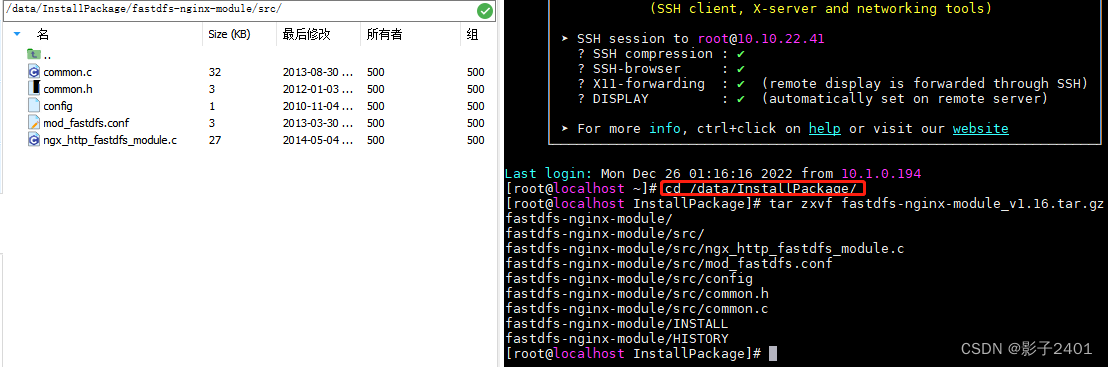
initializeState
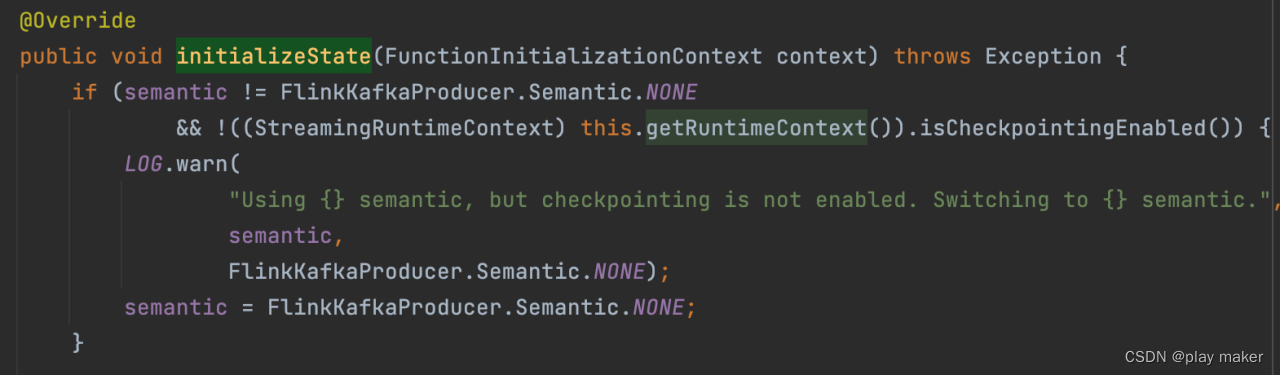

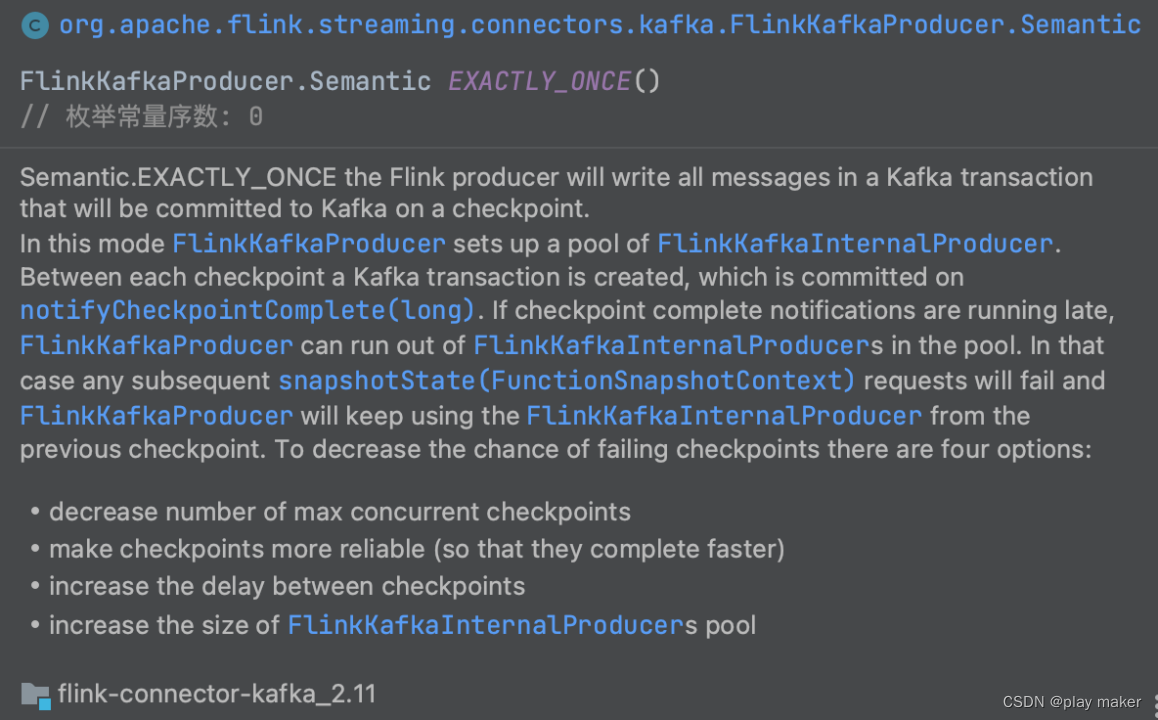

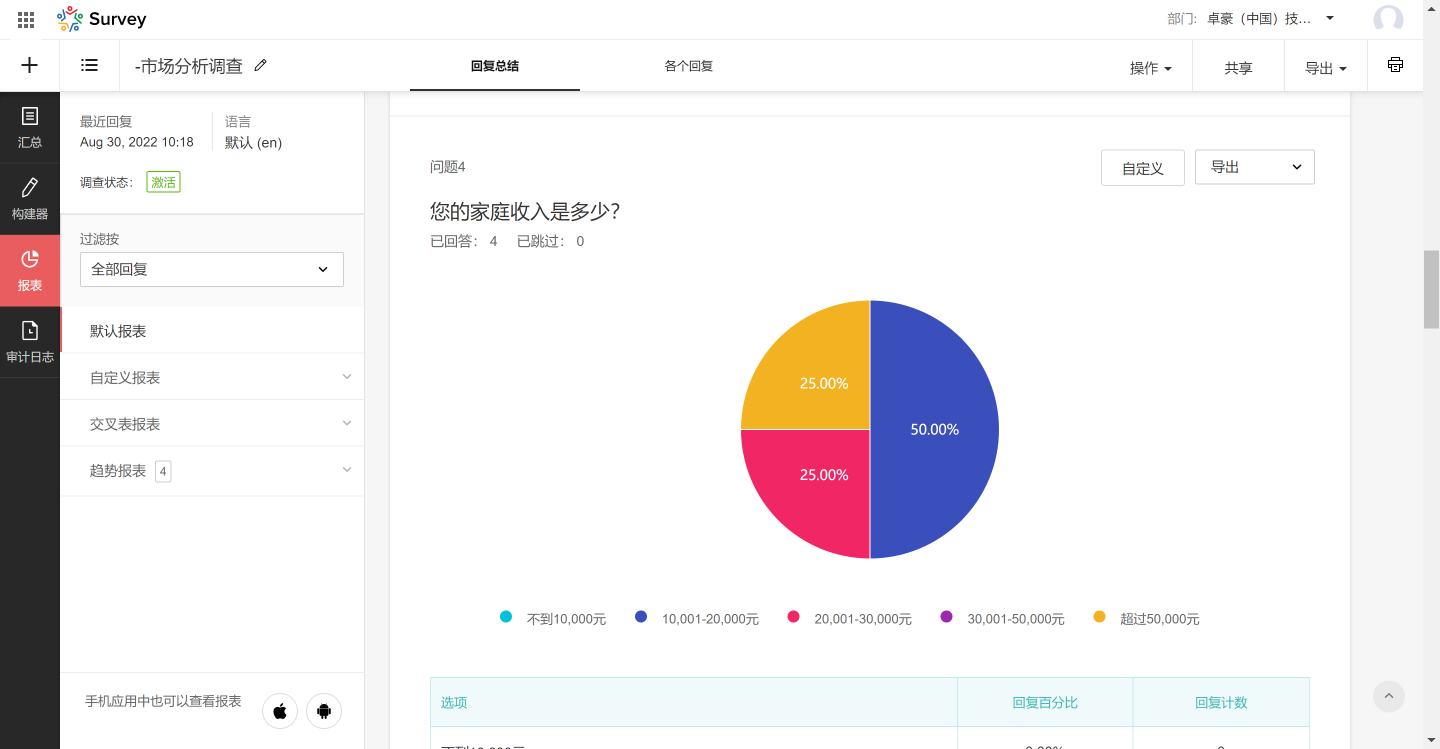
先查询是否开启isCheckpointingEnabled配置,如果没开,但是使用了EXACTLY_ONCE或者AT_LEAST_ONCE语义,就报错。
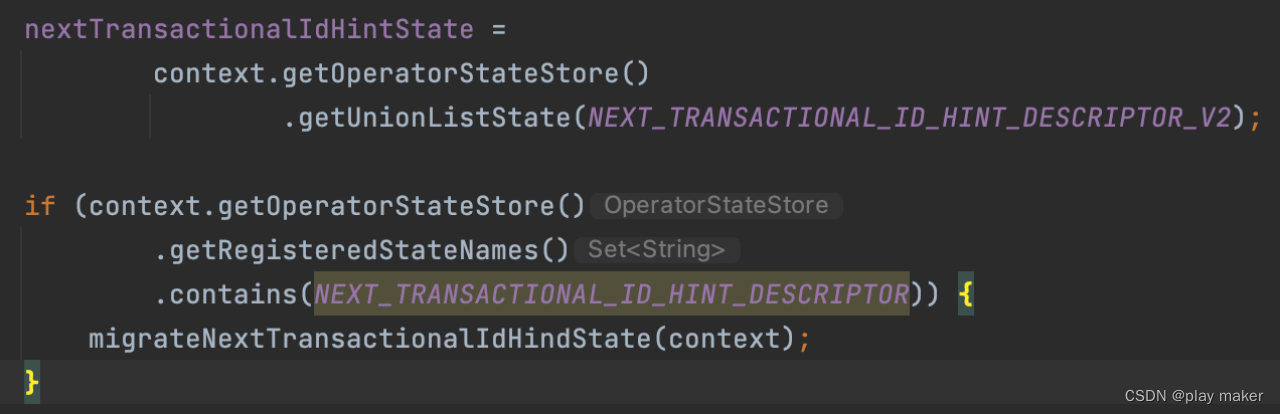

