由于 Token 的限制,在开发 LangChain 问答机器人应用时,我们经常需要将文档切割,接着使用 Embedding 引擎 分别将分割后的 Document 变成 Embeddings,即向量表示。
同时输入的问题,也需要用到 Embedding 引擎 变成向量,再根据向量相似度找到最相近的 Embedding,将它们拼接成答案返回。
由此可见,一个合适又好用的 Embedding 引擎在 LangChain 应用开发过程中的重要性。
Inference 就是由 Jina AI 推出的 云端 API 解决方案,旨在为企业和开发者提供 经济实惠 的 AI 模型能力,如 BILP 模型,CLIP 模型,可用于处理常见的 AI 任务。
当你需要用到 CLIP 模型生成文本、图像的 Embedding 时,就不需要自己费时费力去训练模型了,Inference 直接提供了 API,可以非常方便地嵌入 LangChain 的工作流程里,速度更快,效果更好!
LangChain 官方推荐的 Embedding 引擎
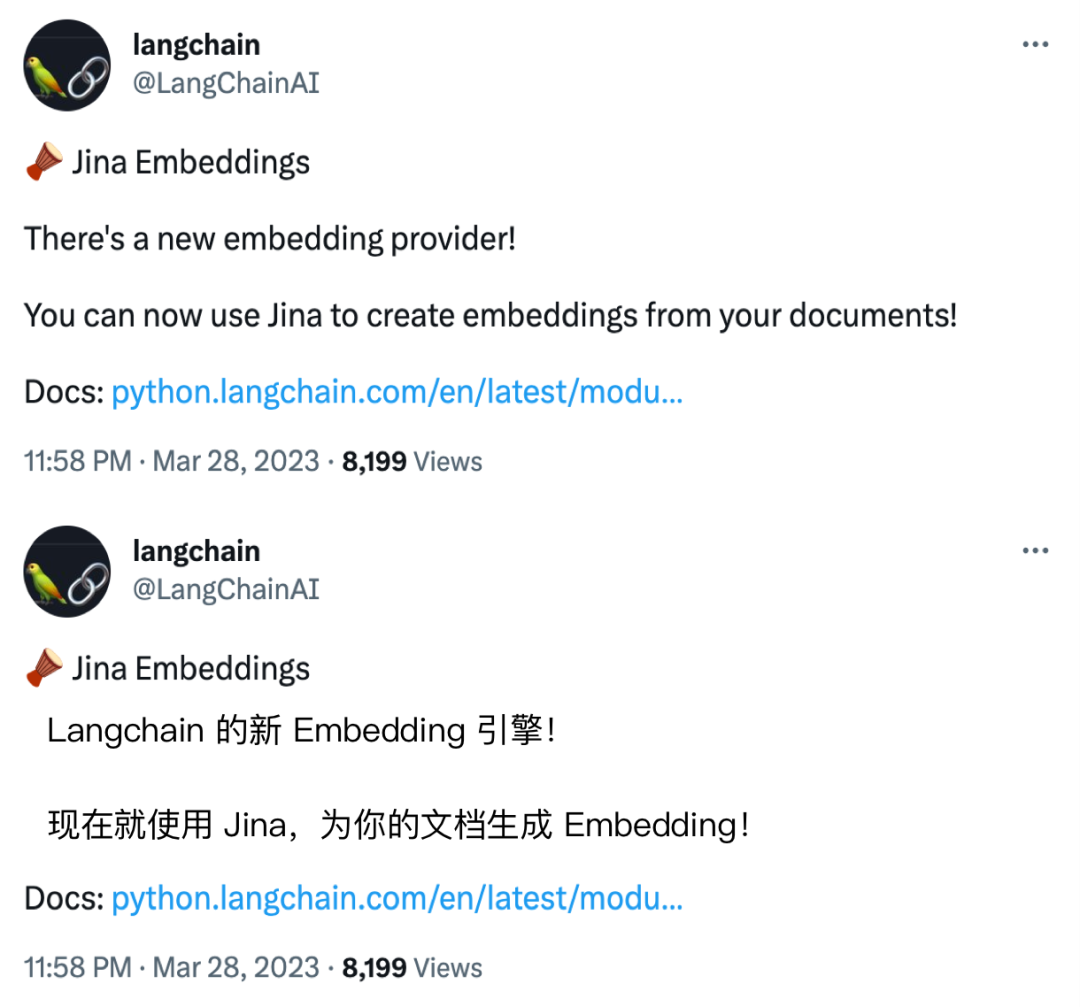
LangChain 推文
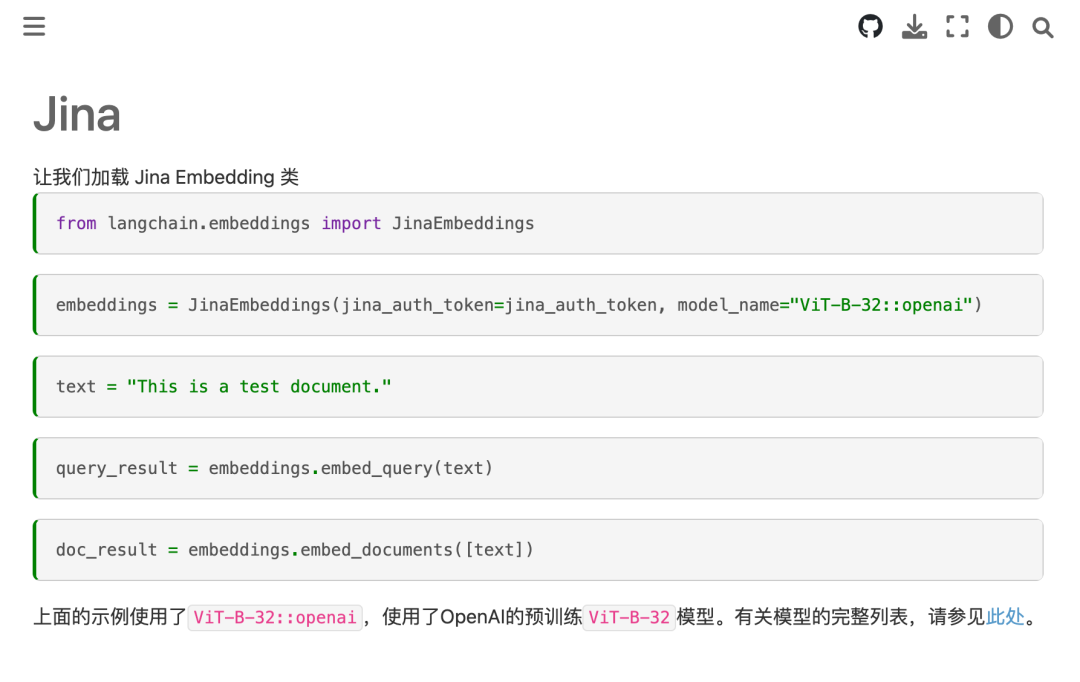
LangChain 官方文档
除了生成 Embedding 外,Inference 还为常见任务提供了一系列 AI 模型的 API,对于 视觉推理、视觉问答、向量表示计算、图像描述生成 等常见任务,你只需选择任务和模型,就能将 API 集成到服务里。目前支持 BILP 模型、CLIP 模型及其各种变体。
Inference 有哪些优势?
1. 简单易上手
Inference 提供了直观易用的网站页面,新手也能轻松上手。
cloud.jina.ai
2. 高性能&低延迟
AI 模型的托管和维护交给 Jina AI 来承担,企业和开发者只需要调用 Inference 高性能&低延迟 的 API,大幅节省了工程资源和时间成本。
3. 灵活&可拓展
Inference 为 LangChain 应用提供了很好的兼容性,为了提供更灵活更全面的服务,Inference 精选了 BLIP 模型,以及来自 OpenAI、OpenCLIP 和 HuggingFace 的 CLIP 模型及其变体,这些变体由不同的模型架构,或者训练数据集训练而来。
为了帮助你更好地了解 CLIP 模型的性能,为你的应用程序选择最佳模型。我们提供了一个 Benchmark:
