,高并发的性能瓶颈
- 提高了系统的稳定性及可用性(稳定性体现在IO冲突减少,锁表减少。可用性是指某个库出问题,其他的库仍然可用)
4.水平分表
水平分表,是在同一个数据库内,把同一个表的数据按照一定的规则拆分到多个表中
它所带来的优点是:
- 优化单一数据表因为数据量过大而导致性能问题
- 避免IO争抢,减少锁表几率
5.总结
- 垂直分表: 按字段访问频次、是否大字段等原则,将原先的大表拆分为多个小表,从而提升数据库性能 。垂直分表会导致表结构改变,所以拆分时尽量从业务角度出发,避免联查,否则得不偿失。
- 垂直分库:可以按照数据表业务,将相同业务的表拆分到多个数据库,这些数据库可以分布在不同的服务器上。这个过程中,表结构不发生改变。拆分之后,压力被多个服务器分别承担,从而提升访问数据,同时可以提高业务清晰度。但它需要解决跨库所带来的所有复杂问题。
- 水平分库:可以把一个数据表中的数据,按照一定的规则拆分到不同的数据库中,这些数据库可以分布在不同的服务器上,从而减少单表压力。这个过程中,数据库的表结构不发生改变。
- 水平分表:把一个数据表中的数据按照一定规则,拆分到多个表中,从而减少单表的数据量,减少查询压力。
一般来说,在系统设计阶段就应该根据自己的业务耦合松紧来确定垂直分库,垂直分表方案。在数据库及压力压力不是特别大的情况下,首先考虑缓存,读写分离,索引等技术方案。若数据量极大,且持续增长,再考虑水平分库和水平分表。
6 分库分表带来的问题
- 事务的一致性(由于分库分表把数据分布在不同的服务器数据库上,所以不可避免的带来了分布式事务的问题)
- 跨节点联查问题(分多次查询,然后组合数据。在业务中实现)
- 跨节点分页,排序问题
- 主键避免重复问题
- 公共表
二 Sharing-JDBC初步使用
Sharing-JDBC是一个轻量级的Java框架,在Java的JDBC层提供额外的服务,使用客户端直连数据库,以 jar包形式提供服务,无需额外部署和依赖。
Sharing-JDBC的核心功能是数据分片和读写分离
通过Sharing-JDBC,应用可以透明的使用JDBC访问已经分库分表,读写分离的多个数据源,而不用关心数据源的数据量及数据如何分布。
1.准备数据库
创建一个名为 order_db 的数据库,然后再创建两张订单表,分别为t_order_1,t_order_2。
创建数据库:
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
创建数据表:
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2.引入sharding-jdbc
在maven项目中的pom.xml文件中,引入sharding-jdbc
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
3.数据插入演示
本示例使用 MySQL + MybatisPlus 实现,部分代码不展示,此处仅展示关键代码
以下是application.yml中关于sharding-jdbc的配置内容,及部分 mybatis-plus的配置内容
spring:
main:
#s允许Bean重复定义覆盖
allow-bean-definition-overriding: true
shardingsphere:
datasource:
#数据源名称,多个数据源时使用逗号(,)分割
names: master
master:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
sharding:
tables:
t_order:
#配置数据节点,m1.t_order_1,m1.t_order_2
actual-data-nodes: m1.t_order_$->{1..2}
key-generator:
#配置主键,及主键生成算法
column: order_id
# 雪花算法
type: SNOWFLAKE
table-strategy:
inline:
# 配置分片键
sharding-column: order_id
# 配置分片策略( order_id % 2 + 1 的值就是数据实际要进入的数据表 )
# 利用“取模”计算的方式进行分片,将分片键除以分片表的个数,得到的模就是该数据要进入的数据表
# 示例中,共有2张分片表,则此处求取分片键的值与分片表的模数,表示为 order_id % 2,又因为分片表的初始值以 1 开始,则再加上1
algorithm-expression: t_order_$->{order_id % 2 + 1}
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 配置数据库字段与实体类映射方式,是否是小驼峰命名法
map-underscore-to-camel-case: true
global-config:
db-config:
# 配置数据表前缀
table-prefix: t_
解释说明:
- 利用“取模”计算的方式进行分片,将分片键除以分片表的个数,得到的模就是该数据要进入的数据表
- 示例中,共有2张分片表,则此处求取
分片键的值与分片表数量的模数,表示为 order_id % 2,又因为分片表的初始值以 1 开始,则再加上1
编写测试用例进行测试:
@Test
public void testOrderInsert(){
for (int i = 0; i < 10; i++) {
Order order=new Order();
order.setStatus("正常");
order.setPrice(new BigDecimal(20));