然后从checkpoint中保存的state中读取nextTransactionalIdHintState。
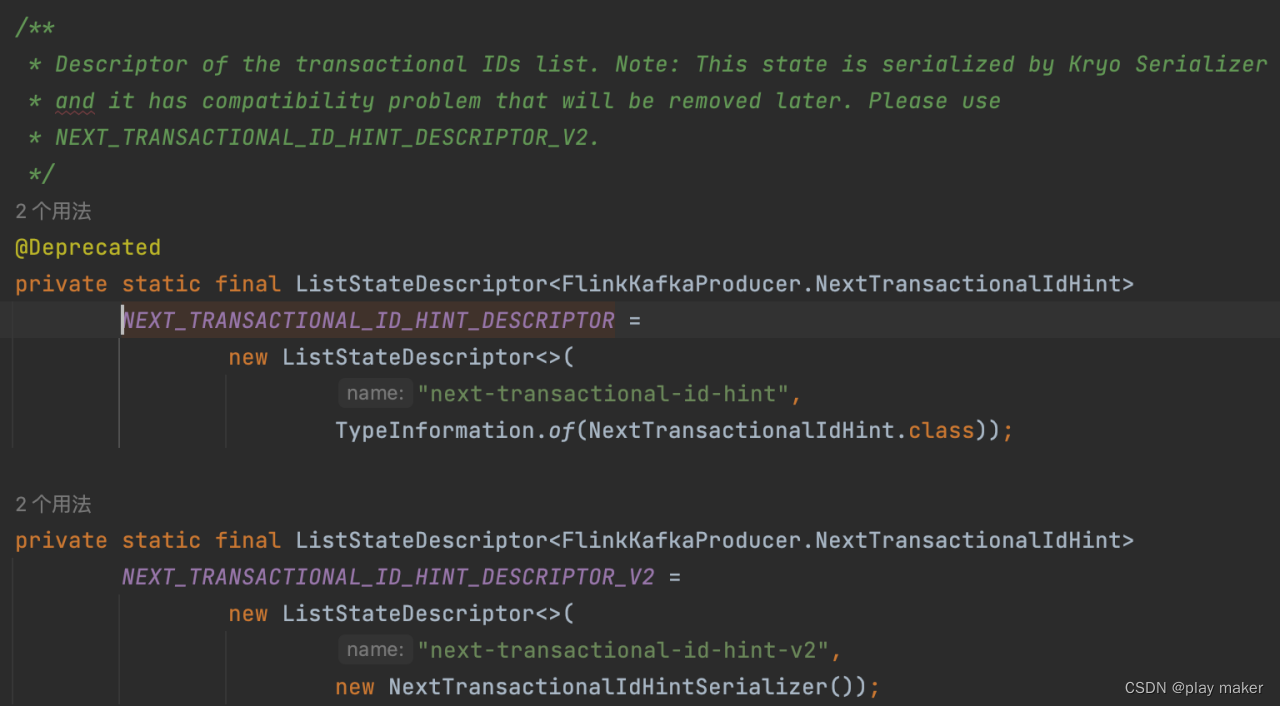
NEXT_TRANSACTIONAL_ID_HINT_DESCRIPTOR现在使用v2版本,如果checkpoint中保存的是v1版本的,则调用migrateNextTransactionalIdHindState方法进行迁移。
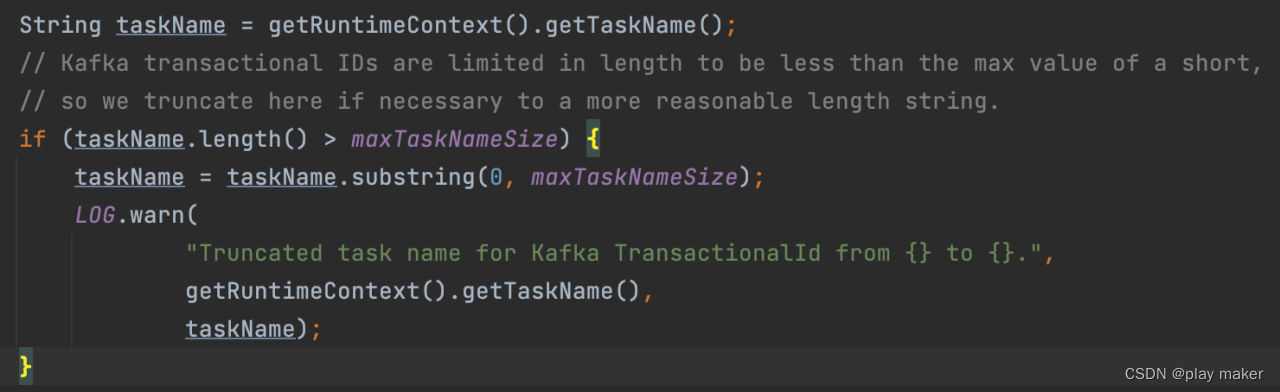
然后读取taskName,taskName有最大字数限制,如果大于maxTaskNameSize则截断。

维护事务ID池子
然后初始化TransactionalIdsGenerator。
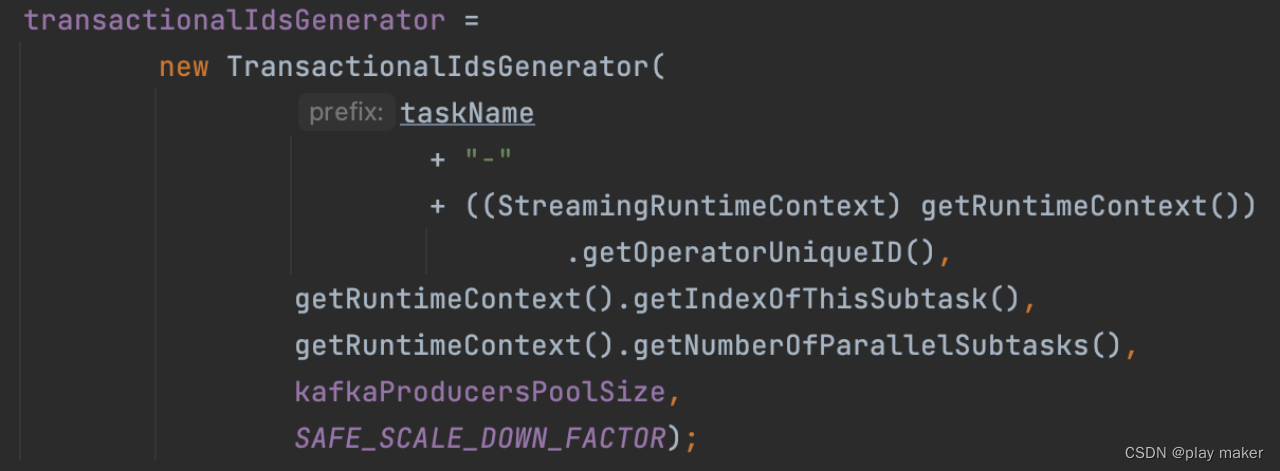

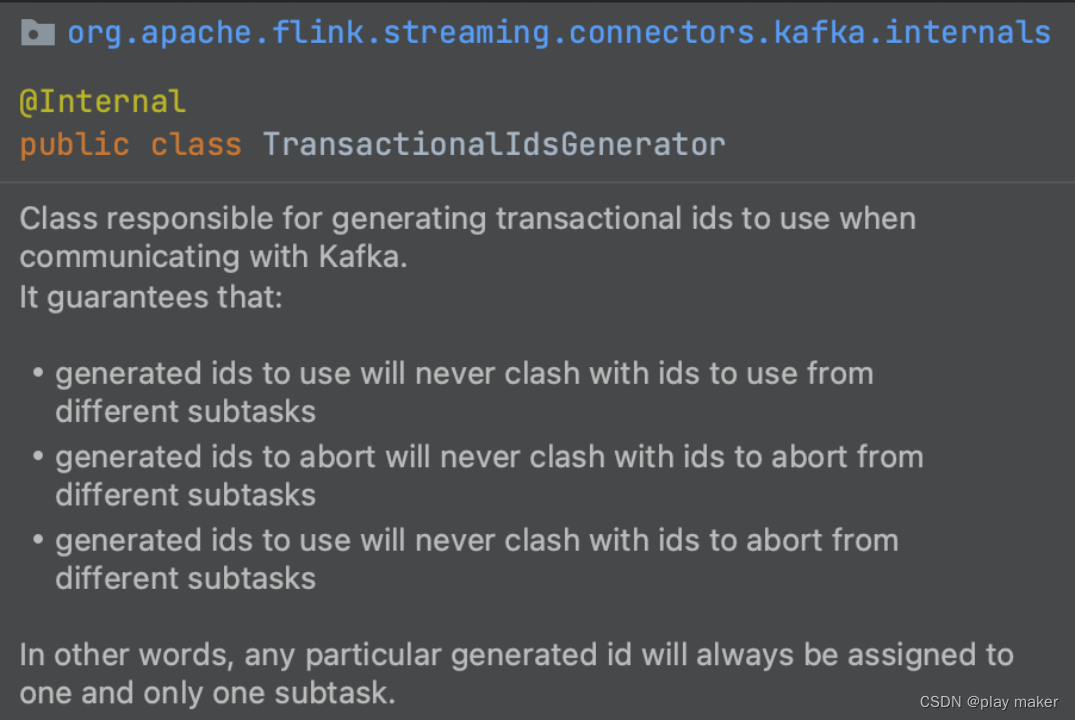
TransactionalIdsGenerator保证了不同子任务之间使用和abort的事务id号不会重复,互相之间没有干扰。
并发子任务运行在同一个operator上,prefix为taskName+OperatorUniqueID,因此多个并发子任务的prefix相同。
因此入参还传入了参数subtaskIndex、totalNumberOfSubtasks,来区分不同的子任务。