🔗 https://clip-as-service.jina.ai/user-guides/benchmark/
4. 更具优势的成本
Inference 按需付费,也就是说企业和开发者只需为他们生成 Embedding 的需求付费,不用再支付额外的基础设施和维护成本。基于 Inference,企业能够以较低的成本,为用户提供高质量的 AI 服务。
针对 BILP2 模型,我们对市场上其他产品进行了比较。结果显示,Inference 在处理每个图像描述时的速度比其他竞品快了 4 倍。同时,Inference 的价格只有市场一般价格的 1/50。
所以 Inference 是一种性价比极高的选择。
🔗 Inference 产品链接:https://cloud.jina.ai/user/inference

上手实践:从 PDF 文档中提取内容
接下来,我们将创建一个可以处理 PDF 文件中文本的应用。
-
使用 Inference 生成 Embedding。
-
在用户提出问题时,使用这些 Embedding 来提取最相关的段落。
第 1 步:注册 Jina AI Cloud
注册 Jina AI Cloud 账号,🔗 网址:cloud.jina.ai
第 2 步:生成新的 Token
需要在 Setting 页面的 Access token 创建一个 Token。
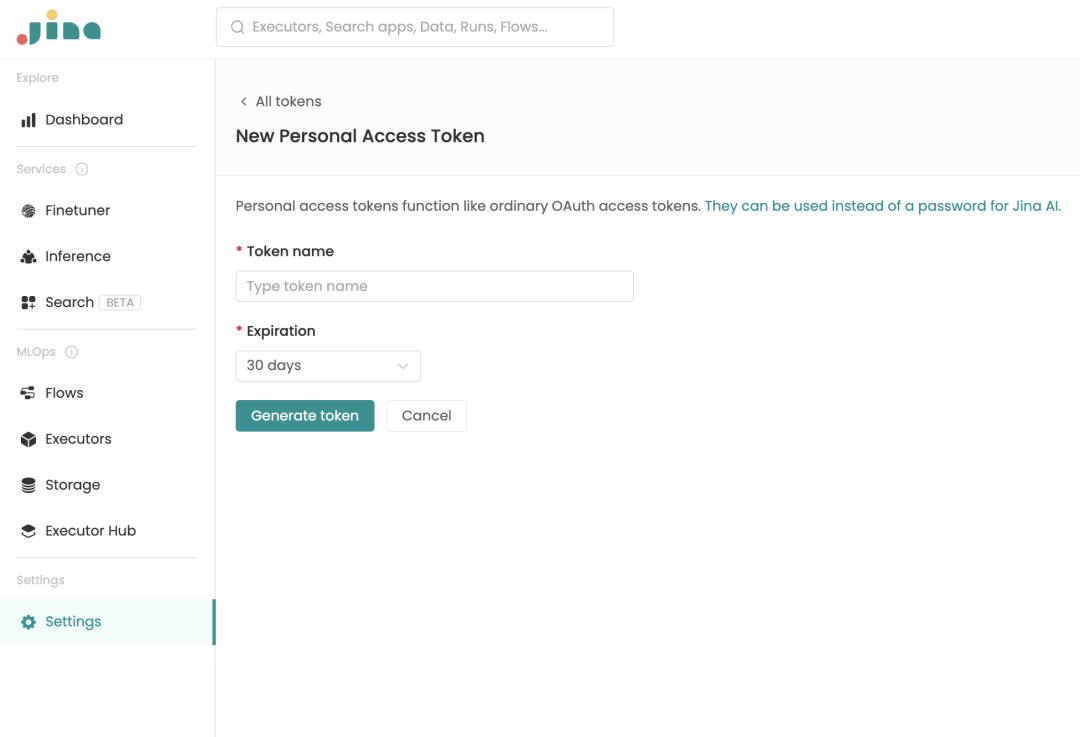
第 3 步:创建 Inference API
我们目前提供了 CLIP 模型、BILP 模型,以及他们的多种变体模型,你可以挑选模型和任务,创建一个 Inference API。
想要了解模型及其变体的技术细节?选择模型后,单击 Details 查看。
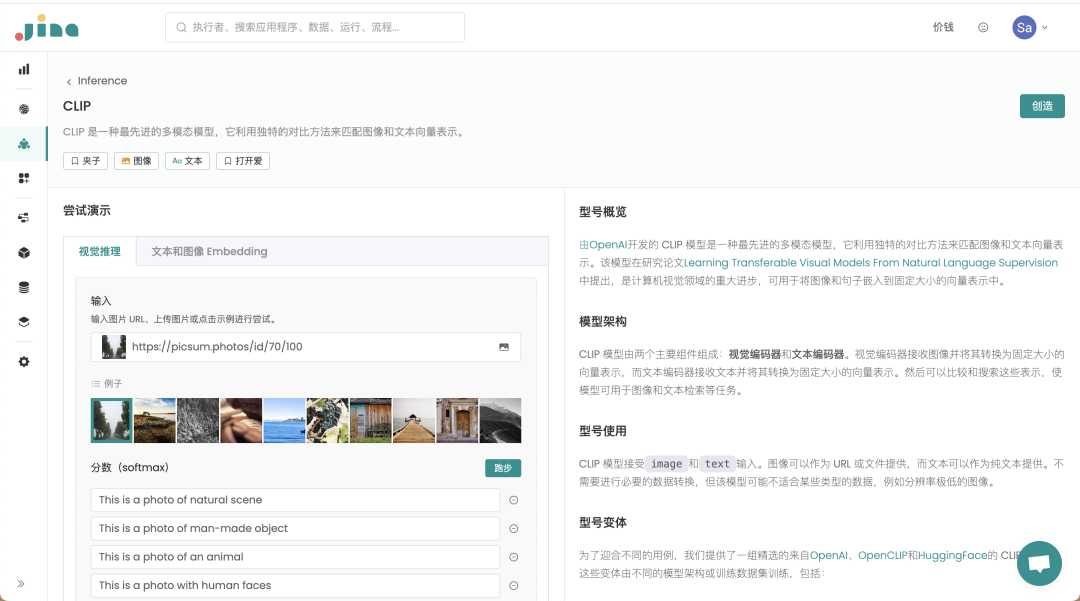
单击右上方的 Create ,开始创建 API。
接着,输入你的 API 名称,例如 “my-first-inference-api”。
现在,根据你对查询吞吐量和编码性能的要求,选择一个模型变体,例如 ViT-B-32::openai。最后,单击 Create。
第 4 步:安装包
首先,你需要为 LangChain 和 Inference 安装需要的包。使用以下命令来安装:
pip install "langchain>=0.0.124" jina==3.14.1 chromadb unstructured