order.setUserId(1L);
boolean save = orderService.save(order);
System.out.println(save);
}
}
运行之后,在数据库中查看结果
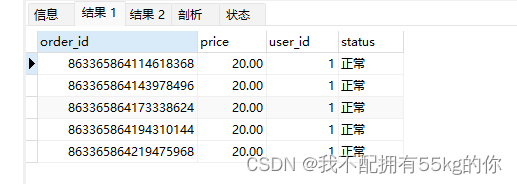
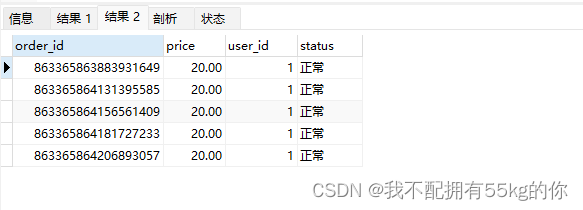
可以看到,数据已经被平均分配到t_order_1和t_order_2中,t_order_1中主键的末尾值均为偶数,而t_order_2中均为奇数。
这种平均分配的情况其实是比较少的,因为很多时候可能会连续生成多个主键Id为偶数或奇数的情况,当数据量越多,它们之间数据量越接近相等
4.数据查询演示
@Test
public void testSelectOrderList(){
LambdaQueryWrapper<Order> wrapper= Wrappers.lambdaQuery();
List<Long> ids=new ArrayList<>();
ids.add(863365864114618368L);
ids.add(863365864206893057L);
wrapper.in(Order::getOrderId,ids);
List<Order> list = orderService.list(wrapper);
for (Order order : list) {
System.out.println(order.toString());
}
}
注意观察一下日志,程序中执行的SQL为:
SELECT order_id,price,user_id,status FROM t_order
经过Sharding-JDBC的计算,实际在数据库中执行的SQL为:
SELECT order_id,price,user_id,status FROM t_order_1;
SELECT order_id,price,user_id,status FROM t_order_2;

最后将两张表的数据拼合起来,就得到了我们的全部数据。
当使用分片键作为条件查询单条数据时,Sharding-JDBC会先确定好去查哪张表,然后直接去表中查询。但是如果是多条件或者查询多个时,则会查询分片键所在的全部表,以上示例中,因为两个Id值分布在两张表中,因此,查询了两张分片表
5.流程分析
在整个执行过程中,Sharding-JDBC具体做了一下几件事情:
- 解析SQL,获取分片键,本示例中,使用的是 order_id
- Sharding-JDBC通过分片规则
t_order_$->{order_id % 2 + 1},知道了当order_id为偶数时,数据存储在 t_order_1,反之,在 t_order_2。 - 根据配置规则,开始改写SQL语句
- 执行真实的SQL语句
- 如果是查询,则在执行完成后,会将结果汇总。增,删,改操作则只返回操作结果。
三 Sharding-JDBC执行原理
1.相关概念
- 逻辑表:水平拆分的数据表的总称,例如 t_order_1,t_order_2,他们的逻辑表明为 t_order
- 真实表:在分片的数据库中真实存在的数据表,例如 t_order_1,t_order_2
- 数据节点:数据分片的最小物理单元,由数据源名称和数据表组成,例如 db_01.t_order_1
- 绑定表:指分片规则一致的主表和子表,例如 t_order 和 t_order_detail ,均按照 order_id 进行水平分片,绑定表之间的分片键完全相同,则此两张表称之为绑定表。绑定表之间不会出现笛卡尔积关联,关联查询效率也很高。
- 公共表:所有分库中都需要的数据表。例如 字典表
- 分片键:用于分片的数据库字段,是将数据库分片的关键字段
- 分片算法:通过分片算法将数据分片
- 分片策略:分片算法+分片键组合起来,构成了分片策略,内置的分片策略包含尾数取模,哈希,范围,标签,时间等等。
- 自增主键生成策略:通过在客户端自增主键以替换数据库原生自增主键的方式,以做到分布式主键无重复
2.执行原理
四 水平分库
1.准备工作
前面已经实现了水平分表,下面主要介绍水平分库。
将原先的 order_db 分为两个数据库,分别为 order_db_1,order_db_2,每个库中仍然有两张表

2.配置多个数据源
修改分片规则,由于数据库拆分成了两个,这里需要配置两个数据源
spring:
shardingsphere:
datasource:
#数据源名称
names: master1,master2
master1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db_1?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
master2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db_2?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
sharding:
tables:
# 逻辑表名
t_order:
key-generator:
column: order_id
type: SNOWFLAKE
# 划重点,此处配置分库策略
database-strategy:
# 这里的分片策略使用的是 inline
inline:
# 定义分片键,此处使用 另一个字段值 user_id 作为分片键
sharding-column: user_id