前面文章
Flink+Pulsar、Kafka问题分析及方案 – 幂等性
分析过,**Kafka因为一个事务ID只能支持对最后一个事务的commit幂等性,那么当flink出现并发checkpoint的情况时就有可能出错,**因此kafka使用了一个事务ID池子,只要并发checkpoint的个数小于事务ID池子的大小,那么就不会出错。
事务ID池子的大小默认为DEFAULT_KAFKA_PRODUCERS_POOL_SIZE,即5个。
每个子任务使用的事务ID池子是固定的,会把事务ID池子保存到userContext,userContext保存在state里,从而作为快照的一部分存储起来,当从checkpoint/savepoint启动时,就会读取前面保存的事务ID池子。
-
如果从checkpoint/savepoint中启动
org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction#initializeState
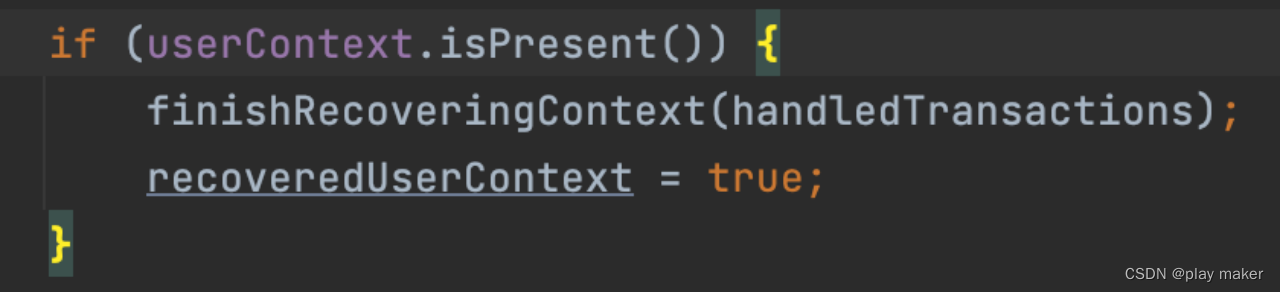



从checkpoint中恢复userContext后,调用finishRecoveringContext方法,从userContext恢复事务ID池子,设置进availableTransactionalIds。 -
如果不从checkpoint/savepoint中启动,则没有恢复userContext,会调用initializeUserContext来初始化userContext。
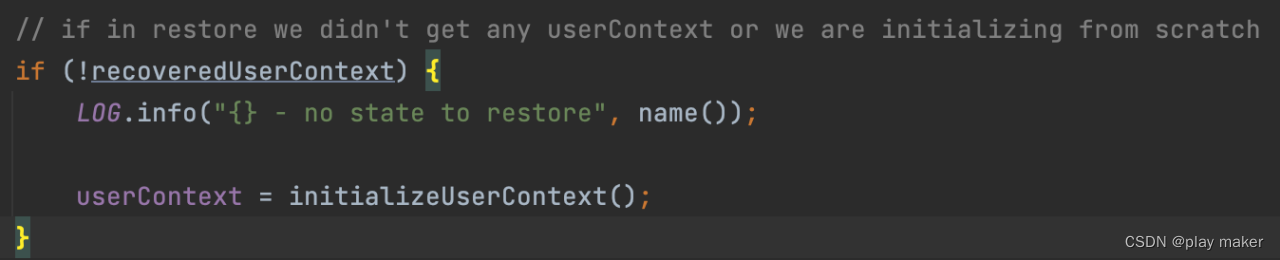


KafkaTransactionContext就只保存了事务ID池子。

调用transactionalIdsGenerator.generateIdsToUse来生成该任务使用的事务ID池子,需要传入一个入参nextTransactionalIdHint.nextFreeTransactionalId,它是用来帮助确定生成安全的事务ID号的,后续会进一步分析它。
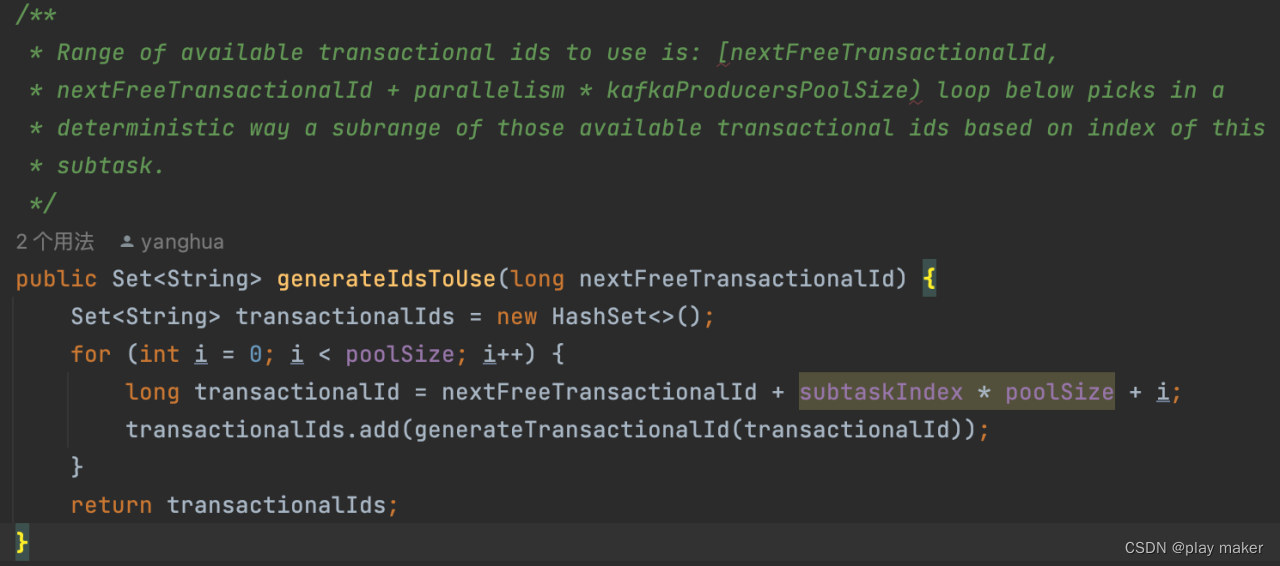

所有并发子任务的id池子为[nextFreeTransactionalId,nextFreeTransactionalId + parallelism * kafkaProducersPoolSize)
单独某个子任务的id池子为[nextFreeTransactionalId + subtaskIndex * poolSize, nextFreeTransactionalId + (subtaskIndex+1) * poolSize)
维护nextTransactionalIdHint
下面看nextTransactionalIdHint是怎么维护的。
首先要对比分析一下TwoPhaseCommitSinkFunction#state


注记:这行代码除了从checkpoint中获取operator state,还起到注册该operator state的作用。
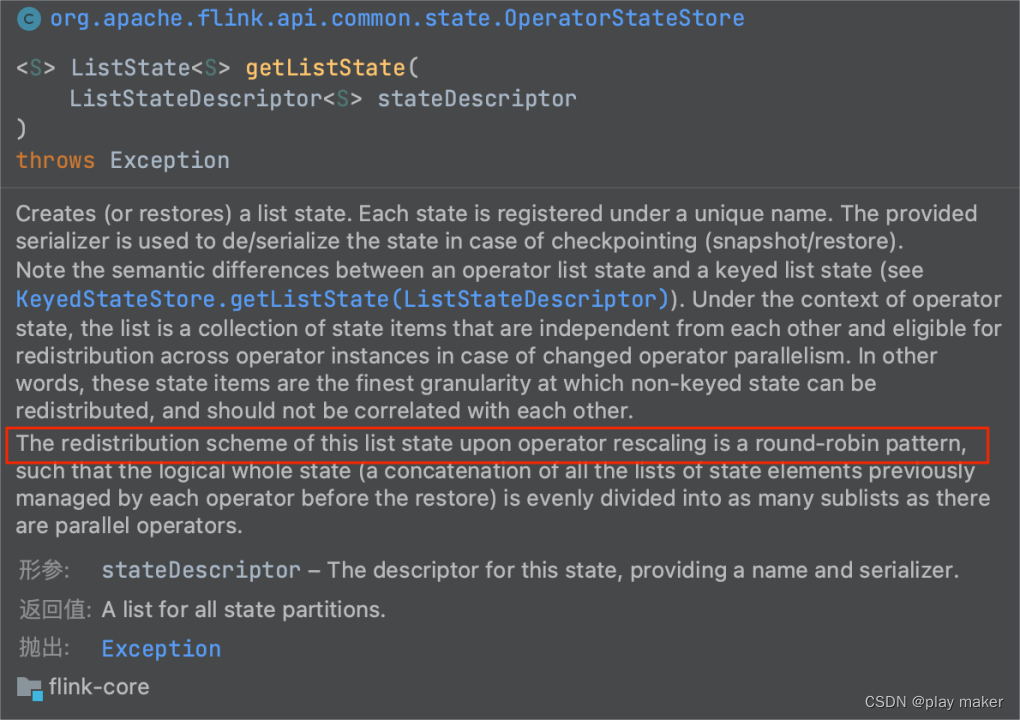
state状态的redistribution scheme是round-robin pattern,比如说有10个子任务,则一个checkpoint中会保存10个state,如果并发度降低为5,则这10个state会以round-robin模式分配给这5个子任务。
这也是为什么TwoPhaseCommitSinkFunction#initializeState方法里要对state用for循环遍历,因为启动实例的时候同一个子任务可能分配到了多个state。

nextTransactionalIdHintState与前面的state成员不一样,它注册的state的redistribution scheme是broadcast pattern,即一个checkpoint里包含的该state会分发给所有子任务,所有子任务读取到相同的state内容。