Chroma 是一个内存型向量数据库,不需要在系统上或远程运行向量数据库。
第 5 步:导入库
from langchain.embeddings import JinaEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import UnstructuredPDFLoader
第 6 步:读取 PDF 内容:
loader = UnstructuredPDFLoader('path/to/file/knowledge.pdf')
data = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=0)
chunks = text_splitter.split_text(data[0].page_content)
使用 LangChain 的 CharacterTextSplitter,可以把我们从 PDF 中获取的大文本拆分为更小的块,然后使用 JinaEmbeddings 生成 embedding。
第 7 步:Embedding
使用 JinaEmbeddings 给文档生成 Embedding:
embeddings = JinaEmbeddings(
jina_auth_token='<your-auth-token-from-step-2>', model_name='ViT-B-32::openai'
)
docsearch = Chroma.from_texts(
chunks, embeddings, metadatas=[{'source': f'{i}'} for i in range(len(chunks))]
)
这里你需要输入你第二步得到的 jina_auth_token,同时 model_name 也需要输入你在第 3 步中,创建 Inference API 时选择的模型名字。
第 8 步:查找相似段落
对于给定的查询,在文档中找到最相似的段落:
query = 'the highest mountain in the Alaskan Range'
answers = docsearch.similarity_search(query)
print([answer.page_content for answer in answers])
输出如下所示:
[
