1. MySQL架构一共分为两层 server 和 存储引擎层(一般为Innodb引擎)
主要执行流程都在server层:连接器,查询缓存,解析SQL(解析器),执行SQL(预处理器,优化器,执行器)
存储引擎层:索引数据结构由引擎层实现,Innodb引擎支持的是B+树索引。数据表中创建的主键索引和二级索引都由B+树实现。
执行一条SQL语句会发生什么
1. 连接器: 与客户端进行TCP三次连接(长连接)
校验用户名和密码
用户名验证通过后,会基于此时读取到的用户权限来进行逻辑判断
TCP长连接不会轻易断开,所以使用长连接的好处就是减少建立连接和断开连接的过程。
但是时间长了它也会占用内存过多,因此会采用以下两种方式来断开连接:
1) 定期断开长连接
2)客户端主动重置连接
2.查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;(因为当有表更新之后,对应的语句就会被清除,所以会比较鸡肋)
3. 解析SQL:两个过程:
1. 词法分析:根据输入的字符识别出来关键字,构建SQL语法树,方便后面的模块获取SQL类型,表名,字段名。
2.语法分析:根据词法分析的语法树,判断该语句是否符合MySQL的语法。
4. 执行SQL
1. 预处理器:
检查SQL语句中的表和字段是否存在
将SQL语句中的 * 扩展为表中的所有列
2. 优化器:
基于查询成本考虑,选择成本最小的执行计划。(主要选择主键索引还是二级索引)
3. 执行器:
根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
MySQL一行记录是怎么存储的
MySQL数据文件存放在哪个文件?
一共有三个文件: db.opt 用来存放当前数据库的默认字符集和字符校验规则
t_order.frm 用来存放当前表结构
t_order.ibd 用来存放当前表数据(MySQL数据存放在这里)
表空间的文件结构:
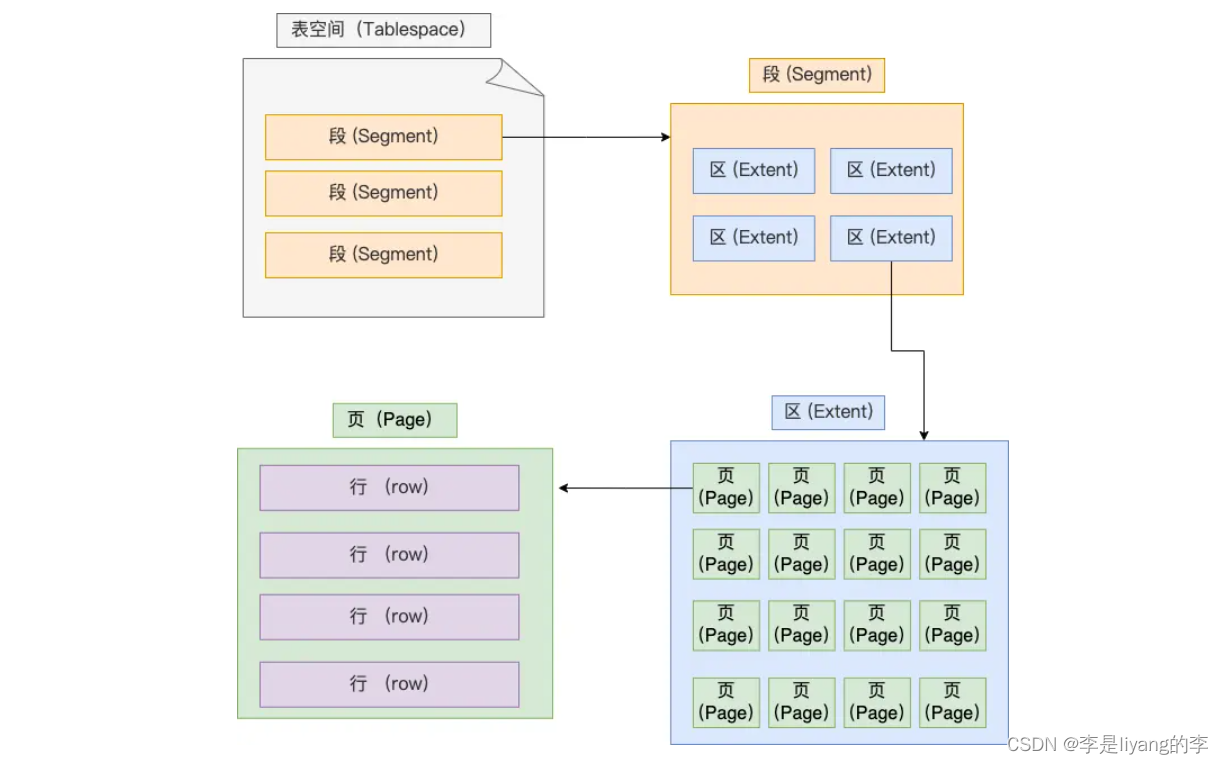
行:数据库表中的数据都是按行的形式存储,每行记录根据不同的行格式采用不同的存储结构。
页:每次只读取一行效率会很低,所以数据库读取数据都是以页为单位来读取数据。默认每个页的大小都是16KB。
区:Innodb存储引擎是以B+树的形式存储,B+树的每一层都是以双向链表的形式连接起来。但是链表中相邻的两个页之间并不是连续的,所以使用区的形式,让页与与页之间相邻。所以,当表中的数据量较大时,按照区为单位分配内存空间,每个区的大小为1MB。
段:表空间是由多个段组成,段由多个区组成。段有数据段,索引段,回滚段等
索引段:存放B+树中非叶子节点的区的集合
数据段:存放B+树中叶子节点的集合
回滚段:存放的是回滚数据的区的集合。
Innodb的行格式:COMPACT

Innodb的行格式一共分为两个部分:记录的额外信息,记录的真实数据
记录的额外信息一共分为三个部分:变长字段长度列表,NULL值列表,记录头信息。
记录的真实数据:

前面包含三个字段:
row_id : 当建表的时候设置了主键或者唯一约束,那么就不会有row_id字段。
trx_id : 事务id,表明了当前数据是由哪个事务生成的。
roll_pointer : 这条记录上一个版本的指针。
总结:
MySQL的NULL值是怎么存放的:
是由Compact行格式中的NULL值列表来标记NULL的列,NULL不会存储在行格式中的真实数据部分。
MySQL如何知道varchar(n) 实际占用的数据大小:
利用行格式中的变长字段长度列表。
行溢出后,多余的数据怎么处理:
当一行存储不了所有的数据后,会将多余的数据存储到溢出页。并且在真实数据部分流出20KB的空间用来指向溢出页的地址。