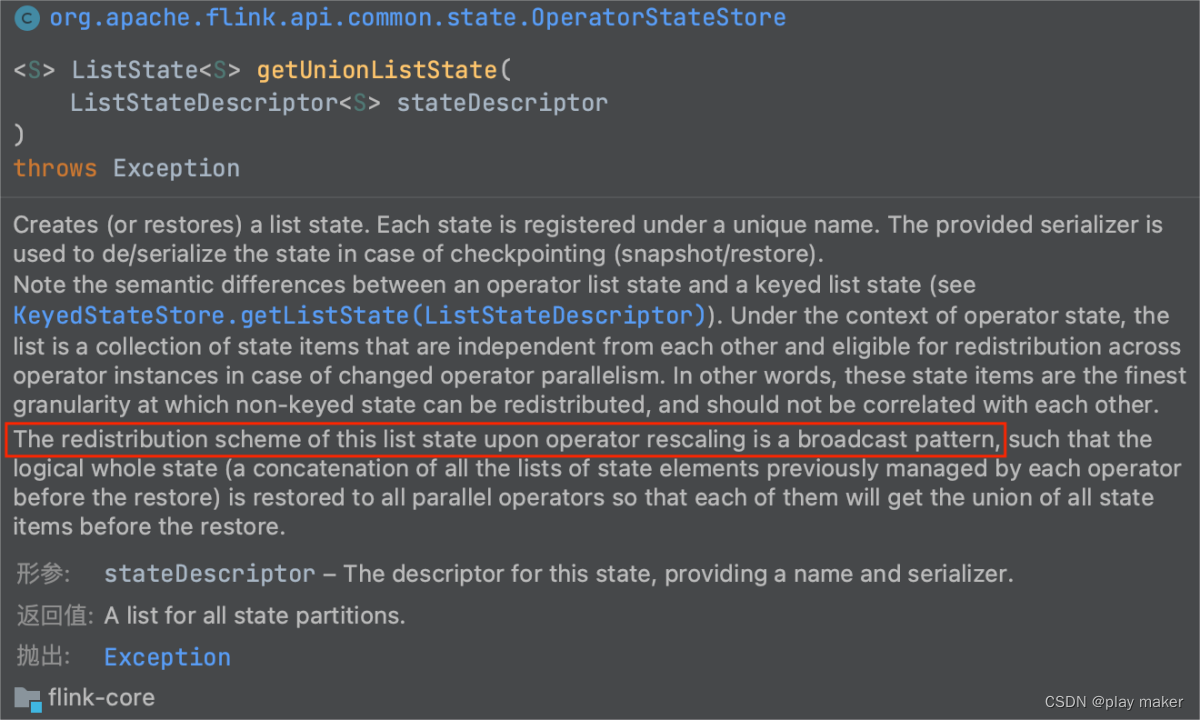
继续看FlinkKafkaProducer#initializeState方法。
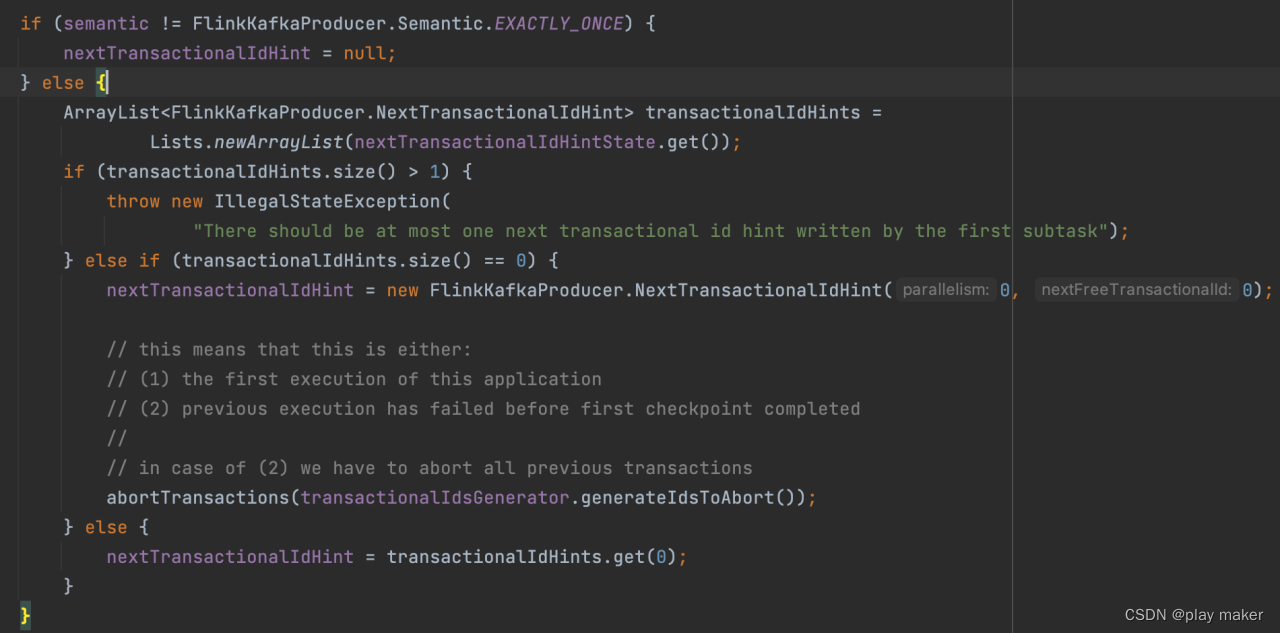
如果不从checkpoint启动,则这里transactionalIdHints的size为0,如果从checkpoint启动,则size应该为1,大于1是不合法的。
因此,
-
如果size为1,则直接设置进nextTransactionalIdHint变量即可。
-
如果size为0,则说明不是从checkpoint启动,则可能有下面一些情况:
- 第一次启动该任务,
- 前面启动过任务,但是从来没成功打过checkpoint
- 用户启动任务执行一些测试,后面正式生产时不从checkpoint启动
除了第一种情况,其他情况都可能会残留一些open的事务,因此需要abort掉。
abort哪些事务也是一个值得关注的问题,这个后续再分析。
nextTransactionalIdHintState作为一个新增的operator状态,同样在snapshotState方法中保存进Checkpoint里。
snapshotState

先调用TwoPhaseCommitSinkFunction#snapshotState把state成员给保存下来。
但是Kakfa connector还有一个状态nextTransactionalIdHintState。
因此接下来的代码把nextTransactionalIdHintState给更新,并保存到状态后端里。
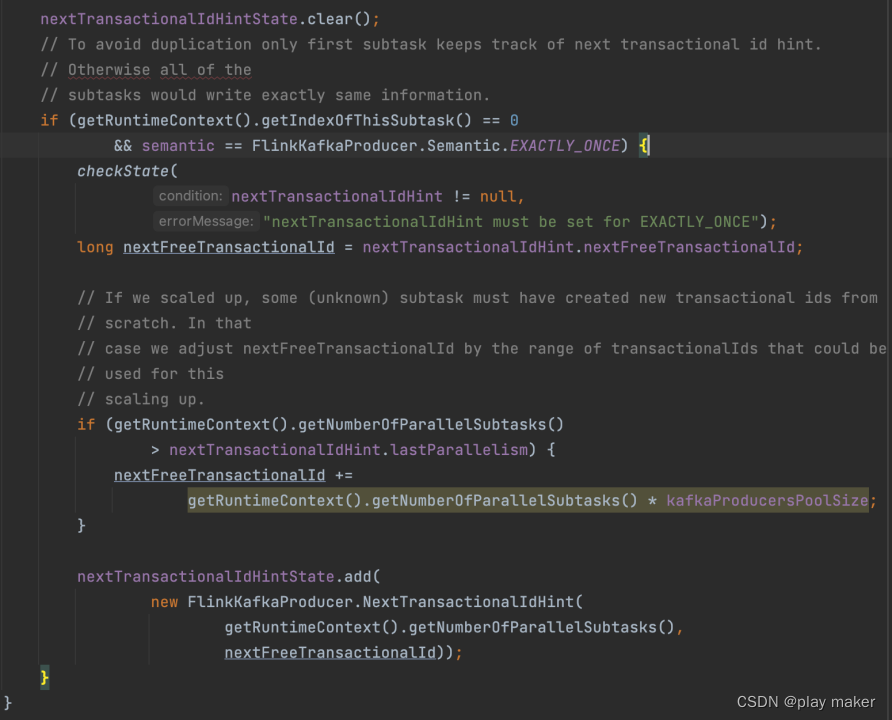
为了避免重复保存nextTransactionalIdHintState变量(因为它的redistribution scheme是broadcast pattern),只由第一个子任务(即index为0)来维护与保存即可。
注意:不从checkpoint启动时,nextTransactionalIdHint是初始化为

因此生成id池子时传入nextFreeTransactionalId为0。

因此所有子任务生成的ID范围为[0,parallelism * kafkaProducersPoolSize)
当任务开启打第一个checkpoint时,这里判断
getRuntimeContext().getNumberOfParallelSubtasks()
> nextTransactionalIdHint.lastParallelism
肯定为true,因此更新nextFreeTransactionalId为parallelism * kafkaProducersPoolSize,这就是一个安全的事务ID起点。当前使用的事务ID号都比它小。
而Flink任务停止后,再次启动时是可以修改子任务并发度的,增加或者减小都有可能,因此从checkpoint恢复时,如果并发度增加为parallelism2,新的子任务使用的ID号就会超过nextFreeTransactionalId,所有子任务使用的ID范围为[0,parallelism2 * kafkaProducersPoolSize)
因此需要更新nextFreeTransactionalId为parallelism2 * kafkaProducersPoolSize
然后保存进nextTransactionalIdHintState里。
根据对代码的分析,nextTransactionalIdHint.nextFreeTransactionalId只会在下面调用链中使用到:generateNewTransactionalIds -> initializeUserContext
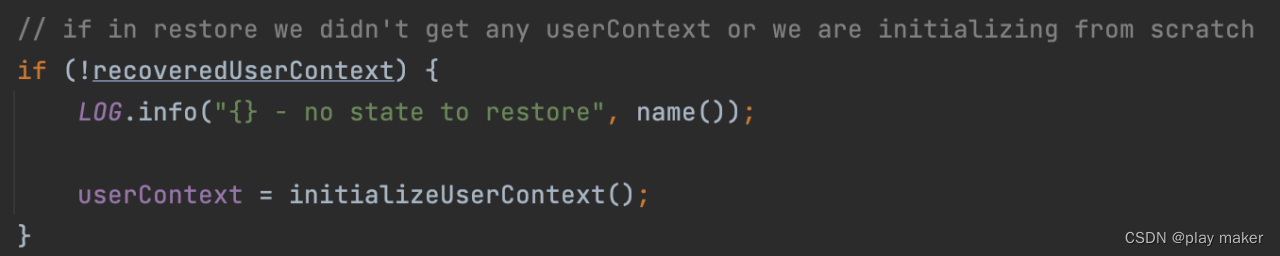
而由于Kafka connector会把ID池子保存进userContext里,进而保存进checkpoint里,因此这块代码只有在读取不到userContex时才会调用到。
而读取不到userContex有下面情况:
- 大多数情况下不从checkpoint/savepoint中启动才会读取不到userContex,不从checkpoint/savepoint中启动,则nextTransactionalIdHint.nextFreeTransactionalId肯定为0,即Flink并发子任务生成的事务ID是使用
TransactionalIdsGenerator#generateIdsToUse(0)
来生成的。 - 如果增加并发度,新增的某些子任务会读取不到state、userContext,因此会调用
generateNewTransactionalIds -> initializeUserContext,但是因为nextTransactionalIdHint这个operator状态是广播分发的,因此nextTransactionalIdHint.nextFreeTransactionalId不为0。
要验证这个事情可以如下实验:
先并发度为1,则[0,5)
然后并发度为2,检测多出来的一个子任务使用的事务ID范围是否为[10,15),而不是[5,10)。
如果证实了,则就可能有bug!
因为后面的generateIdsToAbort方法是基于nextFreeTransactionalId为0的假设!
如果新增的子任务创建的事务ID超过了generateIdsToAbort方法预估事务ID的上限,则会导致OPEN事务的残留。
其实nextFreeTransactionalId的本身貌似没有用处?
Abort残留的事务
不从checkpoint/savepoint中启动
下面分析前面提到的,不从checkpoint/savepoint中启动时,需要调用abort方法来把残留的事务给终结掉。