'Clark at its southwest end to the White River in Canadas Yukon Territory in the southeast. The highest mountain in North America, Denali, is in the',
'The Alaska Range is a relatively narrow, 600-mile-long (950km) mountain range in the southcentral region of the U.S. state of Alaska, from Lake',
'Alaska Range. It is part of the American Cordillera. The Alaska range is one of the higher ranges in the world after the Himalayas and the Andes.'
]
结论
结合 Inference 的 API 和 LangChain 的模块化工作流程,让开发者和企业可以更容易地创造可扩展、且经济高效的应用程序。
赶快登录 cloud.jina.ai,探索 Inference 和 LangChain 集成的强大和便利。
将 LangChain 应用推向生产环境
在 LangChain 技术圈,Jina AI 还有一个开源项目广受欢迎:LangChain-serve,它为开发者们提供了一个简单易用的解决方案,可以 在几秒钟内将你的 LangChain 应用部署到云端,同时保持本地开发的简单性和便利性。
🌟 https://github.com/jina-ai/langchain-serve
使用 LangChain-serve 的好处
-
简易部署:基于 Langchain-serve,你可以把本地的 Chain 和 Agent ,转换成 RESTful、gRPC 或 WebSocket API,从而轻松实现部署。
-
可扩展性:部署之外,你还能够享受独立扩展、Serverless 和自动扩展 API 的好处,你可以根据自己的需求,用云端的资源来扩展你的应用,不需要担心基础架构的管理和维护。
-
简单开发:只需要修改很少的代码行,不会牺牲本地开发的简便性。
-
轻松展示:你还可以使用 Streamlit 演示来更好地调试和展示你的应用。
🌟 https://github.com/jina-ai/langchain-serve