# 定义分片规则(user_id % 2 + 1),值为 1 使 进入 master1,值为 2 时,进入master2
algorithm-expression: master$->{user_id % 2 + 1}
# 配置分表策略
table-strategy:
inline:
# 定义分片键
sharding-column: order_id
# 定义分片策略
algorithm-expression: t_order_$->{order_id % 2 + 1}
以上示例的介绍,使用 user_id 决定数据落在哪个数据库,使用 order_id 决定数据落在指定库的哪张表
关于分片策略的介绍:
-
standard:标准分片策略,对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的
分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和
RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置
RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
-
complex:符合分片策略,对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和
BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复
杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发
者实现,提供最大的灵活度。
-
inline:行表达式分片策略,对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和
IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java
代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为 t_user_0 到
t_user_7 。
-
hint:Hint分片策略,对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。对于分片字段
非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工
登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
-
none:不分片策略,对应NoneShardingStrategy。不分片的策略。
五 垂直分库
垂直分库是指按照业务表进行分类,将数据分布在不同的数据库上面
垂直分库的核心理念:业务分离,专库专用
1.准备数据库
准备一个新的 user_db,将用户数据存储到另一个数据库:
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`fullname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户姓名',
`user_type` char(1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2.配置分库规则
前边的水平分库示例配置省略,以下以 master3 数据源为例,配置 垂直分库
spring
shardingsphere:
datasource:
#数据源名称,
names: master1,master2,master3
master3:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/user_db?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
sharding:
tables:
# 逻辑表明
t_user:
# 配置数据节点
actual-data-nodes: master3.t_user
# 配置主键以及主键算法
key-generator:
type: SNOWFLAKE
column: user_id
t_order:
# 关于 t_order 的配置此处省略,与前边保持不变即可
3.编写测试用例
@Resource
private UserService userService;
@Test
public void testInsertUser(){
User user=new User();
user.setUserType("1");
user.setFullname("肖恩");
boolean save = userService.save(user);
System.out.println(save);
}
六 公共表
公共表属于系统中数据量小,变动少,但是却高频联合查询的表,参数表,字典表等属于此类型。可以将此类表在每个数据库中存储一份,所有更新操作将同时发送到所有分库执行。
Sharding-JDBC将提供关于公共表的所有操作,在配置完公共表之后,所有对公共表的增删改操作,将会同时分发到所有的分库。
1.准备工作
在 user_db,order_db_1,order_db_2中分表创建字典表 t_dict
CREATE TABLE `t_dict` (
`dict_id` bigint(20) NOT NULL COMMENT '字典id',
`type` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典类型',