这里有一个问题需要解决的:由于不从checkpoint/savepoint中启动,因此我们无法得知之前启动时的并发度,假设前面启动时的并发度为P1,当前启动的并发度为P2,因此前面的任务执行使用的事务ID范围为[0,P1 * PoolSize),我们需要把这些事务ID都abort一次,但是P1是不可知的。
- 如果P2大于P1,即增加并发度,则[0,P2 * PoolSize)肯定包含[0,P1 * PoolSize),此时对[0,P2 * PoolSize) 遍历abort一次即可。
- 如果P1大于P2,即降低并发度,则[0,P2 * PoolSize)是[0,P1 * PoolSize)的子集,此时无法猜测要abort多少事务ID。
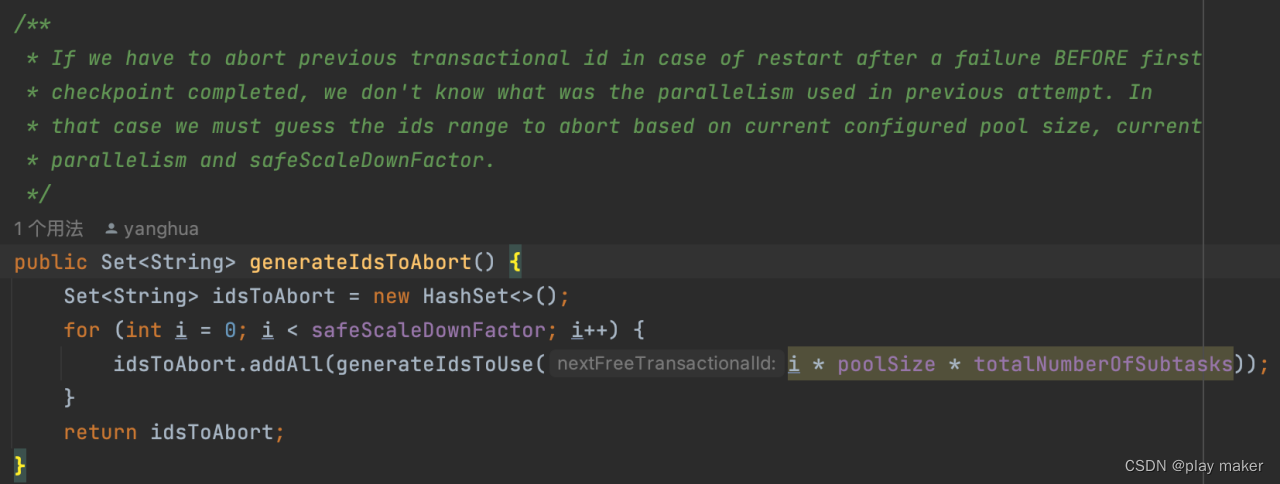
Kakfa的解决方法是,设定一个参数safeScaleDownFactor,即Flink任务减低并发度的比例不能超过这个,默认值为5。
比如说,第一次启动Flink任务的并发度为10,则第二次启动Flink任务的并发度至少为10/5=2。
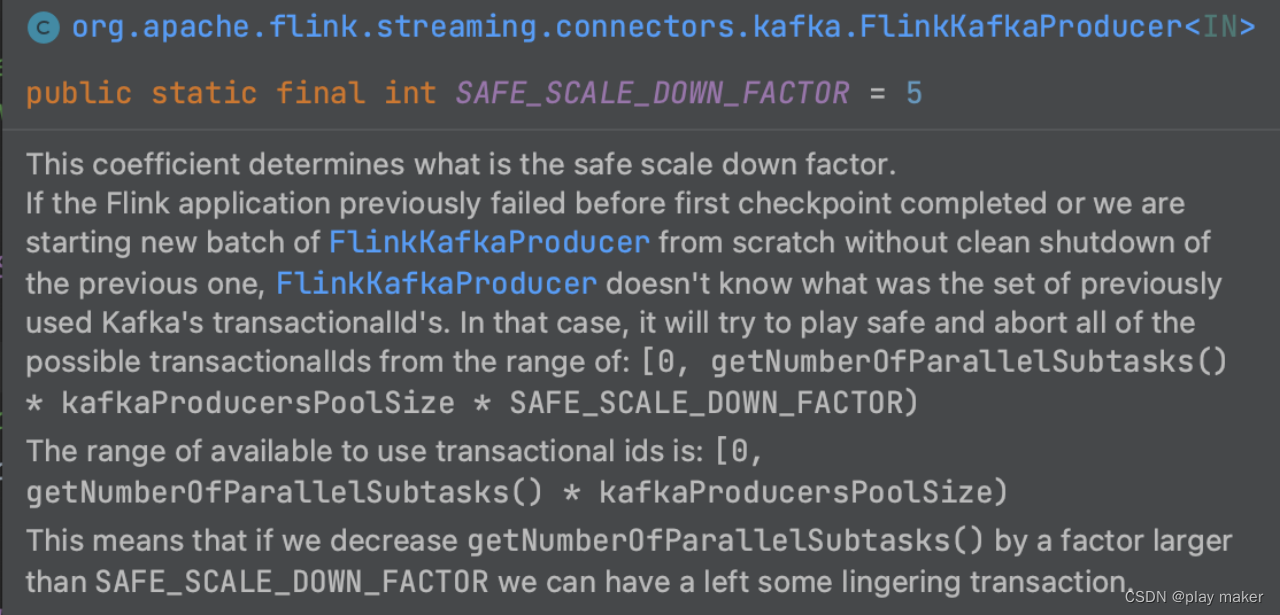
通过这种方式,我们得知P1、P2的关系:P2*5>=P1
即[0,P2 * 5 * PoolSize)肯定包含[0,P1 * PoolSize)。
因此,我们对[0,P2 * 5 * PoolSize)范围内的事务ID号都abort一次即可。
注意这里用到了一个假设:生成事务ID时所用的入参nextFreeTransactionalId是0.
另外,由于Pulsar、Kafka的topic分区数都只能增加,不能减小;而Flink任务的并发度往往跟分区数相关,因此Flink任务的并发度调整大多只会增加,而不会减小,就算减小也不会减小很多,因此,Kafka connector这种做法其实也还行。
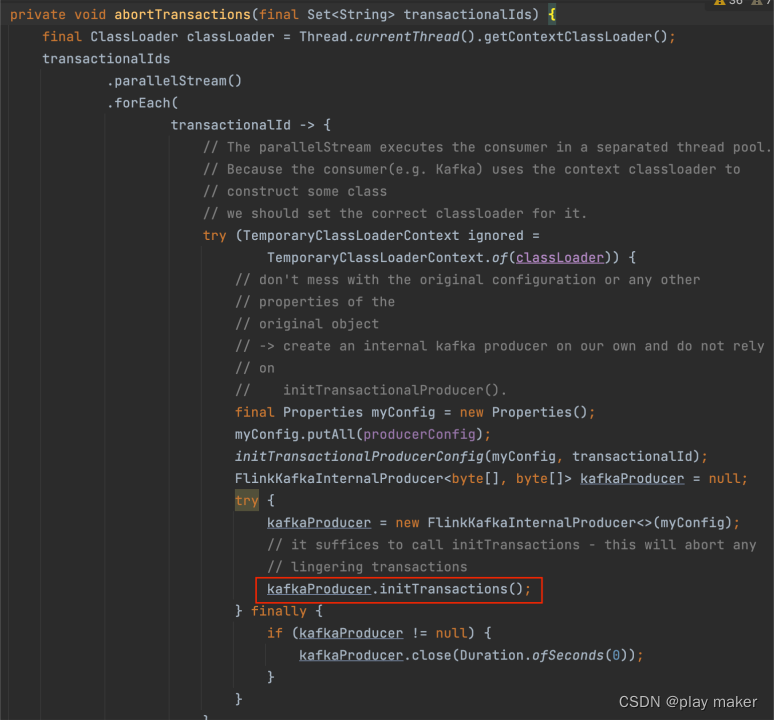
另外,abortTransactions事务的方式不是发送abort请求,而是调用
kafkaProducer.initTransactions();
来初始化该事务ID对应的Producer,此时服务端会关闭处于正在进行但还未进行提交的事务,同时服务端会对epoch进行递增。
从checkpoint/savepoint中启动
除了“不从checkpoint/savepoint中启动”这个case需要abort掉残留的事务,Flink从Checkpoint/Savepoint启动时也有可能残留open的事务。
如果Flink任务成功执行了initializeState方法,即成功创建了新事务,但是在成功执行snapshotState前就失败挂掉了,则这个新创建的事务也是无法记录到Checkpoint/Savepoint里的,因此也会导致遗漏某些事务没有被完结。

这种case也是很常见的。
下面看看Kafka connector是怎么处理的。
TwoPhaseCommitSinkFunction#initializeState ->
FlinkKafkaProducer#finishRecoveringContext ->
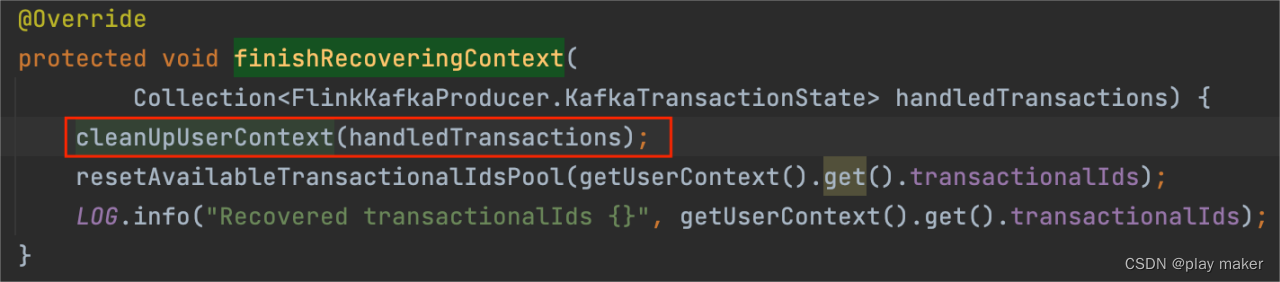
FlinkKafkaProducer#cleanUpUserContext
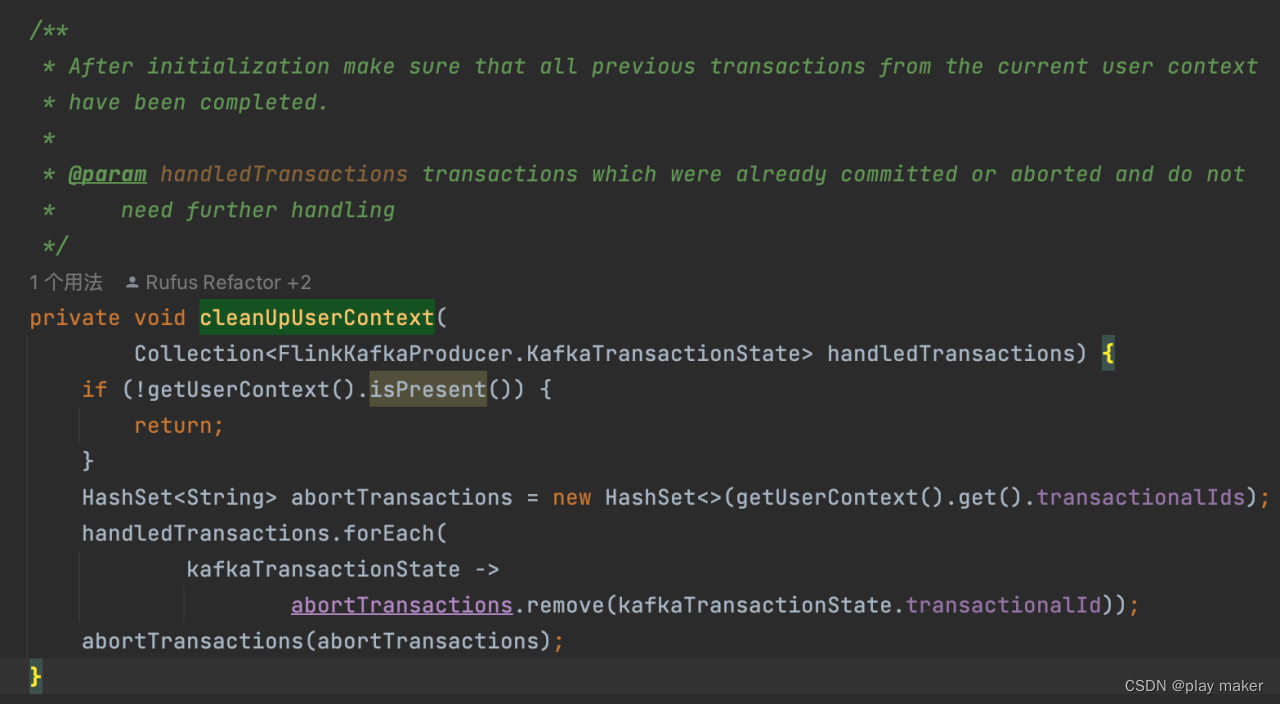
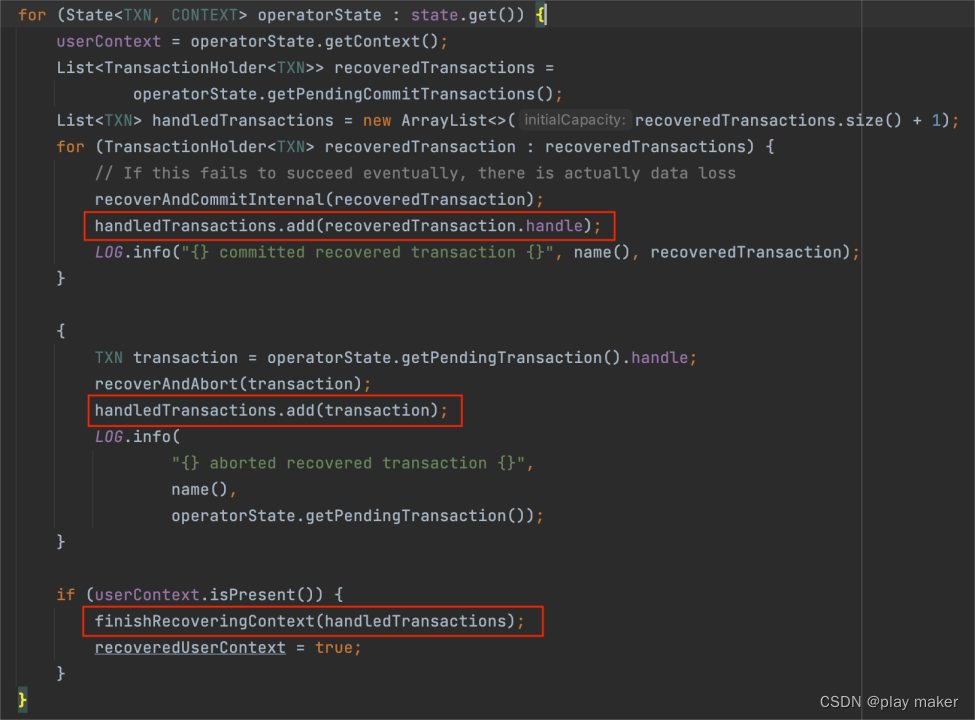
从Checkpoint/Savepoint启动,TwoPhaseCommitSinkFunction#initializeState方法会对checkpoint中存储的未完成的事务ID(即pendingTransaction、pendingCommitTransactions)调用recoverAndCommit、recoverAndAbort,然后把这些事务ID加入到handledTransactions里。

但是根据前面分析,可能有一些未完结的事务并没有存储进快照里,即pendingTransaction、pendingCommitTransactions里面。
因此我们还需要补充abort那些不在快照里的事务ID,因为Kafka connector的事务ID都是固定的,都在池子里存储着,而Context里存储了事务ID池子,因此恢复userContext后,即从userContext读取出来事务ID池子后,刨除掉handledTransactions的那一部分事务ID,剩下的事务ID都abort一次即可。
因此会调用finishRecoveringContext -> cleanUpUserContext方法,把剩下的事务ID都abort一次。
最后finishRecoveringContext方法会把读取出来的事务ID池子设置进当前任务使用的事务ID池子。
recoverAndCommit、recoverAndAbort
这部分在Flink+Pulsar、Kafka问题分析及方案 – 幂等性中也分析过,不过那里是以Kafka、Pulsar对比的角度来分析的,这里再以Flink Kafka Connector的源码分析角度来进行介绍。
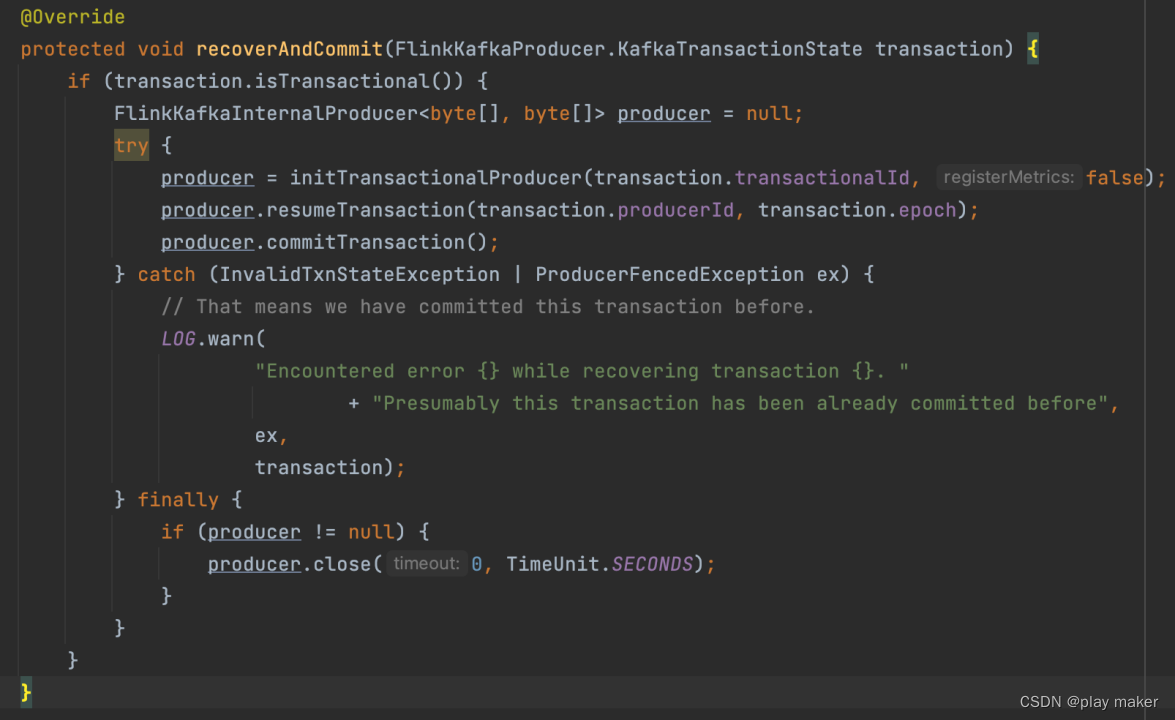
producer = initTransactionalProducer(transaction.transactionalId, false);
就是创建一个简单的Producer。