`code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典编码',
`value` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',
PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2.配置公共表规则
spring:
shardingsphere:
datasource:
#数据源名称
names: master1,master2,master3
master1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db_1?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
master2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db_2?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
master3:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/user_db?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
sharding:
# 通过 broadcast-tables 配置公共表(广播表),公共表指定
broadcast-tables: t_dict
注意,broadcast-tables 绑定多个龚波表时,使用以下格式:
spring:
shardingsphere:
sharding:
# 通过 broadcast-tables 配置公共表(广播表),公共表指定
broadcast-tables:
- t_dict
- t_config
编写测试代码:
@Resource
private DictService dictService;
@Test
public void testInsert(){
Dict dict=new Dict();
dict.setCode("1001");
dict.setType("1");
dict.setValue("颜值");
boolean save = dictService.save(dict);
System.out.println(save);
}
经过以上配置,在对 t_dict 表进行增删改操作时,数据将同步到配置好的三个数据源中
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r0D4SVc9-1684464163610)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230512142337196.png)]
七 读写分离
面对日益增加的系统访问量,数据库的吞吐量面临着一个巨大瓶颈。对于同一时刻有大量并发读操作和少量写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责增删改,从库负责查询,这能够有效的避免由数据更新引起的行锁,使得整个系统的性能得到显著提升。
- 一主多从:一个主库多个从库的配置,可以将查询请求均匀的分散到各个副本,能够进一步的提升系统性能
- 多住多从:使用多住多从的方式,不但能够提升系统的吞吐量,还可以提高系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘损坏的情况下,仍然不影响系统的正常运行
Sharding-JDBC的读写分离,是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。
Sharding-JDBC只负责路由分配,不负责数据同步。数据同步需要开发人员在具体的数据库中实现
1.环境准备
使用 docker 运行 3个 mysql 容器,端口分别为 3306,3307,3308。
其中 3306 为 master , 其余 为 slave。
docker run \
--name mysql \
-p 3306:3306 \
-v /temp/mysql/config:/etc/mysql/conf.d \
-v /temp/mysql/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:8.0
容器运行完成后如下:

分别进入容器,修改 root 账号 的访问权限,或者也可以单独添加一个允许远程访问的账号。
此处建议单独添加一个账号,并且只允许操作特定的数据库,这里仅做演示,在实际生产环境中切记要注意
# 1.进入容器
docker exec -it mysql bash
# 2.登录MySQL
mysql -u root -p
# 3.切换至 MySQL 数据库,
use mysql;
# 4.添加账号
create user 'shawn'@'%' identified by '123456';
# 5.授予权限
grant all privileges on *.* to 'shawn'@'%' with grant option;
3个数据库实例都配置完成以后,退出数据库,退出容器即可,然后使用 mysql 数据库管理工具连接。
2.配置主库
修改 mysql 的 master 实例,在配置文件中新增以下内容:
注意,我们的mysql 容器在运行时已经通过数据卷将数据库文件和配置文件的目录映射到了宿主机上。