注记:这里构造返回的是FlinkKafkaInternalProducer,它封装了KafkaProducer,并且提供了resumeTransaction等有用的方法。
注意:这里创建完事务Producer后,并没有按照Kafka事务的官方规范的使用方式,即创建完事务Producer后,立马调用producer.initTransactions(),如下例:
KafkaProducer producer = createKafkaProducer(
“bootstrap.servers”, “localhost:9092”,
“transactional.id”, “my-transactional-id”);
// 初始化事务,这里会向 TC 服务申请 producer id
producer.initTransactions();
这是因为:如果调用initTransactions方法,会立马把当前事务ID对应的事务都结束掉,然后把epoch值递增1,从而把旧的Producer给fence掉,这个是Kafka为了解决僵尸实例而设计的一个机制。
但是Flink必须要对旧的事务进行commit、abort,因此需要做一些trick,调用FlinkKafkaInternalProducer#resumeTransaction方法。
producer.resumeTransaction(transaction.producerId, transaction.epoch);

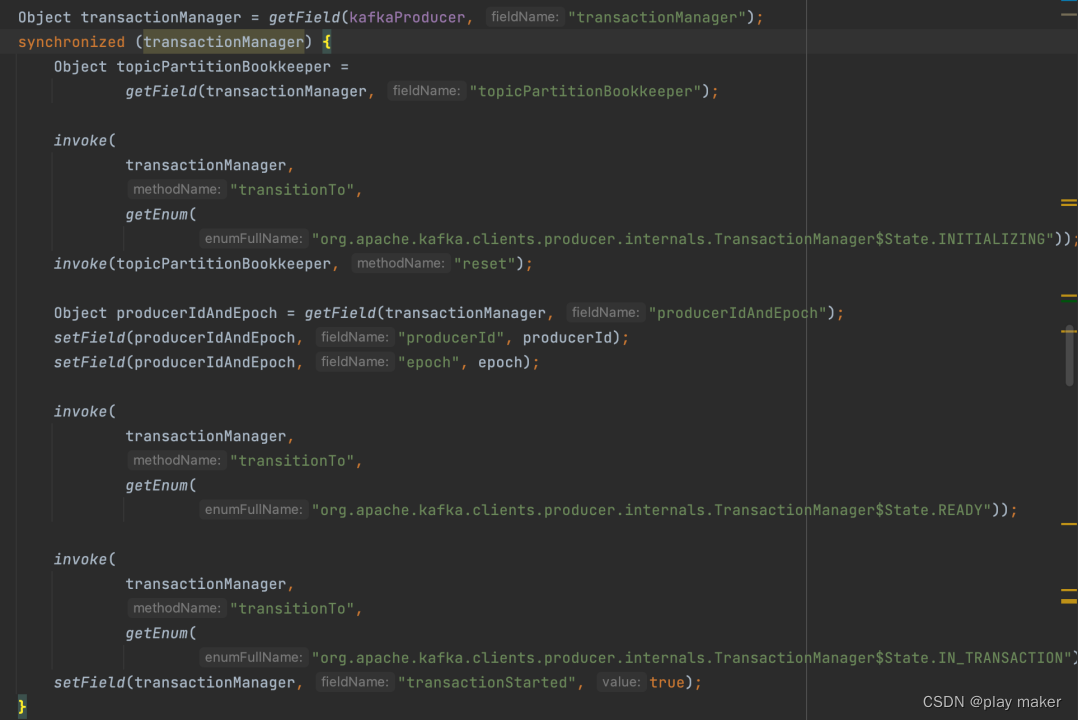
通过反射的方式,将事务Producer的producerId、epoch设置好,并将事务的本地状态转换为IN_TRANSACTION,从而能发送commit、abort请求。
最后再调用producer.commitTransaction()来发送commit请求。

然后是异常处理了,根据Flink+Pulsar、Kafka问题分析及方案 – 幂等性的分析可知,InvalidTxnStateException、ProducerFencedException这两种异常类型直接catch掉不报错即可。
最后把这个Producer关闭掉,因为现在旧的事务都已经处理完了,可以把这个旧的Producer给close掉,后续开启新的事务Producer。
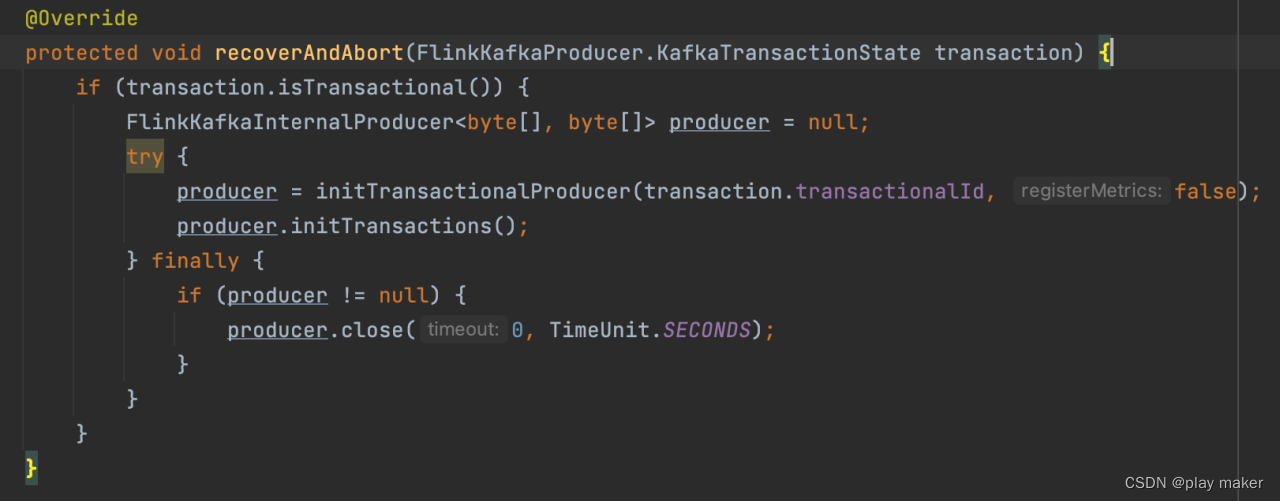
recoverAndAbort方法则直接调用initTransactions方法来把旧事务给abort掉,比较简单。
beginTransaction、Commit、Abort
beginTransaction

可以看到,每次创建新事务时,都会创建一个新的Producer来工作。因此后面每次abort、commit完成时,也会把对应的Producer给close掉。
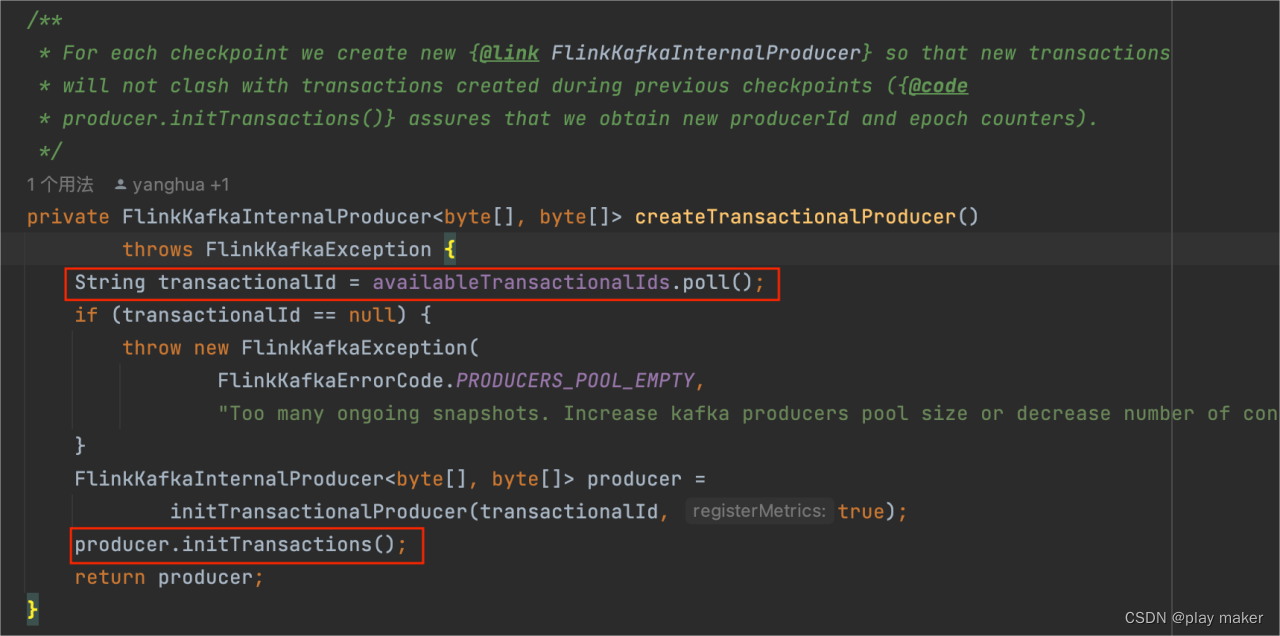
这里创建事务Producer时,就是走的官方流程,创建成功后会调用producer.initTransactions()。
事务ID要从池子availableTransactionalIds里面取,如果取不到,则直接抛错,因为并发checkpoint的个数超过池子事务ID的个数时,会发生冲突。
commit
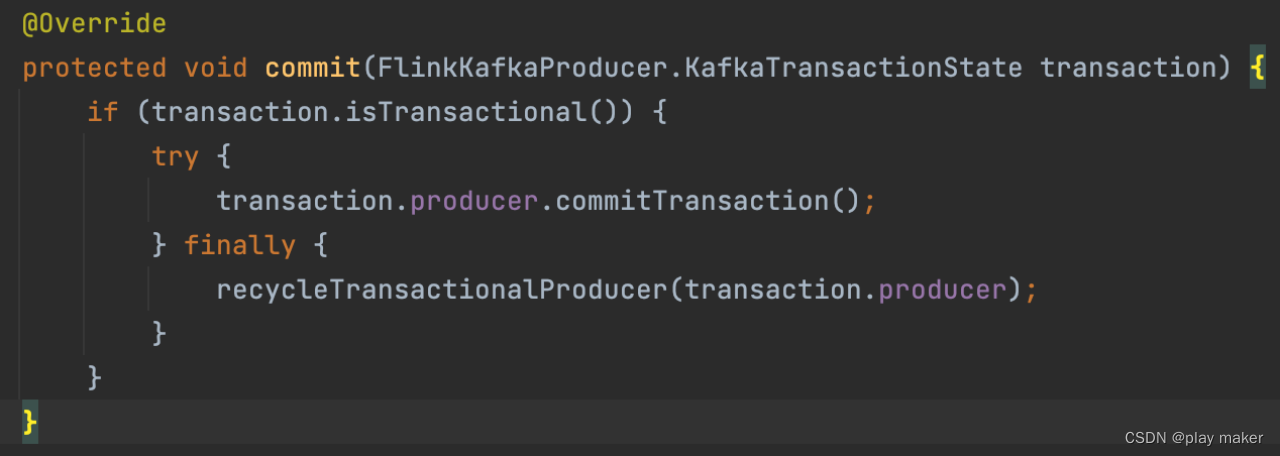

commit完成后,就把该Producer对应的事务ID回收到池子availableTransactionalIds里。
因为每次创建新事务的时候,都是创建新的Producer来工作,因此这里每次abort、commit完成时,也会把对应的Producer给close掉。
abort
类似。

open、close、invoke
open方法
在创建初始化实例时会调用open方法。
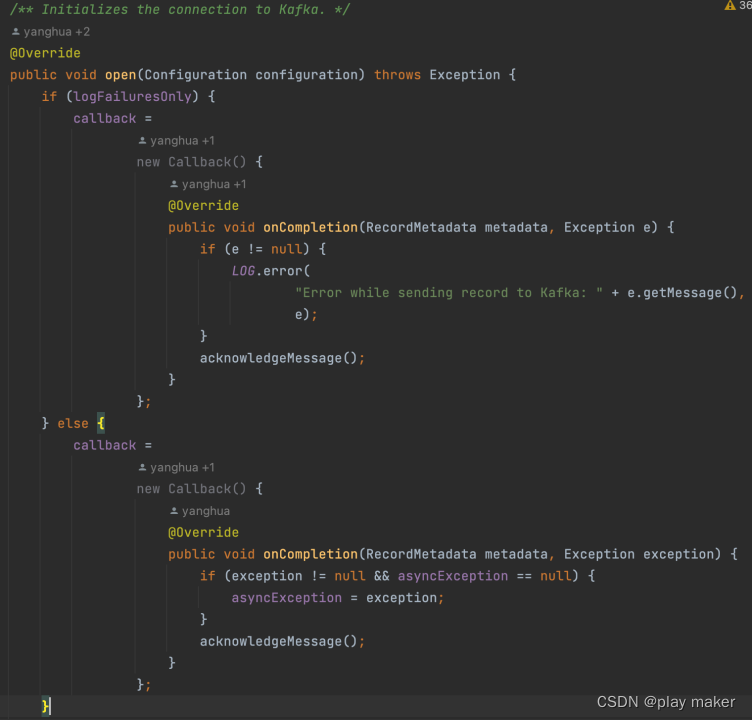


logFailuresOnly变量为true时,遇到写入报错时只记录错误日志,不抛错;为false时,则把报错保存到asyncException成员里,checkErroneous方法会检查asyncException成员是否有内容,如果有则抛出来。
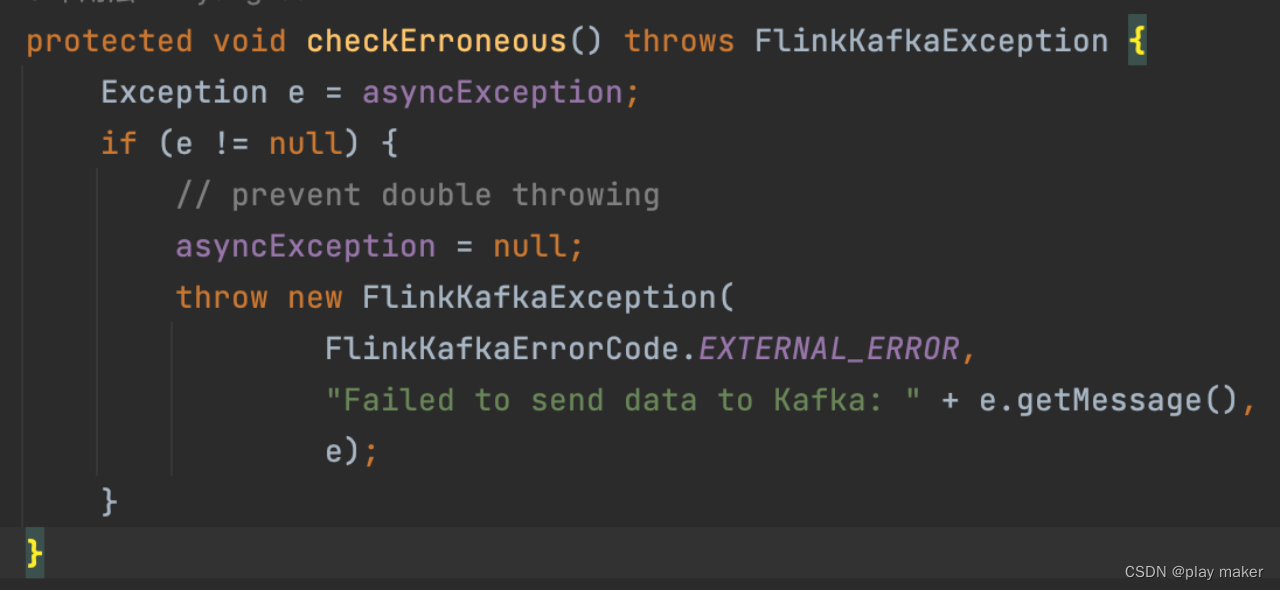
因此,open方法先根据logFailuresOnly配置设置好callback成员。
invoke方法
invoke方法在发送消息时,把callback成员设置成发送消息的回调。

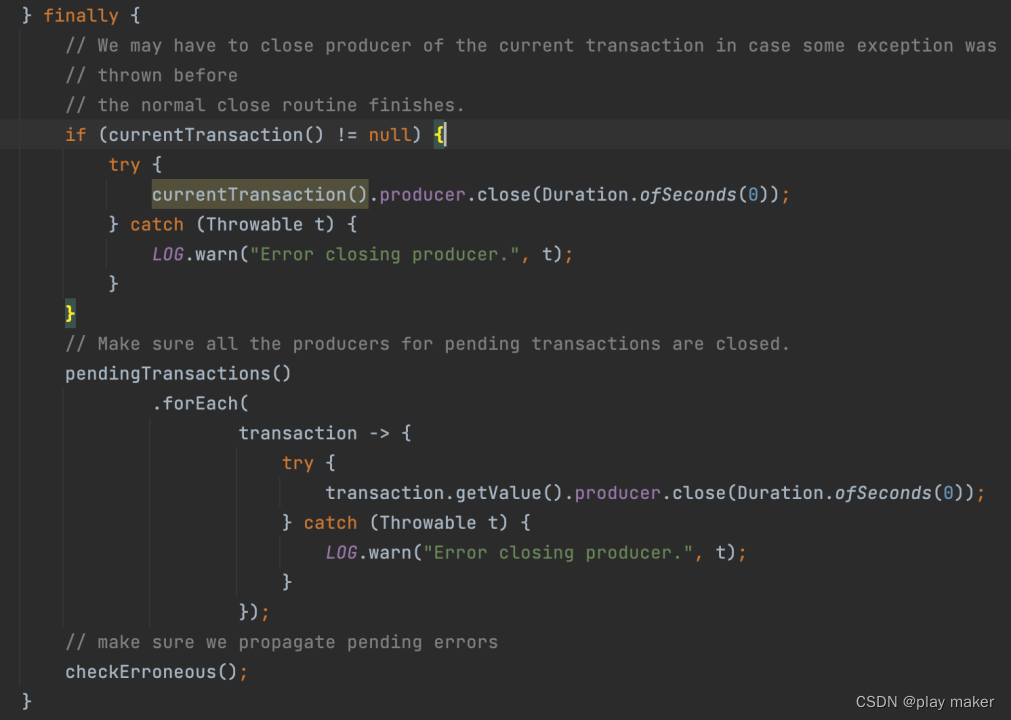
close方法
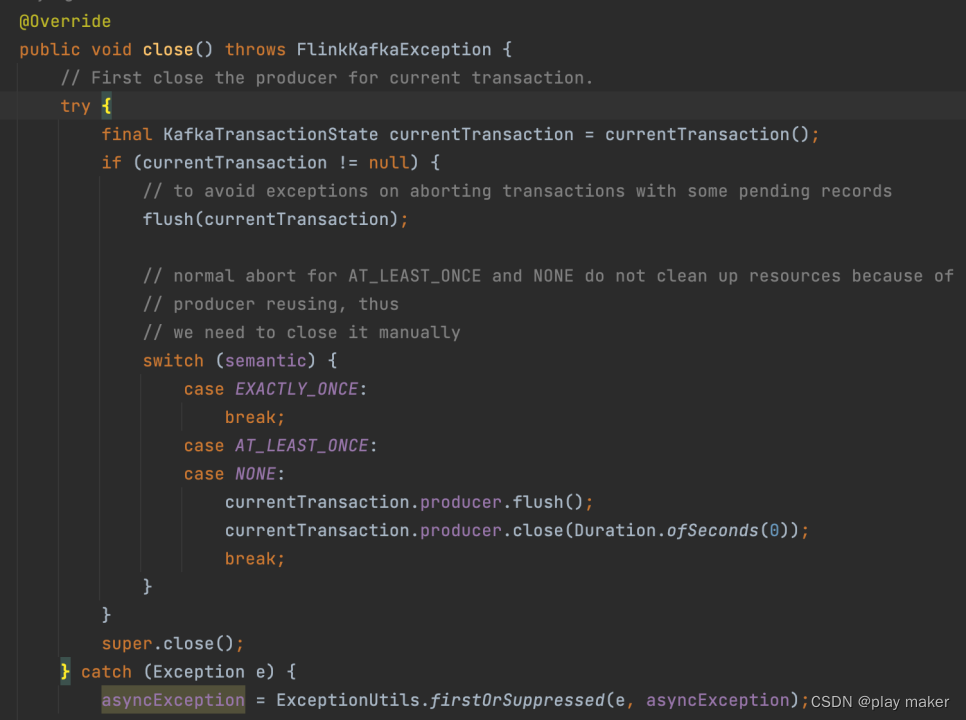
close方法先把currentTransaction的内容给flush一下,最后把pendingCommitTransactions、currentTransactionHolder对应的Producer都关闭掉,这里把代码放在finally代码块里,是为了避免前面抛错导致没有执行close。

![P2233 [HNOI2002]公交车路线](https://img-blog.csdnimg.cn/img_convert/8785b506d80e6970b4ced680e4c86d7e.png)