这里master实例的配置文件被映射到了 /temp/mysql/my.conf,我们只需要修改这个文件即可
# 开启日志,数据库的同步就是通过日志实现的
log-bin = mysql-bin
# 设置服务Id,主从不能相同
server-id=1
#允许同步的数据库
binlog-do-db=user_db
#屏蔽系统数据库的同步
binlog-ignore-db=information_schema
binlog-ignore-db=mysql
binlog-ignore-db=performance_schema
binlog-ignore-db=sys
此处建议,专门创建一个MySQL用户,用来做数据同步
CREATE USER 'db_slave'@'%' IDENTIFIED BY 'db_slave';
GRANT REPLICATION SLAVE ON *.* TO 'db_slave'@'%';
3.配置从库
修改 mysql 的 slave实例,分别在两个实例的配置文件中新增以下内容:
log-bin = mysql-bin
# 设置服务Id,主从不能相同
server-id=2
#设置需要同步的数据库
replicate_wild_do_table=user_db.%
# 屏蔽系统数据库的同步
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=performance_schema.%
replicate_wild_ignore_table=sys.%
查询主节点的当前位点,记录文件名及位点
show master status;
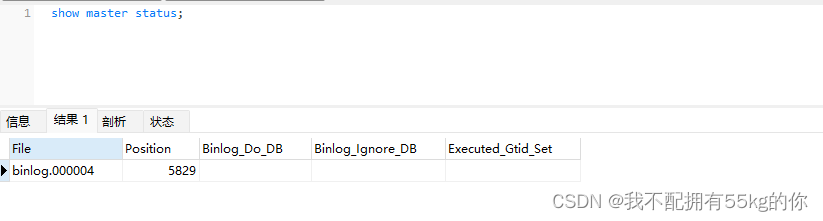
这里的同步文件为 binlog.000004,位点为 5829。
注意,在配置数据同步期间,不要做任何增删改操作。如果做了,则请重新查询位点。以防万一,在开始同步时最好再查询一遍。
CHANGE MASTER TO
MASTER_HOST='xxx.xxx.xxx.xxx',
MASTER_PORT=3306,
MASTER_USER='shawn',
MASTER_PASSWORD='xxxxxx',
MASTER_LOG_FILE='binlog.000004',
MASTER_LOG_POS=5829;
其他常用命令:
- 停止同步:STOP SLAVE;
- 开始同步:START SLAVE;
- 重置同步:RESET SLAVE;
- 查看同步状态:SHOW SLAVE STATUS;
- 查询MySQL Server-Id:SHOW VARIABLES LIKE ‘server_id’;
4.配置application.yml
以下是一个分库分表+读写分离的配置示例:
spring:
shardingsphere:
datasource:
#数据源名称
names: master1,master2,master3,slave1,slave2
master1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.16.150:3306/order_db_1?serverTimezone=Asia/Shanghai&characterEncoding=utf8
username: root
password: 123456
# 其他数据源连接配置省略
sharding:
# 主库存库逻辑数据源定义
master-slave-rules:
# ds-user 表示当前配置的数据源的逻辑数据源
ds-user:
# 配置主数据源
master-data-source-name: master3
# 配置从数据源
slave-data-source-names:
- slave1
- slave2
tables:
t_user:
# 配置数据节点,配置了主从同步之后,此处需要使用主从关系的逻辑数据源名称
# 而不再使用数据源名称
actual-data-nodes: ds-user.t_user
key-generator:
type: SNOWFLAKE
column: user_id
# 逻辑表名
t_order:
actual-data-nodes: master${1..2}.t_order_${1..2}
key-generator:
column: order_id
type: SNOWFLAKE
# 划重点,此处配置分库策略
database-strategy:
inline:
# 定义分片键,此处使用 另一个字段值 user_id 作为分片键
sharding-column: user_id
# 定义分片规则(user_id % 2 + 1),值为 1 使 进入 master1,值为 2 时,进入master2
algorithm-expression: master$->{user_id % 2 + 1}
# 配置分表策略
table-strategy:
inline:
# 定义分片键
sharding-column: order_id
# 定义分片策略
algorithm-expression: t_order_$->{order_id % 2 + 1}
# 绑定公共表(广播表)
broadcast-tables: t_dict
props:
# 打开SQL日志
sql:
show: true
mybatis-plus:
configuration:
# 配置数据库字段与实体类映射方式,是否是小驼峰命名法
map-underscore-to-camel-case: true
global-config:
db-config:
# 配置数据表前缀
table-prefix: t_